Consider this code:
#include <iostream>
using namespace std;
int main () {
ios::sync_with_stdio(false);
ios::sync_with_stdio(true);
}
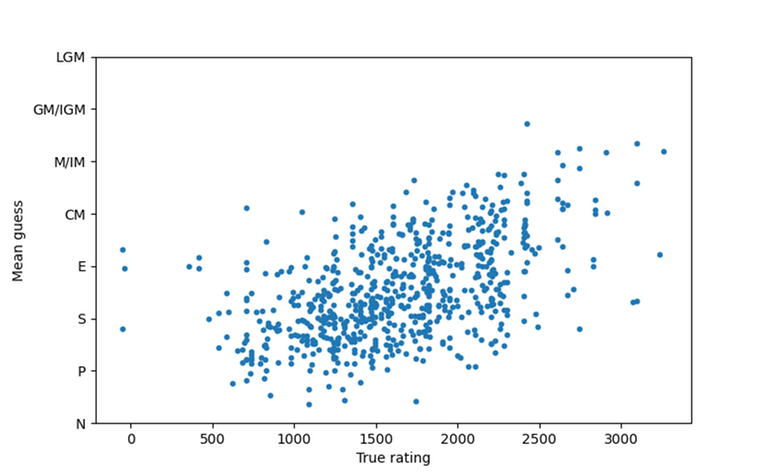
In GCC, are the C++ streams like std::cout etc then synchronized with the corresponding C methods like printf?
Answer
No — the second sync_with_stdio has no effect at all.
There is no trick here: the booleans aren't being interpreted as pointers or anything like that. There is simply no code to handle turning synchronization back on.
Implementation of sync_with_stdio
bool
ios_base::sync_with_stdio(bool __sync)
{
// _GLIBCXX_RESOLVE_LIB_DEFECTS
// 49. Underspecification of ios_base::sync_with_stdio
bool __ret = ios_base::Init::_S_synced_with_stdio;
// Turn off sync with C FILE* for cin, cout, cerr, clog iff
// currently synchronized.
if (!__sync && __ret)
{
// Make sure the standard streams are constructed.
ios_base::Init __init;
ios_base::Init::_S_synced_with_stdio = __sync;
// Explicitly call dtors to free any memory that is
// dynamically allocated by filebuf ctor or member functions,
// but don't deallocate all memory by calling operator delete.
buf_cout_sync.~stdio_sync_filebuf<char>();
buf_cin_sync.~stdio_sync_filebuf<char>();
buf_cerr_sync.~stdio_sync_filebuf<char>();
#ifdef _GLIBCXX_USE_WCHAR_T
buf_wcout_sync.~stdio_sync_filebuf<wchar_t>();
buf_wcin_sync.~stdio_sync_filebuf<wchar_t>();
buf_wcerr_sync.~stdio_sync_filebuf<wchar_t>();
#endif
// Create stream buffers for the standard streams and use
// those buffers without destroying and recreating the
// streams.
new (&buf_cout) stdio_filebuf<char>(stdout, ios_base::out);
new (&buf_cin) stdio_filebuf<char>(stdin, ios_base::in);
new (&buf_cerr) stdio_filebuf<char>(stderr, ios_base::out);
cout.rdbuf(&buf_cout);
cin.rdbuf(&buf_cin);
cerr.rdbuf(&buf_cerr);
clog.rdbuf(&buf_cerr);
#ifdef _GLIBCXX_USE_WCHAR_T
new (&buf_wcout) stdio_filebuf<wchar_t>(stdout, ios_base::out);
new (&buf_wcin) stdio_filebuf<wchar_t>(stdin, ios_base::in);
new (&buf_wcerr) stdio_filebuf<wchar_t>(stderr, ios_base::out);
wcout.rdbuf(&buf_wcout);
wcin.rdbuf(&buf_wcin);
wcerr.rdbuf(&buf_wcerr);
wclog.rdbuf(&buf_wcerr);
#endif
}
return __ret;
}