



Добро пожаловать на 2013-2014 CT S01E03: selected problems from 2002 Central European (CEPC 2002) + 2010 Southeast USA Region. Продолжительность тренировки — 5 часов. Тренировка открыта как для команд, так и для индивидуальных участников. После ее окончания вы можете дорешивать задачи тренировки или поучаствовать в ней виртуально, если не смогли принять участие одновременно со всеми. Пожалуйста, участвуйте в тренировке честно.
Так как это тренировка, то возможно набор задач будет расширен, если для значительного количества участников он окажется простым.
Регистрация на тренировку будет доступна со страницы Тренировки и будет открыта до окончания тренировки. Регистрируя команду, выберите именно тех её членов, кто будет писать тренировку.
Удачи!







Спасибо! А то я уже начал сомневаться, будет ли тренировка. Удобно, что они всегда стабильно по средам в четыре по Москве.
Как решать H?
Просто считать динамику от 3 параметров (сколько осталось, сколько у первого, сколько у второго). Значение динамики — маск. выигрыш, переходы — все, которые возможны по условию.
А как учитываются случаи, когда мы начинаем игру заново с новым числом пончиков? Не совсем понятно как наращивать число пончиков, если в итоге мы можем их не съесть, а на них сыграть.
Просто переходим в состояние (total, first, second) -> (second, 0, 0) (если первый выиграл текущую партию).
Спасибо! Я сдал с 4 параметрами (4-ый это кто ходит). Я видел решания с тремя. Как избавиться от 4 параметра? Интересно, можно ли делать такую динамику не рекурсией с меморизацией (например циклами)?
Избавиться от четвертого можно так: будем считать, что параметр сколько у первого — на самом деле сколько у того, кто сейчас ходит(при рекурсивном вызове обмениваем кол-во у первого и второго).
От рекурсии можно избавиться так: сначала делаем цикл по сумме параметров, потом по количеству штук в коробке, потом по количеству у первого игрока (у второго, соответственно, сумма — на столе — у первого).
Работает потому что при переходе либо уменьшается сумма (кто-то из игроков съел свою долю) либо сумма не меняется, но уменьшается количество в коробке.
Моё решение: http://mirror.codeforces.com/gym/100231/submission/4565739
а как вы написали с 4 параметрами? Можете описать переходы или код показать как-то?
Слабые тесты в задаче A!! Мое решение работает свыше 10 секунд на макс. тесте при запуске на CF, но получает AC. А я все сидел и отпимизил =(
Submitted solutions codes' not visible. Will they be visible later?
No, it will not. you can't see other people code in CF gym before get AC for this problem
Many solutions not visible...
Because you can only view a solution after you've solved a problem. It's really tiring to write this every time...
Can't we see the solutions to problems?
How to solve problem D, L?
L: Key observation: ans(L, R) = ans(1, R) — ans(1, L — 1).
So one can iterate over the number of ones in binary representation(let's call it C). If the current number of ones gives proper X value, then all what we need to do is to calculate the amount of numbers which have exactly C ones in binary representation and less or equal to R.
One can do this using dynamic programming(the state is (number of bits processed, number of ones used, is it equal to or strictly less than R)).
D: Let's say that team i gets xi balloons of type A and Ki - xi of type B. Then, the cost for that team is Ci = DA, ixi + DB, i(Ki - xi) = DB, iKi + xi(DA, i - DB, i). We need to minimize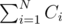 .
.
The first term is constant, so let's ignore it. Then, we can sort the teams and use a greedy approach: go from smallest DA, i - DB, i to largest. As long as DA, i - DB, i < 0, we give the team as many balloons as possible, so that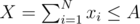 and xi ≤ Ki. Once we move on to DA, i - DB, i ≥ 0: for a valid solution, we need
and xi ≤ Ki. Once we move on to DA, i - DB, i ≥ 0: for a valid solution, we need 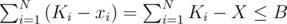 , but we don't want to increase X anymore when that's valid, because it increases the result. So if we can achieve that condition's validity by setting xi to some value ≤ Ki for some i, we do it; otherwise, it's best to set xi = Ki.
, but we don't want to increase X anymore when that's valid, because it increases the result. So if we can achieve that condition's validity by setting xi to some value ≤ Ki for some i, we do it; otherwise, it's best to set xi = Ki.
It needs careful checking of all conditions' correct combinations, but no extreme algorithms otherwise. Total running time: per test case.
per test case.
L: Observe that after the first iteration, any number will drop to at most 60, because there can be at most 60 ones in its binary representation. So we need to be able to calculate 2 things: "for given A and k, how many numbers in the interval [1, A] have exactly k > 0 ones in binary?" and "how many iterations does it take to get to 1 from k"?
The second part is easy, just bruteforce it. The first is quite tough. Number the bits of A as b0..m, where b0 is least significant. We go from bm to b0. For every bit, we have at most 2 choices: either the numbers we're interested in will have bits bi to bm equal to those of A, in which case we just continue on, or (only possible if bi = 1) we have the numbers with bi = 0 and all larger bits equal to those of A; those numbers will all be < A, so there is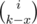 of them, where
of them, where 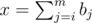 . So we need to calculate binomial coefficients up to around
. So we need to calculate binomial coefficients up to around 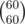 . That works in
. That works in 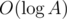 . Now, we can try all possible k, find out how many times we'll have number i after one iteration, and count how many of those take X - 1 more iterations to get to 1.
. Now, we can try all possible k, find out how many times we'll have number i after one iteration, and count how many of those take X - 1 more iterations to get to 1.
EDIT: Whoops, already answered. At least I've got a more detailed (and more chaotic :D) explanation.
About problem L, I have the idea exactly same as yours, however, I got WA on test 2 many times. Here's the link of my submission:LINK Can you help me fix the bug in my solution or can you share your code with me?(If so, you can send me message in CF). Thanks.
Ops, Sorry. I made a stupid mistake, when c == 1. Apology for bother.
Я поражён — в 2002 году поляки делали туры интереснее и красивее многих современных контестов. Задачи A, C, E и G — прекрасные.
А расскажите, пожалуйста, как решать A, C и E :)
С. Будем обходить граф в глубину, теперь все ребра будут либо в дереве обхода, либо будут обратными. Также будем считать для вершины время входа в нее и минимальное время выхода из нее или из какой-то вершины ее поддерева. Рассматриваем ребра, которые изначально не ориентированы. Если это обратное ребро, то мы всегда можем его ориентировать. Если это прямое ребро (v, u), то тогда мы можем его ориентировать тогда и только тогда, когда время выхода из u меньше или равно времени входа в v.
Твое решение на тесте
утверждает, что ни одному из двунаправленных ребер нельзя присвоить ориентацию. Но разве не правда, что если направить их по циклу 1-3-5-4-3-2-1, то все вершины будут достижимы друг из друга и при этом ответ улучшиться (т.к. уменьшится до нуля число ребер, которые мы оставили неориентированными)?
А что такое дерево обхода в ориентированном графе?
В А решение следующее. Вот пусть D[i][j] — степень сходства i-го монстра и j-го монстра. Тогда можно понять, что верно следующее:
Самая неприятная часть в задаче наступает когда вы смотрите на сэмплы и видите, что нужна грёбаная абсолютная точность. Я с этим справился, домножив ответ на 10600 и считая в целочисленной длинной арифметике (так как ответ — дробь со степенью двойки в знаменателе, это обеспечит целочисленность промежуточных результатов).
А ещё абсолютную точность можно достичь с использованием Java BigDecimal
Е. Давайте не для каждой вершины находить множество B(v), а для вершины находить вершины, в множества которых она входит. Для начала посчитаем d[col][v] — кратчайшее расстояние от вершины v до какой-нибудь вершины с r[v] >= col. Тогда как проверить, что вершина u подходит для множества B(v) вершины v. Это значит, что dist(u, v) < d[r[u] + 1][v]. Это очевидно. Теперь рассмотрим дерево кратчайших путей для вершины u. Пусть у вершина v подходит и у нее есть предок в дереве w. Длина ребра из предка len. Тогда dist(u, w) + len = dist(u, v). Мы знаем, что dist(u, v) < d[r[u] + 1][v]. Условие для того, чтобы подходило w: dist(u, w) < d[r[u] + 1][w] => dist(u, v) — len < d[r[u] + 1][w]. Не сложно заметить, что d[r[u] + 1][w] >= d[r[u] + 1][v] — len, иначе d[r[u] + 1][v] можно было бы обновить. Из этого получаем, что и w подходит. Из условия, что сумма размеров множеств не больше 30 * N получаем простое решение. Запускаем Дейкстру из очередной вершины u. И если в Дейкстре извлекаем вершины v, для которой мы не подходим, тогда просто не релаксируем из нее ничего.
И G :D
Давайте заметим следующее. Во-первых, потенциальных ответов — не более, чем deg[1], где deg[x] — степень вершины x. Это так, потому что нас просят фактически посчитать минимальные по включению отрезки на прямой времени среди всех возможных отрезков [start, end] по всем маршрутам из 1 в n. Любой такой маршрут где-то начинается, а именно он начинается с какого-то прямого рейса из 1 куда-то. А раз так, то всевозможных времён начал маршрутов из 1 в n ровно deg[1]. Фактически для каждого рейса из 1 в k надо посчитать минимальное время, за которое мы доберёмся до финиша из k.
Давайте считать динамику D[x][t] — это минимальное время, когда мы можем добраться до финиша, если мы оказались в x-ой вершине в момент времени t. Такая динамика пока работает слишком долго, но её можно соптимизировать следующим соображнием. Заметим, что для каждой вершины v нас интересуют только интересных моментов — это моменты, когда на неё приезжают какие-то рейсы и уезжают. Давайте оставим только те состояния для этой вершины, которые соответствуют её интересным моментам. Таким образом останется
интересных моментов — это моменты, когда на неё приезжают какие-то рейсы и уезжают. Давайте оставим только те состояния для этой вершины, которые соответствуют её интересным моментам. Таким образом останется  состояний динамики. Как пересчитывать? По умоланию D[x][t] = D[x][next[t]], где next[t] — следующий интересный момент. А если в момент времени t со станции x отходят электрички, то тогда D[x][t] = min(D[x][t], D[y][arrival]) по всем городам y, куда есть рейс, отходящий из x в момент времени t (arrival — время прибытия этого рейса). Итоговая сложность — O(M) плюс пара сортировок, которые, видимо, не нужны, так как в условии рейсы даны в хронологическом порядке.
состояний динамики. Как пересчитывать? По умоланию D[x][t] = D[x][next[t]], где next[t] — следующий интересный момент. А если в момент времени t со станции x отходят электрички, то тогда D[x][t] = min(D[x][t], D[y][arrival]) по всем городам y, куда есть рейс, отходящий из x в момент времени t (arrival — время прибытия этого рейса). Итоговая сложность — O(M) плюс пара сортировок, которые, видимо, не нужны, так как в условии рейсы даны в хронологическом порядке.
Ну и в конце нужно решить классическую задачу — оставить из K отрезков минимальные по включению (т. е. такие, что из итогового множества никакие два не вложены друг в друга). Это делается сортировкой отрезков по левому концу и проходом со стеком.
Благодарю.
Все гораздо проще. Давайте для каждой станции будем хранить указатель на последний поезд, который мы еще не отправили. Пойдем от 23:59 к 0:00 назад. Очевидно, что если мы применили какой-то маршрут для данного времени старта, то для более ранних времен он не имеет смысла, так как до финиша мы доберемся не раньше, чем для данного времени. Таким образом попав на какую-то станцию в какое-то время нам достаточно проверить все маршруты, исходящие с данной станции после данного времени и пометить их как пройденные. Одновременно если так делать, то мы автоматом получим невложенные отрезки
Меня не покидало ощущение, что можно сделать проще, если тупо пойти по времени назад. Ну вот прекрасно, значит это ещё более красивая задача с простым решением.
any ideas for solving B?
Greedy: sort the intervals by their ends, then process them in increasing order. Always add as few points into the set as necessary for the condition of that interval to be valid, and take them from the last one that you still haven't taken (that ensures that they intersect with as many of the unprocessed intervals as possible).
There are at most 50000 points to be added, so store them in a set. To find out how many points from the set are in an interval, use a Fenwick tree (BIT) for sums.
One can solve this problem with next greedy algorithm. Let's sort segments in increasing order of right end. When processing i-th segment let's see how many integers from that segment are already taken. If we have taken x integers from that segment and x < ci, we still need to add some numbers into set. Let's do that starting from the right end of the segment ri in decreasing order.
You may need some data structures for this solutions, for me it was enough to use set to store unused numbers and Fenwick tree for checking how many integers there are already in segment.
UPD: Xellos was faster =)
Let's sort our intervals [a;b] by b. Consider the first interval [a1;b1]. Obviosly, we must put points in positions {b1, b1-1, b1-2, ..., b1-c1+1}, because it will be better for future intervals. Now delete the first interval and continue our algorithm. If interval [ai; bi] has already ci points we do nothing. So, we need to find sum on a interval [ai; bi] and to put a points in the end of out interval. We can keep Fenwick tree and set with unused points. My implementation : http://ideone.com/NMYH6F UPD : Xellos and Zlobober were much more faster than me :D
Thank you all guys, got it accepted :)
What's the idea behind I ?
That's an easy one. Realize that we can split a palindrome of length L into 2 halves, of lengths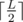 and
and 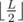 , where the 2nd one is uniquely defined by the first. We only need to consider 2 possibilities: either the result's first half is equal to the original string's first half (in which case the result might be a smaller palindrome and then it's not valid), or it's just larger by 1 (in which case it's definitely a larger palindrome); construct those 2 and choose the smaller one larger than the original string.
, where the 2nd one is uniquely defined by the first. We only need to consider 2 possibilities: either the result's first half is equal to the original string's first half (in which case the result might be a smaller palindrome and then it's not valid), or it's just larger by 1 (in which case it's definitely a larger palindrome); construct those 2 and choose the smaller one larger than the original string.
I would like to get emails about these trainings. Is there a way to subscribe?
How to solve Voracious Steve Problem ??? and what happens at n reduces to 1.
Dynamic programming. A state DP[i][j][k] is the maximum number of donuts Steve can eat, if there are i donuts in the box, Steve has j and Digit k donuts, and it's Steve's move. (If it isn't Steve's move and, he can eat i + j + k - DP[i][k][j] donuts — applying the optimal strategy for Digit.) Time O(N4).
Can you please write the full DP equation, Not able to get it.
Define S[i][j][k] = i + j + k - DP[i][k][j] (the result for the 2nd player). Now, if i = 0, then DP[0][j][k] = j + S[k][0][0]. Otherwise, DP[i][j][k] = minx = 0min(M, i){S[i - x][j + x][k]} if x < i, or j + i + S[k][0][0] if x = i.
Is it possible to get hints/solutions or tutorials for other GYM contest as well.
how to solve problem G ? my solution was as follow : for each edge compute the shortest time which can be start using this edge an arrived to city N. Finally, output inner intervals for edges from city 1. is that true ?