


Привет, Codeforces!
Осталась всего пара дней до 2025 года. Напоследок в этом году залечу с обновлением — надеюсь, оно окажется полезным.
Теперь в свой мэшап вы можете автоматически подбирать случайные задачи по ряду критериев и ограничений. Задачи берутся из архива, необычные задачи исключаются автоматически.
Итак, нажимайте ссылку "Добавить случайные задачи" под списком задач и переходите к форме добавления.
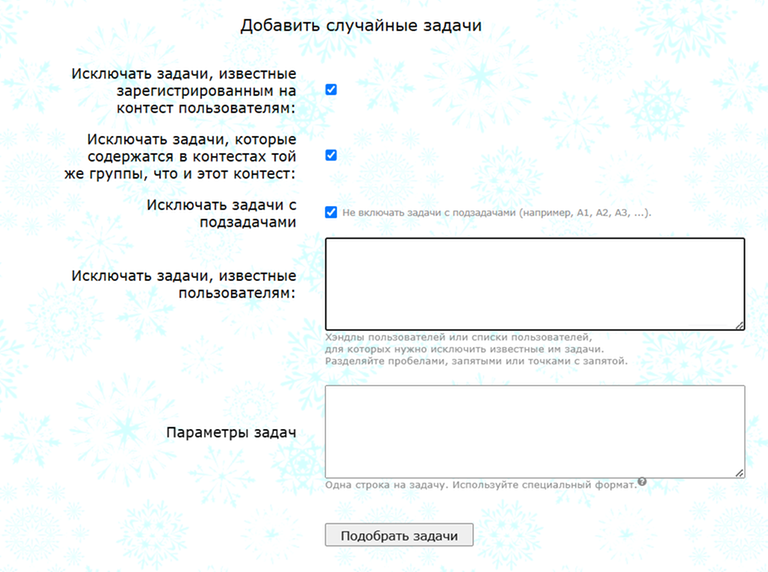
Здесь можно:
- исключить задачи, которые сдавали или пытались сдать зарегистрированные на мэшап участники (чтобы задача была исключена, достаточно одного зарегистрированного участника, который её может знать),
- если мэшап находится в группе (например, это группа ваших тренировок), то исключить все задачи из других контестов этой группы,
- исключить задачи с подзадачами — такие задачи часто как-то связаны между собой или ссылаются друг на друга,
- просто указать список хэндлов или списков пользователей, для которых нужно убрать известные им задачи,
- и, наконец, самое хитрое: в поле "параметры задач" можно указать в специальном формате требования к добавляемым задачам.
Поле "параметры задач" описывает количество и свойства задач, которые нужно найти. По клику на знак вопроса появится следующий поясняющий текст.
Введите одну или несколько строк. Каждая строка задаёт требования для одной задачи. Строка должна начинаться с латинской буквы p, после чего через пробел можно указать дополнительные параметры:
- Короткое название задачи (её букву в контесте);
- Требования к сложности задачи (например,
ratings:1000-1200,ratings:2000,ratings:3000-илиratings:-1000— отсутствие числа слева или справа от знака минус обозначает отсутствие соответствующей границы); - Теги (используйте
tags:и укажите список тегов через запятую, например,tags:dp, binary search, brute force) — будет выбрана задача, содержащая хотя бы один тег из списка. Названия тегов можно писать и на русском языке.
Примеры строк с требованиями:
"p"— произвольная задача, буква в контесте будет назначена автоматически;"p F"— произвольная задача, которой назначается букваF;"p ratings:2000-2400"— задача с уровнем сложности от 2000 до 2400, буква в контесте назначается автоматически;"p D ratings:-1200 tags:жадные алгоритмы,дп"— задача с уровнем сложности не более 1200, имеющая тегжадные алгоритмыилидп(или оба), которой назначается букваD.
При нажатии кнопки "Подобрать задачи" вам будет предложен список задач для добавления. Кнопку можно нажимать повторно для генерации другого списка. В этом списке вы можете отметить понравившиеся задачи и, наконец, добавить их в мэшап.
Обратите внимание, что рядом с кнопкой "Подобрать задачи" после нажатия на неё будет выведена дополнительная статистика, которая может помочь вам сориентироваться по рейтингам доступных задач в условиях заданных ограничений.
Надеюсь, теперь подбирать задачи для внутренних тренировок и соревнований станет проще.



