


Edit: I have realized that this blog has been sent quite a lot on discord servers, so I am adding a content page at the start to help organize this blog better.
Prerequisites
Let us first define the classical knapsack, unbounded knapsack and subset sum problems.
Subset Sum
There are $$$N$$$ items. The $$$i$$$-th item has weight $$$w_i$$$. Find a set $$$S$$$ such that $$$\sum\limits_{i \in S} w_i = C$$$.
Knapsack
There are $$$N$$$ items. The $$$i$$$-th item has weight $$$w_i$$$ and value $$$v_i$$$. Find a set $$$S$$$ such that $$$\sum\limits_{i \in S} w_i \leq C$$$ and $$$\sum\limits_{i \in S} v_i$$$ is maximized.
Unbounded Knapsack
There are $$$N$$$ items. The $$$i$$$-th item has weight $$$w_i$$$ and value $$$v_i$$$. Find a multiset $$$S$$$ such that $$$\sum\limits_{i \in S} w_i \leq C$$$ and $$$\sum\limits_{i \in S} v_i$$$ is maximized.
You should know how to do both versions of knapsack in $$$O(NC)$$$ and subset sum in $$$O(\frac{NC}{32})$$$ before reading this blog.
In this blog post, I will just show some results that speed up the above problems for special cases.
Content of this Blog
| Section | Result |
|---|---|
| Subset Sum Speedup 1 | Given $$$\sum w = C$$$, solve the subset sum problem of all values between $$$0$$$ and $$$C$$$ in $$$O(\frac{C \sqrt{C}}{32})$$$ |
| Subset Sum Speedup 2 | Given $$$w \leq D$$$, solve the subset sum problem for sum $$$C$$$ in $$$O(DC)$$$ |
| Knapsack Speedup 1 | Given knapsack where each item has $$$k_i$$$ copies and we need to find the best value with sum of weights less than $$$C$$$, we can solve in $$$O(\min(S \log S,N) \cdot S)$$$. |
| (max,+) convolution | Given $$$2$$$ arrays $$$A$$$ and $$$B$$$ of length $$$N$$$, find an array $$$C$$$ of length $$$2N-1$$$ such that $$$C_i = \max\limits_{j+k=i}(A_j+B_k)$$$. Generally, it is hard to do faster than $$$O(N^2)$$$, but if at least one of $$$A$$$ and $$$B$$$ is convex, we can solve in $$$O(N)$$$ using SMAWK. |
| Knapsack Speedup 2 | Suppose the number of distinct weights of items is $$$D$$$ and we need to find best value with sum of weights less than $$$C$$$. We can solve it in $$$O(DC)$$$. |
| Knapsack Speedup 3 | Suppose $$$w \leq D$$$ and we are allowed to take an item multiple times to find the best value with sum of weights less than $$$C$$$. Wr can solve it in $$$O(D^2 \log C)$$$. |
I would like to thank:
- tfg for his helpful discussions, digging through papers and implementing SMAWK.
- maomao90 for proofreading.
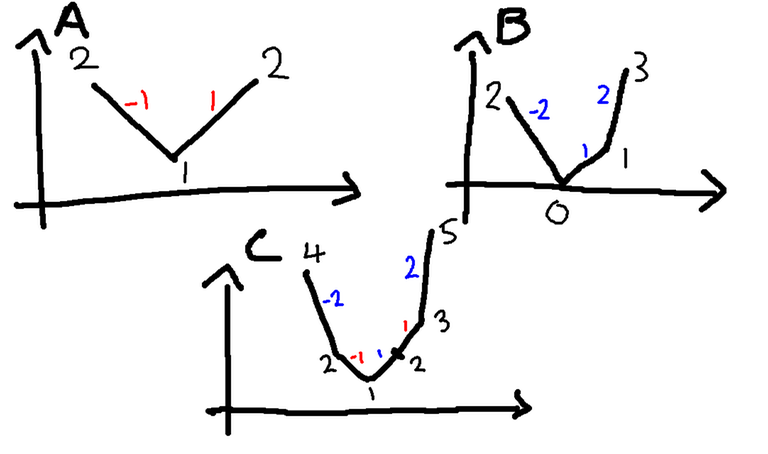
Subset Sum Speedup 1
There are $$$N$$$ items. The $$$i$$$-th item has weight $$$w_i$$$. Let $$$\sum\limits_{i=1}^N w_i=C$$$. For each $$$k \in [1,C]$$$, can we find a set $$$S$$$ such that $$$\sum\limits_{i \in S} w_i = k$$$?
It turns out we can do this in $$$O(\frac{C \sqrt C}{32})$$$.
Let us first consider an algorithm that seems like it is $$$O(\frac{C \sqrt C \log C}{32})$$$. We will group items of equal weights together, so we will get $$$M$$$ tuples of the form $$$(w_i,occ_i)$$$ where there are $$$occ_i$$$ occurrences of $$$w_i$$$ in the original items. For each tuple, we will decompose it into powers of $$$2$$$. For example, for $$$(w_i,15)$$$, we will decompose it into $$$\{w_i,2w_i,4w_i,8w_i\}$$$, for $$$(w_i,12)$$$, we will decompose it into $$$\{w_i,2w_i,4w_i,5w_i\}$$$. If you think about these things as binary numbers, it is not too difficult to see that we will get the same answers when we use these new weights instead of the original weights.
Furthermore, it is well known that if you have some weights that sum to $$$C$$$, then there are only $$$\sqrt{2C}$$$ distinct weights. So we can already determine that $$$M \leq \sqrt{2C}$$$. Since $$$occ_i \leq C$$$, we can figure out that each tuple will contribute $$$\log C$$$ elements. Giving up a simple upper bound of $$$O(\frac{C \sqrt C \log C}{32})$$$.
However, this is actually bounded by $$$O(\frac{C \sqrt C}{32})$$$ $$$^{[1]}$$$. Consider the set of tuples that contribute a weight $$$k \cdot w_i$$$, we will call this set $$$S_k$$$. We want to show that $$$\sum\limits_{k \geq 1} |S_k| = O( \sqrt C)$$$. Firstly, we note that most of the new weights will be a multiple of $$$2^k$$$ of the original weight, for each tuple, it will only contribute at most $$$1$$$ new weight that is not a power of $$$2$$$. Therefore, if we can show that $$$\sum\limits_{k=2^z} |S_k| = O(f(C))$$$, then $$$\sum\limits_{k \geq 1} |S_k| = O(f(C)+\sqrt C)$$$.
It is obvious that $$$\sum\limits_{i \in S_k} w_i \leq \frac{C}{k}$$$ and we can conclude that $$$|S_k| \leq \sqrt\frac{C}{k}$$$.
Therefore, $$$\sum\limits_{k=2^z} |S_k| \leq \sum\limits_{z \geq 0} \sqrt \frac{2C}{2^z} = \sqrt {2C} \left (\sum\limits_{z \geq 0} \frac{1}{\sqrt {2^z}} \right) = O(\sqrt C)$$$.
However, there is a simpler way to do this $$$^{[2]}$$$. Consider processing the weights from smallest to largest, with an initially empty list $$$W'$$$ as the list of our new weights. Suppose there are $$$occ$$$ occurrences of the smallest weight $$$w$$$. If $$$occ$$$ is odd, we add $$$\frac{occ-1}{2}$$$ occurrences of $$$2w$$$ to the original weights and $$$1$$$ occurrence of $$$w$$$ to $$$W'$$$. The case if $$$occ$$$ is even is similar, we add $$$\frac{occ-2}{2}$$$ occurrences of $$$2w$$$ to the original weights and $$$2$$$ occurrence of $$$w$$$ to $$$W'$$$.
It is not hard to see that $$$|W'| \leq 2 \sqrt {2C} = O(\sqrt C)$$$, since we only add at most $$$2$$$ occurences of some weight to $$$W'$$$.
Problems:
- CC MINFUND (testcases are super weak)
- CF755F
- CC TREUPS↵
Subset Sum Speedup 2
There are $$$N$$$ items. The $$$i$$$-th item has weight $$$w_i \leq D$$$. Can we find a set $$$S$$$ such that $$$\sum\limits_{i \in S} w_i = C$$$?
We will solve this in $$$O(ND)$$$ $$$^{[3]}$$$. Firstly, if $$$\sum\limits w_i \lt C$$$, the answer is obviously no, so we will ignore that case.
Let us find the maximal $$$k$$$ such that $$$\sum\limits_{i=1}^k w_i \lt C$$$. The basic idea is that we initially have an answer of $$$w_1+w_2+\ldots+w_k$$$, then we can either subtract $$$w_i$$$ for $$$i \leq k$$$ or add $$$w_i$$$ for $$$i \gt k$$$ in some order such that the cost of our items is in the range $$$[C-D,C+D]$$$, which is not too hard to show constructively. The proof sketch is just: if the current weight is more than $$$C$$$, remove something, otherwise add something.
Let us define $$$can(total,l,r)$$$ as a dp function that returns true iff there exists $$$\lambda_l,\lambda_{l+1}, \ldots, \lambda_r \in [0,1]$$$ such that $$$\sum\limits_{i=1}^{l-1}w_i + \sum\limits_{i=l}^{r} \lambda_i w_i = total$$$, where $$$total \in [C-D,C+D]$$$.
Notice that $$$can(total,l,r) = true$$$ implies that $$$can(total,l-1,r)=true$$$, this means that $$$can$$$ is monotone on the dimension $$$l$$$. Therefore, let us define a new dp function $$$dp(total,r)$$$ that stores the maximal $$$l$$$ such that $$$can(total,l,r)=true$$$.
Furthermore, $$$can$$$ is monotone on the dimension $$$r$$$, so $$$dp(total,r) \leq dp(total,r+1)$$$.
Let us consider the transitions.
From $$$dp(total,r)=l$$$, we can extend $$$r$$$, transitioning to $$$dp(total+w_{r+1},r+1)$$$ or $$$dp(total,r+1)$$$. We can also extend $$$l$$$ and transition to $$$dp(total-w_{l'},r)=l'$$$ for $$$l' \lt l$$$. However, this transition would be $$$O(N)$$$ per state, which is quite bad.
However, it would only make sense to transition to $$$dp(total-w_{l'},r)=l'$$$ for $$$dp(total,r-1) \leq l' \lt dp(total,r)=l$$$, otherwise this case would have been covered by another state and there would be no need for this transition. Since $$$dp(total,r) \leq dp(total,r+1)$$$, the total number of transitions by extending $$$l$$$ is actually bounded by $$$O(ND)$$$ using amortized analysis.
Therefore, our dp will have $$$O(ND)$$$ states with a total of $$$O(ND)$$$ transitions.
Actually there is a scammy way to do this. Similarly, we find the maximal $$$k$$$ such that $$$\sum\limits_{i=1}^k w_i \lt C$$$, then we want to solve the subset sum problem with the weights $$$\{-w_1,-w_2,\ldots,-w_k,w_{k+1},\ldots,w_N\}$$$ and sum $$$C- \sum\limits_{i=1}^k w_i$$$.
Let us randomly shuffle the list of weights and pretend $$$C- \sum\limits_{i=1}^k w_i$$$ is very small. Then this can be viewed as a random walk with $$$0$$$ sum. The length of each step is bounded by $$$D$$$, so we can expect $$$O(D \sqrt N)$$$ deviation from the origin (my analysis is very crude). Using bitsets, we can obtain a complexity of $$$O(\frac{ND \sqrt N}{32})$$$ which is probably good enough.
The paper also mentions a way to generalize this technique to knapsack where weights are bounded by $$$D$$$ and values are bounded by $$$V$$$ in $$$O(NDV)$$$ but I think it is not a significant speedup compared to the usual knapsack to be used in competitive programming.
Problems:
- GP of Bytedance 2020 F
- ABC221G
- NCPC21E (Thank you nigus)
Knapsack Speedup 1
Consider SG NOI 2018 Prelim knapsack.
The editorial solution is to only consider $$$O(S \log S)$$$ items, since only $$$\frac{S}{w}$$$ items for a certain weight $$$w$$$ can be used, to get a complexity of $$$O(S^2 \log S)$$$. But I will discuss a slower $$$O(NS)$$$ solution.
Let $$$dp(i,j)$$$ be the maximum value of items if we only consider the first $$$i$$$ types using a weight of $$$j$$$.
Then our transition would be $$$dp(i,j)=\max\limits_{0 \leq k \leq K_i}(dp(i-1,j-k\cdot W_i)+k\cdot V_i)$$$. If we split each $$$dp(i,j)$$$ into the residue classes of $$$j \% W_i$$$, it is easy to see how to speed this up using the sliding deque trick or using an RMQ.
Now, let us talk about a more general speedup. But first, we will have to introduce a convolution that appears frequently in dp.
(max,+) convolution
The problem statement is this: Given $$$2$$$ arrays $$$A$$$ and $$$B$$$ of length $$$N$$$, find an array $$$C$$$ of length $$$2N-1$$$ such that $$$C_i = \max\limits_{j+k=i}(A_j+B_k)$$$.
Doing this in $$$O(N^2)$$$ is easy. Can we do better? It seems that doing this faster is a really hard problem and so far the fastest known algorithm is a very scary $$$O(\frac{n^2}{\log n})$$$ or $$$O(\frac{n^2 (\log \log n)^3}{(\log n)^2})$$$, which does not seem practical for competitive programming.
Note that $$$(\max,+)$$$ and $$$(\min,+)$$$ convolution are not too different, we can just flip the sign. In the rest of this section, I will use $$$(\min,+)$$$ convolution to explain things.
First, we note that if both arrays $$$A$$$ and $$$B$$$ are concave, then we can do this convolution in $$$O(N)$$$ time $$$^{[5],[6]}$$$. The basic idea is we can consider the union of the slopes of the lines $$$\{A_i - A_{i-1} \} \cup \{B_i - B_{i-1} \}$$$ and sort them to get the slopes of $$$C$$$.
Another way to reason about this is using epigraphs (fancy word for colour everything above the line), which I find more intuitive. Because if we take the epigraph of $$$A$$$ and $$$B$$$, we get $$$2$$$ convex polygons, taking their Minkowski sum gets us the epigraph for $$$C$$$ and finding Minkowski sum on convex polygons is well known as taking the union of their edges, which is why this is also known as the Minkowski sum trick.
This speedup can be used in several dp problems such as ABC218H and JOISC18 candies. Furthermore, this can be abused in several dp problems where we can think of slope trick as $$$(min,+)$$$ convolution so we can store a priority queue of slopes such as in SG NOI 2021 Finals password. Another more direct application is CF1609G.
Anyways, we can actually solve $$$(\min,+)$$$ convolution quickly with a weaker constraint that only $$$B$$$ is convex.
First, let us discuss a $$$O(N \log N)$$$ method.
Define a $$$i$$$-chain as the line segment with points $$$\{(i+1,A_i+B_1),(i+2,A_i+B_2),(i+3,A_i+B_3),\ldots \}$$$. Then I claim that $$$2$$$ chains only intersect at a point, which is the sufficient condition for using Li Chao tree to store these lines $$$^{[7]}$$$.
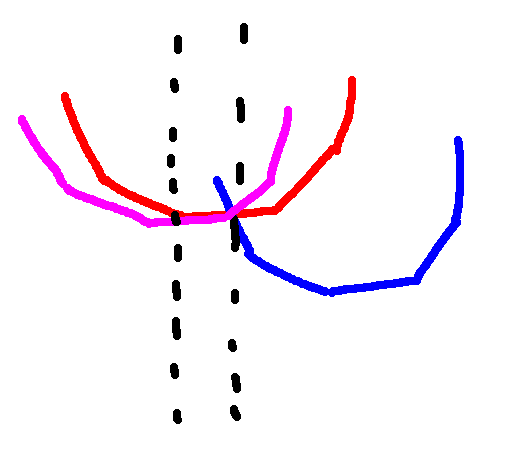
Let us prove that this is actually true. Let the equation for the $$$i$$$-chain be $$$f_i(x)$$$, so $$$f_i(x)$$$ is a convex function. We want to show that for $$$g(x)=f_i(x)-f_j(x)$$$, there exists $$$k$$$ such that $$$g(x) \lt 0$$$ for $$$x \lt k$$$ and $$$0 \leq g(x)$$$ for $$$k \leq x$$$ whenever $$$i \lt j$$$.
$$$g(x)=(A_i+B_{x-i})-(A_j+B_{x-j})=(B_{x-i}-B_{x-j})+(A_i-A_j)$$$.
Consider $$$g(x+1)-g(x)=(B_{x+1-i}-B_{x-i})-(B_{x+1-j}-B_{x-j})$$$. Recall that $$$B$$$ is convex (i.e. $$$B_{x+1}-B_x \geq B_{x}-B_{x-1}$$$). Since we have assumed that $$$i \lt j$$$, we can conclude that $$$(B_{x+1-i}-B_{x-i}) \geq (B_{x+1-j}-B_{x-j})$$$. Therefore, $$$g(x+1)-g(x) \geq 0$$$, i.e. $$$g$$$ is a (non-strict) increasing function.
Therefore, we can insert all chains into a Li Chao Tree and find the convolution in $$$O(N \log N)$$$.
Now, we will consider an $$$O(N)$$$ method. We will have to use the SMAWK algorithm $$$^{[8]}$$$ which I will not explain because the reference does a better job at this than me. Here I will actually use $$$(\max,+)$$$ convolution to explain.
Anyways, the result we will be using from SMAWK is that given an $$$N \times M$$$ matrix $$$X$$$ that is totally monotone, we can find the minimum value in each row.
A matrix is totally monotone if for each $$$2 \times 2$$$ sub-matrix is monotone i.e. for $$$\begin{pmatrix} a & b \\ c & d \end{pmatrix}$$$:
- If $$$c \lt d$$$, then $$$a \lt b$$$
- If $$$c = d$$$ then $$$a \leq b$$$
The way I think about this is consider the function $$$\sigma(x)=\begin{cases} 1, & \text{if } x \gt 0 \\ 0, & \text{if } x = 0 \\ -1 , & \text{if } x \lt 0 \end{cases}$$$. We pick $$$2$$$ columns $$$1 \leq i \lt j \leq M$$$ and consider writing down $$$[\sigma(H_{1,i}-H_{1,j}), \sigma(H_{2,i}-H_{2,j}), \ldots, \sigma(H_{N,i}-H_{N,j})]$$$. Then this sequence should be increasing when $$$i \lt j$$$.
Now given the arrays $$$A$$$ and $$$B$$$, we define a $$$2N-1 \times N$$$ matrix $$$X$$$ such that $$$X_{i,j}=A_{i}+B_{i-j}$$$. It is clear that the row minimas of $$$X$$$ are the answers we want. It can be shown that if $$$B$$$ is convex, $$$X$$$ is totally monotone $$$^{[9]}$$$. I would just remark the proof is basically the same as the proof writen for the case on Li Chao Trees.
Here is a template for SMAWK written by tfg for $$$(\max,+)$$$ convolution with a single concave array.
Knapsack Speedup 2
Now, we can talk about which special case of knapsack we can speed up.
There are $$$N$$$ items. The $$$i$$$-th item has weight $$$w_i$$$ and value $$$v_i$$$. Find a set $$$S$$$ such that $$$\sum\limits_{i \in S} w_i \leq C$$$ and $$$\sum\limits_{i \in S} v_i$$$ is maximized.
Furthermore, the number of distinct weights is $$$D$$$. Then, we have a $$$O(DC)$$$ solution $$$^{[9]}$$$. Usually $$$D=O(N)$$$, but maybe there are some special conditions such as $$$w_i$$$ being small, such that we can bound $$$D$$$.
We will start with $$$D=1$$$. This has an obvious greedy solution of putting the largest value first. Let's suppose the values are $$$v_1,v_2,\ldots$$$ with $$$v_1 \geq v_2 \geq \ldots$$$ and they all have weight $$$w$$$. To make the sum of items become $$$kw$$$, the answer is $$$\sum\limits_{i=1}^k v_i$$$.
Therefore, it is easy to extend this to $$$O(DC)$$$ by performing $$$(\max,+)$$$ convolution with $$$B=[0,v_1,v_1+v_2,\ldots]$$$ on each residue class modulo $$$w_i$$$. We will perform $$$w_i$$$ convolutions and each convolution will take $$$O(\frac{C}{w_i})$$$ time since $$$B$$$ is concave and we are doing $$$(\max,+)$$$ convolutions. So each distinct weight we only need $$$O(C)$$$ time to process it.
Consider there to be $$$4$$$ items. $$$w=\{2,2,3,3,3\}$$$ and $$$v=\{5,1,7,10,2\}$$$. Initially $$$A=[0,-\infty,-\infty,\ldots]$$$.
We process $$$w_i=2$$$, $$$B=[0,5,6]$$$. Then $$$A=[0,-\infty,5,-\infty,6,-\infty,\ldots]$$$.
We process $$$w_i=3$$$, $$$B=[0,10,17,19]$$$. Then $$$A=[0,-\infty,5,10,6,15,17,16,22,19,\ldots]$$$.
Please note that we cannot assume that the sequence $$$[A_i,A_{i+w_i},A_{i+2w_i},\ldots]$$$ is convex which is shown by the above example.
Problems:
Knapsack Speedup 3
There are $$$N$$$ items. The $$$i$$$-th item has weight $$$w_i \leq D$$$. Find a multiset $$$S$$$ such that $$$\sum\limits_{i \in S} w_i \leq C$$$ and $$$\sum\limits_{i \in S} v_i$$$ is maximized.
We can solve this in $$$O(D^2 \log C)$$$ $$$^{[9]}$$$. Note that when we talk about convolution, we are refering to $$$(\max,+)$$$ convolution in $$$O(D^2)$$$ complexity. (I believe Algorithm 2 in the reference has a slight error and I have emailed the paper authors.)
Let us define $$$ans_i$$$ as the optimal answer with sum of weights being $$$i$$$. The main observation is that $$$ans_i=\max\limits_{j+k=i}(ans_j,ans_k)$$$, but we can actually impose a constraint that $$$|j-k| \leq D$$$ without loss of correctness. Suppose that $$$j-k \gt D$$$, then we can "move" an item from $$$ans_j$$$ to $$$ans_k$$$. This process can be repeated until $$$|j-k| \leq D$$$. Actually this can be generalized to $$$|j-k - \alpha| \leq D$$$ for some arbitrary $$$\alpha$$$ with the exact same constructive proof (of course we will assume reasonable values for $$$\alpha$$$).
Therefore, we can convolute $$$[ans_{i-\frac{D}{2}}, ans_{i-\frac{D}{2}+1}, \ldots, ans_{i+\frac{D}{2}}]$$$ with $$$[ans_{j-\frac{D}{2}}, ans_{j-\frac{D}{2}+1}, \ldots, ans_{j+\frac{D}{2}}]$$$ to get the value of $$$ans_{i+j}$$$.
From this, we have several extensions. We can convolute $$$[ans_{T-D}, ans_{T-D+1}, \ldots, ans_{T}]$$$ with $$$[ans_0,ans_1,\ldots,ans_{2D}]$$$ to get the values for $$$[ans_{T+1}, ans_{T+2}, \ldots, ans_{T+D}]$$$ (there are probably many off by one errors so just pad them with $$$\pm 5$$$ or something). We can also convolute $$$[ans_{T-D}, ans_{T-D+1}, \ldots, ans_{T+D}]$$$ with itself to get the values for $$$[ans_{2T-D}, ans_{2T-D+1}, \ldots, ans_{2T}]$$$.
We can get the array $$$[ans_0,ans_1,\ldots,ans_{2D}]$$$ in $$$O(D^2)$$$ by using the normal knapsack dp.
Since we have a method of "doubling", which allows us to obtain a complexity of $$$O(D^2 \log C)$$$ to compute the array $$$[ans_{C-D},ans_{C-D+1},\ldots,ans_{C}]$$$, which is sufficient to find our answer.
Problems:
References
- https://mirror.codeforces.com/blog/entry/49793?#comment-337754
- https://mirror.codeforces.com/blog/entry/49793?#comment-337790
- https://sci-hub.yncjkj.com/10.1006/jagm.1999.1034
- https://arxiv.org/pdf/1212.4771.pdf
- https://mirror.codeforces.com/blog/entry/75925?#comment-602354
- https://mirror.codeforces.com/blog/entry/98334
- https://cp-algorithms.com/geometry/convex_hull_trick.html
- http://web.cs.unlv.edu/larmore/Courses/CSC477/monge.pdf
- https://arxiv.org/pdf/1802.06440.pdf







Thank for your blog!
I found a typo in your blog. Maybe CF775F will be CF755F. May you update it?
updated. thanks for pointing out this typo
Could you please teach me how to solve this problem?
Update: Solved. Sorry for bothering.
Here you can submit NCPC21E
Thank you very much for this blog!
A very minor nitpick: the algorithm from "Subset Sum Speedup 2" section actually finds the largest sum not exceeding $$$C$$$, doesn't just check if a set with sum $$$C$$$ exists.
And here is a more substantial nitpick: towards the end of "(max,+) convolution" when you start describing how to build a totally monotone matrix to feed it to SMAWK, the linked paper simply says "...Consider the matrix $$$A$$$ with $$$A_{ij} = a_j +b_{i−j}$$$, where we suppose that elements of the sequences with out-of-bounds indices have value $$$- \infty$$$." (they need row maxima, hence the negative infinity).
But this is wrong! The matrix constructed this way will not be totally monotone, which you can easily see by looking at a 2x2 submatrix with three $$$\infty$$$ in it. The infinities added "above" the matrix must be strictly increasing and those added "below" must be decreasing(in each row). Also, the "lower" and "upper" infinities must always compare the same way, doesn't matter how exactly.
For min-plus convolution, if $$$a$$$ and $$$b$$$ are both convex we convolve with minkowski sum. If $$$a$$$ and $$$b$$$ are both concave we just check the two boundary values. If only $$$b$$$ is convex we run smawk. But what if only $$$b$$$ is concave? I tried to adapt 1D1D for it but candidates having a "lifetime" breaks the process. Is there something obvious I'm missing or is this hard like the general case?
Figured it out. Run left-to-right concave 1d1d (with a stack) on the prefix $$$c[0,M)$$$, right-to-left on the suffix $$$c[N-1,N+M-1)$$$, then interlace left-to-right and right-to-left batches on ranges like $$$c[kM,kM+M)$$$. This visits each "interior" $$$c_k$$$ twice. Runs in $$$O(N\log M+M)$$$. 163722679
can somebody share with me an easy implementation of subset sum speedup 1 i knew that root c is the upper bound for distinct elements but how will we choose root c elements?
I recently implemented this technique here.