


I have learned the normal version of CHT quite long ago. But I am having trouble implementing the dynamic version of it. I searched for some implementations and found this. Though its pretty short, I can't understand it much :( and I will be participating in my country's OI competition soon. There I can't bring templates with me. So, if anyone can provide me with an easier code, it will be really helpful. :)
→ Обратите внимание
До соревнования
CodeTON Round 9 (Div. 1 + Div. 2, Rated, Prizes!)
06:55:29
Зарегистрироваться »
CodeTON Round 9 (Div. 1 + Div. 2, Rated, Prizes!)
06:55:29
Зарегистрироваться »
*есть доп. регистрация
→ Трансляции
→ Лидеры (рейтинг)
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | tourist | 4009 |
| 2 | jiangly | 3823 |
| 3 | Benq | 3738 |
| 4 | Radewoosh | 3633 |
| 5 | jqdai0815 | 3620 |
| 6 | orzdevinwang | 3529 |
| 7 | ecnerwala | 3446 |
| 8 | Um_nik | 3396 |
| 9 | ksun48 | 3390 |
| 10 | gamegame | 3386 |
| Страны | Города | Организации | Всё → |
→ Лидеры (вклад)
| № | Пользователь | Вклад |
|---|---|---|
| 1 | cry | 167 |
| 2 | Um_nik | 163 |
| 3 | maomao90 | 162 |
| 3 | atcoder_official | 162 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 156 |
| 8 | TheScrasse | 154 |
| 9 | Dominater069 | 153 |
| 9 | nor | 153 |
→ Найти пользователя
→ Прямой эфир





Codeforces (c) Copyright 2010-2024 Михаил Мирзаянов
Соревнования по программированию 2.0
Время на сервере: 23.11.2024 10:39:33 (k1).
Десктопная версия, переключиться на мобильную.
При поддержке

I found LiChao Tree easier to understand/implement, this is a good explanation
Yeah, I've read it and it is quite easy.
But LiChao Tree can take per insert/query where L and R are the min and max possible values of x (assuming its done online). Whereas, Dynamic CHT takes
per insert/query where L and R are the min and max possible values of x (assuming its done online). Whereas, Dynamic CHT takes 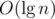 . Did you ever run into problems because of this?
. Did you ever run into problems because of this?
It worked just as fast as the solution with sets on the problems I tried.
You won't fall in trouble due to this much change in the complexity. However this has its own advantage. You can have a line added to a segment and not the whole segment. This can be done in O(lg(R-L)), whereas in DCHT, it takes O(nlog^2n) [by maintaing a segment tree of DCHT nodes]. and its more intuitive to implement too.
But what about real number queries?
Generally questions are for integers. However if you need you can extend the LiChao segment tree for fixed precision too.
Initially, the tree height was log(R-L) to make the last level range of the form i-(i+1). If you want you can build the tree to x levels getting precision of (R-L)/2^x.
Implementation would be similar to Implicit segment tree,
I use this code written by niklasb. Note my comment in link, the original code has a bug.
we have used this code for years and never had any problems... can you give an example where niklas original code fails?
Yes, I found the problem while solving 91E - Igloo Skyscraper (I've built a segment tree of CHT's). When I relied on the original code the first input example wasn't correct. This is the WA solution 59667839. This is the submission with my fix that got Accepted 59662177. These solutions are identical except the changes in the "insertLine" function. (The code is a bit different for the purpose of the question)
If you are sure the code is right maybe I had the problem while using it. If that is the case I don't understand why the problem I mentioned doesn't happen.
Write a sqrt decomp version. Keep a buffer of lines, apart from the CHT structure.. When new line is given, add to buffer. and when buffer size exceeds some B, remake the whole CHT structure. During query, query on the CHT structure as well as evaluate all lines in the buffer. Set B= sqrt(n). This works almost as fast as the set implementation, and is very easy to code imo.
ig this is pretty slow when n is slightly large. Can you ac this with sqrt decomp?
Set has a huge constant factor, whereas sqrt method has few cache misses. Thats why they dont have too much of a time difference, as you would expect from sqrt vs log in normal probs.
In the prob you gave, the sqrt decomp method only passes about half the test cases though. (Maybe it can be optimised more ? :P )
I do not have much knowledge about cache misses (or catches?) but I think, even if you set buffer size $$$c\sqrt{n}$$$ for some constant $$$c > 1$$$, still building up a whole cht $$$\frac{\sqrt{n}}{c}$$$ times which screws us with sufficient amount of constant factors (even if you don't need to sort, there is nothing that cache memory can do by catching those caches, because you are not doing anything 'same' everytime, right?) is quite much.