


→ Pay attention
→ Top rated
| # | User | Rating |
|---|---|---|
| 1 | Benq | 3792 |
| 2 | VivaciousAubergine | 3647 |
| 3 | Kevin114514 | 3611 |
| 4 | jiangly | 3583 |
| 5 | strapple | 3515 |
| 6 | tourist | 3470 |
| 7 | dXqwq | 3436 |
| 8 | Radewoosh | 3415 |
| 9 | Otomachi_Una | 3413 |
| 10 | Um_nik | 3376 |
→ Top contributors
| # | User | Contrib. |
|---|---|---|
| 1 | Qingyu | 162 |
| 2 | adamant | 150 |
| 3 | Um_nik | 146 |
| 4 | Dominater069 | 144 |
| 5 | errorgorn | 141 |
| 6 | cry | 139 |
| 7 | Proof_by_QED | 136 |
| 8 | YuukiS | 135 |
| 9 | chromate00 | 134 |
| 9 | TheScrasse | 134 |
→ Find user
→ Recent actions





Codeforces (c) Copyright 2010-2026 Mike Mirzayanov
The only programming contests Web 2.0 platform
Server time: May/12/2026 11:34:27 (h1).
Desktop version, switch to mobile version.
Supported by

Can someone explain Ques B when the string contains '*' .
Thank You!
if string(Say "str") contains '*' then it means that we can replace this '*' by another string(say "child_str") of any length (possibly 0). And this "child_str" must contain only bad characters(if it is not empty).
Assuming it is possible to replace every '?' in "str" by a good character(because if it is not possible than answer is "NO") which is equal to the character at the corresponding position in query string, If you are able to form some child_str such that both the strings become equal then answer is "YES."
Has anyone written a solution for D with
O(N + Q)complexity?Sparse table works in O(n log n + q). How can D be solved in O(n + q)?
Hmm, links works strange...
Check Topcoder(https://www.topcoder.com/community/data-science/data-science-tutorials/range-minimum-query-and-lowest-common-ancestor/#A%20O(N),%20O(1)%20algorithm%20for%20the%20restricted%20RMQ)
Oh, forgot about it, thanks.
Simply Farach-Colton and Bender algorithm :)
Or we can go offline and get O((n + q)α(n)) by Tarjan's algorithm.
Could you please provide further explanation for E or point out similar problems or tutorials for the required background?
It's just the basics of linear algebra. You can find it everywhere.
link?
https://en.wikipedia.org/wiki/Gaussian_elimination
About Gaussian_elemination and how to derive the amount of solution according to the final matrix.
https://en.wikipedia.org/wiki/Transformation_matrix
As we have to apply the transformation that we executed on the string matrix(it's like the LHS of an equation set)on to the b string(we can view it as the RHS), building a transformation matrix is faster and more visualized.
Thank you, I am able to solve the system of equations but I am still trying to understand what things to be altered to the algorithm to work on "mod 5".
the calculation rules are modified to suit the cyclic group.
for example, you want to do Gauss elimination on
then the step is(to make it easy to understand, I follow the method on wiki)
Which criteria are used to set division rules? More precisely, how do you calculate it?
Why in D's solution, you just push back i into vector of p but not p into i's vector? And you said that we considered 3! = 6 permutations of a, b and c, but as I saw in the code, there was only 3 permutations. Correct me if I was misleading.
It's because editoral for this problem is written by me, but solution is by Arpa.
Arpa, can you explain your solution?
Hi. Sorry for the delay.
Let calc(f, s, t) number of texts will be counted by Grisha if Misha rides from s to f and Grisha rides from t to f, it is obvious that calc(a, b, c) = calc(a, c, b).
So we can use 3 permutations instead of 6.
We calculate the length of common part of paths from
atocand frombtoc, so there is no sense in ordering verticesaandb, and we have only 3 variants for the third vertex.Thank you, I got it. But i read his code and i saw that he just do
g[p].push_back(i)but notg[i].push_back(p)because as what I have learned, tree is bidirection graph, so we have to create 2 edge for each pair of vertices. And his dfs, I think if v is connected with u then we can only dfs(v) if v != parent(u)?It can be proven, that when the tree is given as array p2, p3, ..., pn, then pi is always a parent of vertex i, if we consider vertex 1 to be the root.
Proof of this:
Consider the sequence i, pi, ppi, pppi, .... By definition of the p's, each pair of consecutive vertices is distinct and connected to each other, so they must all be distinct (since trees don't have cycles). Then eventually this sequence hits 1 and ends, so pi is closer to 1 than i.
Anyone used regex to solve problem B. I tried using regex in C++ and hopefully generated the right regular expression pattern as well but couldn't pass the pretests. Can anyone help?
I got to test 79 with Python's Regex :-) 28858499
My code gives right answer in ideone compiler for pretest 2 but when submitted here gave me wrong answer on pretest 2. This is really disheartening as I am not able to figure out the problem with my code. Any help is appreciated. 28850846
Your submission is buggy when you copy reg to regi which is a uninitialized stack array, i.e. regi is not 0 terminated. I modified it a little bit to make it pass pretest 2. 28881236. However just like my previous submissions it fails at test 5 because of runtime error. I cannot figure out why
Confirmed, there ARE some problems with regex implementation of GCC in CodeForces, see:
TLE with VSC++(this is expected)
RE with GCC 14
RE with GCC 11
Down voted by mistake. :(
What is "lca" in the solution for D?
Lowest common ancestor
I am not able to figure out any mistake in my submission. Can anyone tell what could be the mistake? Thanks. EDIT: solve(a, b, c) gives the answer to the common distance when you are going from b to a and c to a.
Is there a smaller test similar to test 6 for D?
My solution to C runs in linear time:
http://mirror.codeforces.com/contest/832/submission/28858056
But even after acceptance, it took to me a lot of time to be convinced that it works in all cases.
Ugh, C isn't even conceptually hard, it's just extremely painful to code up.
Honestly, I'm really tired of problems which are obvious binary searches on doubles with horrible implementations and high chance of floating-point error.
Sorry, I've found a counterexample to my solution to C (although it passes all tests). To simplify it, assume that the right-hand-side limit is L=76 instead of 1000000. Now, consider the input with n=3 people and s=4.
The right place for the bomb is x=x3=36, and it gives t=8.
But my program is not going to find it.
I find lca for 3 stations and then understand that I am puzzled with many variants of their mutual location in tree..
Why ternary search on bomb position is not works? I think that function time(bomb_position) is decreasing and increasing then. http://mirror.codeforces.com/contest/832/submission/28865055
in C, i don't know how to apply scanline or prefix sum approach to find a point which is contained in both type(segments for persons going left & right) of segments can someone explain it or give link to read. what method is used in editorial? tia.
I really don't understand how to from the matrix,could you help me explaining the matrix. Forgive me my poor English.
Could anyone explain how to calculate the number of intersession edges for two given paths (problem D) please? I don't understand the formula given in tutorial.
Take a look at mraron's answer below
I also didnt understand formula in editorial so I made it up myself. Lets say you want to calculate commong edges of paths a->c and b->c.
If level of lca( a,b ) is higher than max( lca(a,c), lca(b,c) ) that means a and b will meet up, and then together continue their path to lca( a,c) (in this case lca(a,c) == lca(b,c) ), and from there they will continue to b. So solution in this case is level[ lca(a,b) ] — level [ lca(a,c) ] + level[ b ] — level [ lca(a,c) ] , which is actually just level[ lca(a,b) ] — 2* level [ lca(a,c) ] + level[ b ]
If level of lca( a,b) is not higher than max( lca(a,c) , lca(b,c)) , that means a and b will separately go to c, without meeting before reaching their lca's with b, so solution is level [ b ] — max( level[ lca(a,b) ] , level [ lca( c,b) ].
So, you have 2 cases for 3 combinations of s,f,t : when s,f and t are destinations respectively. Code: http://mirror.codeforces.com/contest/832/submission/28877111
you made some typos when the destination is C (in formula above level[b] should be level[c]), but I understand you idea. Thank you very much for your reponse, it is very helpful. This is my understanding according to you reply. Consider also a -> c and b -> c, the idea is to see if a and b meet up before reaching max(level[lca(a, c), level[lca(b, c)]) (this is the point they will meet for sure). If yes we should add an additional length of level[lca(a, b)] — max(level[lca(a, c), level[lca(b, c)]). In general let
the answer should be
ans = max(lb, 0) + laYes, thats it. Im glad I helped :) And yes, it should be level[c] instead of level[b], sorry for typo.
Can someone please clarify what do (u1 & u2) represent in the Problem D explanation?
Simpler solution for problem D: let dist(a, b) be the number of vertices between a and b then
Implementation: 28875062
thanks for it ...i have used this and my solution get accepted ...but can u please explain how you land on this expression?
Let a point p be outside of path x - y if and only if we move p closer to x step by step and at every step it gets closer to both x and y.
You should consider 3 cases:
If you draw all 3 cases you'll see why the formula is true.
You're a genius. This was the only solution I could understand :)
Counter example:
Suppose we have the following graph:
Note that the following expression uses floor division:
Let s = 3, f = 2, t = 4
But the answer in this case should be 1.
Did I misunderstand your formula?
Sorry my definition for dist(a, b) was a bit misleading and not well defined, dist(a, b) should be the number of nodes on path a to b. So the formula works because
.
Really clean solution. Thanks!
For problem D, since s and t are interchangeable, there are only 3 cases we need to check, not 3!.
is the same as
That is true! And since I used a slower lca method ( in such a way that my code complexity was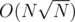 ) checking only 3 instead of 3! possibilities made my code get AC instead of TLE
) checking only 3 instead of 3! possibilities made my code get AC instead of TLE
TLE code checking 3!
AC code checking 3
How can you calculate the LCA in O(1) (I'm talking about problem D) can someone explain please ?
You use a sparse table, where the operation is just finding the max of two elements. Although it should be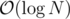 since you need to find the largest power of two less than a number. I guess this is negligible.
since you need to find the largest power of two less than a number. I guess this is negligible.
Read about it more here on topcoder
Mainly, look at the Sparse Table section.
I think they assume that power and log operations are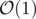 .
.
You can pre-calculate logs ans powers in .
.
Note that number of edges in the interseption of two such ways v1 -> v2 и u1 -> u2, hv1 ≤ hv2, hu1 ≤ hu2 is max(0, hlca(u2, v2) - max(hv1, hu1)).
Can somebody please show me how to prove this statement?
How is the scanline approach in problem c (832C)? I have never heard of it and by googling I only found scanline for polygon filling as in this link
Can someone please explain to me if the above link shows the same scanline approach mentioned in the editorial, or where can I find a tutorial with the same "scanline" mentioned in the editorial (for segments intersections or so)? Is it like line sweep approach?
It means Sweepline.
Why problem E %5 is OK?
Could anyone explain what does that mean in problem B "It is guaranteed that the total length of all query strings is not greater than 10^5." Does it mean |S1|+|S2|+---+|Sn| <= 10^5?
Yes :)
Can someone please explain how do the prefix sums work in problem C?
Your objective is to mark in an array (i.e. working in range [1,n] ) which places are suitable to put bomb in.
For each person you get information about a new range [a,b] of the array that is suitable. The naive approach would be to iterate from a to b on the array and set all those items to 1. But it cost O(n) in worst case for person, that is O(n * m) overall where n is the amount of places and m is the amount of people.
So to optimize you Just use an auxiliary array (name it sum[1,n]) and for each person that adds an a-b range you just increment sum[a]++ and sum[b+1]-- (the differences that would be in the final array). Note this cost O(1)
With those information stored in sum[1,n] you can, after processing all people ,generate the real array with suitable positions with a simple formula in O(n)
arr[i] = sum[i] if i = 1
arr[i] = sum[i] + arr[i - 1] if i != 1
There is a slight difference that in this case if arr[i] > 0 then the place is suitable, but the information we've generate is still useful.
And the overall complexity of the process is O(m + n)
Can you provide the implementation of this idea in a code? Thanks in advance.
28978544
implementation is terribly hard. I used binary search approach although there is a direct formula solution (that is even harder). Efficiency difference is slight in practice.
I have a problem about C. If we change the compare function in the given solution 28853440 like:
we will get runtime error 30198318 Why is that? Why the second line must be
I think this decrease the probability of swapping elements thus speeding the program up but without it I think we can still get the correct answer. I ran the code locally with a similar case to case 9, I indeed got segmentation fault. Anyone knows why?
deleted
Hello, could you explain for me the formular in the question D? I find out that if for example u2 or v2 is the root of the tree then the h lca(u 2, v 2) = 0 but something wrong here I can find a such road such as its intersections are more than one node.
$$$max(0, h lca(u 2, v 2) - max(h v 1, h u 1))$$$
Deleted
C can solve in O(nlogn + n * it) with two pointers, and i mean has a weak tests