


Problem A(div 2) — LLPS
It's assumed that this problem can be solved just looking at the samples and without reading the statement itself :)
Let's find the letter in the given string which comes last in the alphabet, denote this letter by z. If this letter occurs p times in the given string, then the answer is string a consisting of letter z repeated p times.
Why is it so? Using the definition of lexicographical comparison and the fact that z is the largest letter in the string it's easy to understand that if some other subsequence b of the given string is lexicographically larger than a, then string b should be longer than a and, moreover, a should be a prefix of b (that is, b should start with a). But string b must be a palindrome, therefore its last letter must be z. In this case string b must contain more occurrences of letter z than the original string s does, which is impossible as b is a subsequence of s.
Besides that, the constraint on the length of the string was very low, so the problem could be solved using brute force. For every subsequence of the given string it's necessary to check whether it's a palindrome, and from all palindromic subsequences of s the lexicographically largest should be chosen as the answer. The complexity of such a solution is O(2n·n), where n is the length of the string (unlike the solution above with complexity O(n)).
Problem В(div 2) — Brand New Easy Problem
The constraints in this problem were so low that a solution with complexity O(m·kn) was just fine. In each problem's description it's enough to loop over all possible subsequences of words which are permutations of words in Lesha's problem, for each of them calculate the number of inversions and choose a permutation with the smallest number of inversions. This can result in a short solution using recursion or, for example, you can use several nested loops (from 1 to 4).
Here is an example of pseudocode for n = 4:
w - array of words of Lesha''s problem
s - the description of the current problem
best = 100
for a = 1 to k do
for b = 1 to k do
for c = 1 to k do
for d = 1 to k do
if s[a] == w[1] and s[b] == w[2] and s[c] == w[3] and s[d] == w[4] then
inversions = 0
if a > b then inversions = inversions + 1
if a > c then inversions = inversions + 1
if a > d then inversions = inversions + 1
if b > c then inversions = inversions + 1
if b > d then inversions = inversions + 1
if c > d then inversions = inversions + 1
if inversions < best then
best = inversions
At the end you should choose the problem with the smallest value of best and print the answer in the corresponding form.
Problem A(div 1)/C(div 2) — Clear Symmetry
It's interesting that originally the authors had an idea not to include the x = 3 case into pretests. Imagine the number of successful hacking attempts in this contest -- considering the fact that none of the first 43 solutions to this problem passed pretests :)
Note that the sought n is always an odd number. Indeed, if n is even, then two central rows of matrix A must contain zeroes, otherwise there will exist two neighbouring cells containing ones. Similar restriction applies to two central columns of matrix A. Replacing two central rows with just one and two central columns with just one and leaving zeroes in them, we'll obtain a smaller matrix with the same sharpness.
Note that the sharpness of a matrix with side n can't exceed 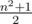 . It's easy to see that it's possible to lay out
. It's easy to see that it's possible to lay out 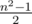 "domino pieces" 1 by 2 without intersections on a field with side n (in other words, all cells except one can be divided into pairs so that each pair contains neighbouring cells). Then there can be at most one one in the cells under each "domino piece" in the corresponding matrix. Therefore, the total number of ones doesn't exceed
"domino pieces" 1 by 2 without intersections on a field with side n (in other words, all cells except one can be divided into pairs so that each pair contains neighbouring cells). Then there can be at most one one in the cells under each "domino piece" in the corresponding matrix. Therefore, the total number of ones doesn't exceed 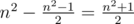 .
.
Note that a matrix with side n and sharpness exists for an odd n. Paint all cells of the matrix in chess order and put ones into black cells and zeroes into white cells. It's easy to see that such a matrix is both clear and symmetrical and has sharpenss exactly .
Intuitively it seems that if there exists a matrix with sharpness there should also exist a matrix with every smaller sharpness. That's correct except only one case -- there doesn't exist a matrix with side 3 and sharpness 3, though there exists a matrix with side 3 and sharpness 5.
Let's show that the claim above is correct for odd n ≥ 5. We'll build a matrix with sharpness as shown above and gradually turn ones into zeroes reducing the sharpness. Cells containing ones in the matrix can be divided into three types.
The first type is the central cell. The number in it can be turned into zero and the matrix won't stop satisfying the required conditions.
The second type is the cells in the central row and the central column (except central cell). Such cells are divided into pairs by the condition of symmetry -- if we turn the number in one of them into zero, we should turn the number in its pair cell into zero as well.
The third type is all the other cells. Such cells are divided into groups of four by the condition of symmetry -- if we turn the number in one of them into zero, we should turn the number in all cells from this group into zero as well.
Now for obtaining the required sharpness of x we'll act greedily. Let's turn ones into zeroes in third type cells by four until the current shapness exceeds x by less than 4 or there are no third type cells with ones remaining. After that let's turn ones into zeroes in second type cells by pairs while the current sharpness exceeds x by at least 2. At this moment the sharpness of our matrix is either x or x + 1. If it's equal to x + 1, let's put a zero into the central cell and obtain a matrix with sharpness x. It's easy to check that we'll be able to obtain a matrix with any sharpness acting this way.
Why is this reasoning incorrect for n = 3? Because second type cells are absent in the matrix with sharpness 5 obtained from chess coloring. For n ≥ 5 this matrix contains cells of all types, which is important for the algorithm above. It's better to find the answers for x ≤ 5 by hand but carefully -- for example, a lot of contestants decided that the answer for x = 2 is 5 instead of 3.
Problem В(div 1)/D(div 2) — Guess That Car!
We need to find such x and y that the value of 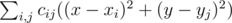 is minimum possible. This expression can be rewritten as
is minimum possible. This expression can be rewritten as 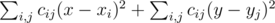 . Note that the first part doesn't depend on y and the second part doesn't depend on x, so we can minimize these parts separately. Here is how to minimize
. Note that the first part doesn't depend on y and the second part doesn't depend on x, so we can minimize these parts separately. Here is how to minimize 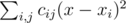 , the second part is minimized similarly. As the expression in the brackets doesn't depend on j, this part can be rewritten as
, the second part is minimized similarly. As the expression in the brackets doesn't depend on j, this part can be rewritten as 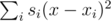 , where
, where 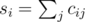 . Now it's enough to calculate the required value for all possible values of x and choose x for which this value is the smallest. The optimal value of y can be found similarly.
. Now it's enough to calculate the required value for all possible values of x and choose x for which this value is the smallest. The optimal value of y can be found similarly.
The overall complexity of this solution is O(n·m + n2 + m2).
As the objective function is convex, other approaches to this problem are possible, for example, ternary search, gradient descent or analytical approach (calculation of derivatives).
The main hero of this problem is Ra16bit.
Problem С(div 1)/E(div 2) — Fragile Bridges
There are a few different ways to solve this problem, the editorial contains one of them.
For any solution the following fact is useful. Suppose the sought path starts on platform i and ends on platform j (i ≤ j, if that's not the case, we can reverse the path). Then all bridges between platforms i and j will be passed through an odd number of times, and all other bridges will be passed through an even number of times.
Let's find the maximum length of a path with its ends on platforms i and j. To do that, let's find the following auxiliary values for each platform: lefti -- the maximum length of a path starting and ending on platform i and passing only through bridges to the left of platform i; rightj -- similarly for bridges to the right of platform j. Also for each bridge define oddi as the largest odd number not larger than ai, and for each platform define sumOddi as the sum of oddj for all bridges to the left of platform i.
Then the maximum length of a path with its ends on platforms i and j is equal to lefti + rightj + (sumOddj - sumOddi), or, which is the same, (rightj + sumOddj) + (lefti - sumOddi).
Now we can find the pair (i, j) for which this value is the largest in linear time. Let's loop over j. From the formula it's obvious that we should find such i ≤ j that (lefti - sumOddi) is the largest. If we loop over j from 1 to n, we can maintain the largest value of this expression for all i ≤ j and recalculate it when moving to the next j, comparing (leftj - sumOddj) with the current maximum and possibly updating this maximum. This way for each j we have to check only one value of i and not all i ≤ j.
The last thing to show is how to find all lefti quickly (all rightj can be found similarly). Clearly left1 = 0, then we'll calculate lefti using lefti - 1. Note that when ai - 1 = 1, we have lefti = 0 as after passing the bridge to platform (i - 1) this bridge will collapse and it will be impossible to return to platform i. If ai - 1 > 1, then lefti = lefti - 1 + eveni - 1, where eveni - 1 is the largest even number not larger than ai - 1. Indeed, we can move to platform (i - 1), then move along the path corresponding to lefti - 1, and then move along the bridge between platforms (i - 1) and i until the limit on the number of transitions is less than 2 (finishing on platform i).
The overall complexity of this solution is O(n).
Problem D(div 1) — Brand New Problem
The first solution coming to mind is dynamic programming f[i][j] = (the smallest possible number of inversions to the moment if among the first j words of the archive problem we've found a permutation of words included in bitmask i). In this solution parameter j varies from 0 to 500000, parameter i varies from 0 to 215 - 1 and calculation of each value is possible in O(1) (we are either using the current word in the subsequence or not). That's too much.
Let's make use of a standard technique: make the value of DP a new parameter and make one of the existing parameters the value of DP. Not for every DP this is possible, but at least it's possible for this one :)
It's clear that with a fixed subset of words and a fixed number of inversions it's optimal to choose the first occurrences of these words giving this number of inversions. Let f[i][j] = (the smallest number z such that among first z words of the archive problem there exists a permutation of words from bitmask i containing exactly j inversions). The basis of this DP is f[0][0] = 0, f[0][j] = ∞ for j > 0. Recalculation of values happens in the following way: loop over a word q from the bitmask i which was the last in the permutation. With the knowledge of this word and the number of inversions j it's easy to find how many inversions j' there were without this word — that's j minus the number of words in the mask which appeared later in Lesha's problem than word q. Let p = f[i^(1«q)][j']. Then we should consider p2 equal to the position of the next occurrence of word q after position p as a possible value for f[i][j]. To find p2 quickly we should fill an array next[500010][15] so that next[i][j] = (the smallest position k > i such that the k-th word in the archive problem equals the j-th word in Lesha's problem) for each archive problem in advance. This array can be easily filled passing from right to left once.
The total number of operations can be calculated as m·(k·n + 2n·Cn2·n), where m is the number of problems in the archive, k is the number of words in one archive problem description and n is the number of words in Lesha's problem description. Under the given constraints that is about 200 million operations, and the author's solutions (including a Java solution) worked for less than 2 seconds. The time limit was set with a margin -- 5 seconds.
The main heroes of problems D(div 1) and B(div 2) are Chmel_Tolstiy and ivan.metelsky.
Problem E(div 1) — Thoroughly Bureaucratic Organization
Let's imagine that we have a magic function maxN(m, k) that returns, given m and k, the largest value of n such that it's possible to solve the problem for n people and m empty lines in the form using k requests. Then we'll be able to use binary search on the answer -- the number of requests k.
Suppose we've made k requests. Let's match a string of length k to each person, where the i-th character is equal to 1 if this person is mentioned in the i-th request and 0 otherwise. Note that we'll be able to determine the exact appointment date for each person if and only if all n strings of length k are pairwise distinct. Indeed, if two persons' strings are the same, their appointment dates could be exchanged and the responses to the requests wouldn't have changed. If all strings are distinct, for each date we may find the person appointed for this date looking at the set of requests with responses containing this date and finding the person mentioned in the same set of requests.
The constraint on m empty lines in the form means that each of k positions in the strings should contain no more than m ones in all n strings overall. Thus function maxN(m, k) should return the maximum size of a set of distinct k-bit strings meeting this condition. Let's make this restriction weaker: we'll search for a set such that the total number of ones in all n strings doesn't exceed k·m. As we'll prove later, the answer won't change.
With this weaker restriction the problem can be solved using a simple greedy strategy. It's obvious that strings with smaller number of ones are better. Let's loop over the number of ones i in the string from 0 to k and also maintain a variable t containing the remaining number of ones (initially it's equal to k·m). Then at the i-th step we can take at most 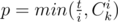 strings containing i ones. Let's add p to the answer and subtract p·i from t. Note that the values of Cki should be calculated with care -- they can turn out to be too large, so it's important not to allow overflows.
strings containing i ones. Let's add p to the answer and subtract p·i from t. Note that the values of Cki should be calculated with care -- they can turn out to be too large, so it's important not to allow overflows.
It can be shown that the overall complexity of this algorithm is at most O(log2 n).
The remaining thing is to prove the claim above. The idea of the proof below belongs to rng_58 (the author's proof is notably harder).
Let's solve the problem with a greedy algorithm with the k·m constraint on the total number of ones. The resulting set of strings may not satisfy the restriction of m ones for each position. If it doesn't, some of the positions contain more than m ones and some contain less than m ones. Let's pick any position X containing more than m ones and any position Y containing less than m ones. Find all strings containing 1 at X and 0 at Y (suppose there are x such strings) and all strings containing 0 at X and 1 at Y (suppose there are y such strings). It's clear that x > y. In each of x strings we can try to put 0 at X and 1 at Y -- then the string we obtain will either remain unique in this set or coincide with one of those y strings (but only one). As x > y, for at least one of x strings the change above leaves this string unique. Let's take this string and put 0 at X and 1 at Y. Now position X contains one 1 less, and position Y contains one 1 more. It means that the total number of "extra" ones in the positions has been decreased (as Y still contains no more than m ones). Doing this operation for a needed number of times, we'll achieve our goal.







Thanks for publishing editorial! There are some mistakes in text. It seems [user:] function is broken and is not working properly so that links to users are not created. Or is it a problem from my side and other users don't have any problems with it?!
I think there is problem in ur side because I can see the users in colors with their profile links ..Ofcourse ,Unless I am too late to answer , which I dont assume otherwise the blog author must have replied to u ..
There is a strange bug with Codeforces Markup which has been already reported to MikeMirzayanov. Anyway, I've fixed it in this blogpost by adding a couple of linebreaks :)
i am still not able to understand the solution of Div 2 problem C. Can anyone please explain me in a more detailed way. Please :)
Can someone explain Div2- C. It is not clear for me too.
anyone please tell me what following line of code is doing
this line is from rng_58's solution of problem D.
Another solution for E?
If the problem can be solved by brute force why does it appear in tag of binary search and how to solve it using binary search :)
Which problem are you referring to?