Здравствуйте! Этот пост написан для всех тех, кто хочет освоить полиномиальные хэши и научиться применять их в решении различных задач. Я кратко приведу теоретический материал, рассмотрю особенности реализации и разберу некоторые задачи, среди них:
Поиск всех вхождений одной строки длины n в другую длины m за O(n + m)
Поиск наибольшей общей подстроки двух строк длин n и m (n ≥ m) за O((n + m·log(n))·log(m)) и O(n·log(m))
Нахождение лексикографически минимального циклического сдвига строки длины n за O(n·log(n))
Сортировка всех циклических сдвигов строки длины n в лексикографическом порядке за O(n·log(n)2)
Нахождение количества подпалиндромов строки длины n за O(n·log(n))
Количество подстрок строки длины n, являющихся циклическими сдвигами строки длины m за O((n + m)·log(n))
Количество суффиксов строки длины n, бесконечное расширение которых совпадает с бесконечным расширением всей строки за O(n·log(n)) (расширение — дублирование строки бесконечное число раз)
Наибольший общий префикс двух строк длины n с обменом двух произвольных символов одной строки местами за O(n·log(n))
Примечание 1. Не исключено, что некоторые задачи могут быть решены быстрее другими методами, например, сортировка циклических сдвигов — это в точности то, что происходит при построении суффиксного массива, искать все вхождения одной строки в другую и работать с собственными суффиксами позволят префикс-функция и алгоритм Кнута-Морриса-Пратта, а с подпалиндромами отлично справляется алгоритм Манакера
Примечание 2. В задачах выше приведена оценка, когда поиск хэша осуществляется при помощи сортировки и бинарного поиска. Если у Вас есть своя хэш-таблица с открытым перемешиванием или цепочками переполнения, то Вы — счастливчик, смело заменяйте бинарный поиск хэша на поиск в Вашей хэш-таблице, но не вздумайте использовать std::unordered_set, так как на практике поиск в std::unordered_set проигрывает сортировке и бинарному поиску в связи с тем, что эта штука подчиняется стандарту C++ и обязана много чего гарантировать пользователю, что полезно при промышленной разработке и, зачастую, бесполезно в олимпиадном программировании, поэтому сортировка и бинарный поиск для несложных структур одерживают абсолютное первенство в C++ по скорости работы, если не тянуть что-то свое.
Примечание 3. В тех случаях, когда сравнение элементов затратно (например, сравнение по хэшам за O(log(n))), то в худшем случае std::random_shuffle + std::sort всегда проигрывает std::stable_sort, так как std::stable_sort гарантирует минимальное число сравнений среди всех сортировок (основанных на сравнениях) для худшего случая.
Решение перечисленных задач будет приведено ниже, исходники тоже.
В качестве плюса полиномиального хэширования могу отметить, что зачастую не нужно думать, можно сразу брать и писать наивный алгоритм решения задачи и ускорять его полиномиальным хэшированием. Лично мне решения с полиномиальным хэшем приходят в голову в первую очередь, может поэтому я синий.
Среди минусов полиномиального хэширования: а) Слишком много операций остатка от деления, порой на грани TLE на больших задачах и б) на codeforces в программах на C++ зачастую маленькие гарантии от взлома из-за MinGW: std::random_device генерирует каждый раз одно и то же число, std::chrono::high_resolution_clock тикает в микросекундах вместо наносекунд. (Компилятор cygwin на windows лишен всех недостатков MinGW, в том числе и медленного ввода/вывода).
`UPD`: Одолели пункт а)Для того, чтобы не использовать медленную операцию взятия остатка от деления, можно взять два модуля m1 = 231 - 1 и m2 = 264.
Тогда для взятия остатка от деления по модулю m2 необходимо проводить вычисления в беззнаковом 64-битном типе, например, в типе unsigned long long в C++, т.к. во многих языках программирования гарантируется, что вычисления в этом типе данных будут проводиться по модулю 264.
Для взятия остатка от деления по модулю 231 - 1 = 2147483647 для положительных чисел x до (mod - 1)2 + mod - 1 (результат умножения двух остатков и одного сложения) можно брать смещенный остаток следующим образом:
x = (x >> 31) + (x & 2147483647);
x = (x >> 31) + (x & 2147483647);
return x;
В случае сложения и вычитания по модулю m1 двух остатков можно обойтись обычным тернарным оператором.
`UPD`: Одолели пункт б)Достаточно делать побитовое ИЛИ для значений текущего времени и адреса в памяти, полученного от менеджера кучи:
Что такое полиномиальный хэш?
Хэш-функция должна сопоставлять некоторому объекту некоторое число (его хэш) и обладать следующими свойствами:
Если два объекта совпадают, то их хэши равны.
Если два хэша равны, то объекты совпадают с большой вероятностью.
Коллизией называется очень неприятная ситуация равенства двух хэшей у несовпадающих объектов. В идеале, при выборе хэш-функции необходимо обеспечить как можно меньшую вероятность коллизии. На практике — такую вероятность, чтобы успешно пройти набор тестов к задаче.
Существует два подхода в выборе функции полиномиального хэша, которые зависят от направления: слева-направо и справа-налево. Для начала рассмотрим вариант слева-направо, а ниже, после описания проблем, которые возникают в связи с выбором первого варианта, рассмотрим второй.
Рассмотрим последовательность {a0, a1, ..., an - 1}. Под полиномиальным хэшем слева-направо для этой последовательности будем иметь в виду результат вычисления следующего выражения:

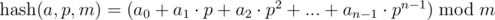
Здесь p и m — точка (или основание) и модуль хэширования соответственно.
Условия, которые мы наложим: 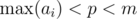 ,
, 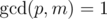 .
.
Примечание. Если подумать об интерпретации выражения, то мы сопоставляем последовательности {a0, a1, ..., an - 1} число длины n в системе счисления p и берем остаток от его деления на число m, или значение многочлена (n - 1)-й степени с коэффициентами ai в точке p по модулю m. О выборе p и m поговорим позже.
Примечание. Если значение 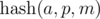 , не взятое по модулю, помещается в целочисленный тип данных (например, 64-битный тип), то можно каждой последовательности сопоставить это число. Тогда сравнение на больше / меньше / равно можно выполнять за O(1).
, не взятое по модулю, помещается в целочисленный тип данных (например, 64-битный тип), то можно каждой последовательности сопоставить это число. Тогда сравнение на больше / меньше / равно можно выполнять за O(1).
Сравнение на равенство за O(1)
Теперь ответим на вопрос, как сравнивать произвольные непрерывные подотрезки последовательности за O(1)? Покажем, что для их сравнения достаточно посчитать полиномиальный хэш на каждом префиксе исходной последовательности {a0, a1, ..., an - 1} .
Определим полиномиальный хэш на префиксе как:
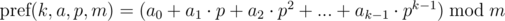
Кратко обозначим 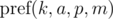 как
как 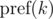 и будем иметь в виду, что итоговое значение берется по модулю m. Тогда:
и будем иметь в виду, что итоговое значение берется по модулю m. Тогда:
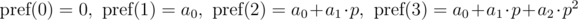
Общий вид:
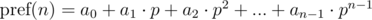
Полиномиальный хэш на каждом префиксе можно находить за O(n), используя рекуррентные соотношения:
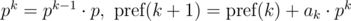
Допустим, нам нужно сравнить две подстроки, начинающиеся в позициях i и j и имеющие длину len, на равенство:
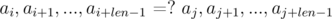
Рассмотрим разности 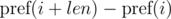 и
и 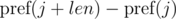 . Не трудно видеть, что:
. Не трудно видеть, что:
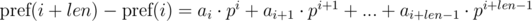
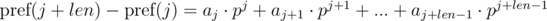
Домножим 1-е уравнение на pj, а 2-е на pi. Получим:
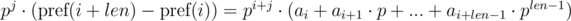
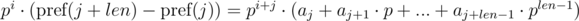
Видим, что в правой части выражений в скобках были получены полиномиальные хэши от подотрезков:
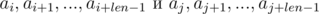
Таким образом, чтобы определить, совпали ли искомые подотрезки, необходимо проверить выполнение следующего равенства:
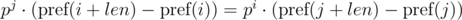
Одно такое сравнение можно выполнять за O(1), предподсчитав степени p по модулю. С учетом модуля m, имеем:
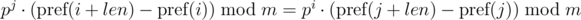
Проблема: сравнение одной строки зависит от параметров другой строки (от j).
Первое решение данной проблемы (предложил veschii_nevstrui) основывается на домножении первого уравнения на p - i, а второго на p - j. Тогда получим:
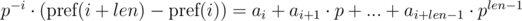
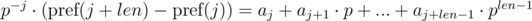
Можем заметить, что в правых частях был получен полиномиальный хэш от искомых подотрезков. Тогда, равенство проверяется следующим образом:
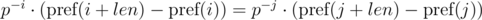
Для реализации этого необходимо найти обратный элемент для p по модулю m. Из условия gcd(p, m) = 1 обратный элемент всегда существует. Для этого необходимо вычислить значение функции Эйлера для выбранного модуля φ(m) и возвести p в степень φ(m) - 1. Если предподсчитать степени обратного элемента по выбранному модулю, то сравнение можно выполнять за O(1).
Второе решение данной проблемы основывается на знании максимальной длины сравниваемых строк. Обозначим максимальную длину сравниваемых строк как 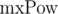 . Домножим 1-е уравнение на p в степени mxPow - i - len + 1, а 2-е на p в степени mxPow - j - len + 1. Тогда:
. Домножим 1-е уравнение на p в степени mxPow - i - len + 1, а 2-е на p в степени mxPow - j - len + 1. Тогда:
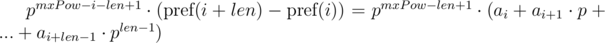
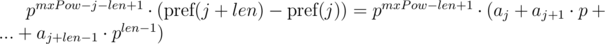
Можем заметить, что в правых частях был получен полиномиальный хэш от искомых подотрезков. Тогда, равенство проверяется следующим образом:
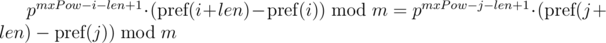
Этот подход позволяет сравнивать одну подстроку длины len со всеми подстроками длины len на равенство, в том числе, и подстроками другой строки, так как выражение 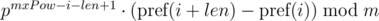 для подстроки длины len, начинающейся в позиции i, зависит только от параметров подстроки i, len и константы mxPow, а не от параметров другой подстроки.
для подстроки длины len, начинающейся в позиции i, зависит только от параметров подстроки i, len и константы mxPow, а не от параметров другой подстроки.
Теперь рассмотрим другой вариант выбора функции полиномиального хэширования. Определим полиномиальный хэш на префиксе как:
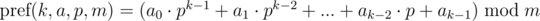
Кратко обозначим как и будем иметь в виду, что итоговое значение берется по модулю m. Тогда:
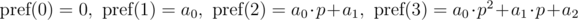
Полиномиальный хэш на каждом префиксе можно находить за O(n), используя рекуррентные соотношения:
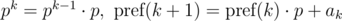
Допустим, нам нужно сравнить две подстроки, начинающиеся в позициях i и j и имеющие длину len, на равенство:
Рассмотрим выражение 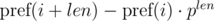 и
и 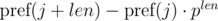 . Не трудно видеть, что:
. Не трудно видеть, что:
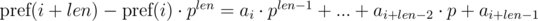
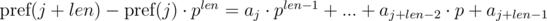
Видим, что в правой части выражений в скобках были получены полиномиальные хэши от подотрезков:
Таким образом, чтобы определить, совпали ли искомые подотрезки, необходимо проверить выполнение следующего равенства:
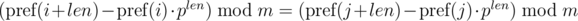
Одно такое сравнение можно выполнять за O(1), предподсчитав степени p по модулю m.
Сравнение на больше / меньше за O(log(n))
Рассмотрим две подстроки возможно разных строк длин len1 и len2, (len1 ≤ len2), начинающиеся в позициях i и j соответственно. Заметим, что отношение больше / меньше определяется первым несовпадающим символом в этих подстроках, а до позиции этого символа строки совпадают. Таким образом, необходимо найти позицию первого несовпадающего символа методом бинарного поиска, а затем сравнить найденные символы. Благодаря сравнению подстрок на равенство за O(1), можно решить задачу сравнения подстрок на больше / меньше за O(log(len1)):
Псевдокодlow = 0; high = len1+1;
while (high-low > 1) {
mid = (low + high) / 2;
if (hash(i,mid) == hash(j,mid)) {
low = mid;
} else {
high = mid;
}
}
low - позиция первого различия
Минимизация вероятности коллизии
Используя парадокс дней рождений, приведем (возможно, грубую) оценку вероятности коллизии. Пусть мы вычисляем полиномиальный хэш по модулю m и в ходе работы программы нам нужно сравнить n строк. Тогда вероятность того, что произойдет коллизия:
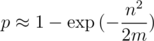
Отсюда очевидно, что m нужно брать значительно больше, чем n2. Тогда, аппроксимируя экспоненту рядом Тейлора, получаем вероятность коллизии на одном тесте:
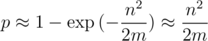
Если мы рассмотрим задачу о поиске вхождений всех циклических сдвигов одной строки в другую строку длин до 105, то мы можем получить 1015 сравнений строк.
Тогда, если мы возьмем простой модуль порядка 109, то мы не пройдем ни один из максимальных тестов.
Если мы возьмем модуль порядка 1018, то вероятность коллизии на одном тесте ≈ 0.001. Если максимальных тестов 100, то вероятность коллизии в одном из тестов ≈ 0.1, то есть 10%.
Если мы возьмем модуль порядка 1027, то на 100 максимальных тестах вероятность коллизии равна ≈ 10 - 10.
Вывод: чем больше модуль — тем больше вероятность пройти тест. Эта вероятность не учитывает взломы.
Двойной полиномиальный хэш
Разумеется, в реальных программах мы не можем брать модули порядка 1027. Как быть? На помощь приходит китайская теорема об остатках. Если мы возьмем два взаимно простых модуля m1 и m2, то кольцо остатков по модулю m = m1·m2 эквивалентно произведению колец по модулям m1 и m2, т.е. между ними существует взаимно однозначное соответствие, основанное на идемпотентах кольца вычетов по модулю m. Иными словами, если вычислять 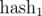 по модулю m1 и
по модулю m1 и 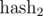 по модулю m2, а затем сравнивать два искомых подотрезка по и одновременно, то это эквивалентно сравнению полиномиальным хэшем по модулю m. Аналогично, можно брать три взаимно простых модуля m1, m2, m3.
по модулю m2, а затем сравнивать два искомых подотрезка по и одновременно, то это эквивалентно сравнению полиномиальным хэшем по модулю m. Аналогично, можно брать три взаимно простых модуля m1, m2, m3.
Особенности реализации
Итак, мы подошли к реализации описанного выше. Цель — минимум взятий остатка от деления, т.е. получить два умножения в 64-битном типе и одно взятие остатка от деления в 64-битном типе на одно вычисление двойного полиномиального хэша, при этом получить хэш по модулю порядка 10^27 и защитить код от взлома на codeforces.
Выбор модулей. Выгодно использовать двойной полиномиальный хэш по модулям m1 = 1000000123 и m2 = 2^64. Если Вам не нравится такой выбор m1, можете выбрать 1000000321, главное выбрать такое простое число, чтобы разность двух остатков лежала в пределах знакового 32-битного типа (int). Простое число брать удобнее, так как автоматически обеспечиваются условия gcd(m1, m2) = 1 и gcd(m1, p) = 1. Выбор в качестве m2 = 2^64 не случаен. Стандарт C++ гарантирует, что все вычисления в unsigned long long выполняются по модулю 2^64 автоматически. Отдельно модуль 2^64 брать нельзя, так как существует анти-хэш тест, который не зависит от выбора точки хэширования p. Модуль m1 необходимо задать как константу для ускорения взятия модуля (компилятор (не MinGW) оптимизирует, заменяя умножением и побитовым сдвигом).
Кодирование последовательности. Если дана последовательность символов, состоящая, например, из маленьких латинских букв, то можно ничего не кодировать, так как каждому символу уже соответствует его код. Если дана последовательность целых чисел разумной для представления в памяти длины, то можно собрать в один массив все встречающиеся числа, отсортировать, удалить повторы и сопоставить каждому числу в последовательности его порядковый номер в полученном упорядоченном множестве. Начинать нумерацию с нуля запрещено: все последовательности вида 0,0,0,..,0 разной длины будут иметь один и тот же полиномиальный хэш.
Выбор основания. В качестве основания p достаточно взять любое нечетное число, удовлетворяющее условию max(a[i]) < p < m1. (нечетное, потому что тогда gcd(p, 2^64) = 1). Если Вас могут взломать, то необходимо генерировать p случайным образом с каждым новым запуском программы, причем генерация при помощи std::srand(std::time(0)) и std::rand() не подходит, так как std::time(0) тикает очень медленно, а std::rand() не обеспечивает достаточной равномерности. Если компилятор НЕ MinGW (к сожалению, на codeforces установлен MinGW), то можно использовать std::random_device, std::mt19937, std::uniform_int_distribution<int> (в cygwin на windows и gnu gcc на linux данный набор обеспечивает почти абсолютную случайность). Если не повезло и Вас посадили на MinGW, то ничего не остается, как std::random_device заменить на std::chrono::high_resolution_clock и надеяться на лучшее (или есть способ достать какой-нибудь счетчик из процессора?). На MinGW этот таймер тикает в микросекундах, на cygwin и gnu gcc в наносекундах.
Гарантии от взлома. Нечетных чисел до модуля порядка 10^9 тоже порядка 10^9. Взломщику необходимо будет сгенерировать для каждого нечетного числа анти-хэш тест так, чтобы была коллизия в пространстве до 10^27, скомпоновать все тесты в один большой тест и сломать Вас. Это если использовать не MinGW на Windows. На MinGW таймер тикает, как уже говорилось, в микросекундах. Зная время запуска решения на сервере с точностью до секунд, можно для каждой из 10^6 микросекунд вычислить, какое случайное p сгенерировалось, и тогда вариантов в 1000 раз меньше. Если 10^9 это какая-то космическая величина, то 10^6 уже кажется не такой безопасной. При использовании std::time(0) всего 10^3 вариантов (миллисекунды) — можно ломать. В комментариях я видел, что гроссмейстеры умеют ломать полиномиальный хэш до 10^36.
Удобство в использовании. Удобно написать универсальный объект для полиномиального хэша и копировать его в ту задачу, где он может понадобиться. Лучше писать самостоятельно для своих нужд и целей в том стиле, в котором пишете Вы, чтобы разбираться в исходном коде при необходимости. Все задачи в этом посте решены при помощи копирования одного и того же объекта. Не исключено, что существуют специфические задачи, в которых это не сработает.
UPD: Для ускорения программ можно быстро вычислять остатки от делений на модули 231 - 1 и 261 - 1. Основная сложность заключается в умножении. Чтобы понять принцип, посмотрите следующий пост от dacin21 в параграфе Larger modulo и его комментарий с объяснениями.
Mult mod `2^61-1`constexpr uint64_t mod = (1ull<<61) - 1;
uint64_t modmul(uint64_t a, uint64_t b){
uint64_t l1 = (uint32_t)a, h1 = a>>32, l2 = (uint32_t)b, h2 = b>>32;
uint64_t l = l1*l2, m = l1*h2 + l2*h1, h = h1*h2;
uint64_t ret = (l&mod) + (l>>61) + (h << 3) + (m >> 29) + (m << 35 >> 3) + 1;
ret = (ret & mod) + (ret>>61);
ret = (ret & mod) + (ret>>61);
return ret-1;
}
Задача 1. Поиск всех вхождений одной строки длины n в другую длины m за O(n + m)
Дано: Две строки S и T длин до 50000. Вывести все позиции вхождения строки T в строку S. Индексация с нуля.
Пример: Ввод S = "ababbababa", T = "aba", вывод: 0 5 7.
Ссылка на задачу на acmp.ru.
Решение и кодПосчитаем полиномиальный хэш на префиксах строк S и T. Будем идти вдоль строки S, сравнивая полиномиальный хэш текущей подстроки со всей строкой T. При совпадении хэшей выводим текущую позицию. Асимптотика: O(n) по времени и памяти. Исходный код.
Задача 2. Поиск наибольшей общей подстроки двух строк длин n и m (n ≥ m) за O((n + m·log(n))·log(m)) и O(n·log(m))
Дано: Длина строк N и две строки A и B длины до 100000. Вывести длину наибольшей общей подстроки.
Пример: Ввод: N = 28, A = "VOTEFORTHEGREATALBANIAFORYOU", B = "CHOOSETHEGREATALBANIANFUTURE", вывод: THEGREATALBANIA
Ссылка на задачу на acm.timus.ru с длиной до 10^5.
Ссылка на задачу на spoj.com с длиной до 10^6.
Решение и кодПервым делом посчитаем полиномиальный хэш на префиксах строк A и B. Пусть мы нашли наибольшую общую подстроку длины len, начинающуюся в позиции pos любой из строк. Тогда общей подстрокой будет также и любая подстрока длин len-1, len-2, ..., 1, начинающаяся в позиции pos, а len+1 уже не будет являться общей подстрокой. Видно, что выполняются условия бинарного поиска. Инициализация бинарного поиска: low = 0, high = N+1. На каждой итерации поиска будем складывать все хэши подстрок длины mid строки A в вектор, сортировать его, а дальше проходить по хэшам подстрок длины mid строки B и искать их среди отсортированных хэшей строки A. Асимптотика решения по времени O(n log(n)^2), по памяти O(n). Исходный код.
Решение для 10^6 за O(n log(n)^2) с сжатием символов Решение для 10^6 за O(n log(n)) с хэш-таблицей с открытой адресацией
Задача 3. Нахождение лексикографически минимального циклического сдвига строки длины n за O(n·log(n))
Дано: Строка S длины до 10^5. Вывести минимальный лексикографически сдвиг строки A.
Пример: Ввод: "program", Вывод: "amprogr"
Ссылка на задачу на acmp.ru.
Решение и кодВ этой задаче необходимо написать сравнение двух подстрок методом бинарного поиска, описанным выше. Продублируем строку S и посчитаем полиномиальный хэш на префиксе. Каждый циклический сдвиг будем представлять в виде числа (начальной позиции). Сложим в вектор все позиции, а дальше применим линейный алгоритм нахождения минимума в массиве, используя оператор сравнения подстрок. Асимптотика: O(n log(n)) по времени и O(n) по памяти. Исходный код.
Задача 4. Сортировка всех циклических сдвигов строки длины n в лексикографическом порядке за O(n·log(n)2)
Дано: Строка S длины до 10^5. Вывести номер позиции исходного слова в отсортированном списке циклических сдвигов. Если таких позиций несколько, то следует вывести позицию с наименьшим номером. Во второй строке вывести последний столбец таблицы циклических сдвигов.
Пример: Ввод: "abraka", Вывод: "2 karaab"
Ссылка на задачу на acmp.ru.
ЗамечанияНе забудьте, что быстрая сортировка в процесса своей работы может переставлять элементы, но по условию задачи, равные циклические сдвиги не переставляются. Изначально теста против этого не было, теперь он есть. Более того, одиночный полиномиальный хэш по модулю 2^64 валится на этой задаче. Изначально анти-хэш теста не было, теперь он есть.
Решение и кодНе хотите строить суффиксный массив? Я тоже. Но когда-то все-таки нужно будет его построить, а пока продублируем строку S и посчитаем полиномиальный хэш на префиксе. Каждый циклический сдвиг будем представлять в виде числа (начальной позиции). Сложим в вектор все позиции, а дальше применим устойчивую сортировку слиянием, используя оператор сравнения подстрок. Асимптотика: O(n log(n)^2) по времени и O(n) по памяти.
Код сортировкой слиянием: 0.9 с
Код быстрой сортировкой без перемешивания: 2.5 c
Код быстрой сортировкой с перемешиванием: 1.8 с
Победила сортировка слиянием. Если кто-нибудь сдаст построением суффиксного массива, сообщите Ваш результат.
Задача 5. Нахождение количества подпалиндромов строки длины n за O(n·log(n))
Дано: Строка S длины до 10^5. Вывести количество подпалиндромов строки.
Пример: Ввод: "ABACABADABACABA", Вывод: 32
Ссылка на задачу на acmp.ru с ограничениями до 10^5.
Ссылка на задачу на acmp.ru с ограничениями до 10^6.
Решение и кодСкопируем исходную строку и обратим порядок элементов. Построим полиномиальный хэш на префиксах исходной строки и развернутой. Будем перебирать центры палиндромов и применять бинарный поиск по длине максимального палиндрома, имеющего центр в текущем символе.
Пусть строка S — исходная, а строка T — развернутая. Тогда необходимо сравнивать хэши:
S[i...i+len-1] и T[j...j+len-1], где j = n - i + 1.
Затем будем строить палиндромы четной длины. В этом случае нужно сравнивать хэши:
S[i+1...i+len] и T[j...j+len-1], где j = n - i + 1.
Асимптотика решения: O(nlog(n)) по времени и O(n) по памяти. Исходный код для 10^5 Исходный код для 10^6
Задача 6. Количество подстрок строки длины n, являющихся циклическими сдвигами строки длины m за O((n + m)·log(n))
Дано: Заданы две строки S и T длины до 10^5. Необходимо определить, сколько подстрок строки S являются циклическими сдвигами строки T.
Пример: Ввод: S = "aAaa8aaAa", T="aAa", Вывод: 4
Ссылка на задачу на acmp.ru.
Решение и кодЗапомним исходную длину строки T и продублируем строку 2 раза. Пусть n — исходная длина. Построим полиномиальный хэш на префиксах строк S и T. Выпишем хэши всех подстрок длины n строки T и отсортируем. Теперь задача свелась к тому, чтобы поискать каждую подстроку длины n строки S среди выписанных хэшей строки T. Это можно сделать за O(n log(n)) по времени и O(n) по памяти. Исходный код.
Задача 7. Количество суффиксов строки длины n, бесконечное расширение которых совпадает с бесконечным расширением всей строки за O(n·log(n))
Дано: Строка S длины до 10^5. Бесконечным расширением строки назовем строку, полученную выписыванием исходной строки бесконечное число раз. Например, бесконечное расширение строки "abс" равно "abcabcabcabcabc...". Необходимо ответить на вопрос, сколько суффиксов исходной строки имеют такое же бесконечное расширение, какое и строка S.
Пример: На входе: S = "qqqq", на выходе 4.
Ссылка на задачу на acmp.ru.
Решение и кодПервым делом развернем строку S и будем решать для префиксов. Построим полиномиальный хэш на префиксе строки S. Далее необходимо сравнить расширение каждого префикса с расширением исходной строки.
Пусть есть префикс S[0...m) длины m и префикс S[0...n) длины n, где n >= m. Рассмотрим расширение длины n*m. Это будет означать, что мы префикс S[0..m) запишем n раз подряд, а префикс S[0..n) — m раз подряд:
S[0...m)* = (1+p^m+p^(2m)+p^(3m)+p^((n-1)m))(S[0] + S[1] * p + S[2] * p^2 + ... + S[m-1] * p^(m-1)))
S[0...n)* = (1+p^n+p^(2n)+p^(3n)+p^((m-1)n))(S[0] + S[1] * p + S[2] * p^2 + ... + S[n-1] * p^(n-1)))
Хэш на префиксе вычислять мы уже умеем, осталось решить подзадачу вычисления следующей суммы:
sum(a, k) = 1+a+a^2+a^3+...+a^(k-1)
Ответ sum(a, k) = (a^k-1) / (a - 1) = (a^k - 1) * inverse(a-1, mod) — неверный, так как у четных чисел нет обратных в кольце по модулю 2^64.
Пусть k — четное, например, k = 8. Тогда:
sum(a,8) = 1+a+a^2+a^3+a^4+a^5+a^6+a^7 = (1+a)*(1+a^2+a^4+a^6) = (1+a) * sum(a^2, 4)
пусть k — нечетное, например, k = 7. Тогда:
sum(a,7) = 1+a+a^2+a^3+a^4+a^5+a^6 = 1 + a * (1+a+a^2+a^3+a^4+a^5) = 1 + a * sum(a, 6)
Получили рекуррентные формулы, позволяющие вычислять значения sum(a, k) для любых a и k за O(log(k)):
sum(a, 2*k) = (1+a) * sum(a^2, k) и sum(a, 2*k+1) = 1 + a * sum(a, 2*k).
В случае простого же модуля предложенный способ вычисления суммы геометрической прогрессии быстрее в два раза, чем sum(a, k) = (a^k - 1) * inverse(a-1, mod), так как второй способ вызывает функцию быстрого возведения в степень два раза. В случаях с хэшами ускорение в два раза может быть критично.
Осталось только сравнить sum(p^m, n) * pref(m) с sum(p^n, m) * pref(n). Асимптотика решения O(n log(n)) по времени и O(n) по памяти. Исходный код.
Задача 8. Наибольший общий префикс двух строк длины n с обменом двух произвольных символов одной строки местами за O(n·log(n))
Дано: Строки S и T длиной до 2*10^5. Разрешается один раз обменять местами два произвольных символа строки S или не менять вовсе. Найти максимальную длину наибольшего общего префикса среди всех возможных замен.
Пример: На входе: S = "aaabaaaaaa" и T = "aaaaaaaaab", на выходе 10.
Ссылка на задачу.
Решение и кодЗаметим, что для улучшения результата нужно обязательно поменять местами элемент в позиции первого различия строк. После нахождения этой позиции пытаемся менять по очереди этот символ со всеми символами, находящимися после него и находить длину наибольшего общего префикса бинарным поиском. Как пересчитывать полиномиальный хэш на префиксе длины len после замены символов в позициях i и j? Три случая:
Отрезок [0, len) не содержит i: ответ pref(len)
Отрезок [0, len) не содержит j: ответ pref(i) + a[j] * p ^ i + pref(len) - pref(i+1)
Иначе: pref(i) + a[j] * p ^ i + pref(j) - pref(i+1) + a[i] * p ^ j + pref(len) - pref(j+1)
Асимптотика: O(n log(n)) по времени и O(n) по памяти. Исходный код.
На этом все. Надеюсь, этот пост поможет Вам активно применять хэширование и решать более сложные задачи. Буду рад любым комментариям, исправлениям и предложениям. В ближайших планах перевести этот пост на английский язык, поэтому нужны ссылки, где эти задачи можно сдать на английском языке. Возможно, к тому времени Вы внесете существенные корректировки и дополнения в этот пост. Ребята из Индии говорят, что пытались сидеть с гугл-переводчиком и переводить с русского языка посты про полиномиальный хэш и у них это плохо вышло. Делитесь другими задачами и, возможно, их решениями, а также решениями указанных задач не через хэши. Спасибо за внимание!
Полезные ссылки:
Rolling Hash (Rabin-Karp Algorithm)
Anti-Hash test
Выбор точки хэширования
Anti-Double Hash test
Полиномиальные хеши



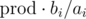 , где
, где 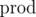 — произведение всех ai. На этом идеи кончились и нужна помощь. Может из-за маленького n решение предполагает динамику за O(n2) времени с памятью O(n), но с ней тоже не вяжется.
— произведение всех ai. На этом идеи кончились и нужна помощь. Может из-за маленького n решение предполагает динамику за O(n2) времени с памятью O(n), но с ней тоже не вяжется.





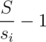 отрезков
отрезков 