We hope everyone enjoyed the problems of XIII UnB Contest Mirror! This editorial contains the description of the solutions and their implementation. Feel free to discuss them in the comments!
Problem A
- Author: PedroPacoca
- Coauthor: duduFreire
In this problem, we want to count the number of strings of length $$$n$$$ that have at least one occurrence of the given substring. To do this, we will use the Knuth-Morris-Pratt (KMP) algorithm and the automaton constructed from it, with a complexity of $$$O(m)$$$.
If $$$n$$$ were small, we could solve this problem using dynamic programming, calculating, for each $$$1 \leq i \leq n$$$, how many ways we can reach state $$$0 \leq j \leq m$$$ of the automaton (representing a string with the last $$$j$$$ characters equal to the first $$$j$$$ of $$$s$$$). This solution has $$$n \cdot m$$$ states with transitions of the size of the alphabet, resulting in a time complexity of $$$O(26 \cdot n \cdot m)$$$, which is too slow for this problem, since $$$n$$$ can go up to $$$10^{18}$$$.
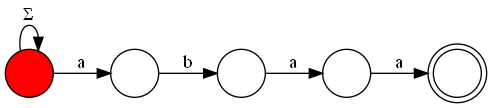
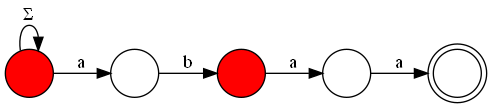
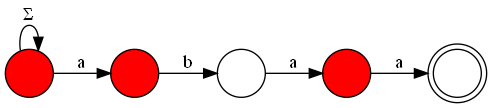
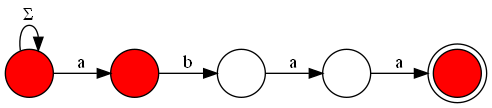
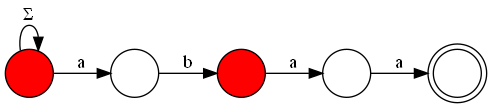
Therefore, we need a faster way to solve this problem, which can be achieved by visualizing the KMP automaton as a graph. In this graph, we will have all the states of the automaton as nodes, and the transitions as edges. Additionally, to ensure that we do not count repeated strings or miss counting strings that do not end in the acceptance state (but have passed through this state at least once), we add a new node that will hold all strings that have passed through the acceptance state at least once. Thus, the acceptance state must have an edge to this final state, and to count all the possibilities of strings that have passed through this state once, the final state must have $$$26$$$ edges directed to itself, one for each letter of the alphabet.
Let $$$A$$$ be the adjacency matrix of the constructed graph. We know that $$$A^k$$$ will contain the number of paths of length $$$k$$$ between any two vertices. From this, we can observe that the answer to the problem will be the number of paths of length $$$n+1$$$ from the initial state of the automaton to our final state, since we must consider all letters used in the string and also the additional step between the acceptance state and the final state. We can calculate the matrix $$$A^{n+1}$$$ using the fast exponentiation algorithm with matrix multiplication, resulting in a final complexity of $$$O(m + m^3 \cdot \log(n))$$$, which is sufficient for the limits of this problem.
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int MAXM = 100;
int MOD = 998244353;
// exponenciacao de matrizes para contar o numero de caminhos no automato
struct Matrix {
int r, c;
vector<vector<int>> mat;
Matrix(int n, int m, bool id = false): r(n), c(m), mat(r, vector<int>(c, 0)) {
if (id) {
for (int i = 0 ; i < min(r, c) ; i++)
mat[i][i] = 1;
}
}
Matrix operator*(const Matrix &o) {
assert(c == o.r);
Matrix result(r, o.c);
for (int i = 0 ; i < r ; i++) {
for (int j = 0 ; j < o.c ; j++) {
ll sum = 0;
for (int k = 0 ; k < c ; k++)
sum = (sum + (1LL * mat[i][k] * o.mat[k][j])) % MOD;
result.mat[i][j] = sum;
}
}
return result;
}
};
Matrix binpow(Matrix a, ll b) {
Matrix res(a.r, a.c, true);
while (b) {
if (b&1) res = res * a;
a = a * a;
b >>= 1;
}
return res;
}
// KMP automata
int automata[MAXM+1][26];
vector<int> kmp(string s) {
int n = s.size();
vector<int> pi(n, 0);
for (int i = 1 ; i < n ; i++) {
int j = pi[i-1];
while (j > 0 && s[j] != s[i]) j = pi[j-1];
j += (s[i] == s[j]);
pi[i] = j;
}
return pi;
}
void build_aut(string s) {
s.push_back('#');
int n = s.size();
vector<int> p = kmp(s);
for (int i = 0 ; i < n ; i++) {
for (int c = 0 ; c < 26 ; c++) {
if (i > 0 && c+'a' != s[i]) automata[i][c] = automata[p[i-1]][c];
else automata[i][c] = i + (c+'a' == s[i]);
}
}
}
int main() {
ll n;
int m;
string s;
cin >> n >> m;
cin >> s;
build_aut(s);
// no nosso grafo, precisamos de um vertice a mais
// para "prender" todos os matchings que ja foram feitos
// assim nao contamos repetido ou deixamos de contar algumas strings
// entao no estado de matching temos que colocar uma aresta para esse estado final
Matrix adj(m+2, m+2);
for (int i = 0 ; i < m ; i++) {
for (int c = 0 ; c < 26 ; c++) {
adj.mat[i][automata[i][c]]++;
}
}
adj.mat[m][m+1] = 1;
adj.mat[m+1][m+1] = 26;
Matrix paths = binpow(adj, n+1);
cout << paths.mat[0][m+1] << '\n';
return 0;
}
Problem B
- Author: arthur_9548
If $$$AB$$$ has $$$2$$$ or $$$4$$$ digits, the answer is certainly unique: the first half is $$$A$$$ and the second half is $$$B$$$. The reason for this is that both numbers must have between $$$1$$$ to $$$2$$$ digits.
The most complicated case is when $$$AB$$$ has three digits: $$$XYZ$$$. One can manually check the cases $$$XY-Z$$$ and $$$X-YZ$$$ by verifying that the numbers are between $$$1$$$ and $$$99$$$ and are not written with leading zeros. If both meet the conditions, print $$$-1$$$, otherwise print the separation that meets the statement.
s = input()
if len(s) == 3:
if s[1] == '0': print(s[:2], s[2:])
elif s[2] == '0': print(s[:1], s[1:])
else: print(-1)
elif len(s) < 3: print(s[0], s[1])
else: print(s[:2], s[2:])
Problem C
- Author: arthur_9548
This problem can be solved using dynamic programming (DP).
We can calculate the best answer for all prefixes of the list; the answer for prefix $$$i$$$ will be $$$dp_i$$$. For the first prefix: $$$dp_1 = max(A_1, 0)$$$. Then, we iterate from $$$2$$$ to $$$N$$$ making $$$dp_i = max(A_i + dp_{i-K}, dp_{i-1})$$$ (if $$$i \leq K$$$, consider $$$dp_{i-K}$$$ as $$$0$$$).
This represents that the best answer for prefix $$$i$$$ is the best between choosing song $$$i$$$, using the best answer up to $$$K$$$ positions back, and not choosing it, simply maintaining the best answer calculated up to the previous prefix. This works because the best answer can only increase by adding a new song to the prefix, so we can only look at the best answer calculated $$$K$$$ positions back or the last calculated one.
The limits of the problem were chosen so that DP states $$$N$$$ and $$$K$$$ will also pass within the time limit.
#include<bits/stdc++.h>
using namespace std;
int main(){
ios_base::sync_with_stdio(0); cin.tie(0);
int n, k; cin >> n >> k;
vector A(n, 0ll);
for(auto& x : A)cin >> x;
vector dp(n, 0ll); // best prefix answer
dp[0] = max(A[0], 0ll);
for(int i = 1; i < k; i++)dp[i] = max(A[i], dp[i-1]);
for(int i = k; i < n; i++)dp[i] = max(A[i]+dp[i-k], dp[i-1]);
cout << dp.back() << endl;
}
Problem D
- Author: cebolinha
Imagine that Arthur's favorite sequence is $$$[1, 3, 2]$$$. Is it possible to shift the message $$$[4, 5, 6]$$$ so that Arthur's sequence appears? It is not possible. Analyzing the shifted versions of $$$[4, 5, 6]$$$, we can see that the differences between adjacent values remain constant. The second value will always be $$$1$$$ more than the first, and the third will always be $$$1$$$ more than the second.
Thus, the sequence $$$[1, 3, 2]$$$ could only appear in a section of the message that has the same differences between adjacent values, meaning the second value is $$$2$$$ more than the first and the third is $$$1$$$ less than the second.
We can take a vector $$$DB$$$, corresponding to the adjacent differences in sequence $$$B$$$, and search for occurrences of it in $$$DA$$$, a vector corresponding to the adjacent differences in message $$$A$$$. We can do this with any string matching algorithm, such as Z-Function, KMP, or Polynomial Hashing.
For each detected match, we must determine what shift would allow for that occurrence. To do this, we find the character in $$$A$$$ corresponding to the start of this match and subtract the first character of $$$B$$$ from that value. We can maintain a vector that contains the number of occurrences of each shift so that in the end we can find the largest one.
#include <bits/stdc++.h>
using namespace std;
const int MOD = 1e4;
const int MAXN = 1e6;
array<int, MOD> cnt;
array<int, MAXN> A, B;
array<int, 2*MAXN-1> S;
array<int, 2*MAXN-1> PI;
void prefix_function(array<int, 2*MAXN-1> const& S, int len) {
for (int i = 1; i < len; i++) {
int j = PI[i-1];
while (j > 0 && S[i] != S[j]) j = PI[j-1];
if (S[i] == S[j]) j++;
PI[i] = j;
}
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
int N, M;
cin >> N >> M;
for (int i = 0; i < N; i++) cin >> A[i];
for (int i = 0; i < M; i++) cin >> B[i];
for (int i = 0; i+1 < M; i++) {
S[i] = B[i+1]-B[i];
if (S[i] < 0) S[i] += MOD;
}
S[M-1] = -1;
for (int i = 0; i+1 < N; i++) {
S[i+M] = A[i+1]-A[i];
if (S[i+M] < 0) S[i+M] += MOD;
}
int len = (M-1)+1+(N-1);
prefix_function(S, len);
for (int i = M; i < len; i++) {
if (PI[i] == M-1) {
int A_idx = i - M - (M-2);
int delta = B.front() - A[A_idx];
if (delta < 0) delta += MOD;
cnt[delta]++;
}
}
int best = max_element(cnt.begin(), cnt.end()) - cnt.begin();
cout << best << ' ' << cnt[best] << endl;
}
Problem E
- Author: arthur_9548
The total number of operations is at most $$$100$$$, so quadratic implementations should also pass the time and memory limits.
The problem can be implemented using a list of lists, inserting elements at the end of them according to the statement. In operation type $$$1$$$, an empty list is added to the list of lists, and in type $$$2$$$, an integer $$$x$$$ is added to list $$$i$$$. By keeping all the lists, fulfilling operation type $$$3$$$ becomes simple: just access the $$$j$$$-th element of list $$$i$$$.
Given the problem's limits, one can simulate this list of lists by fixing that it will have $$$100$$$ lists of size $$$100$$$ each, initially filled with zeros. Operation type $$$1$$$ can be completely ignored, and for type $$$2$$$, it is enough to change the value of the first position filled with a zero in list $$$i$$$ to $$$x$$$.
q = int(input())
l = []
for _ in range(q):
line = [int(i) for i in input().split()]
if line[0] == 1: l.append([])
if line[0] == 2:
i, x = line[1]-1, line[2]
l[i].append(x)
if line[0] == 3:
i, j = line[1]-1, line[2]-1
print(l[i][j])
Problem F
- Author: j3r3mias
For each vertex $$$s$$$, the algorithm performs a BFS for each neighbor $$$u$$$ in the graph without $$$s$$$. Then, the smallest cycle that contains $$$u$$$ and $$$s$$$ is given by the shortest distance to some neighbor $$$v$$$ of $$$s$$$, where $$$v\neq u$$$. Thus, the smallest cycle that contains $$$s$$$ is the smallest cycle obtained by the algorithm described.
For each vertex:
- Number of neighbors: $$$deg(s)$$$
- Each BFS: $$$O(N + M)$$$
Therefore, the cost per vertex $$$s$$$ is $$$O(deg(s) \cdot (M+M))$$$, and the complexity is:
#include <bits/stdc++.h>
using namespace std;
#define FASTIO ios::sync_with_stdio(false); cin.tie(nullptr)
#define pb push_back
#define endl '\n'
typedef long long ll;
const int INF = 0x3f3f3f3f;
int n, m;
vector<int> G[1005];
int bfs(int s) {
vector<int> neighbors = G[s];
if (neighbors.empty()) {
return 1;
}
vector<int> dists(1005, -1);
queue<int> q;
int ans, start, u, w;
ans = INF;
for (int i = 0; i < neighbors.size(); i++) {
start = neighbors[i];
dists.assign(1005, -1);
while (!q.empty()) {
q.pop();
}
dists[start] = 0;
q.push(start);
while (!q.empty()) {
u = q.front(); q.pop();
for (int v : G[u]) {
if (v == s) {
continue;
}
if (dists[v] == -1) {
dists[v] = dists[u] + 1;
q.push(v);
}
}
}
for (int j = i + 1; j < neighbors.size(); j++) {
if (dists[neighbors[j]] != -1) {
ans = min(ans, dists[neighbors[j]] + 2);
}
}
}
if (ans == INF) {
return 1;
}
return ans;
}
int main() {
FASTIO;
int a, b, c;
cin >> n >> m;
for (int i = 0; i < m; i++) {
cin >> a >> b;
G[a].pb(b);
G[b].pb(a);
}
ll ans = 0;
for (int i = 1; i <= n; i++) {
c = bfs(i);
// cout << "Ciclo minimo que contem " << i << ": " << c << endl;
ans += i * c;
}
cout << ans << endl;
return 0;
}
Problem G
- Author: emershowjr02
To solve this problem, we need to maximize the quality function of a gelato, which is defined as $$$\min_{x \in E} \, (x) \; \cdot \; |E|$$$, adhering to the restrictions given by the derangement.
From the permutation, we can describe a graph where the edges indicate that the ingredients represented by the vertices cannot be used together in the recipe. Thus, we have some important properties of the graph:
- Each vertex has degree $$$2$$$.
- The graph is formed by disjoint cycles.
- In a cycle of size $$$|C|$$$, the maximum number of vertices we can select without violating the restrictions (i.e., without choosing two adjacent vertices) is $$$\lfloor \frac{|C|}{2} \rfloor$$$.
The main idea is to fixate, in decreasing order, the ingredient with the smallest value in the selected subset. For each ingredient $$$i$$$ (with value $$$a_i$$$), we consider only the ingredients with values greater than or equal to $$$a_i$$$, thus obtaining a subgraph composed only of these vertices and disregarding the others, since they have a lower score than the fixated ingredient.
As we process the ingredients in decreasing order, we will add edges to the graph (when both ends have values $$$\geq a_i$$$) and maintain the state of the connected components using a DSU. This way, we can keep track, for each component, of the size and the maximum number of vertices that can be selected from it.
While we are testing some ingredient, we can visualize as if we were adding the vertex that represents it and the edges that connect it to the elements with scores greater than or equal to its own. Therefore, when adding an ingredient $$$i$$$ (with value $$$a_i$$$), we have three cases:
The ingredient does not add any edges: This occurs when both ingredients with which $$$i$$$ is incompatible have values less than $$$a_i$$$. In this case, $$$i$$$ forms a new component of size $$$1$$$. We add $$$1$$$ to the total number of vertices we are selecting.
The ingredient adds one edge: This occurs when only one of the incompatible ingredients has a value $$$\geq a_i$$$. Then, $$$i$$$ is connected to an existing component, increasing its size by $$$1$$$. If the size was $$$s$$$, it is now $$$s + 1$$$. Thus, the maximum number of vertices selected in that component is altered. The contribution of the component changes from $$$\lceil\frac{s}{2} \rceil$$$ to $$$\lceil\frac{(s + 1)}{2} \rceil$$$.
The ingredient adds two edges: This occurs when both incompatible ingredients have values $$$\geq a_i$$$. Here, we have two possibilities:
Closing a cycle: If the two incompatible vertices are already in the same component, then adding $$$i$$$ completes a cycle. The maximum number of vertices selected in that component becomes $$$\lfloor \frac{|C|}{2} \rfloor$$$, where $$$|C|$$$ is the size of the formed cycle.
Merging two components: If the two vertices are in different components, then we merge these two components, of sizes $$$s_1$$$ and $$$s_2$$$. Thus, we must first address our test: since we are fixing an ingredient as the smallest, we must select the vertex that represents it. Therefore, if any of the components we are merging has an odd size, then in this test the union will contribute with $$$\lfloor \frac{(s_1 + s_2 + 1)}{2} \rfloor$$$ selected. Otherwise, $$$\lceil \frac{(s_1 + s_2 + 1)}{2} \rceil$$$ will be selected. Finally, the maximum number of selected vertices from the new component (in future tests) becomes $$$\lceil \frac{(s_1 + s_2 + 1)}{2} \rceil$$$, where $$$s_1$$$ and $$$s_2$$$ are the sizes of the original components.
To avoid recalculation, we will maintain a variable throughout these tests that represents the sum of the maximum number of selected vertices in all components in the current subgraph, which is updated according to the cases presented. Thus, we achieve a total complexity of $$$O(N \cdot log(N))$$$, resulting from the sorting to process the highest scoring ingredients first.
#include <bits/stdc++.h>
using namespace std;
#define int long long int
#define float long double
#define ld long double
#define ll long long
#define pb push_back
#define ff first
#define ss second
#define vi vector<int>
#define vl vector<ll>
#define vpii vector<pair<int, int>>
#define vvi vector<vector<int>>
#define vvf vector<vector<long double>>
#define pii pair<int, int>
#define all(x) x.begin(), x.end()
#define rall(x) x.rbegin(), x.rend()
#define rep(i, x, n) for(int i = x; i < n; i++)
#define in(v) for(auto & x : v) cin >> x;
#define outi(v) for(auto x : v) cout << x << ' ';
#define tiii tuple<int, int, int>
#define tam(x) ((int)x.size())
const int MAXN = 2e5+1;
const int LLINF = (int)(1e18);
const float EPS = 1e-7;
int MOD = 998244353;
const int LOG = 30;
const ld PI = acos(-1);
const int MINF = INT64_MIN;
vector<pair<int, int>> dirs = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}};
struct DSU {
int n;
vector<int> parent, size;
DSU(int n): n(n) {
parent.resize(n, 0);
size.assign(n, 1);
for(int i=0;i<n;i++)
parent[i] = i;
}
int find(int a) {
if(a == parent[a]) return a;
return parent[a] = find(parent[a]);
}
void join(int a, int b) {
a = find(a); b = find(b);
if(a != b) {
if(size[a] < size[b]) swap(a, b);
parent[b] = a;
size[a] += size[b];
}
}
};
void solve(){
int n; cin >> n;
vpii v;
vector<vi> edges(n+1);
for(int i = 1; i <= n; i++){
int x; cin >> x;
v.emplace_back(x, i);
}
for(int i = 1; i <= n; i++){
int p; cin >> p;
edges[i].pb(p);
edges[p].pb(i);
}
sort(rall(v));
DSU dsu(n+2);
vector<bool> put(n+1);
for(auto [val, i] : v){
put[i] = true;
if(!put[edges[i][0]]){
edges[i].erase(edges[i].begin());
if(!put[edges[i][0]]) edges[i].erase(edges[i].begin());
continue;
}
if(!put[edges[i][1]]) edges[i].pop_back();
}
int qtd = 0, ans = MINF;
for(auto[val, i] : v){
if(!edges[i].size()){
qtd++;
ans = max(ans, (qtd)*val);
} else if(edges[i].size() == 1){
qtd -= ((int)(dsu.size[dsu.find(edges[i][0])]) + 1) / 2;
dsu.join(i, edges[i][0]);
qtd += ((int)(dsu.size[dsu.find(i)]) + 1) / 2;
ans = max(ans, (qtd)*val);
} else{
if(dsu.find(edges[i][1]) == dsu.find(edges[i][0])){
qtd -= ((int)(dsu.size[dsu.find(edges[i][0])]) + 1) / 2;
dsu.join(i, edges[i][0]);
qtd += (int)(dsu.size[dsu.find(edges[i][0])]) / 2;
ans = max(ans, (qtd)*val);
continue;
}
qtd -= ((int)(dsu.size[dsu.find(edges[i][0])]) + 1) / 2;
qtd -= ((int)(dsu.size[dsu.find(edges[i][1])]) + 1) / 2;
int aux = 0;
if(dsu.size[dsu.find(edges[i][0])] % 2 || dsu.size[dsu.find(edges[i][1])] % 2){
dsu.join(i, edges[i][0]);
dsu.join(i, edges[i][1]);
aux = dsu.size[dsu.find(i)] / 2;
} else {
dsu.join(i, edges[i][0]);
dsu.join(i, edges[i][1]);
aux = (int)(dsu.size[dsu.find(i)] + 1) / 2;
}
ans = max(ans, (aux+qtd)*val);
qtd += (int)(dsu.size[dsu.find(i)] + 1) / 2;
}
}
cout << ans << '\n';
}
int32_t main() {
ios::sync_with_stdio(false); cin.tie(NULL);
cout.tie(NULL);
int t = 1;
// cin >> t;
while(t--)
solve();
return 0;
}
Problem H
- Author: Vilsu
You can answer the queries of this problem online with the help of a persistent segment tree (segtree), sparse, and with lazy propagation.
Let's initialize a sum segtree with only zeros. We can root the given tree at any vertex and apply the update associated with that vertex to the segtree. From this root, we start a DFS where each vertex will copy the segtree of its parent and apply its own update to that copy. In this way, we can answer any query from a vertex to the root. To answer a query between two vertices $$$S$$$ and $$$F$$$, simply calculate the LCA $$$W_q$$$ of $$$S_q$$$ and $$$F_q$$$ and respond with $$$query(S_q) + query(F_q) - 2 \cdot query(W_q) + t$$$ where $$$t = 0$$$ if $$$max(L_w, X_q) \gt min(R_w, Y_q)$$$, otherwise $$$t = (max(L_w, X_q) - min(R_w, Y_q) + 1) \cdot K_w$$$.
The LCA can be pre-computed in $$$O(N \log N)$$$ and answered in $$$O(1)$$$, and each update or query costs $$$O(\log M)$$$ in time, so the solution will be $$$O(N \log N + N \log M + Q \log M)$$$.
#include<bits/stdc++.h>
using namespace std;
const long long MOD = 998'244'353;
struct Sparse_Table{
vector<vector<pair<int, int>>> sparse_table;
Sparse_Table(){}
Sparse_Table(vector<pair<int,int>> a){
int n = a.size(), m = 1;
while((1 << m) <= n) m++;
sparse_table.assign(m, a);
for(int i = 0; i + 1 < m; i++)
for(int j = 0; j + (1 << (i + 1)) - 1 < n; j++)
sparse_table[i + 1][j] = min(sparse_table[i][j], sparse_table[i][j + (1 << i)]);
}
pair<int,int> query(int l, int r){
int i = 31 - __builtin_clz(r - l + 1);
return min(sparse_table[i][l], sparse_table[i][r - (1 << i) + 1]);
}
};
struct LCA{
Sparse_Table sparse_table;
vector<int> time_in;
LCA(vector<vector<int>> tree) : time_in(tree.size(), 0){
vector<pair<int,int>> tour;
DFS(tree, tour, time_in, 0, -1, 0);
sparse_table = Sparse_Table(tour);
}
void DFS(vector<vector<int>> &tree, vector<pair<int,int>> &tour, vector<int> &time_in, int cur, int last, int depth){
time_in[cur] = tour.size();
tour.push_back(make_pair(depth, cur));
for(int next : tree[cur]){
if(next == last) continue;
DFS(tree, tour, time_in, next, cur, depth + 1);
tour.push_back(make_pair(depth, cur));
}
}
int query(int u, int v){
int l = time_in[u], r = time_in[v];
if(l > r) swap(l, r);
return sparse_table.query(l, r).second;
}
};
struct Seg{
int n;
vector<int> val, lazy, left_child, right_child;
Seg(int n) : n(n){}
int copy(int id){
if(id == -1){
val.push_back(0);
lazy.push_back(0);
left_child.push_back(-1);
right_child.push_back(-1);
}else{
val.push_back(val[id]);
lazy.push_back(lazy[id]);
left_child.push_back(left_child[id]);
right_child.push_back(right_child[id]);
}
return (int)val.size() - 1;
}
void prop(int l, int r, int id){
lazy[left_child[id]] = (lazy[left_child[id]] + lazy[id]) % MOD;
lazy[right_child[id]] = (lazy[right_child[id]] + lazy[id]) % MOD;
val[id] = ((long long)(r - l + 1) * lazy[id] + val[id]) % MOD;
lazy[id] = 0;
}
void update(int lu, int ru, int k, int l, int r, int id){
if(ru < l || r < lu){
if(lazy[id]){
left_child[id] = copy(left_child[id]);
right_child[id] = copy(right_child[id]);
prop(l, r, id);
}
}else if(lu <= l && r <= ru){
lazy[id] = (lazy[id] + k) % MOD;
left_child[id] = copy(left_child[id]);
right_child[id] = copy(right_child[id]);
prop(l, r, id);
}else{
int m = (l + r) / 2;
if(lazy[id] || left_child[id] == -1 || lu <= m)
left_child[id] = copy(left_child[id]);
if(lazy[id] || right_child[id] == -1 || m < ru)
right_child[id] = copy(right_child[id]);
if(lazy[id]) prop(l, r, id);
update(lu, ru, k, l, m, left_child[id]);
update(lu, ru, k, m + 1, r, right_child[id]);
val[id] = (val[left_child[id]] + val[right_child[id]]) % MOD;
}
}
void update(int lu, int ru, int k, int id){
update(lu, ru, k, 0, n - 1, id);
}
int query(int lq, int rq, int l, int r, int id){
if(rq < l || r < lq) return 0;
else if(lq <= l && r <= rq){
if(lazy[id]){
left_child[id] = copy(left_child[id]);
right_child[id] = copy(right_child[id]);
prop(l, r, id);
}
return val[id];
}else{
int m = (l + r) / 2;
if(lazy[id] || left_child[id] == -1)
left_child[id] = copy(left_child[id]);
if(lazy[id] || right_child[id] == -1)
right_child[id] = copy(right_child[id]);
if(lazy[id]) prop(l, r, id);
return (query(lq, rq, l, m, left_child[id]) +
query(lq, rq, m + 1, r, right_child[id])) % MOD;
}
}
int query(int lq, int rq, int id){
return query(lq, rq, 0, n - 1, id);
}
};
void DFS(Seg &seg, vector<vector<int>> &tree, vector<array<int, 3>> &triple, vector<int> &roots, vector<int> &parent, int cur){
if(parent[cur] != -1) roots[cur] = seg.copy(roots[parent[cur]]);
else roots[cur] = seg.copy(-1);
auto [li, ri, ki] = triple[cur];
seg.update(li, ri, ki, roots[cur]);
for(int next : tree[cur]){
if(next == parent[cur]) continue;
parent[next] = cur;
DFS(seg, tree, triple, roots, parent, next);
}
}
signed main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
int n, m; cin >> n >> m;
vector<vector<int>> tree(n);
for(int i = 0; i < n - 1; i++){
int u, v; cin >> u >> v;
u--; v--;
tree[u].push_back(v);
tree[v].push_back(u);
}
LCA lca(tree);
vector<array<int, 3>> triple(n);
for(auto &[li, ri, ki] : triple){
cin >> li >> ri >> ki; li--; ri--;
}
Seg seg(m);
vector<int> roots(n, -1), parent(n, -1);
DFS(seg, tree, triple, roots, parent, 0);
int q; cin >> q;
int ans = 0;
while(q--){
int u, v, x, y; cin >> u >> v >> x >> y;
u ^= ans; v ^= ans; x ^= ans; y ^= ans;
u--; v--;
int w = lca.query(u, v);
x--; y--;
int qu = seg.query(x, y, roots[u]);
int qv = seg.query(x, y, roots[v]);
int qw = seg.query(x, y, roots[w]);
ans = ((qu + MOD - qw) % MOD + (qv + MOD - qw) % MOD) % MOD;
auto [li, ri, ki] = triple[w];
li = max(li, x);
ri = min(ri, y);
if(li <= ri) ans = ((long long) (ri - li + 1) * ki + ans) % MOD;
cout << ans << '\n';
}
}
Problem I
- Author: gnramos
The solution is simple and can be done in various ways. One approach is to iterate through each letter in the matrix and, if it is "v" or "V", check if there are neighbors in the 4 indicated directions (horizontal, vertical, and diagonals). If there are neighbors, just check if one of them is "a" or "A" and if the other is "u" or "U". If so, increment a counter. Note! In the input, the number of letters in each line is given before the number of lines.
M, N = map(int, input().split())
matriz = [' ' * (M + 2)] + [f' {input().lower()} ' for _ in range(N)] + [' ' * (M + 2)]
qtde = 0
for i in range(1, N + 1):
j = -1
while (j := matriz[i].find('v', j + 1)) != -1:
# horizontal
qtde += matriz[i][j-1] == 'u' and matriz[i][j+1] == 'a'
qtde += matriz[i][j-1] == 'a' and matriz[i][j+1] == 'u'
# vertical
qtde += matriz[i-1][j] == 'a' and matriz[i+1][j] == 'u'
qtde += matriz[i-1][j] == 'u' and matriz[i+1][j] == 'a'
# diagonais
qtde += matriz[i-1][j-1] == 'u' and matriz[i+1][j+1] == 'a'
qtde += matriz[i-1][j-1] == 'a' and matriz[i+1][j+1] == 'u'
qtde += matriz[i-1][j+1] == 'u' and matriz[i+1][j-1] == 'a'
qtde += matriz[i-1][j+1] == 'a' and matriz[i+1][j-1] == 'u'
print(qtde)
Problem J
- Author: arthur_9548
The total number of cells is $$$N \cdot M$$$. It is known that, in each turn, one of the cells is marked. Therefore, the game will have exactly $$$N \cdot M$$$ turns with possible moves, and the player who makes the $$$N \cdot M$$$-th move will certainly be the winner. Thus, it is enough to check the parity of $$$N \cdot M$$$.
n, m = map(int, input().split())
if n*m%2: print('W')
else: print('P')
Problem K
- Author: dporto
Summary of the idea:
Sort the vector of timestamps $$$t$$$.
For each query $$$[L,\ R]$$$, the answer is: $$$idxR - idxL$$$, where:
$$$idxL =$$$ first position with value $$$\geq L$$$ -> $$$lower_bound(t.begin(),\ t.end(),\ L)$$$
$$$idxR =$$$ first position with value $$$ \gt R$$$ -> $$$upper_bound(t.begin(),\ t.end(),\ R)$$$
The result ($$$idxR - idxL$$$) is exactly the number of elements $$$t_i$$$ in $$$[L,\ R]$$$.
Why it works:
$$$lower_bound$$$ returns an iterator to the first element not less than $$$L$$$ (that is, $$$\geq L$$$).
$$$upper_bound$$$ returns an iterator to the first element strictly greater than $$$R$$$ ($$$ \gt R$$$).
All elements between these two positions (inclusive on the left, exclusive on the right) are those such that $$$L \leq t_i \leq R$$$.
Complexity:
Sorting: $$$O(N \log N)$$$
Each query: $$$O(\log N)$$$ for $$$lower_bound$$$ + $$$O(\log N)$$$ for $$$upper_bound$$$ -> $$$O(\log N)$$$
Total: $$$O(N \log N + Q \log N)$$$, suitable for $$$N, Q$$$ up to $$$2 \cdot 10^5$$$.
#include <bits/stdc++.h>
using namespace std;
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);
int N, Q;
if (!(cin >> N >> Q))
return 0;
vector<long long> t(N);
for (int i = 0; i < N; ++i)
cin >> t[i];
sort(t.begin(), t.end());
while (Q--) {
long long L, R;
cin >> L >> R;
auto itL = lower_bound(t.begin(), t.end(), L);
auto itR = upper_bound(t.begin(), t.end(), R);
cout << (itR - itL) << '\n';
}
return 0;
}
Problem L
- Author: Maxwell01
We can summarize the problem as finding the sum of the squares of the first $$$N + 1$$$ odd numbers and discarding 1 unit. Therefore, we will focus only on finding this sum. There are several ways to do this:
i) The first and most direct way is using the closed formula: $$$\frac{N \left( 4N^2 - 1 \right)}{3}$$$
ii) We can rewrite the sum as $$$\sum_{i=0}^{N} (2i + 1)^2 = \sum_{i=0}^{N} (4i^2 + 4i + 1)$$$
And calculate each term separately as follows:
$$$\sum_{i=0}^{N} 4i^2 = 4 \cdot \sum_{i=0}^{N} i^2 = 4 \cdot \frac{N \cdot (N + 1) \cdot (2N + 1)}{6}$$$
$$$\sum_{i=0}^{N} 4i = 4 \cdot \frac{N * (N + 1)}{2}$$$
$$$\sum_{i=0}^{N} 1 = N$$$
Thus, just perform the operations and sum the results.
iii) A final solution would be to see that there is a polynomial that describes the formula, calculate some points of it, and perform Lagrange interpolation to calculate at point $$$N$$$. Note that, in fact, the polynomial given in the first solution has a small degree.
Important: Since the answer to the problem is a very large number, we cannot calculate it and then print the answer modulo $$$10^9 + 7$$$. Therefore, we must calculate this modulo at each step of the operations. Specifically for division, it is necessary to calculate the multiplicative inverse of the number, and it is not enough to just perform the division directly. More details about this can be found in this blog
// https://mirror.codeforces.com/blog/entry/125435
#ifdef MAXWELL_LOCAL_DEBUG
#include "../debug_template.cpp"
#else
#define debug(...)
#define debugArr(arr, n)
#endif
#define dbg debug()
#include <bits/stdc++.h>
#define ff first
#define ss second
using namespace std;
using ll = long long;
using ld = long double;
using pii = pair<int,int>;
using vi = vector<int>;
using tii = tuple<int,int,int>;
// auto [a,b,c] = ...
// .insert({a,b,c})
const int oo = (int)1e9 + 5; //INF to INT
const ll OO = 0x3f3f3f3f3f3f3f3fLL; //INF to LL
const int MOD = (int)1e9 + 7;
const int INV3 = 333333336;
void add(ll &a, ll b) {
a = (a + b + MOD) % MOD;
}
void mul(ll& a, ll b) {
a = (a * b) % MOD;
}
void solve() {
ll N;
cin >> N;
N += 1;
N %= MOD;
// OEIS A000447
// a(n) = 1^2 + 3^2 + 5^2 + 7^2 + ... + (2*n-1)^2 = n*(4*n^2 - 1)/3.
ll a = 1;
mul(a, N);
mul(a, N);
mul(a, 4);
add(a, -1);
mul(a, INV3);
mul(a, N);
add(a, -1);
cout << a << "\n";
}
int32_t main() {
ios::sync_with_stdio(false);
cin.tie(NULL);
int t = 1;
//cin >> t;
while(t--) {
solve();
}
}
Problem M
- Author: arthur_9548
- Special thanks: VLamarca
Since the polygons in the plane are distinct and do not intersect, they form a tree, where the parent of a polygon is the smallest polygon that strictly contains it (if it is not contained by anyone, the parent is the root of the tree, an auxiliary vertex). Considering the points of the questions as polygons with a single vertex, it is enough to see their height in this tree to count how many polygons contain them.
To construct this tree, the Sweep Line technique can be used. In this Sweep Line, the points of the questions and the edges of the polygons that are not aligned with the vertical axis will be processed. Each point will be a Sweep Line event, and each edge will generate a creation event (at the leftmost end) and a removal event (at the rightmost end). The order of the events is: coordinate $$$X$$$, addition before removal, coordinate $$$Y$$$ (the points of the questions are considered additions).
During the algorithm, we will maintain the coordinate $$$X$$$ that is currently being processed, called $$$X_a$$$. Additionally, we will maintain a $$$set$$$ that keeps the segments that have been added but not yet removed in an ordered manner. The order of the segments within the $$$set$$$ is as follows: segment $$$A$$$ comes before segment $$$B$$$ if the intersection between $$$A$$$ and the line $$$x = X_a$$$ is below the intersection between $$$B$$$ and $$$x = X_a$$$.
To achieve this ordering, it is enough to keep $$$X_a$$$ as a global variable and create a function that implements this comparison between segments (which can be calculated in $$$O(1)$$$) to be passed to the $$$set$$$. It can be proven that this ordering is consistent as long as:
- The segments do not intersect with each other (guaranteed by the statement).
- The segments remain in the $$$set$$$ only while there is an intersection between them and $$$X_a$$$ (guaranteed by the processing method of the Sweep Line).
Thus, the events of the Sweep Line are processed in order. Removal events simply remove the segment from the $$$set$$$. Addition events add the segment to the $$$set$$$ (if it is not a point) and also calculate the parent of the current polygon or point, if its parent has not yet been calculated. To do this, it is enough to see the first segment of the $$$set$$$ whose intersection with $$$X_a$$$ is greater than the intersection of the current one with $$$X_a$$$ (i.e., the first segment above the current one). This can be done with binary search since the $$$set$$$ is ordered. If the binary search does not find any segment above, then the parent of the current one is the root of the tree. Otherwise, we check if the found segment is part of the upper or lower edge of the polygon to which it belongs — we say that a segment is part of the upper edge if and only if it connects $$$P1$$$ to $$$P2$$$ (considering the counterclockwise order) and $$$P2$$$ is to the left of $$$P1$$$. If it is part of the upper edge, then the parent of the current one is it (since it contains the current one); if not, the parent of the current one is its parent (since it would be a sibling of the current one in the tree).
We see that the tree can be constructed in $$$O(P \log P)$$$, where $$$P$$$ is the total number of points in the input. Then, we can calculate the height of each vertex using breadth-first or depth-first search. Finally, we just need to print the heights of the vertices that are points of the questions.
#include <bits/stdc++.h>
using namespace std;
#define endl '\n'
#define pb push_back
#define eb emplace_back
#define rep(i, a, b) for (int i = a; i < (int)(b); i++)
#define sz(x) (int)x.size()
typedef long long ll;
typedef long double ld;
struct P { ll x, y; };
// Line Segment
int current_x;
struct Segment {
int idx; P p1, p2; bool is_upper;
Segment(P p, P q, int i): idx(i), p1(p), p2(q), is_upper(p2.x < p1.x) { if (is_upper)swap(p1, p2); }
ld get_y(ll x) const { return (ld) (p2.y - p1.y) / (p2.x - p1.x) * (x - p1.x) + p1.y; }
tuple<ld, bool, int> get_comp() const { return {get_y(current_x), is_upper, p2.x}; }
bool operator<(const Segment & o) const { return get_comp() < o.get_comp(); }
};
signed main() {
ios_base::sync_with_stdio(0); cin.tie(0);
int n, q; cin >> n >> q;
vector<vector<P>> polygons(n);
rep(i, 0, n) {
int k; cin >> k;
rep(j, 0, k) {
int x, y; cin >> x >> y;
polygons[i].eb(x, y);
}
}
vector<P> queries(q);
rep(i, 0, q) {
int x, y; cin >> x >> y;
queries[i] = {x, y};
}
vector<tuple<int, int, int, Segment>> edges; // polygon edges
rep(idx, 0, n) {
const auto & v = polygons[idx];
rep(i, 0, sz(v)) {
int j = (i + 1) % sz(v);
if (v[i].x == v[j].x)continue; // ignores vertical edges
Segment seg = Segment(v[i], v[j], idx);
edges.eb(seg.p1.x, 0, -seg.p1.y, seg);
edges.eb(seg.p2.x, 1, -seg.p2.y, seg);
}
}
rep(idx, 0, q){
P p = queries[idx];
P p2 = p; p2.x++; // this wont be used by the sweep line
Segment seg = Segment(p, p2, n + idx);
edges.eb(seg.p1.x, 0, -seg.p1.y, seg);
}
// Sweep Line
sort(edges.begin(), edges.end());
set<Segment> s;
vector pai(n+q+1, n), vis(n+q, 0);
for (auto [l, t, y, seg]: edges) {
current_x = l;
int i = seg.idx;
if (t == 0) {
if (not vis[i]) {
vis[i] = true;
auto it = s.upper_bound(seg);
if (it == s.end())pai[i] = n+q;
else if (it->is_upper)pai[i] = it->idx;
else pai[i] = pai[it->idx];
}
if (i < n)s.insert(seg);
}
else if (i < n)s.erase(seg);
}
// depth in tree
vector<vector<int>> g(n+q+1);
rep(i, 0, n+q)g[pai[i]].pb(i), g[i].pb(pai[i]);
vector h(n+q+1, -2); // plane is -1, bigger polygons are 0
auto dfs = [&](auto rec, int v, int p) -> void {
h[v] = h[p] + 1;
for(int f : g[v])if (f != p)rec(rec, f, v);
};
dfs(dfs, n+q, n+q);
rep(i, n, n+q)cout << h[i] << endl;
}
Problem N
- Author: edsomjr
The problem can be solved by simulating Professor John's movement strategy. To do this, set $$$X\gets 0, step\gets 1, d\gets D, i\gets 0$$$ and follow these steps while $$$|step| \lt d$$$:
- $$$d\gets d - |step|$$$ (updates the distance traveled)
- $$$X\gets X + step$$$ (repositions the boat)
- if $$$i$$$ is even, reverse the sign of $$$step$$$; otherwise, $$$step\gets 2\times step$$$ (corrects the navigation direction)
- $$$i\gets i + 1$$$
At the end of the process, there were only $$$d$$$ meters left to reach $$$Y$$$, so $$$X\gets X + d\times \mathrm{sig}(step)$$$, where $$$\mathrm{sig}(x)$$$ is the sign function of $$$x$$$.
However, it is important to pay attention to the possible inconsistency of the data, which occurs when $$$X$$$ corresponds to a position that has already been visited. To check this condition, simply maintain two pointers $$$L$$$ and $$$R$$$, initially equal to zero. In each iteration of the proposed algorithm, just update $$$L$$$ and $$$R$$$ to record the smallest and largest values of $$$X$$$, respectively. Thus, $$$[L, R]$$$ will be the interval of positions already visited. At the end of the routine, if $$$X\in [L, R]$$$, the data is inconsistent.
This solution has a complexity of $$$O(\log D)$$$.
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
auto solve(ll N, ll Y) -> pair<string, ll>
{
ll step = 1, L = 0, R = 0, X = 0;
int i = 0;
while (llabs(step) < N)
{
N -= llabs(step);
X += step;
L = min(L, X);
R = max(R, X);
step = i & 1 ? 2*step : -step;
i++;
}
ll sig = step > 0 ? 1 : -1;
X += sig*N;
auto ok = X < L or X > R;
if (not ok)
return { "Nao", -1 };
ll ans = Y - X;
return { "Sim", ans };
}
int main()
{
ios::sync_with_stdio(false);
ll N, Y;
cin >> N >> Y;
auto [ans, X] = solve(N, Y);
cout << ans << '\n';
if (ans == "Sim")
cout << X << '\n';
return 0;
}