


I found a small shortage of materials in English on this topic and I want to start with translated article of rationalex:
The problem
We want to learn how to compare root trees for isomorphism (equality up to the renumbering of vertices + the root of one tree necessarily goes to the root of another tree).
Hash of vertex
Note that since we cannot appeal to the vertex numbers, the only information we can operate on is the structure of our tree.
We will consider as a hash of a vertex without children some constant (for example, 179), and for a vertex with children we will use as a hash some function from the sorted list of hashes of children (since we do not know the true order in which the children should go, we need to bring them to the same form). The hash of the root tree will be considered the hash of the root.
By construction, the hashes of isomorphic root trees coincide (the author leaves the proof by induction on the number of levels in the tree to the reader as an exercise).
Polynomial hash is not suitable
Consider 2 trees:
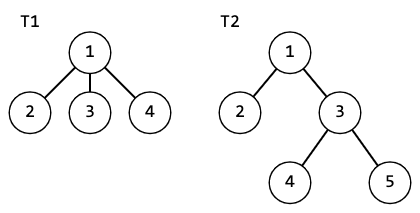
If we calculate for them to take a polynomial hash as a function of children, we get: $$$h(T1)=179+179p+179p^2=179+p(179+179p)=h(T2)$$$
Which hash is suitable?
As a good hash function, for example, this is suitable
For this hash function, it may seem that it is possible not to sort the hashes of children, but this is not the case, because when calculating floating-point numbers, we have an error, and in order for this summation result to be the same for isomorphic trees, it is also necessary to sum the children in the same order.
An example of a more complicated hash function:
Asymptotics
All we need to do at each level is sorting the vertices by hash value and summing, so the final complexity is: $$$O(|V|log(|V|))$$$
I want to continue on my own:
In the reality of Codeforces, these approaches have problems in the form of hacks (which can be seen, for example, by hacks of this task). Therefore, I want to talk about an approach in which there are no collisions.
What is this magic hash function?
Let's sort the hashes of the children for the vertex and match the number to this array, which we will consider the hash of the vertex (if the array is new, then we will assign it the minimum unoccupied number, otherwise we will take the one that has already been given).
Why does it work fast?
It is easy to notice that the total size of the arrays that we counted is $$$n - 1$$$ (each addition is a transition along the edge). Due to this, even using treemap for mapping, all accesses to it will require a total of $$$O(n \cdot log(n))$$$. Comparing a key of size $$$sz$$$ with another key works in $$$O(sz)$$$ and such comparisons for each key will occur $$$O(\log(n))$$$ times, and the sum of all $$$sz$$$, as we remember, is $$$n-1$$$, so it turns out a total of $$$O(n\cdot \log(n))$$$. (You might think that it is worth using hashmap, but this does not improve the asymptotics and causes the probability of a collision).



