Hi Codeforces!
This is a blog about a really cool folklore technique that seems to have been forgotten over time. I currently only know of one place where it is mentioned on the internet, https://www.algonotes.com/en/minimal-memory-dp/, which is a tutorial by monsoon for his problem "Matchings" https://dmoj.ca/problem/ontak2010sko from a POI training camp in 2010 (see this for more information). But I've heard that this technique is even older than that. I originally learnt of this technique a couple of years back when I was digging through the fastest submissions on 321-C - Ciel the Commander and I saw it being used in a submission 9076307 by Marcin_smu from 2014. I don't know if there is a name for this technique, so I've decided to call it the XOR Linked Tree because of its close connection to XOR linked lists https://en.wikipedia.org/wiki/XOR_linked_list.
The XOR Linked Tree is a technique for solving tree problems using very little time and memory. For example, every fastest solution in the "Tree Algorithms" section on https://cses.fi/problemset/ currently use this technique. So it is record breaking fast!
The idea:
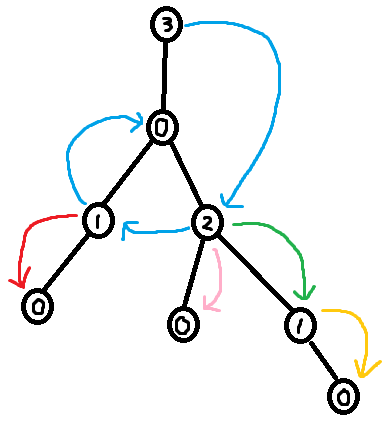
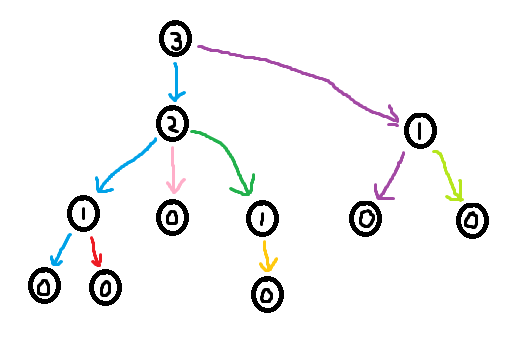
Suppose in the input of a problem, you are given a tree as $$$n - 1$$$ edges. To construct the XOR Linked Tree data-structure from this, you go through all of the edges and compute the following two things for every node in the tree:
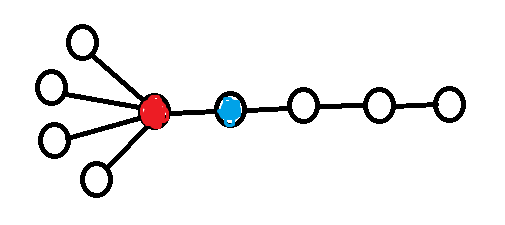
deg[node] = The degree of the node.xor[node] = The XOR of all neighbours of the node.
Storing this will only take $$$2 n$$$ integers, so this is very cheap memory wise compared to using an adjacency list. It is also really fast, since there are no expensive .push_back/.append calls.
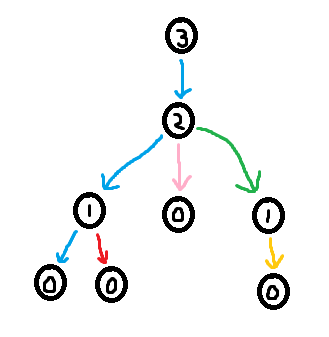
Claim: Using deg and xor, it is possible to reconstruct the tree.
Proof: Identify a leaf node in the tree (this can be done by finding a node with degree 1 in deg). Note that a leaf only has one neighbour, so the XOR of all of its neighbours is simply that neighbour. I.e. the neighbour of a leaf is xor[leaf]. Now remove this leaf from the tree ("pluck it") by lowering the degree of its neighbour by one (deg[neighbour] -= 1) and XORing away the leaf from xor[neighbour] (xor[neighbour] ^= leaf). Now we can just repeat this process of plucking leaves until there a single node left. We have now reconstructed the original tree.
Here is an implementation of the process described in the proof above ^
for i in range(n):
node = i
# While node is a leaf
while deg[node] == 1:
nei = xor[node]
# Pluck away node
deg[node] = 0
deg[nei] -= 1
xor[nei] ^= node
# Check if nei has become a leaf
node = nei
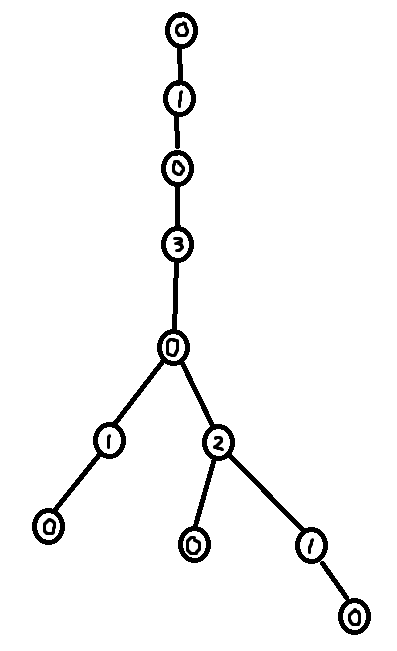
Something to note is that it is possible to control which node is left at the end (the "root") by setting its degree to 0 before running the algorithm. So the final XOR Linked Tree traversal algorithm is
deg[root] = 0
for i in range(n):
node = i
# While node is a leaf
while deg[node] == 1:
nei = xor[node]
# Pluck away node
deg[node] = 0
deg[nei] -= 1
xor[nei] ^= node
# Check if nei has become a leaf
node = nei
This is it! This is the entire algorithm! The deg list is now completely 0 (except for deg[root] which can be negative) and the xor list now contains the parent of every node.
Discussion
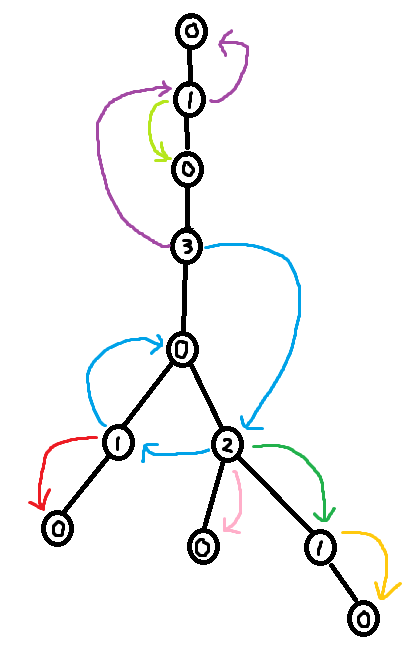
This tree traversal algorithm is different compared to BFS or DFS. For one, it doesn't use anything like a queue or a stack. Instead it simply removes one leaf at a time using a while loop inside of a for loop. The order you traverse the nodes in is kind of like doing a BFS in reverse, but it is not exactly the same thing.
Discussion (Advanced)
One last thing I want to mention is that on some tree problems, you specifically need a DFS ordering. For example, there are tree problems on cses.fi that requires you to compute LCA. Most (if not all) algorithms/data-structures for computing LCA are based on DFS. So is it still possible to use XOR Linked Tree traversal algorithm for these kind of problems?
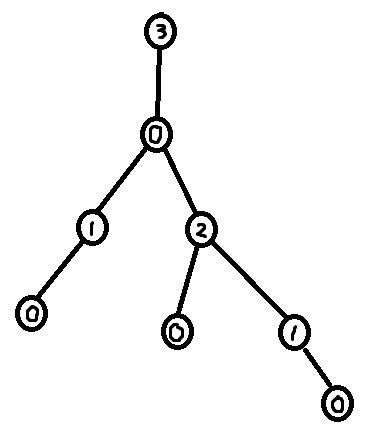
The answer is yes, it is possible to use the XOR Linked Tree traversal algorithm to compute a DFS ordering. The trick is to first compute the sizes of all subtrees, and then use this information to compute the index of each node in a DFS ordering.
# Store the order of the plucked nodes in the XOR Linked Tree traversal
XOR_traversal_order = []
deg[root] = 0
for i in range(n):
node = i
# While node is a leaf
while deg[node] == 1:
nei = xor[node]
# Pluck away node
XOR_traversal_order.append(node)
deg[node] = 0
deg[nei] -= 1
xor[nei] ^= node
# Check if nei has become a leaf
node = nei
# Compute subtree sizes
subtree_size = [1] * n
for node in XOR_traversal_order:
# Note that xor[node] is the parent of node
p = xor[node]
subtree_size[p] += subtree_size[node]
# Compute the index each node would have in a DFS using subtree_size
# NOTE: This modifies subtree_size
for node in reversed(XOR_traversal_order):
p = xor[node]
subtree_size[node], subtree_size[p] = subtree_size[p], subtree_size[p] - subtree_size[node]
DFS_traversal_order = [None] * n
for node in range(n):
DFS_traversal_order[subtree_size[node] - 1] = node
This might be one of the weirdest ways to do a DFS ever. But it is blazingly fast!
Benchmark
Here are some benchmarks based on https://judge.yosupo.jp/problem/tree_diameter
| Python Benchmark | Time | Memory | Submission link |
|---|---|---|---|
| XOR Linked Tree | 315 ms | 188.93 Mib | 243487 |
| BFS with adjacency list | 1076 ms | 227.96 Mib | 243489 |
| DFS (stack) with adjacency list | 997 ms | 228.90 Mib | 243490 |
| DFS (recursive) with adjacency list | 2119 ms | 731.60 Mib | 243496 |
| C++ Benchmark | Time | Memory | Submission link |
|---|---|---|---|
| XOR Linked Tree | 31 ms | 15.50 Mib | 243281 |
| Adjacency list (vector) | 97 ms | 59.54 Mib | 243277 |
| Adjacency list (basic_string) | 89 ms | 58.62 Mib | 243285 |
| "Chinese adjacency list" | 73 ms | 45.24 Mib | 243280 |
| Compressed Sparse Row | 69 ms | 66.15 Mib | 243621 |
Credits
Thanks to everyone who has discussed the XOR Linked Tree with me over at the AC server! rewhile, nor, drdilyor, ToxicPie9. Credit to rewhile for helping me put together the C++ benchmark. Also, thanks jeroenodb for telling me about these notes https://www.algonotes.com/en/minimal-memory-dp/.