



Hello, Codeforces!
From the ICPC 2023 World Finals, we are happy to bring you an exciting online event: The ICPC 2023 Online Challenge powered by Huawei,which will start on November 20, 2023 15:00 UTC (UTC+8)
In this Challenge, you will have a unique chance:
- to compete with top programmers globally
- to solve 1 exciting problem prepared by Huawei
- to win amazing prizes from Huawei!
It is an individual competition.
The ICPC 2023 Online Challenge powered by Huawei:
Start: November 20, 2023 15:00 (UTC+8)
Finish: December 4, 2023 15:00 (UTC+8)
We hope you'll enjoy this complex yet very exciting Challenge!
Problem
We are glad to propose to you an exciting challenge “Deterministic Scheduling for Extended Reality over 5G and Beyond”, which is prepared by Huawei Wireless Product Line.
In this contest, we focus on a XR-service scheduling problem to maximize the total number of successfully transformed XR-data frames under specific transmission requirements. Extended reality (XR) is an umbrella term for different types of realities such as virtual reality (VR), augmented reality (AR), and mixed reality (MR), which can provide people with immersive experience. To achieve better user-experience, scheduling algorithm should be proposed to efficiently utilize the limited radio resources, e.g., time resource, frequency resource, and power resource. Due to several practical constraints, the scheduling task is a typical NP-hard problem.
Prizes from Huawei
| Rank | Prize | |
| Grand Prize (Rank 1) | € 12 000 EUR + the travel trip to the 48th Annual ICPC World Finals in a guest role | |
| First Prize (Rank 2-10) | € 6,000 EUR | |
| Second Prize (Rank 11-30) | € 3,000 EUR | |
| Third Prize (Rank 31-60): | € 800 EUR | |
| TOP 200 Participants | Souvenir T-shirt | |
| * If for any reason, Huawei cannot deliver the allocated prize to your region, the prize may be replaced by another prize (if no legal restrictions), at the discretion of the Huawei.. | ||
Challenge Rules and Conditions
By participating in this Challenge, you agree to the Challenge Rules and Conditions of Participation
Good luck, we hope this will be fun!






0_0
this comment is here to prevent another annoying chain.
thank you for helping to reduce the spam in comments! reading comments is a hassle because of irrelevant messages.
is it rated?
ask while knowing the answer
As a specialist, should I even try?
Do you lose anything by trying?
Well, I suppose not. But it might not be as helpful as normal contests if the problems are much harder than what I can solve
1 impossible chinese problem o_o
so many awards!
o.O
It's such a great chance to improve and have fun!
Especially working accompanied by the best players in the world.
how many do usually attempt this? i just want a t-shirt :D
That's the last round, prizes were almost the same: https://mirror.codeforces.com/contest/1813/standings
The rounds before had even less participants, probably because the problem statement was longer and harder to understand.
wait is this rated
???
nvm its probably not rated
can you explain some information about this contest please
its an contest sponsored by huawei it includes 1 singular problem which is NP-Hard im probably not the best at explaining this but NP-Hard is on the difficulty of the Turing Halting Problem (non-deterministic polynomial-time hard)
great!!
Will be there an additional mirror for Huawei employees, like the previous time?
Dear participant, Thank you for your interest in our contest. Unfortunately, this time additional mirror for Huawei employees is not provided.
hmmmmm it still says post-world finals in the contest page
O_o
Is it rated?
Enjoy the contest!
Why don't they provide Chinese questions for such competitions every time? Is it difficult to do two sets of questions? Isn't Huawei a Chinese company?
!
Is it enough to only set your Codeforces email the same as your ICPC email to be eligible for prizes?
Will there be system test based on hidden test set like in the previous contest, or will the leaderboard be the final results?
Update: Looks like Huawei just published an announcement that addresses this
good question!
I submitted the code a dozen times yesterday, but they were all been wrong. Today I was told that the problem is the space at the end of a line, which is too stupid.
Same, I submitted a solution at 00:10:48 that would've gotten 1000 points and put me at first place but it got WA :skull:
.
Hello Codeforces
Yes.
look at this bot's submissions. maybe you can do something? ban for example https://mirror.codeforces.com/submissions/Wizst
It was a fun competition. Congratulations to all participants! Would you mind sharing your approach? I am really curious to know what people have tried, specially the top performing contestants.
Can you share yours?
Sure. My (final) approach is a simple greedy one.
I sort frames ascendingly by their TBS. For each frame, I sort the TTIs, ascendingly, by the amount of users that are competing (user that has not-yet processed frame overlaping this TTI) it. Then I proceed trying to schedule, on each TTI, until I can deliver all the required TBS, in the following way:
If I have rq>0 free bands on the TTI (R's with no allocation), I allocate 1 power across all cells in these rq bands with this user (I call this a WideAllocation). If this exceeds TBS, I reduce bands quantity accordingly, using bissection method to approximate/minimize the amount of bands and allocation used. (this produces no interference)
If all bands are occupied, I verify if I can grab two WideAllocations and merge to a single band-cell (R-K) (I call this a MergeAllocation), or merge one WideAllocation to an existing MergeAllocation (resulting in 3+ users allocated in the same band-cell-tti). I have some policies to decide which to choose, based on the cost (amount of band used) for each of these operations. When sucessfull, I will have a free band to try to WideAllocate on (previous item). When not sucessfull, I check for ways to merge allocations of the current frame with WideAllocations or MergeAllocations.
When not sucessfull allocating the desired frame, I undo the operations/allocations.
In all these merges, I prevent doing more than one in the same R, different K (to avoid cross-cell interference). And for the same user I avoid having more than one in the same cell (just because it changes the geometric mean, and then I would need to calculate again the transmission).
I have experimented other types of merges having cross-cell interference, or keeping different merges having the same user in the same cell, but I could not make them perform well in time.
Thank you! Very interesting. Looks like only try and guess the only way. May be somebody tried more "scientific" approach?
Thx, I don't think that my be interesting, but anyway:
1) Sort frames by TBS/tti 2) For each tti I select band by maximum data that can bring (considering already existing allocations). Drops if we can't satisfy TBS 3) For each r select all k that brings non zero data. 4) Find optimal distribution (minumum power with target TBS). You used bisectional method, but I use formula.
Once finished I started another approach, like previous but select all (r, k, t) for given frame, sort by data it can bring and used all the power.
After, I select remaining frames and try to assign power and check result, if frames count decreased, power assigning canceled.
All brings about 13000. If I use first step or second, it brings about 12000.
It is interesting, what is make 3000 difference between my approach and yours. Hope we can submit solutions and I will try your sorting.
Also I made a mistake that lead to same user on the same cells, but the results were not worse.
I didn't finish 2 approaches. 1) recursion 2) shaking. This one as far as I remember gave good result in previous competitions.
Sorry If smth unclear
Look at equation (7) in the problem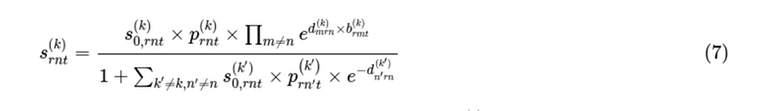 Broadly we want to make the s(r,n,t,k) values large, which means keeping the bottom line of equation (7) small, which suggests making the sum over (k!=k' and n!=n') zero.
Broadly we want to make the s(r,n,t,k) values large, which means keeping the bottom line of equation (7) small, which suggests making the sum over (k!=k' and n!=n') zero.
For every pair (r,t) I choose non-zero p(n,k) values so that either all the n are constant and k varies, or the k are constant and n varies.
Some frames are small. For these we can look for a few p(n,k) (varying n, fixed k) so that several frames are handled by a single (r,t) pair.
Some frames are larger. These require several p(n,k) (fixed n, varying k), and sometimes several (r,t) pairs to allocate enough transmitted bits.
So roughly my algorithm became a greedy approach in 3 steps:
I never managed any form of iterative hill climbing. Once power is allocated to a frame it is never removed.
My scores per test case are shown below. Many frames in test cases #33 and #38 are not sent.
Test cases #33 and #38 all have frames time length 1, so the problem might be solved as T independent small problems which might have an exhaustive search solution. Anybody made progress here?
Yeah, cases with dt = 1 are the most interesting. Comparing my scores with yours, I can assume that all other tests are solved almost optimally with a difference of magnitude of dozens of points. However, tests 21, 26, 33, and 38 are very different; most of the differences between the participants can be explained by these tasks, transferring the problem into an interesting yet distinct one. Let us see what the proportion in the final tests would be. About tests 33 and 38, you can read my post (approach three), and about tests 21 and 26, I'm very curious myself; I hope that some other participants will explain what worked in these cases. Thank you for gathering all the statistics, by the way. I had it in a quite disorganized format
My score is probably similar to yours,about #21 and #26, I only got 654/680points, and about #33 and #38, I got around 1100 points. maybe there is a significant differences in decision making which lead to this condition.
How do you see details of every test case?
You make submissions with the purpose of extracting information about the answer. For example, you could do
and run it a few times with bit=0,1,2,...
Better, is to allocate memory, though it takes care not to lose precision.
In this challenge, once you have the scoring function correctly implemented, you can adjust the power allocations for a solution to reduce the score and signal a number.
Thanks!
Nice post to share the information extraction! Very useful.
Like others, I used a greedy approach.
Look at each time step in order, and use a fixed list of $$$\delta p$$$ values.
For each time step, look at users $$$n$$$ who have live frames which have not yet been sent, repeat the following three greedy methods a number of times (depending on how much CPU time is left), and take the answer with the best score:
Scramble the ordering of $$$r$$$, $$$k$$$, and $$$n$$$, start with an empty time step, and loop over $$$r$$$, $$$\delta p$$$, $$$k$$$, and $$$n$$$, in that order; add each $$$(r, k, n, \delta p)$$$ if it increases the score.
Scramble the ordering of $$$r$$$, $$$k$$$, and $$$n$$$, start with an empty time step, and loop over $$$k$$$, $$$\delta p$$$, $$$r$$$, and $$$n$$$, in that order; add each $$$(r, k, n, \delta p)$$$ if it increases the score.
Scramble the ordering of $$$r$$$, $$$k$$$, and $$$n$$$, start with an empty time step, and do the following twice: loop over $$$r$$$ and $$$k$$$ and for each $$$(r, k)$$$, consider all $$$(n, \delta p)$$$, and add the $$$(r, k, n, \delta p)$$$ which makes a maximum increase to the score, if any exists.
While doing the greedy loops, I used an approximation for $$$f(x,n):=n \log(1 + x^{1/n})$$$.
Someone asked for my code, so I'm providing sample code in this comment. This is not my contest submission, but it illustrates the approach I used. I have disabled the second greedy method listed above, but it's still visible in the code.
When will the system test take place?
a few days later
Update: Oh Sorry it's not!
Here is a graph of the first few scores on the leaderboard (before final testing.)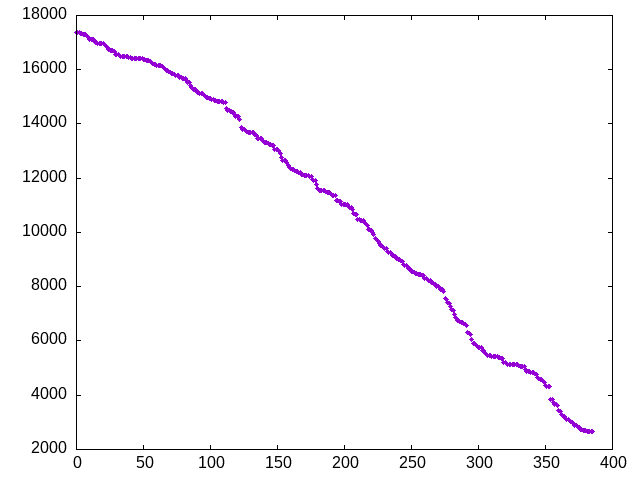
I updated the graph to show the first few scores on the leaderboard on the final data set (green curve) as well as the preliminary data set (purple curve.)
Here is the correlation between the two scores, showing the preliminary score on the X axis and the final score on the Y axis. This graph only shows points which come from scores which were present on both the purple and green curves above.
While we are all waiting for the system tests, I want to write my postmortem.
I'm a big fan of Huawei contests and already have some achievements, but I have never before seriously competed for first place. It was an exciting experience to search for the decisive optimization at 5 o'clock, having the exact same result as two other competitors a couple of hours before the end of the contest. It was a great joy to participate, independent of the final result. But I'm going too fast; let us start from the very beginning...
A small disclaimer: I have never written a serious postmortem before and am not particularly skilled in it. Anyway, I hope that some of you will find some of my ideas meaningful or at least useful. As I believe that such contests should be tried by more competitors apart from sharing ideas for this exact problem, I will try to give some broader advice so this post can be used as an introduction to heuristic contests in general. The small disclaimer is clearly too big, so let us finally start.
All right, so we looked at the task for an hour, trying to figure out what to do and realize what this formula meant. Truly saying I needed way more than an hour for that, which is rather normal for such contests. The first thing to do after that is to start doing something — this is not the kind of task that can be solved with just pen and paper. However, the formula disturbs me very much; just the realization that it will take considerable time. All right, to start, we need to make a reasonable simplification and take a subcase that seems meaningful but still ignores most of the formula. The strangest part of the formula is the exponents and the denominator of the fraction; I spent over an hour trying to understand its behavior, got not too much, and decided just to ignore it. To do so, let us say that the whole frequency at each moment of time belongs just to one user, and then the fraction consists of only the transition rate multiplied by the provided power. Having done that, we can apply the most common method in such tasks — the greedy algorithm. Let us consider the tasks in the "growing" order (there are multiple ways to make a reasonable comparator, but just sorting by size works quite well) and put them greedily on units (unit is a pair of frequency and time) — just calculate for each unit, how much it can transmit and go one by one, till the task will not be fully transmitted. There is indeed some interference due to the geometrical mean, so the resulting transmission is not just a sum, but actually, it is quite a good approximation. Before making exact thoughts about how efficient the assumption is, it is almost always better to implement it quickly and see what happens. Important remark — in such contests, you should not try to write code as quickly as possible; there is a lot of time; what matters much more is to write a bag-free code and also make it as flexible as possible for future ideas. All right, so if you have done it properly, you get around 13.5k thousand, which was top-1 on the first day and around 130th place at the end of the contest. A reasonable optimization would also be to use less power for the final unit — just make a binary search and find how much power would be exactly enough to transmit the task and leave more power to the further ones.
The obvious problem with this assumption is the overuse of space for very small tasks. If you have many more tasks than units, the previous method can clearly not help too much. So, we should consider putting multiple small tasks in one unit. There are two essentially different ways of doing that — distribute subunits between the tasks (subunit is one server with one frequency at a particular point in time), then you have an easy numerator as in the previous case, but probably a big denominator or you can put all the tasks on one subunit, then the denominator would be just one, but the numerator gets smaller. The general strategy is again to simplify the formula in a different meaningful way. But pretty much brute force, you can just check all the pairs of tasks and try to put them in a unit. If it works — perfect, try to add a third, fourth, and so on. With a little bit of time optimization, you quickly get to 15-15.5k, which was top-1 for the first 3 or 4 days and is around the 100th place currently. Again — do not overthink; just see the problem (many small tasks) and implement the most obvious solution — put small tasks together.
Having made these first approximations, one can spend a lot of time improving it, searching for better comparators, or combining a couple of them. However, one can quickly realize that this has very limited potential — 100-200 points, I will assume. In fact, it is one of the major skills in heuristic contests to estimate how much you can have from the optimization, where it makes sense to spend hours or even days on the improvement, and then you should leave the idea after just a couple of attempts. This can be normally seen by the speed of the improvement you are getting. If you have +100 points just by tuning the constants, there is probably a lot there, and you should focus more on it. If you made a reasonable optimization and got just a couple of points or none at all, it means that you either have a wrong intuition for what works in the problem and should work hard on the improvement of intuition or (and it happens more frequently) you took all form this idea and even very smart ideas of its improvement will not bring you much. If you lose a thousand points on a single test, you should probably not focus too much on 10 or 20 points on the other tests. To find this information, do not forget that it is absolutely fine and even encouraged to extract some information from the tests, especially if some tests are openly shared. The way I did it was using the memory. We know the amount of memory used with the step of 1 megabyte, so you can easily send a number between 1-100 for sure. By that, you can, for example, find out how many tasks are not transmitted by the solution, and it turns out that there are two extremely big tests — 33 and 38, where neither of the strategies gives any reasonable points. So, the number of points missing on each of these tests is higher than the sum of the missing points on all of the other tests in general. Some further analysis shows that all the td on these tests are one, and the ds are very small, around -0.1, indicating a low interference of different users. After getting this information, it was time to take a break and think about what was missing in the strategies so far.
I was thinking about many different complex approaches, but as it frequently happens in such contests, the idea is rather simple. If the interference is small, it is very useful to have many tasks in the "numerator" and no tasks in the "denominator", so we take a group of tasks and choose one server for each frequency. The only question is how to take groups of tasks and choose servers, and the most reasonable answer is simple — "random". Any reasonable implementation quickly gives you a score of 16k+, which is around place 60 — the third price. This is also the case where just a small increase in the number of random samples or the quality of the random immediately gives a hundred points. By optimizing the time efficiency of everything (very quick input with strings, precalculation of powers, global variables, and vectors), I achieved around 400 repetitions for each moment of time and the size of the set of tasks, which seems to be the border, where the further optimization does not bring much. However, this moment lies pretty far, and for me, around 1330 points on these tests — an improvement of almost 1600 points in 2 tests and the result of around 16.9k and a solid second prize. Still, I did not give up on improving my results on these tests — in general, I spent around five days just on these two tests alone, and I guess it was a huge factor in the resulting preliminary placing. A good idea was to exclude very small tasks from some of the subunits to decrease the interference factor for big tasks. This allowed me to get around 1380 points on these tasks and a score of over 17k, top-1 just a couple of days ago, and around top-15 at the end of the contest.
No matter how important these particular tests were, it is important not to miss a time to stop and think about other smaller but not that well-optimized cases. The last important breakthrough was to combine all the strategies together, just going through the time steps one by one and trying to put as many tasks as possible with all the strategies above, choosing the best combination and adding control for the given time, using exactly as many random steps as it was possible not to get TL. After some trial and error, this solution got something between 17.1-17.2k, which is somewhere between the first and second prizes currently.
Apart from these main ideas, there were many small ones — in such contests, good realization and proper choice of the local problems to be solved is significantly more important than exact ideas, which can be seen through different approaches, still very similar results in many of the contests and especially in this one, where 3 participants were exactly tied for the first place just 3 hours before the end of the contest. To choose which ideas to implement, it is important to make some small experiments, realize a small but meaningful part, and see whether improvement is present and also improve your intuition of the problem. Ideas that do not work are not less important for understanding than the ones that work. For example, in this problem, no ideas, analyzing different orders of time or order of subunits worked; also, making more than 500 random guesses never helped, so I did not try to improve efficiency further (such results can be obtained by running the code on the first ten time slots and different number of random generations). It seems that the users have rather similar connections to all of the servers at all times, so the orders do not matter. I still spent a couple of hours on the ideas, which turned out to be useless, but in contrast to my previous contests, I was able to stop investing time in them and concentrate on ideas with a high potential.
Here are some smaller ideas that worked:
1) Try different comparators for the order of added tasks in the first method; take the best of them. Random shuffling and even reversing the order helps in some small cases. This gives up to +50 points.
2) If a task can be transmitted with the higher energy of one server but fewer servers — you should rather do it. Another +20-30 points.
3) Taking tasks by the second method, try to take tasks with the higher sizes if the number of the tasks is equal, it gives a better packing, also +20-30 points.
4) If there are many tasks that need just one unit, we have an optimal method of packing — kunh algorithm. Try to apply it and not just the greed algorithm — +10-15 points because these tests were small and solved well anyway.
5) With a small task, try not to close a cluster — all frequencies at one moment of time, leave it to a big task — +10 points
I will leave apart all the optimizations, which were taking place the last night, where every single point was very valuable; I think I am more than enough already :)
If you have any questions concerning my solution, the task, or heuristic contests in general, ask them, and I will do my best to answer them. I'm also very interested in the other approaches; from a brief chat with other participants after the contest, I realized that the focus of some other participants was on the other tests, and by a combination of approaches, another much better result can be born, so looking forward to other post-mortems.
Sorry if I'm repeating obvious things or going too fast and for inaccuracies in English — the night was pretty wild for me :) Thank you to the organizers and the other participants; I'm looking forward to the next contest. Good luck with the final tests for everybody!
P.S. The final results are there; I got second place with 17326.867 points. Congrats to the winner!
P.P.S. Now, I'm looking forward to combining my solution with other participants to get a more solid result. Let me know, if you wish to contribute to this process
Wow. Thank you very much for sharing so throughly. And congratulations!
Congratulations on your grades, thanks a lot for your postmortem that helps me to rejudge my strategy
Congratulations! Thanks for the detailed explanation! The way to extract test cases are pretty useful. It is really helpful to see all those strategies.
The contest was truly enjoyable even though I could participate on last few days. These type of contests are rare in CodeForces, but I like it. At last I got 16.4k points in pretests, but instead of it (if you'd like, I can also write), as at a first glance the problem seems complicated, I'd share a simple and dolce solution that may get into prize zone :)
Solution 1:
and reach top 1% of registrants. Intuition is the best thing I can believe.Solution 2:
maybe you are right, it is easy to just get a T-shirt with some simple algorithm
start systests pls
Nice contest, funny how simple greedy algorithms can earn you as much as top 200. My overthought idea barely has 11.4k after a lot of time spent. Also when systest usually happens after those contests?
My approach: link
Includes code, provisional data stats and results from my last submit
https://en.wikipedia.org/wiki/Simulated_annealing
using not very accurate checker( but fast), you can get 5000+ points
To be fair, you can achieve about 6k without using any checker at all by just giving each person some bandwidth that doesn't exceed the limit.
I also used simulated annealing to optimize. It can achive a pretty good score if it is allowed to run about 20s. For example, it can achieve 700+ frames on test case 21. But the time limit is the problem so only few steps are able to run.
you know, i was shocked knowing getting 6k+ is so easy
Yeah, I think simulated annealing is easy to implement but time consuming. Next time I would definitely try this first before implementing those deterministic algorithm, because the results from this random optimization can give me some hints. It is good for some analysis.
My solution used a very dumb greedy without even checking anything nor using any techniques and it got 8300
I sort frames by the TBS then for the first R frames assign a unique RBG and TTI and a random power and keep repeating this and for the remaining J — R frames just assign anything xD
Agree that getting a t-shirt was not that hard, easier than I personally expected (good! :) ). I approached it with heavy simplifications:
(1) all stations in a specific TTI do the same thing (like a single station) and
(2) ignore frequency dependency (e.g. all RGBs behave identically).
In this scenario, I used a greedy allocation based on the approach "take the easiest frame and try to allocate it, prioritizing the TTIs with a criteria that balances volume you can transit in it (as a plus) and overall need for that TTI (as a minus)". With my surprise, given the simplifications and the greedy strategy, that led to 13.7K, that on Friday night was stably in t-shirt zone (like 110th or so).
In the last few hours, I added a second step trying to stuff the remaining frames into the t/r slots already taken, overlapping at most 2 users, starting with the easiest frames still to allocate, and with the slots belonging to already allocated frames with most wasted resources. This improved to 14.4K. But I realized just now a big mistake in this second step (it was 4am...), i.e. not freeing the resources when an allocation attempt fails. So maybe it could have gone a bit further.
Thank you for the interesting challenge! (Huawei and Mike&staff).
For those interested, there is a simple greedy approach that instantly gives 13600+ points.
The base idea is to assign every $$$(t, r)$$$ to a single user $$$n^*$$$ (or frame $$$j$$$) and fill all those $$$p^k_{rn^*t}$$$ with 1. This avoids all interference.
We choose which $$$(t, r)$$$ to assign first by calculating $$$score(t, r, n) = \sum_k \log(1 + s_{0,rnt}^k)$$$, sort all $$$(t, r, n)$$$'s by their $$$score(t, r, n)/tbs_j$$$ and greedily assign $$$(t,r)\to n$$$ using highest first. If the $$$(t,r)$$$ was already assigned, skip it. If the frame is already filled, ignore that $$$(t,r)$$$.
Doing only that gives the score I said above. There are some small adjustments like choosing an incomplete frame, removing all of its power, and trying to fill another incomplete frame, but it probably gives 20+ points.
For me the key to getting good scores (16K+) easily was simplifying problem a bit. If you don't allow the second type of interference, the complicated SINR expression becomes much more approachable:
I am pretty curious about how to see the interference on nominator is smaller than that on denominator. Because I think the nominator is a multiplication which could be large if there are several users in the same unit. And the denominator is just a sum. Is it because the $$$s_{0,rnt}^{(k)}$$$ term in denominator makes it large?
You are right. most of times $$$s^{(k)}_{0,rnt}*p^{(k)}_{0,rnt}*e^{-d^{(k)}_{mrn}}$$$ is much larger than 1 and ruins the value of $$$s^{(k)}_{rnt}$$$ ,and the nominator 's multiplication is easier to control.You can choose those very small interference (e.g. >-0.1) and $$$s^{(k)}_{rnt}$$$ will not decrease that much.
Same Idea with you. I tried not allowed both types of interference at first and get 11k.Then I tried not allowed the second type of interference and get 13k. I think accept the first type of interference is better than accept the second one. But I can't go further if I just throw the second type of interference away. I find it much harder to handle and give up at day 9. I'm curious about how to go further when an "seems optimal" strategy can already gives 13k points.
Congrats on your good grades!
What’s happened with scores?
they just did the system testing, this should be the final scores
I know there never was any upsolving for Huawei challenges and I could understand the reasons why, but could you at least disclose the rest of preliminary tests so the users could try to make some more experiments on their own with possibility to compare progress against provisional leaderboard?
And thanks again for the challenge!
CC: ICPCNews HuaweiChallenge
The system tests has been performed. The standings are finalized.
so when will I get the T-shirt & money and how? is there any post that write about it?
I'm really bad at this
I used a mathematical methods to allocate the accurate power, it works well and fast on many cases except frame-intensive cases like #33, #38
1 On each tti, I sort all frames by weight = (remaining TBS) * (remaining tti) / (approximate bits in this tti) in ascending order
2 Then I try to put the frames into the current tti one by one. For any frame:
2.1 I give the same power x[k] to different RBGs below CELL[k], cuz when all x equals, the geometric mean Π(x)^1/n is maximum, SINR does not matter
2.2 Determine x[k] for each CELL via conditional extremum, suppose using all RBGs, then
min z = Σ(x[k]) log2(1 + c[1]*x[1]) + ... + log2(1 + c[K]*x[K]) = TBS/W/R, c[k] = Π{SINR[k][r]|1<=r<=R}^1/RBy this we can get the accurate power for each cell to reach the TBS of a frame, while reducing the total power to minimum. Lagrange multiplier can solve this
I didn't make a good job on #33 and #38, only 900+ each. I use brute force with greedy to get a lot of possible combinations expressed as (CELL, RBG, j1,...,jn), then I find the max independent set of all tuples. I think if I allowed different frames into different units of same RBG, it would be better.
Looks like plagiarism detection is going on right now. Good to know. What would be the desired way to report some suspicious submissions/users?
CC: ICPCNews HuaweiChallenge MikeMirzayanov geranazavr555
It seems that timing is not ideal on the platform.
A common concomitant of optimization contests is that the result is not produced by a finite algorithm, but rather tries to improve it continuously, in each iteration. In such cases, we are compelled to measure the time so as not to run to TLE. And here a problem comes: we mostly can measure the wall time, while the system measures the CPU time, which are roughly the same in most cases, but in rare cases the two can differ to an extreme rate. Unfortunately, I ran into such a problem during the system test.
System test:
Practice submission with exactly same code:
The early return was worth 400+ points and a prize category for me.
It is not a unique problem, as far as I know other competitors also experienced this. It would be fair if Codeforces could do something about this, so that it would not happen again.
CC: MikeMirzayanov geranazavr555
How are you measuring time?
My experience is that using clock() and CLOCKS_PER_SEC has been quite reliable, but perhaps I have been lucky.
I have used this on many contests on different platforms and it has always worked.
This is a known problem, I noticed the same during the competition as my solution was based on trying random changes, if the time was not correctly measured I would get considerably lower scores from time to time and I was concerned for the reliability of my code on system test. At the end I was able to fix this on the last few days of the contest using the following solution https://mirror.codeforces.com/blog/entry/85677?#comment-734421.
Using only clock() / CLOCKS_PER_SEC does not fix the problem on all compilers. You can read the post above for more information.
This is a helpful hint, thank you for sharing. Psyho implemented the same idea. As those optimization contest are a more or less regular thing now (hooray!), I would still appreciate, if the underlying problem could be addressed for two reasons: first of all, not every contestant will find this information, causing an inequality between them. Coming from other platforms (Codingame and Topcoder mostly), it would never even have occurred to me, to measure time in a different way. In addition, that's a C++ solution. I think I can make that logic work in C#, although painful to code under Linux. But for other languages it can be a challenge to implement.
hi, guys!
i finished 7th this time. Finally got some time to make a presentation about my approach. you can find it here
Hi, everyone! It's my first time participating in HUAWEI ICPC Online Chanllenge, is there anything i need to prepare before getting the winner prize, excpet for filling in the "ICPC winners form" ? And What's the date I can receive the prize? Thanks for your help!
ヽ(・∀・)ノ How soon will I be contacted to receive my cash prize? I am so excited. This is my first such award, and not some diplomas and certificates. I'm very sad that you don't answer
First of all: just lean back and wait. Huawei will contact you on their own with detailed instructions. I've never had any issues to claim the prize (except for the t-shirt: depending on where you live, customs might just send it back. At least German customs likes doing exactly that). Last time the prize was in my bank account 2 months after the contest ended.
To answer Kyte's question: You will receive a document, that you have to print, sign, scan, send back via email. There you again confirm to give them permission to use your code. The prize will even be a bit higher to account for taxes that Huawei pays on your behalf. This form also asks you for your passport number (at least did so in the past, I don't want to be responsible for you getting a passport that you don't need). If you don't have one, Huawei will wait until you do. Furthermore you have to register as a supplier on some Huawei website and enter your bank account. Confirm that with another round of print-sign-scan-upload. This step can be skipped, if you already have a supplier account.
Thanks!
When will Huawei 2024 Spring Online Challenge be held ? I have seen one blog and it said it will be held on Jan 12 ,2024. But that blog seems to be deleted. Should I just wait now maybe?
Here is the blog about delayed start: https://mirror.codeforces.com/blog/entry/124031
I received a reward notification email, but it says it is encrypted. How can I open it? The email content is as follows.
This message is protected with Microsoft Information Protection. You can open it using Microsoft Outlook, available for iOS, Android, Windows, and Mac OS. Get Outlook for your device here: https://aka.ms/protectedmessage. Microsoft Information Protection allows you to ensure your emails can't be copied or forwarded without your permission. Learn more at https://aka.ms/cp_rms.
I'm facing this problem too. I install the app on "https://aka.ms/protectedmessage" and enter, it needs me to enter my account. After I enter my account, it shows me that "User account 'XXX@XX.com' is a personal Microsoft account. Personal Microsoft accounts are not supported for this application unless explicitly invited to an organization. Try signing out and signing back in with an organizational account. "
Same question. I can't open it even using outlook.
I've received new reward notification email from huawei and they solve this problem
Hi. I noticed notification email just yesterday. When clicking the activation link, website says link expired. Could you please help with? Thank you
Sorry for necroposting, just to be sure it is not a problem of mine: did anybody receive the t-shirt yet?
Thank you for your question! There were some issues with the t-shirt sizes, and those have now been resolved. The t-shirt prizes are in production and distribution, and will be sent shortly. We appreciate your patience. Thanks Again!
Hello, may I ask have the T-shirts distributed yet? Thanks!
Any updates? you are about to start a new competition, it is weird to start a new edition 6 months later without distributing the prizes of the previous edition.
We understand the problem Our friends at Huawei were having some distribution challenges (pardon the pun). The T-shirts are coming. Unfortunate delays.
It's been a month since this reply and two months since you said that issues were solved and prizes were in production and distribution. Tomorrow a new edition is starting, any updates? should we stop expecting to receive the prices from this edition (and potentially Tomorrow's edition)?
Just be patient. I receive my T-shirt today :) . I believe that you will receive your prize soon.