Introduction
In computer science, 2-satisfiability, 2-SAT or just 2SAT is a computational problem of assigning values to variables, each of which has two possible values, in order to satisfy a system of constraints on pairs of variables. It is a special case of the general Boolean satisfiability problem, which can involve constraints on more than two variables, and of constraint satisfaction problems, which can allow more than two choices for the value of each variable. But in contrast to those more general problems, which are NP-complete, 2-satisfiability can be solved in polynomial time. -Wikipedia
If you have not heard of propositional logic before, plead read about it here. Wikipedia links have been provided wherever a term has been used for the first time in this tutorial. The whole algorithm is based on graph theory so it will help to be familiar with directed graphs and strongly connected components beforehand.
By representing our formula in the 2-Conjunctive Normal Form, we can find an assignment of values for our variables in $$$O(N + M)$$$ where we have $$$N$$$ variables and $$$M$$$ clauses or report that the proposition isn't satisfiable. Simply put, a formula in the 2-CNF is an AND of ORs where each clause contains exactly two literals.
Thanks to Monogon for providing valuable suggestions and helping with the proof.
A Few Definitions
$$$\lnot x$$$ is the complement of $$$x$$$. If $$$x$$$ is $$$\it{true}$$$, $$$\lnot x$$$ is $$$\it{false}$$$. If $$$x$$$ is $$$\it{false}$$$, $$$\lnot x$$$ is $$$\it{true}$$$.
$$$(x \lor y)$$$ stands for $$$x$$$ OR $$$y$$$ (disjunction). It results in $$$\it{true}$$$ only if at least one of $$$x$$$ and $$$y$$$ is $$$\it{true}$$$.
$$$(x \land y)$$$ stands for $$$x$$$ AND $$$y$$$ (conjunction). It results in $$$\it{true}$$$ only if $$$x$$$ and $$$y$$$ are both assigned $$$\it{true}$$$.
$$$(x \Rightarrow y)$$$ stands for $$$x$$$ implies $$$y$$$ (implication). In order for it to result in $$$\it{true}$$$, if $$$x$$$ is $$$\it{true}$$$, $$$y$$$ has to be $$$\it{true}$$$. Otherwise, $$$y$$$ could be $$$\it{true}$$$ or $$$\it{false}$$$.
$$$(x \iff y)$$$ stands for ($$$x$$$ implies $$$y$$$) AND ($$$y$$$ implies $$$x$$$). It results in $$$\it{true}$$$ only if both $$$x$$$ and $$$y$$$ have the same value.
2-CNF consists of a bunch of OR clauses combined with AND. Each OR clause must result in $$$\it{true}$$$ for a proposition to be satisfied.
Main Idea
We want to create a directed graph of implications where each node is a variable.
Let's consider a disjunction of two literals $$$x$$$ and $$$y$$$ to see what all information we can deduce from it. We know that: $$$(x \lor y) \iff (\lnot x \Rightarrow y)$$$ (Implication Law).
This becomes an edge $$$(\lnot x, y)$$$ in our graph. An edge $$$(u, v)$$$ in this tutorial is directed from $$$u$$$ to $$$v$$$.
We must also add an edge $$$(\lnot y, x)$$$ to our graph.
Why?An edge $$$(\lnot y, x)$$$ refers to the clause $$$(\lnot y \Rightarrow x)$$$.
$$$(x \lor y) \iff (y \lor x)$$$ (Commutative Property)
$$$(y \lor x) \iff (\lnot y \Rightarrow x)$$$ (Implication Law)
Finally, $$$(x \lor y) \iff ((\lnot x \Rightarrow y) \land (\lnot y \Rightarrow x))$$$.
Since our formula is a conjunction of clauses of the form $$$(x \lor y)$$$, we will be adding edges of this type only.
Do keep in mind that if there exists an edge $$$(x, y)$$$ in the graph, there also exists an edge $$$(\lnot y, \lnot x)$$$.
The Algorithm
Here is what the graph looks like for the following proposition in 2-CNF:
$$$(a \lor \lnot b) \land (\lnot a \lor b) \land (\lnot a \lor \lnot b) \land (a \lor c) \land (d \lor b)$$$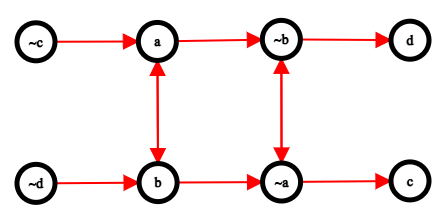
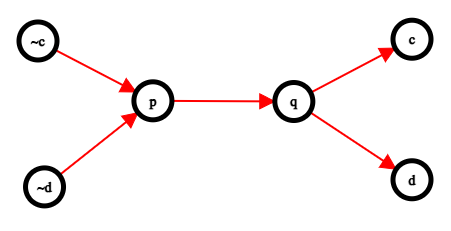
Shown above is the implication graph and its condensation graph.
After we have added all the required edges, we want to find all the strongly connected components in the graph. The condensation graph is acyclic (graph obtained on compressing each SCC into a single node but retaining connections). Visualise this as a graph where SCCs are connected to each other with edges directed from left to right (as shown in the diagrams above).
What happens when for any variable $$$x$$$, $$$\lnot x$$$ lies in the same SCC as $$$x$$$? There is no valid assignment of truth values. Setting $$$x$$$ to $$$true$$$ would imply that $$$\lnot x$$$ has to be $$$true$$$ and setting $$$\lnot x$$$ to $$$true$$$ would imply that $$$x$$$ has to be $$$true$$$. In both cases, this leads to a contradiction. Hence, no answer exists.
When that is not the case, we can assign values to all variables.
Let $$$id[v]$$$ represent the index of the SCC (in any valid topological ordering) that contains $$$v$$$. In the topological ordering, for any two nodes $$$u$$$ and $$$v$$$, if $$$id[u]$$$ < $$$id[v]$$$, the SCC containing $$$u$$$ lies to the left of the SCC containing $$$v$$$. If they are equal, both nodes lie in the same SCC. If it's the opposite, $$$u$$$'s SCC lies to the right of $$$v$$$'s SCC.
For each variable $$$x$$$:
1. If $$$id[x]$$$ > $$$id[\lnot x]$$$, let's set $$$x$$$ to $$$\it{true}$$$ and $$$\lnot x$$$ to $$$\it{false}$$$.
2. If $$$id[x]$$$ < $$$id[\lnot x]$$$, let's set $$$x$$$ to $$$\it{false}$$$ and $$$\lnot x$$$ to $$$\it{true}$$$.
An important observation is that all variables in a SCC have the same truth value.
This way, we can satisfy our proposition in linear time.
Why Does It Work?
The implication graph is set up in a way that our proposition is satisfied if we don't have a case where some node $$$u$$$ which has been assigned $$$true$$$ can reach some node $$$v$$$ which has been assigned $$$false$$$.
If some variable $$$x$$$ is assigned true, we know that $$$id[x]$$$ > $$$id[\lnot x]$$$ because of how we construct the answer. Keep in mind that if $$$x$$$ can reach $$$y$$$, $$$\lnot y$$$ can reach $$$\lnot x$$$ in our implication graph.
Let's prove that we don't have two nodes $$$u$$$ and $$$v$$$ such that there is a path from $$$u$$$ to $$$v$$$ and $$$u$$$ is assigned $$$true$$$ while $$$v$$$ is assigned $$$false$$$. Assume that this is the case. What does this mean? $$$id[\lnot u] \lt id[u]$$$ because $$$u$$$ has been assigned $$$true$$$ and $$$id[v] \lt id[\lnot v]$$$ because $$$v$$$ has been assigned $$$false$$$. According to our assumption, $$$id[\lnot u] \lt id[u] \leq id[v] \lt id[\lnot v]$$$. However, since there exists a path from $$$u$$$ to $$$v$$$, there has to exist a path from $$$\lnot v$$$ to $$$\lnot u$$$. That would imply that $$$id[\lnot u] \ge id[\lnot v]$$$. This contradicts our previous inequality.
Types of Constraints
Keep in mind that:
$$$(x \lor y) \iff ((\lnot x \Rightarrow y) \land (\lnot y \Rightarrow x))$$$1. Forcing a variable to be $$$true$$$
If we want to force $$$x$$$ to be true, it is equivalent to adding a clause $$$(x \lor x)$$$.
2. Exactly one variable must be $$$true$$$
This is equivalent to $$$(x \lor y) \land (\lnot x \lor \lnot y)$$$.
3. At least one variable must be $$$true$$$
This is just a clause $$$(x \lor y)$$$.
4. Both variables must have the same value
This is equivalent to $$$(\lnot x \lor y) \land (x \lor \lnot y)$$$.
Implementation
After we figure out the clauses that need to be added and set up the graph adjacency list, we need to extract all strongly connected components (using any algorithm keeping in mind its efficiency). Kosaraju's algorithm or Tarjan's algorithm is commonly used to extract strongly connected components. I use Kosaraju's algorithm in my implementation below. We want to give each SCC an ID and store for each node which SCC it belongs to. Variables can be numbered from $$$1$$$ to $$$N$$$ and their complements can be numbered from $$$N + 1$$$ to $$$2N$$$. So $$$i + N$$$ is $$$i$$$'s complement.
Code For 2-SAT Using Kosaraju's Algorithmstruct two_sat {
int n;
vector<vector<int>> g, gr; // gr is the reversed graph
vector<int> comp, topological_order, answer; // comp[v]: ID of the SCC containing node v
vector<bool> vis;
two_sat() {}
two_sat(int _n) { init(_n); }
void init(int _n) {
n = _n;
g.assign(2 * n, vector<int>());
gr.assign(2 * n, vector<int>());
comp.resize(2 * n);
vis.resize(2 * n);
answer.resize(2 * n);
}
void add_edge(int u, int v) {
g[u].push_back(v);
gr[v].push_back(u);
}
// For the following three functions
// int x, bool val: if 'val' is true, we take the variable to be x. Otherwise we take it to be x's complement.
// At least one of them is true
void add_clause_or(int i, bool f, int j, bool g) {
add_edge(i + (f ? n : 0), j + (g ? 0 : n));
add_edge(j + (g ? n : 0), i + (f ? 0 : n));
}
// Only one of them is true
void add_clause_xor(int i, bool f, int j, bool g) {
add_clause_or(i, f, j, g);
add_clause_or(i, !f, j, !g);
}
// Both of them have the same value
void add_clause_and(int i, bool f, int j, bool g) {
add_clause_xor(i, !f, j, g);
}
// Topological sort
void dfs(int u) {
vis[u] = true;
for (const auto &v : g[u])
if (!vis[v]) dfs(v);
topological_order.push_back(u);
}
// Extracting strongly connected components
void scc(int u, int id) {
vis[u] = true;
comp[u] = id;
for (const auto &v : gr[u])
if (!vis[v]) scc(v, id);
}
// Returns true if the given proposition is satisfiable and constructs a valid assignment
bool satisfiable() {
fill(vis.begin(), vis.end(), false);
for (int i = 0; i < 2 * n; i++)
if (!vis[i]) dfs(i);
fill(vis.begin(), vis.end(), false);
reverse(topological_order.begin(), topological_order.end());
int id = 0;
for (const auto &v : topological_order)
if (!vis[v]) scc(v, id++);
// Constructing the answer
for (int i = 0; i < n; i++) {
if (comp[i] == comp[i + n]) return false;
answer[i] = (comp[i] > comp[i + n] ? 1 : 0);
}
return true;
}
};
Try to solve this problem on your own.
SolutionThis problem is very direct. Each topping represents a variable. For a topping $$$x$$$ and preference '$$$+$$$', we use $$$x$$$ while adding a clause. For preference '$$$-$$$' we use $$$\lnot x$$$ in our clause.
Code for Giant Pizza#include <bits/stdc++.h>
using namespace std;
struct two_sat {
int n;
vector<vector<int>> g, gr;
vector<int> comp, topological_order, answer;
vector<bool> vis;
two_sat() {}
two_sat(int _n) { init(_n); }
void init(int _n) {
n = _n;
g.assign(2 * n, vector<int>());
gr.assign(2 * n, vector<int>());
comp.resize(2 * n);
vis.resize(2 * n);
answer.resize(2 * n);
}
void add_edge(int u, int v) {
g[u].push_back(v);
gr[v].push_back(u);
}
// At least one of them is true
void add_clause_or(int i, bool f, int j, bool g) {
add_edge(i + (f ? n : 0), j + (g ? 0 : n));
add_edge(j + (g ? n : 0), i + (f ? 0 : n));
}
// Only one of them is true
void add_clause_xor(int i, bool f, int j, bool g) {
add_clause_or(i, f, j, g);
add_clause_or(i, !f, j, !g);
}
// Both of them have the same value
void add_clause_and(int i, bool f, int j, bool g) {
add_clause_xor(i, !f, j, g);
}
void dfs(int u) {
vis[u] = true;
for (const auto &v : g[u])
if (!vis[v]) dfs(v);
topological_order.push_back(u);
}
void scc(int u, int id) {
vis[u] = true;
comp[u] = id;
for (const auto &v : gr[u])
if (!vis[v]) scc(v, id);
}
bool satisfiable() {
fill(vis.begin(), vis.end(), false);
for (int i = 0; i < 2 * n; i++)
if (!vis[i]) dfs(i);
fill(vis.begin(), vis.end(), false);
reverse(topological_order.begin(), topological_order.end());
int id = 0;
for (const auto &v : topological_order)
if (!vis[v]) scc(v, id++);
for (int i = 0; i < n; i++) {
if (comp[i] == comp[i + n]) return false;
answer[i] = (comp[i] > comp[i + n] ? 1 : 0);
}
return true;
}
};
signed main() {
int N, M;
cin >> N >> M;
two_sat solver(M);
while (N--) {
int topping1, topping2;
char preference1, preference2;
cin >> preference1 >> topping1 >> preference2 >> topping2;
solver.add_clause_or(topping1 - 1, preference1 == '+', topping2 - 1, preference2 == '+');
}
if (!solver.satisfiable()) {
cout << "IMPOSSIBLE";
return 0;
}
for (int i = 0; i < M; i++)
cout << (solver.answer[i] ? '+' : '-') << " ";
}
Though this problem asks only whether it is possible to place the cards in such a way that no two cards are showing the same picture, try to find a valid arrangement as well.
SolutionIf $$$N$$$ was small enough, we could add constraints between each pair of cards. This would be $$$O(N^2)$$$. We cannot do that here.
For each integer $$$x$$$ from $$$1$$$ to $$$2N$$$, we want to store the indices of all the cards which have $$$x$$$ on any side, along with which side they have it on. Now our problem is the following: add implications in such a way that at most one card from each list is turned to the side which has that integer on it.
We can solve this problem for each list of indices separately. What all implications do we have? Let's consider a list $$$C$$$ of size $$$M$$$, for an arbitrary integer $$$x$$$. Let's make the use of $$$M$$$ additional variables $$$\it{pref}_i$$$ in our 2-SAT. $$$\it{pref}_i$$$ tells us if we have already displayed integer $$$x$$$ on a card in the range $$$[0, i - 1]$$$ of this list. We have the following logical implications:
1. If $$$C_i$$$ is $$$\it{true}$$$, $$$\it{pref}_{i + 1}$$$ must be $$$\it{true}$$$.
2. If $$$\it{pref}_i$$$ is $$$\it{true}$$$, $$$\it{pref}_{i + 1}$$$ must be $$$\it{true}$$$.
3. If $$$\it{pref}_i$$$ is $$$\it{true}$$$, $$$C_i$$$ must be $$$\it{false}$$$.
This way, we can solve this problem in linear time. See the code below to understand this better.
Code#include <bits/stdc++.h>
using namespace std;
#define sz(x) (int) (x).size()
struct two_sat {
int n;
vector<vector<int>> g, gr;
vector<int> comp, topological_order, answer;
vector<bool> vis;
two_sat() {}
two_sat(int _n) { init(_n); }
void init(int _n) {
n = _n;
g.assign(2 * n, vector<int>());
gr.assign(2 * n, vector<int>());
comp.resize(2 * n);
vis.resize(2 * n);
answer.resize(2 * n);
}
void add_edge(int u, int v) {
g[u].push_back(v);
gr[v].push_back(u);
}
void add_edge(int i, bool f, int j, bool g) {
add_edge(i + (f ? 0 : n), j + (g ? 0 : n));
add_edge(j + (g ? n : 0), i + (f ? n : 0));
}
// At least one of them is true
void add_clause_or(int i, bool f, int j, bool g) {
add_edge(i + (f ? n : 0), j + (g ? 0 : n));
add_edge(j + (g ? n : 0), i + (f ? 0 : n));
}
// Only one of them is true
void add_clause_xor(int i, bool f, int j, bool g) {
add_clause_or(i, f, j, g);
add_clause_or(i, !f, j, !g);
}
// Both of them have the same value
void add_clause_and(int i, bool f, int j, bool g) {
add_clause_xor(i, !f, j, g);
}
void dfs(int u) {
vis[u] = true;
for (const auto &v : g[u])
if (!vis[v]) dfs(v);
topological_order.push_back(u);
}
void scc(int u, int id) {
vis[u] = true;
comp[u] = id;
for (const auto &v : gr[u])
if (!vis[v]) scc(v, id);
}
bool satisfiable() {
fill(vis.begin(), vis.end(), false);
for (int i = 0; i < 2 * n; i++)
if (!vis[i]) dfs(i);
fill(vis.begin(), vis.end(), false);
reverse(topological_order.begin(), topological_order.end());
int id = 0;
for (const auto &v : topological_order)
if (!vis[v]) scc(v, id++);
for (int i = 0; i < n; i++) {
if (comp[i] == comp[i + n]) return false;
answer[i] = (comp[i] > comp[i + n] ? 1 : 0);
}
return true;
}
};
const int MXN = 5e4 + 1, INF = 1e9 + 5;
two_sat solver;
vector<pair<int, int>> cards[2 * MXN];
void solve() {
int N;
cin >> N;
for (int i = 0; i < N; i++) {
int x, y;
cin >> x >> y;
x--, y--;
cards[x].emplace_back(i, 1);
cards[y].emplace_back(i, 0);
}
int use = N;
solver.init(3 * N);
for (int i = 0; i < 2 * N; i++) {
if (cards[i].empty()) continue;
for (int j = 0; j < sz(cards[i]); j++) {
int cur = cards[i][j].first, val = cards[i][j].second;
solver.add_edge(cur, val, use, 1); // If current true, prefix from next has to be true
if (j > 0) {
solver.add_edge(use - 1, 1, cur, val ^ 1); // If prefix found, current cannot be true
solver.add_edge(use - 1, 1, use, 1); // If prefix found, next prefix also true
}
use++;
}
}
cout << (solver.satisfiable() ? "possible" : "impossible") << "\n";
for (int i = 0; i < 2 * N; i++)
cards[i].clear();
}
signed main() {
ios_base::sync_with_stdio(false);
cin.tie(nullptr);
int TC = 1;
cin >> TC;
while (TC--) solve();
}
Practice Problems