


Tomorrow (January 23rd) at 10:00 AM PST / 21:00 MSK there will be a second round of Facebook Hacker Cup. Don't miss!
I still don't know how to get to the dashboard from the official page (http://facebook.com/hackercup) through the links. Can somebody of the officials that spend time on CodeForces teach me how do I get there in deterministic manner? Maybe a video tutorial? Or maybe you can just make design compatible with human put the big link to it somewhere on the main page? After all, it is the most important link people want to see on the competition page :(
For those having the same headache with getting there, a link to the list of all rounds: link.
Let's discuss problems here.







"10:00 AM PST / 22:00 MSK"
Nice trick, but I'm sure it should be 21:00 MSK.
Hmm, looks like your are right. The first link that appeared to me when I googled "PST to MSK" tends to be incorrect showing Moscow time as UTC+4 :( Thanks!
It would also be better to have link to the dashboard in e-mail.
Also Top 200 will be advanced to round 3 and Top 500 will recieve an oficial T-shirt
Getting to the dashboard is part of the challenge. It's like a round 1.5.
We aim to always keep you on your toes.
I have a question about the rules. Is it fine to submit publicly available code authored by others? More specifically, I'm interested in code snippets from e-maxx.ru
Any code written before a round starts is fair game. I would treat it the same as codebook code.
Definitely nobody should be pointing people to public code during a round, since that constitutes communication which is disallowed. But certainly anything preexisting that you're aware of or discover for yourself during a round is OK.
If you have any concerns about any submissions, feel free to message me.
Round 2 link : https://www.facebook.com/hackercup/round/807323692699472/
This link always had current round dashboard acessible.
Yes, I'm also using it and I've provided it in the post body.
Oops, misread that
The past rounds page didn't have Round 2 when I posted the direct link.
But would you click on Instruction it'll get you there
Oh ok, I didn't know that!
Sad, wasted too much time on C. Only 30 mins left for A, and couldn't solve within time :. Was it greedy for A?
I wouldn't tell much before results are announced, but I did DP on it. DP asking how many times you need to recolour if you start from letter i.
C was difficult to code — especially that even small subtasks were problems in themselves (like calculating all pair square difference with N = 200,000), and I am still not good with quickly producing tree-structures :(
I don't know whether it is correct. But i think i did it in O(n log n) By storing sum, square and no of same height's found till now and by pruning incase a big height ladder came, all this within a map. Seems to work correct for all random test cases that i made
Edit: Its AC :D
True, you don't really need tree there. Should be faster to code.
I solved it using stack, it's easy to code.
Now I see that it works. S#$@ happens, sometimes the first idea is much more complex then needed. :(
Know that feel bro. :(
I also used stack . Though the hardest part for me was to find a way to calculate the sum of square of absolute difference of pair of integers from n numbers in less than O(n^2) time.
If you iterate over the middle split (the point that Jack & Jill never cross -- there is one), then it's greedy from that point outwards for both players -- once you encounter a difference you have to paint it over. However, you need to implement that fast enough, as it is O(N^2) naively.
273 full scores? I hope there's going to be a lot of fails.
UPD: 177. With an average 1 hour submission time for passing.
Do your part first :)
The (probably, correct, as I've compared it with some other contestants) solutions and the answers for all problems. In each directory 02 is a test, and 02.r is the answer for it.
Link.
So, what is the intended solution for D? It's not straightforward Min-Cost-Max-Flow for all O(nc2) transitions (which makes total running time O(nc5)), is it?
Hungarian algo instead of MCMF reults in O(nk4)
Sure, but there must be some better solution than applying MCMF while conducting dp.
First of all, it is O(nc4) because you shouldn't run a solution for an assignment problem if the degree of a vertex is larger than c (so the worst test is where there are n / c vertices of degree c, the running time will be O(nc4)).
Second, you can use Hungarian algorithm instead of min-cost flow. That makes the solution almost impossible to fail since I don't see a way to make the Hungarian algorithm antitest appear often by adjusting the input data in this problem.
Ok, so, no extra tricks — I had all these written. Looks like I've implemented both of them terribly bad. It takes about 10-15 seconds per test on my not-so-outdated PC. 8 cores still solve the problem, but it's not happy about that approach.
The expectation that my code will run slowly and borderline on time-limit failed me hard. I was waiting all 6 minutes for the output and because I was piping the output I didn't realize it was stuck even on 1st case, so I didn't notice the initialization bug which I couldn't find by manual tests in time.
Lesson learned: never pipe.
http://man7.org/linux/man-pages/man1/tee.1.html
You can pipe into
teecommand, like this:python solution.py | tee output.txt. You will see the output as it computes in the terminal, while it also will be written intooutput.txt.Because of this reason I always print the number of solved tests to stderr after each test.
So, again I had a 'passing' solution in my mind, but didn't write it because calculated complexity seemed quite high (well, even O(nc4) seems a lot).
MinCost Matchings and Flows don't stop to amuse me :)
Why nc2? You need only color of parent, and you need to solve odd and even vertex separately
0_0
How odd and even vertices are related to this problem?
Because odd and even vertices can be colored independently. By odd and even, I mean, if you 2-color the tree, odd vertices are the vertices of one color and even are the vertices of the other color.
Very cool! So the complexity of a solution becomes O(nc3), right?
I think that if the solution is optimized well enough, the complexity would be O(nk2): worst case is n / k vertices of degree k, each processed in O(k3) time. To process a vertex: first, use Hungarian algorithm to find an optimal assignment of colors to children in O(k3). Then, it is necessary, for each color, to find an assignment which doesn't use that color. To do this, start with an optimal assignment and remove the vertex which corresponds to that color. After that, one child may have no color assigned to it. In this case, it is necessary to find a single extending path, which can be done (I think) in O(k2) time, so the overall complexity of this step is also O(k3).
Yes, I always have trouble with the speed of assignment problems too. Luckily this time the testcases were small but my solution will fail if the testcase is 30 * max case.
What do you call max case? I've generated a test with T = 1 that is probably the worst for mine solution (it is called 43 in the archive I provided above), and it works in 0.1 on my laptop.
Edges between i+1 and i/30*30. My solution took 50s for this case, but I know my MCMF is terribly slow.
I've generated edges between i and i / 29 + 1 for all i >= 2. My laptop process both mine and your test 30 times in ~10s,
Could someone explain the idea behind D?
Standard tree DP — one choice for states is "edge, colours of its endpoints -> minimum cost for assigning the colours in the subtree of its lower endpoint" (can be optimised by processing odd and even vertices independently, so one of the colours doesn't matter), where you can always try paying P and summing up the minima of its sons, or avoid paying P — in which case you have the problem of assigning distinct colours to sons which minimise the sum of costs (computed by that DP). That's mincost maxflow and can be solved with Hungarian algorithm. See above for optimisations.
how to correctly get probability? without -nan(ind)
I used logarithms.
Define
P[n][k]as the probability to get exactlyk"heads" throwingncoins. Now if you can do a O(N2) DP like this: - ifn == 1,P[1][0] = 1-pandP[1][1] = p- else,P[n][k] = p * P[n-1][k-1] + (1-p) * P[n-1][k]The remaining part of the problem can be solved using linearity of expectations.
D was quite a bit of work, I submitted a few minutes before time but I doubt it's correct (edit: yay it passed). I used dynamic programming, where I had to do weighted matching multiple times in each vertex to get the answer. Did anyone have a nicer solution?
If you think that's hard to code, you must not have seen the "Gaussian elimination and matrix exponentiation inside a segment tree" stunts that they pulled last year. :P
How to solve problem B? We can use BigDecimal to calculate binomial coefficients and powers of p and (1-p) but it is too long (TLE).
You can calculate expressions of form C[n][k] = Cnkpk(1 - p)n - k using the recursive formula C[n][k] = C[n - 1][k - 1]p + C[n - 1][k](1 - p). This solution doesn't contain any divisions, so it won't lead to overflows.
I did this, but still worry about summing up big numbers with small numbers repeatedly. Maybe not an issue for 3,000 items.
I used logarithms (stored in
doublevariables).You can use dynamic programming, if P(A, B) is the probability of getting exactly A heads in B throws where 0 ≤ A ≤ B then:
Where $P(x, y) = 0$ if x > y or x < 0 or y < 0 etc.
According to the scoreboard, 273 people submitted all four problems. I wonder how many of them will actually get full score.
UPD: results are available, 177 people have full score.
No more than 272. :D
That was really horrible contest in fact. 3 goddamn simple problems, long double solution passed in B, "copy-paste from emaxx Hungarian algo" in straightforward D.
nah, even double works for B...
Almost forgot: O(n2) solution works for C.
Solution: http://pastebin.com/3Jxp0wbW
Works 2:30 on my laptop with 1 thread.
There are only 3 tests with n=200000, so no surprise.
That's the cost of changing rules in the middle of contest. Minus T-shirt. I finished 567th, and 100% sure that if rules weren't changed and only 560 people participated in Round 2, I would easily get in 500.
Agree it is fairer this way, but... changing rules in the middle of competition is not fair anyway.
Strange response from you guys. If you think that my statement is factually incorrect — it is correct, very easy to prove, if it's not obvious. If you are not happy that somebody was hurt by change in rules — sorry — might be a revelation — when somebody gains somebody loses. If you think that getting into 500 in Round 1 means less then getting into 500 in Round 2 — that's ok for you to think so. It's not about what you think it is about what rules are And rules were changed in the middle of the contests.
As I remember, Round 1 rules was changed before Round 1 started. Seems fair.
Besides that, you can't know what place you get in Round 1 if rules wasn't changed — I guess a lot of people solved no more tasks than they needed to proceed further according to new rules. So you could easily didn't pass to Round 2 at all.
I agree that on 22nd those people who were the strongest on 22nd won — no arguing about that. But below few top places there is actually lots of randomness involved, so modifying the rules does modify the end result.
Argument about a lot of people who decided to solve just 2 easy problems (1,2,3) or one hard problem in round 1 to get through — I don't buy it. Smallest quirk can kick you out of competition, why risking it? Even those people, who are absolutely sure that they don't have even a minimal mistake in their solution — for them it would take another 15 minutes to solve third problem "just in case". So I don't think there were more then a handful of people following that strategy (solving less then three problems, because that's enough to proceed).
Because the problems are not that interesting?
Why risk it? Because one doesn't care that much and doesn't have that much time/energy?
I was one of the "handful people" who followed that strategy. I figured that if I wouldn't be able to solve problem D in Round 1 flawlessly in one attempt, then I wouldn't be worthy of Round 2. Now I didn't participate in Round 2 anyway (because of lack of time and motivation), but still, the rules this year were way more balanced than last year.
Last year, you were more or less guaranteed to get a T-Shirt if you managed to qualify to Round 2, for which (largely) only time to verify thoroughly that your solutions in Round 1 were correct was needed. So if we want to reward people who can solve problems (quickly and often correctly), rather than people with a lot of time to spare, then a lower threshold in Round 1 is definitely the way to go. (And seriously, a Round 2 with about 600-700 something participants where 500, actually 550 last year, gets a T-Shirt, is not balanced in any way.)
I figured that if I wouldn't be able to solve problem D in Round 1 flawlessly in one attempt, then I wouldn't be worthy of Round 2.
That's a bit too harsh, mistakes happen. Just look at how many excellent contestants got eliminated in round 2 by having one problem fail. I have also seen red coders failing as much as 3 problems in the same round...
I failed D because I ran DFS from vertex 1 instead of 0 to test if the answer stays the same, then forgot to change it back. Then I had all cases correct except for the single-vertex case :c
It does mean less — in round 1 you passed on points, so if you wanted to pass you could just start the contest ~20 hours after it begun, do the first two problems and call it a day — which I assume a lot of people did. Now that your actual ranking matters, these people will start on time and do all the problems, so it makes sense that it's harder to get into the top 500.
Test cases on B may be weak; I passed by computing all binomials and powers of the probability, p. Of course, even though I stored these values in a long double, I would still expect precision problems to arise.
I think that before you go around claiming that the testcases are weak, you should find a testcase where long doubles actually are note precise enough. Saying the testcases are weak because you 'expect' them to be is a bit strange.
3000 choose 1500 exceeds the range of long double. Also I said testcases might be weak.
I don't see how the fact that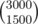 exceeds the range of a long double immediately guarantees that there exists some testcase where using long doubles causes a perturbation of 10 - 6 or more.
exceeds the range of a long double immediately guarantees that there exists some testcase where using long doubles causes a perturbation of 10 - 6 or more.
Also I'm sorry, I didn't see the may earlier.
I checked and it doesn't exceed long double on my machine.
I was going by these standards. Why would the range of long double vary from computer to computer?
Visual C++ thinks that
long doubleis same asdouble, GCC does not — it uses 80-bit double (as used internally by CPU). AFAIK, standard does not requirelong doubleto be really "long", just not shorter than double.Ok, classic T-shirt giveaway. First reply = free T-shirt.
jk i'm getting one
Well done. PM me your address please.
I meant I won one in the contest. I don't really want it, I just felt like being first (sorry). I like the Prodigy picture, by the way.
So it's still on, I guess?
A t-shirt in exchange for an address? Deftly done, Bruce Schneier.
++
Congratz, you know what to do next :)
first?
me
First
Internet Explorer ?
C was a nice problem, but the test input is weak... After the contest, I implemented a simple brute force solution and noticed that it solved the input in 3 minutes, because almost all test cases were small.
In Gym: 2016 Facebook Hacker Cup, Round 2
Tests in D have been splitted to contain at most 5 test cases.
Brutal round :( Solving at least 3 problems (including the last one) is needed to advance :'(
I implemented the intended idea for problem D, but my program only fits into 6min if I split it in 3 processes in a 5 year old computer. I only fixed a bug with 2 min left and the program didn't finish until the end of the contest.
I think the MCMF implementation I used is reasonably fast ( http://ideone.com/OREX0W ), I don't understand why the limits were so tight.
I think fastest MCMF is still much slower than Hungarian. My code runs in 20s in my laptop (~ 4 times faster than Codeforces).
I didn't have Hungarian code at hand, I will check it out!
You were right, I only had time to try using hungarian now and switching just my MCMF to Hungarian makes my program solve the input in 13s as opposed to several minutes. I didn't expect such a huge difference.
Well, you can speed up your solutions K times by noticing that you can actually split coloring vertexes with even and odd distances to root and thus eliminate one of the parameters — the color of current node.
Yeah, I've seen that idea in Egor's comment.
My 'complaint' is due to the editorial explaining the solution like I did with the current label as one of the state parameters.
Well, if you put it that way... Your code on my notebook runs in one and a half minute. And it can be further reduced by half a minute by replacing set with priority queue. And did you compile it with optimisations ? Without them it indeed runs in 7-8 minutes.
Yes, I use -O2. I picked this version from my library because it's shorter code and has been efficient enough for contests.
I didn't think my laptop was that slow. Ouch!
There was only 1666 participants in this round. why don't facebook use online judging system at least from this round on? It could help people like mogers.
It gives people the freedom to use whatever tools they prefer.
The context was about your slow laptop and I'm showing benefits of judging all participant's code with the same judging system. Nobody would feel unlucky then although writing correct solutions.
There are two main reasons Hacker Cup and GCJ use the run-the-code-yourself format:
1) People can use basically any language they want, and any libraries they want. This affords a lot of flexibility that encourages more participation.
2) We don't have to maintain a judging system. Ask MikeMirzayanov about running Codeforces. It's a ton of work. Hacker Cup and GCJ are side projects that exist largely as labours of love.
The main disadvantage of this format is that people have different hardware and different internet connections. We try to err on the side of giving more than sufficient time. For the problem in question, we have a judge solution in Java that runs in 6 seconds on a 3-year-old mid-level laptop. I think it does O(NK) passes of flow, and we have another solution with O(NK^2) passes of flow that takes about 30 seconds.
I just checked how my code would behave with EvenImage 's MCMF code. It solves the input data in 50s on my computer.
I would have qualified to Round3 with this. Lesson learned
MCMF can be used to solve weighted bipartite matching? Do you have any article about that? I thought Hungarian is the only way ?
Yes. Maximum Flow solves the unweighted version and MCMF the weighted one. The topcoder tutorial on MCMF explains this application.
I do not have any article, but here is the general idea.
You have a bipartite graph with costs assigned to the edges. Lets also assign capacity equal to 1 to all of this edges. Let's create two fictious vertices — source and sink. Connect source to all of the vertices of the left part of the graph using edges with capcity = 1, cost = 0. Connect all of the vertices of the right part to the sink using edges with capcity = 1, cost = 0. Find MCMF between source and sink.
All of the edges in this description are directed.
That's it.
Thank you both mogers and Fcdkbear, so, my understanding is we create a flow graph with capacity for each edge is one, and cost from left to right is the assignment cost, and cost from right to left is negative of assignment cost, then we run Dijkstra instead of normal BFS to calculate the MCMF, is that correct?
That's not completely right.
1) You've forgotten about source and sink vertices.
2) The capacity of reversed edges (edges from right to left in your terminology) should be zero (as in usual flow network)
3) You can't just run Dijkstra's algorithm, because it is not working with negative weights. Some people use some modifications of Dijkstra's algorithm. I usually use Bellman-Ford algorithm (it's implemetation based on queue) for this.
Yup, thank Fcdkbear, you clear all my doubts, thanks a lot :)
Oh no, I do C ALMOST correctly, just forget one last mod. However, even if I get that, I would still not be able to get a T-shirt (around rank 560 if C was correct). This year there are too many contestants (and too many excellent contestants), I read that last year you just need 1 problem to be in top 500.
Anyway, great problems, and great experience :D
Damn. I totally forgot about hackercup. I wish they would send a mail 3-4 hours before the round start :(
Did anybody receive their tshirt yet?
Still no one ?
Australia has it by now so I can only conclude you live on the moon.
I've got it about two months ago, maybe you should check with wjomlex