


So, what's up with pow()?
Here at Codeforces it is quite common to see solutions that use pow() fail. Most recently this was the case in round #333 problem div2A. Whose fault is it?
Level 1 answer is that it is obviously the contestant's fault. The contestant should have been aware that pow operates on floating-point numbers and that there can be precision errors. If you expect that a floating-point variable contains an integer, you cannot just cast it to an int. The small precision errors mean that your nice round 100 can actually be stored as 100.00000001 (in which case the typecast to an int still works), but it can also be stored as 99.99999999 (in which case the typecast will produce a 99).
You cannot even expect any kinds of deterministic behavior. For example, consider the following short program:
#include <bits/stdc++.h>
using namespace std;
int main () {
printf("%d\n", (int)pow(10,2));
for (int j=0; j<3; ++j) printf("%d\n", (int)pow(10,j));
}
This code computes 10^2, 10^0, 10^1, and again 10^2. What is its output when using the current g++ version at Codeforces? 100, 1, 10, 99. Fun fun fun :)
For extra fun, change the initialization in the cycle to int j=2. The new output: 100, 100 :)
So, what should you do? Be scared and avoid pow() completely? Nah. Just be aware that precision errors may occur. Instead of truncating the value inside the variable, round it to the nearest integer. See "man llround", for instance.
That being said, it's time for the...
Level 2 answer. Wait a moment. Why the f*#& should there be a precision error when I'm computing something as simple as 10^2? Ten squared is clearly 100. Shouldn't the value returned by pow() be as precise as possible? In this case, 100 can be represented exactly in a double. Why isn't the return value 100? Isn't the compiler violating any standards if my program computes 99.99999999 instead?
Well, kind of.
The standard that actually matters is the C++ standard. Regardless of which one you look into (be it the old one, C++11, or C++14), you will find that it actually never states anything about the required precision of operations such as exp(), log(), pow(), and many others. Nothing at all. (At least to the best of my knowledge.) So, technically, the compiler is still "correct", we cannot claim that it violates the C++ standard here.
However, there is another standard that should apply here: the international standard ISO/IEC/IEEE 60559:2011, previously known as the standard IEEE 754-2008. This is the standard for the floating point arithmetic. What does it say about the situation at hand?
The function pow() is one of about 50 functions that are recommended to be implemented in programming languages. Doing so is optional -- i.e., it is not required to conform to the standard.
However, if a language decides to implement these functions, the standard requires the following: A conforming function shall return results correctly rounded for the applicable rounding direction for all operands in its domain. The preferred quantum is language-defined.
In this particular case, this is violated. Thus, we can claim that the Codeforces g++ compiler's pow() implementation does not conform to the IEEE floating-point number standard.
Hence, if you failed a problem because of this issue, do blame the compiler a little. But regardless of that, in the future take precautions and don't trust anyone.







The solution of using llround seems not to work perfectly for me here. Example:
Output: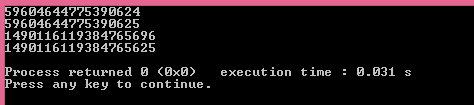
Infact the result for the second one is a lot different in 2 functions, 25**13
That one is OK. The problem here is a different one: that 25^12 cannot be represented exactly in a double. The set of possible values for a double is not a superset of possible values of a long long.
Cool, didn't knew that. This seems to be true. Using powl instead of pow shows correct output for both.
It's actually pretty obvious if you know how floating-point numbers work. A long long is 64 bits, a double is also 64 bits, but some of those are spent on the exponent. The mantissa of a double only has 52 bits (*).
80-bit long doubles use 64 of their bits to store the mantissa.
(*) plus a sign bit plus an implicitly stored bit, so actually the largest integer values that can be stored exactly in a double have about 54 bits.
powl() is good enough.I have got AC with that.
I wonder is it logical to try to hack a solution with pow() function or is it low probability to fail. If it is logical what should I do to hack it. Try to make the code run pow() function as much as possible or there is a trick case like big numbers ?
In this particular contest, one could hack a pow() solution by finding 2 numbers in different bases that should give the result "=". Preferably something large. That way, if one of the numbers becomes off-by-1 because of the pow() "bug", it will give a different result.
I think the judge is very sensitive to this, because my every hack attempt at that kind of solution worked (and I hacked like 7 solutions), so I don't think one can get away with it on "luck"
Don't forget to try your case at "custom invocation" first.
I don't get it.
powis adouble -> double, and there's no rounding inside the function. It's as precise as it can be. Rounding occurs after the function has returned its answer, and it's a separate issue. It would be an issue ifpowreturned anint, but it doesn't,As for the question "why isn't my hundred stored exactly": I would expect
powto approximately find sum of some infinite series, and that's (probably) why it fails even on small and simple numbers.I'm not sure what is the part you "don't get".
Obviously all these functions are evaluated numerically. It's usually way more complicated than just a simple sum of a Taylor series, but that is still a good visualization. (Newton iteration is a slightly better one because it tends to converge faster.)
However. Part of the problem here is that the floating-point standard requires conforming pow() implementations to be as precise as they can be, but this is clearly not the case in case of the implementation used by the Codeforces g++ compiler. Once again in other words: Codeforces pow is not as precise as it can be.
Regardless of what the precision of your internally computed result, it should never return 99.999999 if it is given the exact inputs 10 and 2. The value 100.0 can be represented in a double exactly, and it is closer to the exact answer -- because it is the exact answer.
In this area it's usually possible to prove stuff like "if I take any value x from this interval and I do three iterations of this numeric algorithm, I will get the result that is as precise as possible within the precision of doubles". (A very simple example of this would be: if I use binary search on the interval [1,2], after 100 iterations I can have the answer as precise as doubles allow.) I suspect that the pow() at codeforces sometimes does too few iterations / has some other similar implementational issue. Another possibility would be that it doesn't use a higher precision (80-bit floats) internally and that screws it up somehow.
It's certainly possible to implement pow() in a better way, as witnessed by the fact that it works on other platforms.
Ok, I have to admit that my picture was oversimplified and I have little to zero knowledge about how built-in functions are actually implemented, thanks for the info.
Can you share any literature on provably precise floating-point computations (I guess that's a different area than your common numerical analysis)?
I've just tried to debug your sample using OllyDbg and I've noticed that for
printf("%d\n", (int)pow(10,2));MinGW somehow precomputes the answer in compile time while forfor (int j=0; j<3; ++j) printf("%d\n", (int)pow(10,j));it actually calls thepow()function from legacymsvcrt.dll.It seems that MinGW takes the implementation of
pow()for compile-time optimization from some strange place...Thanks for the information :)
I have checked the same in g++ 5.2.1 on Kubuntu. It does also evaluate the first call to pow() at compile time, but it does obtain the correct value.
i think using function **__gnu_cxx::power()** provided in the header file ext/numeric is safer and much much faster with O(log(n)) complexity
Well, unless you need the special cases such as power(0,10^9) and power(1,10^9), the O(log n) doesn't really matter for powers of standard integers, as the largest valid n is used in power(2,63) for unsigned long longs.
But yeah, power() is in O(log n) and that is useful because it can also be used as follows:
That doesn't exactly violates "faster" word even if n <= 63 :D xD
"Hence, if you failed a problem because of this issue, do blame the compiler a little." If someone uses double->double function and casts it to int (not rounding) then I guess he is in no position to complain :P. Moreover I guess that cases when answer is of form nk (or if that power is somehow used to compute answer) and it is sufficiently small so that it can be kept in long long are pretty rare.
Not so rare. In CodeForces I saw tens of posts "why does my code get WA?" where the answer was "don't use built-in pow()".
I wonder that nobody mentioned
nearbyint()function (in C99 standard).I had exactly the same problem when I tried to solve 595B.
Instead of
int(pow( 10, k ))usenearbyint(pow( 10, k )).Here is an example of my solution which was fixed by using
nearbyint():http://mirror.codeforces.com/contest/595/submission/14169374
llround()was mentioned, and it does nearly the same, but returns the integer, unlikenearbyint(), which is usually preferable.so should I implement my own power function or just use ceil(pow()) when values are small.
Same thing with only basic operations:
First two numbers outputted can be different.