


Hi, Codeforces!
I`m glad to invite everybody to the #546 Codeforces round, which will be held on Monday, March 11, 2019 at 19:35. The round will be rated for all participants from the second division (with rating below than 2100). As usually, we will be glad to see participants from the first division out of competition!
Problems for the round have been proposed by Fedor ---------- Ushakov, Stepan IbragiMMamilov Stepkin, Alexey usertab34 Roze, Denis Denisson Shpakovskij and Alexander Ralsei Gladkov.
The round have been prepared by us, Dmitry DmitryGrigorev Grigoryev, Fedor ---------- Ushakov, Semyon cookiedoth Savkin and Dmitry TheWayISteppedOutTheCar Piskalov.
We'd like to give thanks to Ildar 300iq Gainullin for excellent coordination of the round, Grigoriy vintage_Vlad_Makeev Reznikov, Alexey Aleks5d Upirvitsky and Mohammed mohammedehab2002 Ehab for testing and to Mike MikeMirzayanov Mirzayanov as well for his unbelievable Codeforces and Polygon platforms.
You will receive 5 problems and 2 hours for solving it. During the round you will be helping for an extraordinary girl Nastya, who is studying in an usual school in Byteland.
Score distribution will be announced, traditionally, closer to the start of the contest.
Please, read all the tasks. Good luck!
UPD Score distribution is standart — 500-1000-1500-2000-2500
We're looking forward your participation.
UPD2 Thank you for your participation in the contest!
List of the winners of the contest:
Div.2
Div.1 + Div.2
My frank congratulations for all the winners!
The editorial will be posted very soon. We apologize for delay.
UPD3






Let's hope difficulty gap will be normal
we
I hope this contest makes my contribution positive.
5 problems and 2 hours contest are really challenging. I am looking forward to participating in this contest and I wish to learn new things. :)
Happiness is back!!
That's quite a new thing in an announcement.
Maybe he implies that the problems are not sorted by difficulty
if the problem is concise, that help
Please, read all the tasks
excuse me? do you think being able to post a contest allows you to dictate what people should do? classic slav attitude...
please don't keep a mathforces like last time
and also not a geometry one!
I like mathforces
I wish i can reach 2100 this time
who cares about you to be honest
me
A contest with 5 problems:)
Let's solve the problems just for rating!
Desire positive rating changes in this round!! :)
UPDATE on Mar.12, 2019:
I can not understand why some people voted my reply with negative attitude.
I always believe that everyone desires positive rating changes. Maybe my opinion is a bit wrong.
:(
Five problems!
Haven't seen a 5-problems contest in a while...
A challenge contest! Looking for it! :) I believe that it can improve our skills!
Nastya from "Byteland" .....
Score distribution ?
hope short problems!
Good Luck :D
NOT FOR contribution :3
Auto comment: topic has been updated by DmitryGrigorev (previous revision, new revision, compare).
Score distribution is standart
standard, dude
Is MikeMirzayanov the owner of problem C ?
Seems so, coz his problems are generally based on good idea/observation + quick/short implementation but if you haven't thought of the idea clearly then implementation can go pretty lengthy and fail on system tests
Admin take some action against this user bb2211 he is hacking his solution from another id Ragnar7.
I think you should block both users
Insanely good difficulty balance.
i'm the only one who take 30 min to understand D ?
How to solve E?
Also will the numbers fit in long long?
The number will obviously fit.
E can be solved with segment tree + lazy propagation.
2nd query will be discarded (just calling the get function).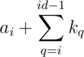 , with mx as the maximum index that
, with mx as the maximum index that 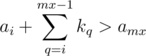 . mx could be found by binary search.
. mx could be found by binary search.
To do the 1st query, first update that single element without lazy propagation, then perform updating all elements id in the range [i + 1, mx] (inclusive) with
How to handle update in range[i+1 ,mx] using lazy?
This part is pretty tricky. Here was my approach in contest:
First of all, my segment tree is one maintaining range sum.
You can see that the newly updated value is always strictly larger than the old one, thus if the lazy attribute for the working node already has some value, overwrite it.
Each "lazy attribute" stores two values: the ai which causes the updating chain begins and its index i.
When propagating from a node with lazy attribute, assume that the node cover the range [st, en]; you'll see that the sum should be overwritten into: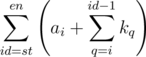 .
.
That one can be rewritten as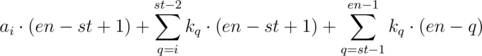 .
.
From here, the propagation can be done in O(1), with the help of prefix sum, or even nested prefix sum, in array k.
ok thanks i will look into it.
Should be [i, st-2] and [st-1, en-1] for the limits, but yah, I forgot that. Edited. ;)
Tried to create a difference array from array A and array K, and tried updating the values of this diff array for query of type 1, it will turn most of the values of this diff array to 0.
Query of type 1 will increase the diff value of only first element and make all other diff value 0. So, at most 2*n values need to be updated at most.
Tried to maintain the index of non-zero values of this diff array using set,and then range update and range sum query using segment tree lazy propagation.
What does "Tried to" mean? Did it pass pretests?
yes it passed
The answer will fit inside of a long long. max(A) starts out ≤ 109 and you can add at most 1011 to it, so A[i] will at most be around 1011, meaning the sum of the As will at most be around 1016. So everything should fit inside a long long without any problems.
About the solution: You can reduce the problem to all k being 0 by working on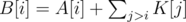 instead of A. For B we have that B[i] ≤ B[i + 1] so it must always be increasing.
instead of A. For B we have that B[i] ≤ B[i + 1] so it must always be increasing.
To do the two types of queries I used binary search together with a lazy segment tree that allowed sum on intervals and set on intervals.
To do the add query you need to add x to B[i] and then update the rest of B so that it is increasing, to do this you can apply binary search on B to find all indices j such that j > i and B[i] > B[j]. Then use the set on interval operation to make all of those B[j] equal to B[i]. This takes per query.
per query.
To do the sum query just use the built in sum in the lazy segment tree. But this is a sum over B and not A, so you need to adjust the answer by removing the extra k you added in the beginning, which can be done by playing around with cumulative sums. This takes per query.
per query.
I did the same stuff but got TLE on test 19. I think there is a way to do add query in O(log n) by removing the binary search step and to find the position by only descending the tree on single-side.
Uhm so I'm currently using pypy and it passed all pretests, so I'm sure you can do it in C++ as well without any problems. You probably just need a quicker implementation of a lazy segment tree.
But yeah, I think you can do a quicker binary search by having another lazy segment tree, this one allowing for set on an interval and maximum on an interval, and with that tree you could do the binary search in just .
.
Seeing my code now I realized I left a debug statement there involving flush after every query.
Can you explain in more detail how to do first query per O(logn)?
This is a pretty well known technique used on segment trees (and binary trees) in general, the idea is to start in the top and walk down the tree.
If the maximum of the left child is ≥ B[i] then walk to the left, else walk to the right. With this you can find the first index j such that B[j] ≥ B[i].
This works straight up on segment trees, and can also be used on lazy segment trees, but then you will have to push lazily stored queries during the search.
There is a solution that do not uses segment tree tricks, just two plain seg trees, one with range += lazy and range sum other with range = and one get one element.
You can notice that if you update a[i] += x that leads to a[i + 1] = a[i] + k[i] and so on from i to some l, than if you'll update a[i] += y again, you'll just make += on range(i, l). So this observations leads us to smth like DSU (disjoint set union). But there is one thing, when we get query update a[i] += x and i belongs to some [l, r] segment where l is strictly less than i this segment [l, r] splits to two [l, i — 1], [i, r]. So you need to do unusual DSU with segment tree (the one with range=).
When you get a[i] += x query your steps is split range to which i belongs than go to right and merge some ranges (continue while conditions from statement is true), while merging make += on right range. It is clear that we will do at most n + q mergins, because we can merge only by two reasons 1 — it was originally disjont (thats n) or 2 — it was splitted (that's q). Complexity O((n + q) * log(n))
Submission for details 51198410
Thanks! I followed your advice and got accepted. https://mirror.codeforces.com/contest/1136/submission/51236918 Instead of segment tree for the DSU-ish part, I used set of pairs. In your personal opinion do you consider this to be harder o easier to implement? I understood your explanation but I couldn't really understand your code.
I just didn't come up with set of pairs idea, I think it's better idea than using another segment tree. Strange I thought my explanation worse than code.
You can solve it using plain segment tree with lazy updates.
Notice the fact that the values will be increasing. So, suppose that the i+1 th index is changed once due to the update on i'th index. Now, if somehow a[i] increases again, a[i+1] will increase by the same amount. Based on this, you can perform range updates. And number of these updates won't be that much.
How to solve D guys?
If you can swap, do it immediately otherwise take the previous pupil to the farthest position from you, until nothing change
This Greedy method will get TLE.
68th test case :(
My solution can pass systest, you can see my submission here 51250678. But it got TLE at a simple test. So painful
We will iterate from the back of the queue (person before Nastya) to the front. We will store for each person i how many persons are after this person in the queue and are favored by person i, in fav[i]. Initially we set fav[i] for each person i that favors Nastya to 1. We will also maintain a variable that stores how many persons have been removed from the queue so far. Now if we are at person i and there are x persons removed, a total of rem = n - 1 - i - x persons remain to the right of this person. If fav[Q[i]] == rem, every person that remains to the right of this person is favored by this person, and thus this person can swap with each one of these. In this case we remove this person and increase our answer by 1. Otherwise we cannot remove it and we will increase fav for all the persons that favor this person.
The complexity of this approach is O(N + M). https://mirror.codeforces.com/contest/1136/submission/51189237
was thinking in the same lines.couldn't complete in time. BTW nice solution.
I have done the same thing
Robbinb1993 what do you mean by favoured by person i? and after this person means to the right or to the left of person
If some person u is favoured by person i, it means person u is allowed to move places with person i, if person i is in front of person u in in the queue. So if all the remaining persons to the right of person i in the queue (towards the back) are favoured by this person i, he can move places with all of them and Nastya is able to move one place forward in the queue. In this case we 'remove' person i from the queue (that is we move it after Nastya).
ok , thanks i understood it . great idea Robbinb1993
I just pushed every person that can let Nastya stay before him to the end of p[] (to the place before such persons that are already at the end), and then counted number of such persons in the end of p[].
Observation: if person can not be pushed to the end, he can not ever let Nastya ahead.
51192297
Me in this round:
Lol.
Good round, tight pretest (at least as of now I supposed) :D
Anyway, any cool observations for D?
Moving from natasha to first guy, if you find the guy that can move to back of natash,then move it.
Dang, I was stupid! :(
Thanks. ;)
Can you please elaborate a bit?
Is your solution working for this case as well?:
I think that the correct output should be
1, I think that your approach will return0.It still works. You can see my solution here.
solution here.
The idea is, when traversing to position i, we'll consider the pupil initially standing at that position solely. And we'll move him/her through the very end, until blocked by someone not he/she isn't willing to swap places.
There are only m relationships, and each only causes one swap, thus only maximum m swaps are performed.
Had i been the online jidge ,i would have definetly passed all your solutions without checking for test cases...i mean just look at comment at the bottom
LOL. If only that applies in real judges :D
I really loved Ur solution .. I was thinking it completely the wrong way
DmitryGrigorev Read all tasks :P
Nice contest, though missed E (knew idea)
Good tasks, thanks!
Someone please explain C.
Each respective diagonal in the matrix must have the same elements.
Can u please elaborate. It would be great help.
for matrix,
[1 2 3]
[4 5 6]
[7 8 9]
all the diagonals are [1], [4, 2], [7, 5, 3], [8, 6], [9]
required matrix,
[1, 4, 7]
[2, 5, 6]
[3, 8, 9]
all the diagonals are [1], [2, 4], [3, 5, 7], [8, 6], [9]
so here we can see those respective diagonals have the same elements so the answer will be "YES" otherwise "NO".
Can u tell why?
Each time you transpose any square submatrix, every element stays on the same respective diagonal. And by transposing 2x2 matrix, you can perform swap for adjacent elements in the diagonal, therefore, you can sort these elements in the diagonal.
Notice that you can imitate transposition of every matrix by little transpositions of matrices 2x2. That's because transposition of matrix 2x2 swaps two nearby elements on the diagonal, and transposition of matrix nxn swaps some elements on every it's diagonal (elements that are on a diagonal remain on that diagonal). But you can imitate every permutation by some swapping nearby elements.
I noticed that transpose does not change the sum of row+column. That's why I just verify that both matrices have values with equivalent sums. I did not prove it though.
How to solve C?
Each respective diagonal in the matrix must have the same elements.
Anyone knows why I can't use auto in my compiler (codeblocks)
Check in your "Compiler settings" if you'd enabled C++11 features yet.
setting -> compiler -> c++14 ->OK
Soooooo shitty pretests in C
Yeah. My stupid bugs failed only on 21th pretest. It's was awful
Any idea what the hacks were for problem C ??
Maybe something like this
3 3
1 1 1
1 1 1
2 1 1
1 1 1
1 2 1
2 1 1
Apparently all matrices in pretests were square but matrices can be nonsquare.
Damn, those are shit weak pretests
That's definitly false
A few people passed pretests for C even though they used n where they should have used m, so we thought there were only square matrices in the pretests. Thanks for the correction.
Something Like: 2 2 1 2 2 1 1 1 2 1
Basically some solutions didn't test for equivalent diagonals but just checked that each element in some diagonal of A has at least one equal element in same diagonal of B
One error I saw some people made is that they checked that the list formed by adding together a diagonal from A with the equivalent diagonal from B had an even number of each integer. This breaks, for example, when a diagonal in A contains two 1's and the corresponding diagonal in B contains two 2's.
Why do people use fake accounts to increase rating? This user bb2211 has hacked 7 solution of his fake account Ragnar7 in this contest, thereby getting +700 points. Hacked soultions — https://mirror.codeforces.com/contest/1136/submission/51194910 https://mirror.codeforces.com/contest/1136/submission/51194506 https://mirror.codeforces.com/contest/1136/submission/51194345 https://mirror.codeforces.com/contest/1136/submission/51194130 https://mirror.codeforces.com/contest/1136/submission/51193823
He definitely will be disqualified.
How did he manage to get 7 fake accounts in same room?
One fake account, and hacked 7 solutions of the same. Check the hacked solutions link. They are like if(n==199) cout<<"Wrong Answer".
They think good rating makes them look cool xD so silly
I care about my rating just because that means I have improved
apparantly I_love_sad_crying_cats noticed this during the contest and got benefited with bb2211's kid play ;) Lol..well played I_love_sad_crying_cats !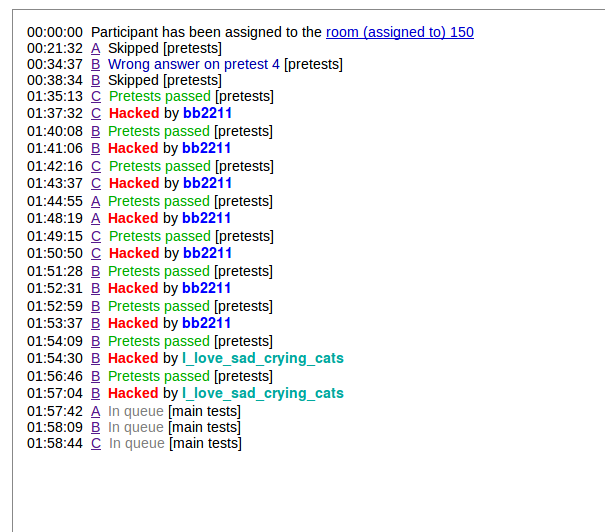
Haha:D, Karma plays well.
Weak pretests for A
*pretests
Isn't it easy?
You may want to check this out: https://mirror.codeforces.com/blog/entry/65873
good contest with interesting problems
who else got WA on problem C? I think most of us(
I got. Very stupid mistake. the amount of diagonals is n + m -1, isn't 2 * n-1. With this mistake my solution broken down only on 72 test.
Problem 'C' was really nice. Thanks to writers :)
Seems like D doesn't have worst case tests, my solution having worst case n^2 passed in 795 ms. I am iterating through all degrees of last person in decreasing order and adding this to answer if you can reach nearest to last person by continous swaps with adjacent person. https://mirror.codeforces.com/contest/1136/submission/51194411 Clearly n^2 when last person is linked to first half of people, and all of those half are connected (moving back) for every other node. Am i missing something here?
EDIT: Got it! There are only m relationships between people so only that much swaps can be there. So it is (NLogN+(M+N)) and not (N*N). really nice question!
My code for D got TLE on system test: https://mirror.codeforces.com/contest/1136/submission/51194792
But resubmitting the same code without any changes passed: https://mirror.codeforces.com/contest/1136/submission/51197516 and https://mirror.codeforces.com/contest/1136/submission/51197653
it just passes on re-submission. once with 19ms gap and once only 4. Server tends to have some measurement error for different run of tests depending on processing load and bunch of other stuff. Check https://mirror.codeforces.com/blog/entry/49965#comments for more info.
Yeah, Realized that. Thanks for the comment link.
Mistake on my part for not including fast I/O. Using fast I/O reduces the runtime to 732 ms from 1980 ms: https://mirror.codeforces.com/contest/1136/submission/51196918
Guess cin/cout are really slow in C++
Hey MikeMirzayanov, this user cs_tree skips his solution, whenever there is a chance of huge decrement in his rating. This is the second time I've seen him do this.
Screenshot during the contest :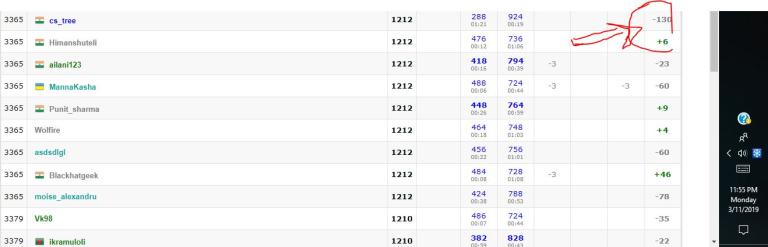
Screenshot after the system testing was completed :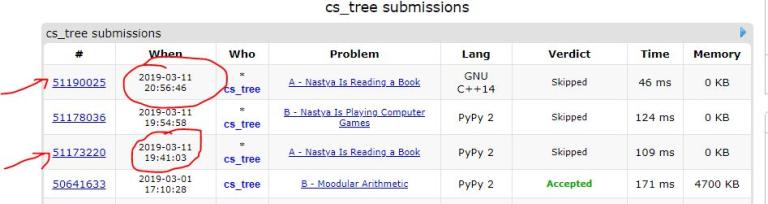
He submits the solution in C++ whenever he wants to get his solution skipped.
Here is a screenshot of his previous skipped contest.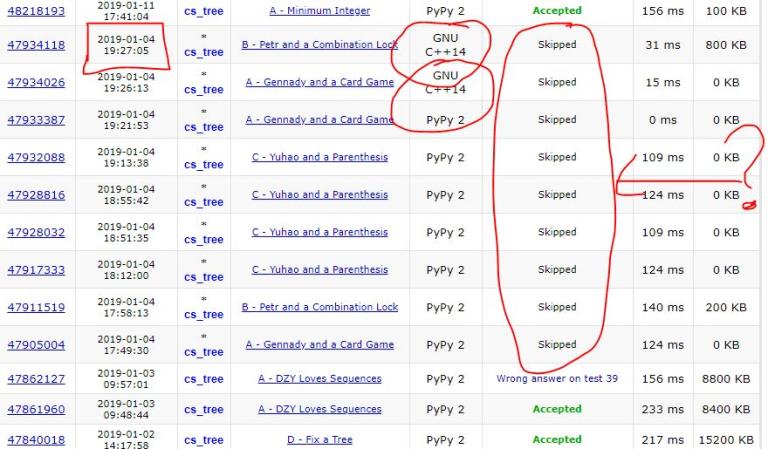
This kind of behavior is unacceptable. Please look into this matter and take strict actions against this kind of people. It is very disheartening for people who give contests regularly and go through the ups and downs in their rating.
how it is done , how to skip a solution . As far as i know , if u want to skip a solution , submit same solution from different account , codeforces will give u system warning and ur solution will be skipped , but if this continues to 2 or more times ur accnt will be blocked ? am i right MikeMirzayanov
To find those ninja techniques participation in contests is a must.
abe bsdk , tere ko kahe lagta hai ki ham contest me participate nahi karte .
Your colour shows that you don't participate.
I don't know it Colorless is new lgm.
Hello, I received a message saying that my solution for Div2D coincides with the code of other users. The code is clearly different and for a problem with such a short solution it is likely for the code to be similar. Please look into this.
Here is the submission which got flagged: https://mirror.codeforces.com/contest/1136/submission/51189268
Very weak pretests for D. In hurry I didn't notice, that edges are directed and passed all of pretests. Rip rating. 51184494
How to solve D ? Any one ? !
We claim that the optimal construction is as follows.
Maintain a "bubble list", which initially contains only Nastya. Then, iterate through every person in line, starting with the one directly in front of Nastya. If this person can be passed by every person in the bubble list, then move them back until they're behind Nastya and increment the answer by one. If there is a person in the bubble list who cannot pass the current pupil, add the current pupil to the bubble list.
Clearly, this construction is valid given the problem parameters. To prove that it is optimal, suppose that there is some pupil A who cannot be passed by some person B, who himself cannot get behind Nastya in the line. No move except for B directly passing A will put B in front of A, so A cannot get behind B, meaning A cannot get behind Nastya. So, any person who cannot be passed by someone in the bubble list cannot get behind Nastya no matter what sequence of moves we use. (To formalize this argument, we'd need to use induction, since we implicitly assume that the bubble list is "correct" before processing each pupil.)
In terms of efficiency, iterating through every pupil is O(N). Checking to see if a pupil can be passed by everyone in the bubble list is O(N) in the worst case, but because there are only M passing pairs, this operation takes only O(N+M) operations. The most intuitive way to check whether one pupil can be passed by another is to use a set or a sorted list, either of which support queries in O(log N). So, the efficiency of our algorithm is O((N+M) log N), which easily passes.
this person can be passed by every person in the bubble list, then move them back until they're behind Nastya
move them back or move him back .. i couldnt understand
athis line
and add the current pupil to the bubble list.. should we add before natsya or after natsya
When we reach a certain person, the only people between that person and Nastya will be the people from the bubble list. So, we can just have that pupil be passed by everyone from the bubble list, at which point he will be behind Nastya.
The order of the bubble list does not matter, as this won't affect whether any future pupil can be passed by every person on the bubble list.
Hey! Thanks for the great solution
I'm getting TLE, because for each person in the queue, I'm checking all the bubble list, resulting in a n^2 running time.
"...but because there are only M passing pairs, this operation takes only O(N+M) operations". Could you please explain how can I do this? I'm not seeing it
Thank you!
To implement this operation with only O(N+M) total queries, we need to stop checking immediately after finding a person from the bubble list who can't pass the pupil we're checking. Here's what it would vaguely look like to check a pupil A:
This way, we continue the loop only if all the elements we've checked so far can pass A, which means that we'll continue the loop at most M times.
Perfect! Thank you again
https://mirror.codeforces.com/contest/1136/submission/51188835 why is my solution skipped? MikeMirzayanov 300iq
ETA of editorials??
D had weak systests. My n^2 solution passed. For example try it with this test:
On the other hand, C had weak pretests, so it didn't catch solutions which assumed square matrices so I guess that evens it out?
We've already talked about this elsewhere, but I think it's worth adding to the discussion here.
I can't pass the suggested test to your program as input in custom invocation because the file size is too large. But I can fill in your data structures n, m, p, g in the code itself like so here. (See how I'm not reading into n, m, p, g from standard input). (This should be fine because reading input shouldn't be the slowest part of your solution).
This runs in 46ms in custom invocation.
The code does look like it should be O(n^2). Does anyone know why it doesn't TLE on Codeforces? My guess is some compiler optimization magic. :)
Edit: Running the program locally with the input hardcoded results in a similar running time as running the program locally and reading the input from standard input, so I’m not convinced that compiler magic is only because of hard coding the input into the program.
Compiler magic happened because you hard-coded the input and indeed I can reproduce that on my machine. But there is no way that can happen if it is read from file and it doesn't happen on my machine neither with gcc nor clang.
If the compiler treats:
which is functionally equivalent to the previous code but more efficient then the complexity drops to (N+M)log N. I don't know if it does, though.
next contest is after 4 weeks?
There will surely be many contests in between. Wait for a couple of days, they might not be declared yet.
VivaanGupta have a look now on the contest page. One is declared. Still there can be more contests :)
My solution to problem c passed pretests including test case 10 but it failed system test with TLE on test 10. Same solution got successfully submitted in practice. 51188133
The same happened to me
I met the same problem.
During the contest, this code got TLE on test 10. Then I changed the range of my arrays from 500 to 5000, and the new submission got AC.
After the contest, I re-submitted the same solution with arrays of range 500 and got AC.
I think the test data before were incorrect, and maybe after the contest, the author corrected them. Why doesn't Codeforces rejudge all submissions of this problem? It's not fair. MikeMirzayanov
Why can't people learn to add three magic lines to speedup their cin?
Oh! Thanks for your reminder!
Always waiting for editorial.
For prob A, I forgot a "=" but still pass the pretests, but after the contest I failed at test 54 :((
We're looking forward your Editorial.~~~
E can be solved using Segment Tree Beats, eliminating the need for a tricky binary search.
Code: 51225191
How to solve Div2 problem C?
you can prove that every number can't get away from right-diagonals(from right to left diagonals), but at every diagonal you can make every permutation by transpont 2*2 squares(with 2*2 square you can swap every neighboring elements, and get any permutation)
Can you elaborate a little further? thanks
number stay at diagonal, if y + x = const, so when we change matrix — coordinats of every element changes like: y + x => y — i, x + i. => element stay at diagonal, because y + x = y — i + x + i
and all you need is check, that muultisets of elementsa at every right-diagonal in both matrixes are equal
Hello, how long does it usually take for the editorial to be released? I'm soooo looking forward on checking how to solve questions D and E.
Auto comment: topic has been updated by DmitryGrigorev (previous revision, new revision, compare).
Thanks for a fast editorial!
Test data of D is weak.
My submission passed test but it's hackable by data I wrote below.
The answer is 2, but my submission prints 3.
Can anyone explain why in C using an unordered multiset is giving a TLE but using a vector and sorting and comparing passes?
I think the time constrains are too rigid in this question
UNORDERED MULTISET https://mirror.codeforces.com/contest/1136/submission/51269981
VECTOR https://mirror.codeforces.com/contest/1136/submission/51270061
Try adding ios_base::sync_with_stdio(0) to your code. The longest part is input and this line speeds it up.