


Hi everyone!
As you may know, I'm an attention whore seeker. For this (well, not only this) reason year and almost a half ago I've created public page on vk.com: Зайчатки разума. Name is some old Russian semi-linguistic meme without adequate English translation, thus I decided to use 'Mindbun' as presumably closest to literal translation as English name. There was announce on codeforces, which didn't get any particularly positive or negative reaction. Or any reaction at all :)
On that page I mostly post maths things interesting to me and information of any similar activities by me on other places (like, here). It serves as some kind of public notebook to me. Why won't I just post stuff on codeforces, as before? Well, my tastes may be very specific and I'm greatly afraid that I will bother community by posting dozens of short posts on topics which only partially relevant to competitive programming and strongly imbalanced (on mentioned page there is like half of content is about polynomials and/or complex numbers). Thus I decided to throw my thoughts on some other channel and leave only 'big' content for codeforces.
And it was pretty successful as for me. VK page has 506 followers currently and I really enjoy making that stuff! You can see compilation of my older posts and newer ones (Russian, sorry!). So now I decided that it's good time for i18n. Thus I'm going to crosspost English versions of original VK public page in special telegram channel. Welcome! Also since I really like to chat with people, I also created Mindbun-related chat for anyone interested in it :)
And to give you some example of what's it like, I'll just provide you first post from the channel :)

P.S. Channel has not any content yet. I'll start by translating some newer posts from VK page, and will post any future entries there. I'd like to translate all the previous stuff, but there's vast of it and I really can't afford it right now, and I feel shy about some of my older posts :(
P.P.S. I would really appreciate your feedback on the following question: how should I inform on updates in Mindbun here? There are several variants I'm considering right now.
- Post only big stuff on codeforces and keep notes to Mindbun only
- Make some kind of digest with updates once a... Week? Month? Year? Random moment of time?..
- Any other formats I haven't considered yet?






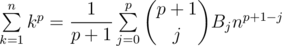
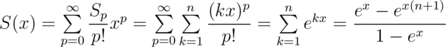
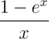 and multiplying it with
and multiplying it with 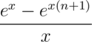 . Enjoy your power sums without Stirling and/or Bernoulli numbers!
. Enjoy your power sums without Stirling and/or Bernoulli numbers!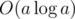 .
.

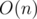 вместо заявленных
вместо заявленных  .
.  correspond to segment
correspond to segment 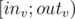 and the path from
and the path from 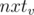 ) will be
) will be 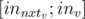 subsegment which gives you the opportunity to process queries on pathes and subtrees simultaneously in the same segment tree.
subsegment which gives you the opportunity to process queries on pathes and subtrees simultaneously in the same segment tree.
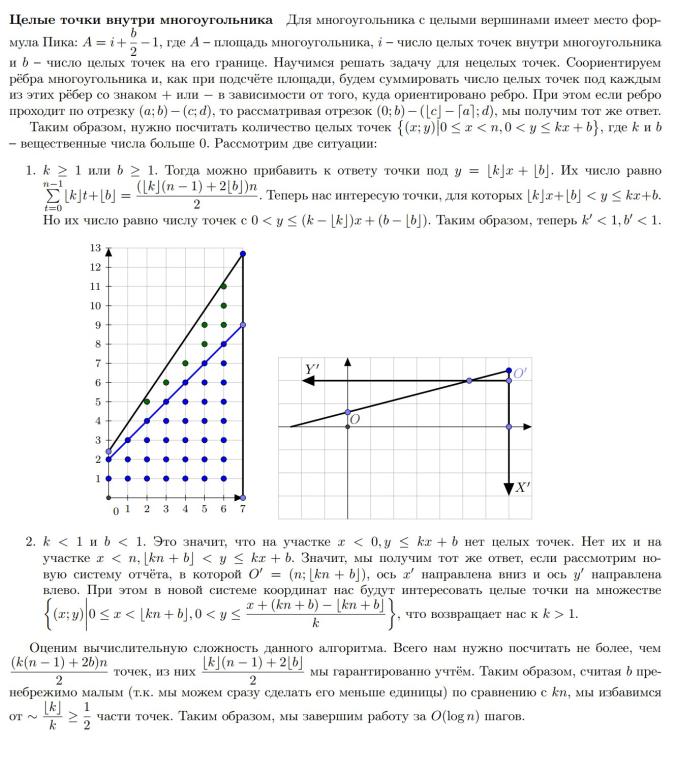
 ?
?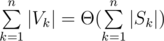 ? Can you prove it or make a counter-example?
? Can you prove it or make a counter-example? в онлайне относительно приписывания символа в конец строки (т.е. ответ будет получен для каждого префикса). Также будет рассмотрена задача разбиения строки на
в онлайне относительно приписывания символа в конец строки (т.е. ответ будет получен для каждого префикса). Также будет рассмотрена задача разбиения строки на 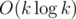 в оффлайне. Первый алгоритм с такой оценкой был получен Дэвидом Эппштейном в 1992 году сведением к fully dynamic minimum spanning tree problem, однако здесь речь пойдёт о более простом алгоритме, предложенном в 2012 году Сергеем
в оффлайне. Первый алгоритм с такой оценкой был получен Дэвидом Эппштейном в 1992 году сведением к fully dynamic minimum spanning tree problem, однако здесь речь пойдёт о более простом алгоритме, предложенном в 2012 году Сергеем 