


Hii I am trying to solve this problem http://www.spoj.com/problems/ZQUERY/ after thinking so many days i am not able to come up with efficient solution ,would any one like to suggest some idea, how to solve this ?
Hii I am trying to solve this problem http://www.spoj.com/problems/ZQUERY/ after thinking so many days i am not able to come up with efficient solution ,would any one like to suggest some idea, how to solve this ?
| # | User | Rating |
|---|---|---|
| 1 | Benq | 3792 |
| 2 | VivaciousAubergine | 3647 |
| 3 | Kevin114514 | 3603 |
| 4 | jiangly | 3583 |
| 5 | turmax | 3559 |
| 6 | tourist | 3541 |
| 7 | strapple | 3515 |
| 8 | ksun48 | 3461 |
| 9 | dXqwq | 3436 |
| 10 | Otomachi_Una | 3413 |
| # | User | Contrib. |
|---|---|---|
| 1 | Qingyu | 157 |
| 2 | adamant | 153 |
| 3 | Um_nik | 147 |
| 3 | Proof_by_QED | 147 |
| 5 | Dominater069 | 145 |
| 6 | errorgorn | 142 |
| 7 | cry | 139 |
| 8 | YuukiS | 135 |
| 9 | TheScrasse | 134 |
| 10 | chromate00 | 133 |







Obviously, you can sort the queries to solve the problem offline and use prefix sums to covert the question to "longest subarray with S[l] = S[r], L ≤ l ≤ r ≤ R.
Then, you can increase R and keep the answers for all L; it's just a matter of updating these answers when R is incremented. It can be done in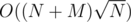 .
.
@Xellos Thanks , can you explain more how to solve efficiently to find the longest subarray with S[l]=S[r] ,L<=l<=r<=R,
can you please explain the part keep answer for all L?
First we use this Mo's algorithm to sort Query.
http://mirror.codeforces.com/blog/entry/7383
Let's call each group is a "bucket"
For each Query, we have to find i j which s[i] = s[j] and L<=i<=j<=R
Each i j has 3 cases :
i and j in bucket, so we can for, just O(sqrt(n))
i in bucket, j out of bucket. Let's call id1[s[j]]=j is the max position of s[j]. So answer is max(id1[s[i]]-i)
i and j out of bucket. Similar, call id2[s[j]]=j is the min position of s[j], so answer is max(id1[s[j]]-id2[s[j]])
I_love_PMK can you explain bit more after query sorting step ?
Let's p = sqrt(n)
Every query has L <= p is in bucket 1
p < L <= 2*p is in bucket 2....
With every query in the same bucket, sort query with increasing of R.
I have solved it with MO's algorithm + segment tree for keeping track of the maximum value . Complexity is O( (N + M) * ROOT(N) * LOG (N) ) .
Here is the implementation http://ideone.com/YayNX7.
It would be good is someone can tell how to solve without the segment tree in O( (N + M) * ROOT(N) ).
Could you please explain how did you solve it??
Have a look at codechef march challenge problem: qchef , it has a nice and detailed editorial.
Thanks Everyone now it is solved :)
Here is a editorial to a different problem with a similar solution.
WOW a post from 11 years ago. But I have a brute force like solution using SQRT decomposition.
Let's build a prefix sum of the array. Then we have to find
max(j - i)wherepref[i] = pref[j]holds for everyl - 1 <= i < j <= rin each query.Let's add
Ntoo everypref[i]. Sincepref[i]is either 1 or -1, after addingN,0 <= pref[i] <= 2 * Nholds for everyi. (We basically did a coordinate compression)Let
Sbesqrt(N). And we will divide the arrayprefintoSblocks. (Each block containsSnumbers.) And we are constructing 2D arraylenwith sizeS x Sas follows: for every0 <= I <= J < S,len[I][J]denotes max value ofj - iwherepref[i] = pref[j]andi,jbelongs toIth,Jth block respectively. This can be done usingvector<int> index[2 * N + 1]whereindex[value]contains everyisuch thatpref[i] = valuein increasing order. TIME COMPLEXITY will beN * sqrt(N) * log(N).Denote
MAX(I, J)as maximum oflen[x][y]whereI <= x <= y <= J. And we are updating ourlen[I][J]to 'MAX(I, J)for each0 <= I <= J < Ssimultaneously. This can be done using Floyd Warshall. TIME COMPLEXITY will besqrt(N)^3orN * sqrt(N)`.Finally, let's answer our queries. Let
l - 1,rbelongs toLth,Rth block respectively andj - ibe our optimal answer. If none ofiandjbelongs to blockLand blockRthen the answer is simplylen[L + 1][R - 1]. (ifx > ythenlen[x][y] = 0) Ifibelongs toLorjbelongs toRthen we can just compute the answer insqrt(N) * log(N)time using thevector<int> index[].Therefore, overall time complexity will be
N * sqrt(N) * log(N).the code will be something like: for pre-queries: ~~~~~ pref[0] = n; for(int i = 1; i <= n; i++) { pref[i] += a[i]; index[pref[i]].push_back(i); }
for(int J = 0; J < S; J++) for(int I = 0; I < J; I++) { for(int i : block[I]) { int val = pref[i]; auto it = upper_bound(index[val].begin(), index[val].end(), block(J).back()); if(it != index[val].begin()) { len[I][J] = max(len[I][J], *prev(it) — i); } } }
for(int M = 0; M < S; M++) for(int L = 0; L < S; L++) for(int R = 0; R < S; R++) { if(L <= M && M <= R) { len[L][R] = max(len[L][R], len[L][M]); len[L][R] = max(len[L][R], len[M][R]); } } ~~~~~ for queries: ~~~~~ for(auto [l, r] : query) { l--; int L = block_id(l), R = block_id(r); int ans = 0; if(L + 1 <= R — 1) ans = max(ans, len[L + 1][R — 1]);
for(int i = l, i <= block[L].back(); i++) { int val = pref[i]; auto it = upper_bound(index[val].begin(), index[val].end(), r); if(it != index[val].begin()) { ans = max(ans, *prev(it) - i); } } for(int i = block[R][0], i <= r; i++) { int val = pref[i]; auto it = lower_bound(index[val].begin(), index[val].end(), l); if(it != index[val].end()) { ans = max(ans, i - *it); } } cout << ans << endl;} ~~~~~