


This blog will compile a list of codeforces issues along with all the times Mike has ignored complaints about them
1. Unreasonable delay for viewing submissions [+973]
Submission pages on Codeforces often not loading [+281] by jeroenodb on October 2024
Unreasonable delay for viewing submissions [+392] by djm03178 on October 2024
Please, give us proper explanations about this nonsense. [+300] by djm03178 on December 2024
No MikeMirzayanov reply
2. Cloudflare misconfiguration [+1232]
Posted CF should rename itself to Cloudflare instead of Codeforces by nor
No MikeMirzayanov reply, nor has since deleted all of their blogs on codeforces
3. IP ban + blocked by the administrator [+105]
Happens right after the DDOS of Codeforces Round 1010 (Div. 1, Unrated), I myself also couldn't login that day
No MikeMirzayanov reply, silent fix (+ one extra cloudflare page on login)
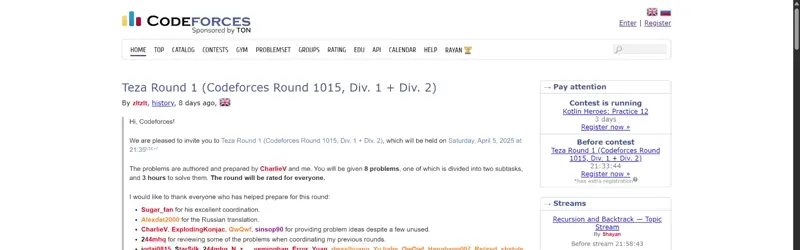
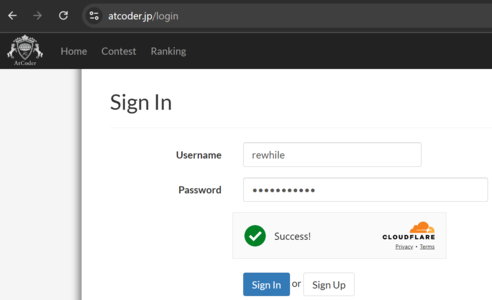
What's up with this abomination of cloudflare usage? I think https://atcoder.jp/login is more reasonable:
4. Recently, your account was used to crawl [+105]
- My account got flagged... posted by _tudor_costin_ [+98]
- Why my account become flagged? posted by FZANOTFOUND [+7]
djm03178's account also got flagged as crawling bot for joining codeforces educational round hacking phase
No MikeMirzayanov reply, radio silent as always
5. Hacking issues
Couldn't hack today by sorry12000 where he couldn't get points hacking A
This also affected dorijanlendvaj. 2 years later he lost 50 points due to an interactor bug but offered no rejudge
No MikeMirzayanov reply
6. API issues
If you've used a rating predictor, for example carrot (40000 users as of April 2025)

You might have noticed that it doesn't work for a long period of time. This is because Mike enabled cloudflare even for apis during contest, which got a workaround in meooow25/carrot#67
It worked for a while again until he started to take down the user.ratedList api during contest too: 
MikeMirzayanov did make a comment about this api 3 years ago. However, it seems like there was no further communication.
∞. The list could stop here
Despite almost graduating from university, when I type c in browser it autocompletes to codeforces.com instead of chatgpt.com

It is not unreasonable to ask for accountability when CF has become the de-facto competitive programming community website.






