


Hi everyone!
As some of you may know, on this summer camp in Petrozavodsk droptable presented a new data structure, palindromic tree. I had the honor to participate in the study of the structure for the six months before that, and I want to tell about it now :)
But firstly a brief explanation. If you alredy know basic ideas of the structure, you may go to the interest part. Let's to each palindrome assign corresponding string equal to its right half, i.e., its radius and the boolean variable indicating its parity. Now let's merge all our radii of subpalindromes of string S in two prefix trees for even and odd lengths separately. Claim: such trie will be 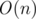 in memory. Indeed, there can be no more than n distinct subpalindromes in the string, and each node in trie corresponds with only one unique palindrome. Therefore, we have no more than n + 2 nodes.
in memory. Indeed, there can be no more than n distinct subpalindromes in the string, and each node in trie corresponds with only one unique palindrome. Therefore, we have no more than n + 2 nodes.
Let's show that such structure can be constructed in 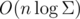 . Let each vertex in the tree store suffix link that leads to the node that corresponds to the radius of maximum suffix palindrome of the whole palindrome of current node. For example, there is a vertex corresponding to the radius "bacaba" with odd length, i.e., to the palindrome "abacabacaba". Suffix link will lead in the node corresponding to the radius of maximum suffix palindrome "abacaba", i.e., "caba".
. Let each vertex in the tree store suffix link that leads to the node that corresponds to the radius of maximum suffix palindrome of the whole palindrome of current node. For example, there is a vertex corresponding to the radius "bacaba" with odd length, i.e., to the palindrome "abacabacaba". Suffix link will lead in the node corresponding to the radius of maximum suffix palindrome "abacaba", i.e., "caba".
Now let us assume that we have a palindromic tree for a string S and we want to add to the end of the string some character. We will maintain a pointer to the node corresponding to the maximum suffix-palindrome of string on every step. Further actions are similar to those in the construction of suffix automaton. We are look at the new character in the string and at the one that stands in a string before palindrome, which corresponds to the current state. If they do not match, then let's go by the suffix link and repeat the check. When they match, we look at whether there is an edge to the new character in the node. If yes, then move along the edge and enjoy, if not palindrome that we should add was not in a string before. So, let's create for it a new node. Now we need to find for it suffix link. Well, let's go by the suffix links again until you find the correct position in a second time for the same symbol. When we found it — this is the suffix link to a new node. That's all. Now we have an algorithm that works amortized in , since at each stage we firstly several times reducing our current string, and then increase it by only one character. And obviously there will be no more erases than inserts (which are no more than n).
And yes, a few words about the implementation. You may have noticed that I do not consider the case when occurs the loss outside of the tree. This is due to the fact that such a loss never occurs :). How to achieve this & mdash; since we have two tries, we have two roots. For one of them let's make an initial length 0 (for even palindromes), and for the second — -1 (respectively for odd). And by default let's do a suffix link from the first one to the second. Thus, every time we are at the root with the length of -1, we always find that the extension is possible, as the new symbol and the symbol before the suffix-palindrome are the same in this case.
Code: link
Written by me as the most similar to the suffix automaton for the purpose of easier memorization :). There is also great implementation from Merkurev link.
Now I will talk about how it happened that I was involved in the preparation of the problem for Petrozavodsk camp. In the comments to my article about the Manacher's algorithm droptable wrote about the online version of the algorithm and asked to add it to the article, which I did, after some discussion. Just then Michael told me about the problem from the APIO, which, in an amazing coincidence, was held at the same time. Brief statement: find refrain-palindrome in the given string.
Then Mikhail hinted that they have a cool structure that quickly and easily solves that problem. Since I was young and inexperienced and still wasn't familiar with the hard suffix structures, I decided to think about that kind of constructive alternative solution. So I'm somewhat reinvented palindromic tree :) In fact, I was very far from the solution, because I did not use the suffix links, and wanted to build it with hashes, but nevertheless I came up with the general structure. And when I told about my tree Mikhail it turned out that it is exactly the structure he told about earlier :)
Furthermore, it was a lot of productive discussion, the results of which I would like to share. For example, I figured out a way to build a tree in 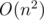 , which, however, in practice is faster than many algorithms with other structures that work in . The idea was similar to an online Manacher's algorithm & mdash; let's store in each item of the array the pointer to the vertex, which corresponds to the maximum palindrome centered at this item. Further, when calculated palindrome in the new cell, we take either vertex from symmetric to the center of maximum suffix-palindrome cell or some of its ancestor with less length, if it "climbs" over the current end of the string. Initially, it seemed to me that the solution will be linear even if you just go up to the correct level every time, but it turned out that it is not :(
, which, however, in practice is faster than many algorithms with other structures that work in . The idea was similar to an online Manacher's algorithm & mdash; let's store in each item of the array the pointer to the vertex, which corresponds to the maximum palindrome centered at this item. Further, when calculated palindrome in the new cell, we take either vertex from symmetric to the center of maximum suffix-palindrome cell or some of its ancestor with less length, if it "climbs" over the current end of the string. Initially, it seemed to me that the solution will be linear even if you just go up to the correct level every time, but it turned out that it is not :(
Using the technique of binary expansion, I was able to reduce time to 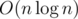 . Also there are algorithms for finding LA (Level Ancestor) in
. Also there are algorithms for finding LA (Level Ancestor) in 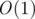 , which would solve this problem in
, which would solve this problem in 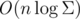 , but, obviously, it would be unreasonable because of the complexity of algorithm. So...
, but, obviously, it would be unreasonable because of the complexity of algorithm. So...
challenge 1: Can you improve the idea of this algorithm to the , without using common methods of solving LA problem?
 :
: Oddly enough, it's not all what I wanted to tell about. In the original version of the problem, which was planned to be at Petrozavodsk one had to not only add character to the end of string and count the number of new palindromes, but also to delete the character from the end of the string. Later, this part has been removed since problem was already complicated enough. Now I would like to describe the possible algorithms for the solution of the task, which was to be originally.
Firstly let's understand & mdash; what is a problem for us? It seems that we have everything to solve the problem, why wouldn't we just do a rollback to the previous state? However, this conclusion is false, because the evaluation of adding a new symbol 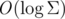 is amortized. And if we for example take a string aaaaaaa...aab, and then start each time to remove and return b. It is easy to see that at each step we will make iterations that is of course, unacceptable. Both methods, which will be described have the goal to make an appending of character with strict but not amortized complexity. So:
is amortized. And if we for example take a string aaaaaaa...aab, and then start each time to remove and return b. It is easy to see that at each step we will make iterations that is of course, unacceptable. Both methods, which will be described have the goal to make an appending of character with strict but not amortized complexity. So:
1) "Smart" suffix links. Let's at each vertex store additional suffix link that leads to the vertex, which have different preceding character in string as in the usual suffix link. Now we can use ordinary and "smart" suffix links in order to find the next state faster. According to Lemma 11 of droptable's Article (article not yet available, however, it has already been accepted for publication. Since it will soon be performing at this conference), the path to the root with "smart" links will pass through 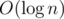 vertices. Thus, every time we will do no more than operations.
vertices. Thus, every time we will do no more than operations.
2) full automaton. Nor, for that matter, why do we bathe with complex theorems, and one link that takes you to a different character? Let's keep at each vertex array on 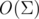 elements & mdash; one such link for each letter in the alphabet. It is easy to show that we can now answer the query in . Let us add to the string symbol 't'. It will be approximately like this:
elements & mdash; one such link for each letter in the alphabet. It is easy to show that we can now answer the query in . Let us add to the string symbol 't'. It will be approximately like this:
v = last
v = smartlink[v][t]
new = to[v][t]
v = smartlink[v][t]
suflink[new] = to[v][t]
smartlink[new] = smartlink[ suflink[new] ]
smartlink[new][p] = suflink[new]
Now we can solve the problem in 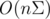 time and memory. Let's improve the result to
time and memory. Let's improve the result to 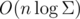 . For this we need persistent array. It can be constructed on the segment tree. So, we create a persistent segment tree with Σ elements. Next, let's create a new vertex. We can fork in
. For this we need persistent array. It can be constructed on the segment tree. So, we create a persistent segment tree with Σ elements. Next, let's create a new vertex. We can fork in  desired root of the tree, and in
desired root of the tree, and in 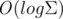 make a corresponding change. Here our quick structure is ready.
make a corresponding change. Here our quick structure is ready.
Challenge 2: Do you see other ways to solve this problem? For example, saving amortized evaluation with removal or other ways to solve the problem in less than 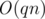 ?
?
For dessert, I want to offer you a work-out in the use of this structure and try to solve two problems. The first of them & mdash; is the same problem that was offered this summer at Petrozavodsk training camp, but with more serious constraints. By the way, only one team solved it. IMCS of Siberian FU Bizons with some terrible bitmask magic compressed in memory suffix automaton and passed it on the first try for three minutes before the end of the contest. Kudos to them and respect :). The second task is already quite old. It was presented for the first time at the winter training camp 2006, where the author's solution reduced the problem to LCA on prefix-function automaton. However...
We offer you to solve it in a slightly different interpretation, in which the author's solution, apparently, is not going to work. Imagine that you are given the first line is the line that should go to the second, and the second given is generator. You need to calculate the answer to each of its prefix. Dare :)
So, the problems:
timus. Palindromes and Super Abilities
e-olimp. Palindromic factory







A bit better (as I think) implementation of palindromic tree: YQX9jv
Also one more nice problem to solve with it: 17E - Palisection
17E — Palisection getting MLE using palindrome tree. This problem allow only 128 megabytes memory/
Change the to[MAXN][SIGMA] array to map<char, int> to[MAXN]. In such a way the memory will reduce.
That's not enough. In that problem one have to use vector<pair<int, int>> to[maxn]...
Can you write a brief introduction (for example, some best advantages of this structure)? Your post is too long. It took me much time to read the post without understanding what you are talking about.
To admistration: why don't you add this blog to main page? adamant is my bro and I think that is a great article!! (real story, I'm not an adamant)
http://mirror.codeforces.com/gym/100543/attachments — Problem G