


This blog post brought to you by pajenegod, Narut, and the rest of #constant-factor on the AC discord server. If you're interested in discussions like this, feel free to join!
For the longest time, CF has constrained us to the tyranny of 32 bit C++. Not only has that slowed down our long long operations, it has also constrained us to a measly 32 bit constant factor reduction with bitsets!
Let's take 2 pieces of equivalent code.
For Loop:
int a[MAXN], b[MAXN]
for (int it = 0; it < iters; it++)
for (int i = 0; i < MAXN; i++)
if (a[i] & b[i]) cnt++;
Bitset:
bitset<MAXN> a, b;
int cnt = 0;
for (int it = 0; it < iters; it++)
cnt += (a | b).count();
On Custom Invocation C++17 (32 bit) for MAXN=1e4 and iters=1e5, this boring for loop code runs in 3594 ms, while the equivalent bitset version runs in 104ms. 3594/104 is approximately 32. Ok, disappointing but makes sense.
However, Mike, in his generosity, has recently decided to free us from our chains, and give us 64 bit C++! Just imagine, 64x constant factor improvements vs 32x! However, what happens if we try our previous benchmark?
For Loop (C++17 64 bit): 3736 ms
Bitset (C++17 64 bit): 107ms
What's going on?
Huh? What gives? Have we been lied to? Where are our improvements? I'm not alone in noting this, see tribute_to_Ukraine_2022's comment here
So, what's the problem? The answer, as it so often is, is Windows. On Windows, long is always defined to be 32 bits, regardless of what the underlying OS is using.
And as it turns out, GCC bitset uses long as it's data type! Which means that even though our compiled code can use 64 bit instructions, the implementation of STL bitset is artificially constraining us! >:(
Misuse of Macros
So the STL is implemented in a way that forces us into 32 bit bitset. Are we screwed? No! As it turns out, before PL people realized how good of an idea namespaces were, they gave us the C++ macro and #include systems! Thus, even though you're importing code that you have no control over, you can actually modify its internals through shameless abuse of macros.
For example, say your colleague's heard of something called "encapsulation" or "abstraction", and made the internals of his data structure private so you can't modify them. Obviously, you're smarter than they are, and now you need to modify the internals of his data structure. You could ask them — or you could #define private public!
We can use a similar idea here, where we want to replace long with long long. In principle, #define unsigned unsigned long would work. Unfortunately, the GCC programmers never thought of such a brilliant usage of their library, and this breaks their internal code. I won't go through the entire process of what we needed to do, so let me present: 64 bit bitsets on Codeforces!
64 bit bitsets!
#include <string>
#include <bits/functexcept.h>
#include <iosfwd>
#include <bits/cxxabi_forced.h>
#include <bits/functional_hash.h>
#pragma push_macro("__SIZEOF_LONG__")
#pragma push_macro("__cplusplus")
#define __SIZEOF_LONG__ __SIZEOF_LONG_LONG__
#define unsigned unsigned long
#define __cplusplus 201102L
#define __builtin_popcountl __builtin_popcountll
#define __builtin_ctzl __builtin_ctzll
#include <bitset>
#pragma pop_macro("__cplusplus")
#pragma pop_macro("__SIZEOF_LONG__")
#undef unsigned
#undef __builtin_popcountl
#undef __builtin_ctzl
#include <bits/stdc++.h>
using namespace std;
signed main() {
bitset<100> A;
A[62] = 1;
cout << A._Find_first()<<endl;
}
If we rerun our benchmarks, we see
For Loop (C++17 64 bit): 3736 ms
Actually 64 bit Bitset (C++17 64 bit): 69ms
Ah... 3736/69 ~= 64. There we go :)
Running the benchmarks with MAXN=1e5 and iters=1e5 makes it more obvious.
Bitset (C++17 64 bit): 908 ms
Actually 64 bit Bitset (C++17 64 bit): 571ms
Real Problems
Let's take a real problem Count the Rectangles, code taken from okwedook here.
Adding our "template" speeds up his solution from 373ms to 249ms!
Caveats
Hm... None that I can see :^)
Note: This code is provided with no warranty. If you get WA, TLE, or your code crashes because of this template, don't blame me.







Auto comment: topic has been updated by Chilli (previous revision, new revision, compare).
BTW, if you use these pragmas
The above benchmark (with real 64 bit bitset) can run with
MAXN=1e4anditers=1e7in 1.1 seconds vs 1.824 seconds (with 32 bit bitset).Full benchmark here (put in custom invocation with C++17 64 bit):
AT&T Bell Labs employees announced retirement.
Amazing read!
I'm probably not going to actually use the code. Still, appreciating it from a distance is almost as good :P .
That's the idea :)
if (a[i] & b[i]) cnt++;Don't do this,
cnt += !!(a[i] & b[i])is faster. It might be optimised to the same thing in this case, but not always — when you try to squeeze through bruteforces using compilation tricks long enough, you'll sometimes find that it slows you down where it matters.I copypasted your codes into my template with some rand-filled arrays
aandband the same limits you use. It says 560 ms both 32-bit and 64-bit g++17 for the slow one.Sure, I agree. I was just choosing some obvious code. For that matter, the 32x vs. 64x constant factor improvements are also fairly coincidental in the examples I chose. You're typically bottlenecked by other considerations.
Those aren't the results I see. There's no easy way to show this, so I'll post some screenshots. One thing I'll note is that 32 bit bitset seems to run faster on C++17 32 bit than C++17 64 bit.
32 bit bitset (note the commented out includes)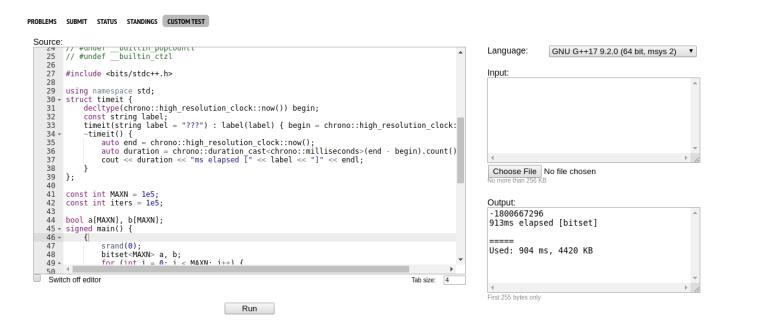
64 bit bitset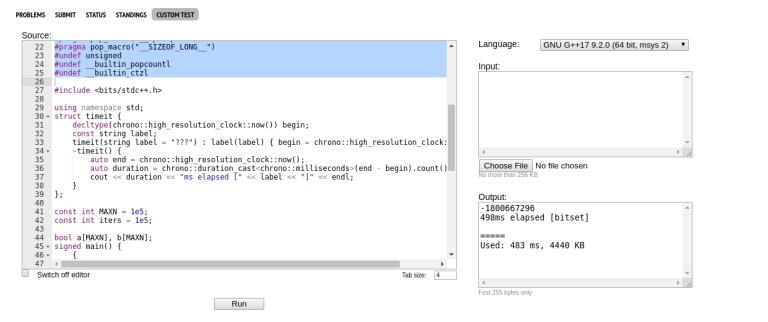
Can you post the exact code you're running? Do you have some pragmas?
Exact code including my memetemplate.
I always get around 600 ms and it's all on that nested loop I copypasted from you.
This isn't using bitsets. If your point is that my 64 bitsets template also gets 600ms, I'd note that my benchmark is with
MAXN=1e5anditers=1e5, while yours is withMAXN=1e4anditers=1e5.Strangely, it does seem like int arrays are faster than bool arrays. But still, on an equivalent benchmark, the 64 bit bitsets runs in 69ms while the for loop runs in 600ms.
I said "for the slow one". The slow code at the top. You say it's 3.6 seconds for you, I was pointing out that it's not that extreme of a difference for me for some reason (maybe the auto-optimisation I mentioned).
Ah, I see. As I mentioned, that's primarily due to the fact that you're using int arrays instead of bool arrays.
I don't really understand why.
I thought you were saying that the 64 bitset template didn't show improvements for you — my bad.
You're using int arrays in the code I copied, that's why. It almost never makes sense to use bool over char, btw — they take the same amount of memory and access time can't be better for bool.
It gets optimized to the same thing here: https://godbolt.org/z/yD8Myz
Do you have an example where your way is faster?
The OP says it runs in 3.6 seconds above, it runs in 0.6 for me. I posted the code above, you can run it under custom invocation. That's all.
Somehow none of the compilers I tried on Godbolt is able to optimize the outer loop in the first example into a multiplication: https://godbolt.org/z/jGM9Hf Any ideas on why? Some of the compilers unrolled the loop to some extent and MSVC appears to interchange the two loops, but all of the outputs contain two nested loops.
Compilers are often pretty stupid.
clang can optimize the loop out of this:
And I've seen compilers do other crazy stuff so I was surprised that none of the compilers figured out the inner loop was doing the same thing every time.
Compilers are pretty stupid considering that they're pretty smart.
It's nice being mentioned. I guess bitset solutions often come to me just because I'm too stupid to think of an intended solution. Surely will try that out!
I just searched for "bitset" on Codeforces to find a bitset solution that I could try plugging the template into and one of your comments came up :)
It still means not all of my comments are completely useless, so =)
Auto comment: topic has been updated by Chilli (previous revision, new revision, compare).
Actually using some of the intrinsics magic my solution using self-made simple version of bitsets is now the fastest to the mentioned problem.
How to join the server?? Could you provide the invite link.
How can I join the #constant-factor on the AC discord server? I want to join.