


We hope you participated and enjoyed the changes made to monthly Long Contests. We had made some changes to the long contest format to make it more exciting. 10 problems for 10 days! It now has everything for everyone, be it a newbie or a veteran You can read more about it in here.
Continuing from there, we bring you the CodeChef June 2012 Long Challenge. The June 2012 Algorithm Challenge is taking place on http://www.codechef.com/JUNE12.
Here are the details:
Date: 1st June 2012 to 11th June 2012
Duration: 10 days
Problems: 9 binary problems of varying difficulty levels + 1 challenge problem.
Problem Setter: IstvanNagy (iscsi), Namit Shetty(shettynamit), Hiroto Sekido (LayCurse), Kaushik Iska (cauchyk), Vitaliy Herasymiw, Duc/ Shilp Gupta, Shanjingbo.
Problem Tester: Anton Lunyov (Anton_Lunyov),
It promises to deliver on an interesting set of algorithmic problems with prizes up for grabs.
The contest is open for all and those, who are interested, are requested to register in order to participate.
Check out the local time in your City/Time Zone here. Do share your feedback on what you feel about the new long contest format at feedback@codechef.com
Good Luck! Hope to see you participating
In case you have not yet checked our new forums please do so here. `







I suggested next flashmob. Everybody insert this comment at the beginning of you submit:
I'm seriously, is there really a reason to have such ancient hardware?.. I really like your long contests, but it's very boring — to waste as much time on optimising, as it needed on writing. It's also bad that solution, working ~0.3 second locally, here on CF, everywhere you can launch it, has TLE with 3 seconds on your testing system.
I guess it's even more than 9 year old.
Every contest I have that problem.
If there were any way to run the solutions, it would somehow help us. But you can't just estimate the runtime on the server.
I agree. However, it's some kind of fun for me to optimize and to guess what solution — rather simple O(n) or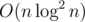 with very small constant will get OK instead of TL.
with very small constant will get OK instead of TL.
But I suppose that the 'Run custom solution on a custom test' will be very and very helpful.
I agree with you the time limits misleading, but (I think) the problems setting for the servers, so I don't think you should optimize your code because the servers are slow :) .
On the other side the topcoders servers are too fast. :)
I don't say that that I recieve TLE just because servers are slow :-) But it's a bit sad, when you can't predict, how much time would 2 million operations take, and will it pass 3 second (!) time-limit. All the sense of complexity and speed of algorithms, obtained from experience in other contests, becomes useless, because you can't just abstractly slow down your solution 42 times in your mind: some operations are slower 10 times on P3 rather then on modern processor, and some of them are slower 50 times.
Okay, sorry maybe I missunderstood you. :) I'm lucky (?!) because my pc's is less than 2 times faster than the server, so for me its easier to predict. I like yeputons idea very much, so I think we should suggest that. ( What I see codechef try to improve their site very much new forum etc so the guys work really hard on that the best programmers (e.g you ;) ) participate their event too, so maybe they will try to do this option, if they don't want to spend lot of money to buy faster servers:) )
The problem is not on Codechef AFAIK, they use SPOJ testing servers/system
SPOJ Server : P III 733MHz
If SPOJ uses same servers for judging codechef solutions then you can estimate the runtime of your solution on actual judge by creating a dummy problem ( with large time limit )on SPOJ with your input-output file and compare the runtime shown by SPOJ status with the runtime obtained by executing code on your system with same input-output. Speed of sorting, binary_search, map, set, arithmetic operations can also be roughly estimated using this way. That looks idiotic and irrelevant but can be tried in long contest and free time :)
Look at this thread, sometimes you need to optimize too much to get AC :-/
Contest has ended.
Please everybody, who correctly answers on 10k or more queries in CLOSEST, tell, what did you do for that? The best I got was hard-optimised K-D tree with some breaks if we are looking through too big number of vertices.
It seems that different heuristics should rule here; but my big problem is that I can't efficently find them in such a type of problems :-(
The K-D tree should score around 15k. Maybe the problem is in precision(double) or overflow(int64->unsigned int64).
For 24k I used a tree similar to K-D tree, but instead of cutting space with a plane I used a sphere (I think the tree is actually called Vintage point tree).
My last submissions are kind of funny, cause I'm still puzzled why they get ~42k. I simply divided the space using the plane that passes through the midpoint of two random points (and of course perpendicular to the segment formed by them) + break in case the number of iterations between the updates of distances are above threshhold.
I don't know may be it is the reason but most of the tests were generated as follows. We take some circle and choose response centers near to it (with different perturbation radius for different tests) then banks are chosen near the line that passes through the center of this circle perpendicular to it. The trickiness of this test is that when no perturbations are made, for each bank all response are of the same distance to it. So when we do some small perturbation it seems that it should be quite hard to determine the closest point. And it was really so because KD-tree completely failed on these tests :P
I think it would be a good idea to specify inputs a bit more precise, specifically, problem statement says "In some tests coordinates are uniformly distributed within its range while other tests created specifically to fail certain heuristics." which less or more leave impression that there are some substantial amount of random tests
Yes we usually try to follow these scheme sometimes even with explicit description of test case generation but for this problem we were afraid that revealing of any idea how test data are generated can allow to find the solution that get perfect score within a time limit. Hence the description was so obscure. Sorry.
P.S. In fact there were only 2 random tests among 17 :)
игнор