


Hi Codeforces,
This Saturday the 9th of may, starting at 13.00 CEST we will hold a mirror of the Benelux Freshmen Programming Contests. It is an ICPC-style contest lasting $$$4$$$ hours.
The problemset was made in collaboration with alumni and students from Dutch universities, and was used as a Freshmen Programming Contest at some Dutch and Belgian universities. The problems are designed to be a gentle introduction to competitive programming while on the harder end still being a challenge for experienced participants. In terms of codeforces ratings it should be similar to division $$$3$$$, but with a slightly wider difficulty range (easier and harder problems).
You are free to make an account and compete on this website: https://fpcs2026.bapc.eu/public (the website will be up sometime later this week). The contest was designed for teams of at most $$$3$$$ people without internet access. Feel free to use the internet in the mirror, but please refrain from using AI.
Hope to see you on the scoreboard!






 Left halve solution for $$$n=15$$$.
Left halve solution for $$$n=15$$$. Solution for middle toy and $$$n=15$$$.
Solution for middle toy and $$$n=15$$$. Full solution for right halve for $$$n=15$$$.
Full solution for right halve for $$$n=15$$$.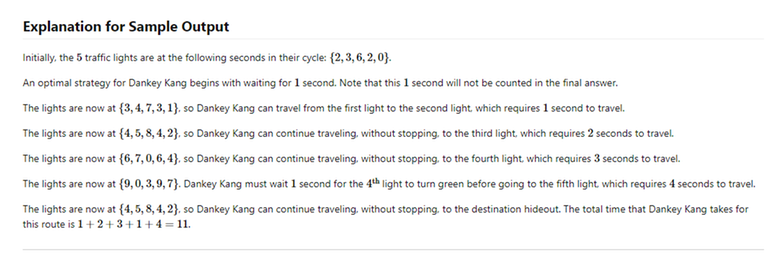

 You can check it out here:
You can check it out here: 