While upsolving this problem, I noticed that there appears to be a dearth of editorials; I couldn't find any official ones, and the only unofficial one I found is this one, which is unfortunately rather poorly formatted. Thus, I've decided to try my hand at writing my own editorial for future reference. Feel free to comment with any questions!
NOTE: You can also read this editorial on my blog, which has slightly better formatting.
Basics
First, consider how we might solve the problem if $$$X=Y$$$. Actually, if we let $$$d(u,v)$$$ denote the distance between nodes $$$u$$$ and $$$v$$$, it turns out the following algorithm works:
In order of increasing $$$d(u,X)$$$ and while we have not exceeded the $$$K$$$ threshold, set the closing time of node $$$u$$$ to be $$$d(u,X)$$$.
Proof. We can use a bounding argument.
- If we want $$$k$$$ nodes to be reachable from $$$X$$$, then the closing times of each of these nodes $$$u_i$$$ must be at least $$$d(u_i,X)$$$; therefore, the answer is lower-bounded by the sum of the $$$k$$$ smallest $$$d(u,X)$$$.
- At the same time, our construction guarantees that all $$$k$$$ nodes can be visited. Roughly, this is because if we select all nodes with $$$d(u,X) \lt D$$$ for some threshold $$$D$$$, there necessarily exists a path using only these nodes to any node with $$$d(u,X)=D$$$ (by definition of distance).
(Note that this approach for $$$X=Y$$$ should apply to general graphs as well, not just trees)
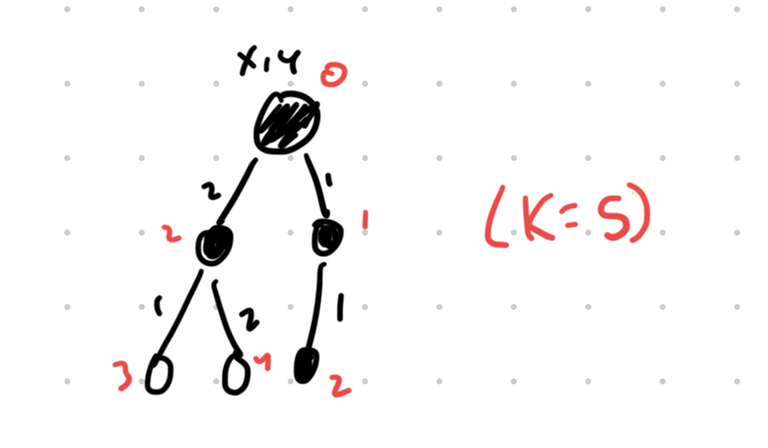
An illustration of this strategy. The red numbers represent $$$d(u,X)$$$ for each node, and the shaded nodes are the ones for which we set the closing times to $$$d(u,X)$$$. All other closing times are 0.
Subtask 1
Now, let's consider the first subtask in which the distance between $$$X$$$ and $$$Y$$$ is greater than $$$2K$$$. This means that no node can be reachable from both $$$X$$$ and $$$Y$$$, which means we can essentially reuse our solution for $$$X=Y$$$! In particular:
- Let $$$c(u)=\min(d(u,X),d(u,Y))$$$.
- Like before, sort by $$$c(u)$$$ and take until we can't.
The proof of correctness is essentially the same as in the $$$X=Y$$$ case.
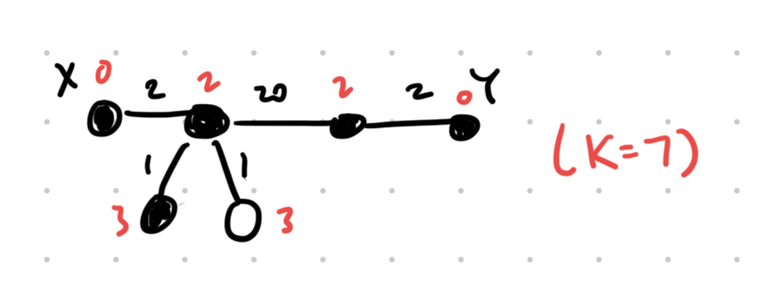
Again, red numbers represent cost and shaded nodes are the reachable ones. In this scenario, the best answer is therefore 5.
Line
Now, consider the case in which the tree is a single line, and $$$X$$$ and $$$Y$$$ are at its ends (but the distance between them can now be less than $$$2K$$$). Now, a node $$$u$$$ could be reachable from both $$$X$$$ and $$$Y$$$ as long as its closing time is at least $$$C(u)=\max(d(u,X),d(u,Y))$$$. Thus, we now have to decide for each node whether it's reachable zero times, once, or twice (corresponding to costs 0, $$$c(u)$$$, and $$$C(u)$$$ respectively).
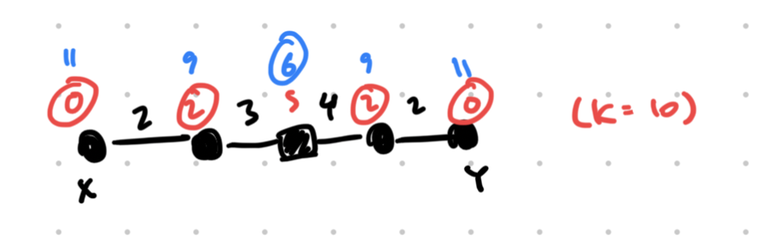
A possible solution. The square means we want this node to be reachable from both $$$X$$$ and $$$Y$$$, and the blue costs represent $$$C(u)$$$. Therefore, the total cost of this configuration is $$$0+2+6+2+0=10 \le K$$$. The total convenience is 1 + 1 + 2 + 1 + 1 = 6.
First, note that in order for any node to be a square, all nodes on this line must at least be shaded circles first (some of which we can then "upgrade" to squares). Moreover, the nodes upgraded to squares must start from the midpoints and propagate outward. For instance, in the example above, it'd be invalid to have only the second node from the left as a square, and the rest as circles.
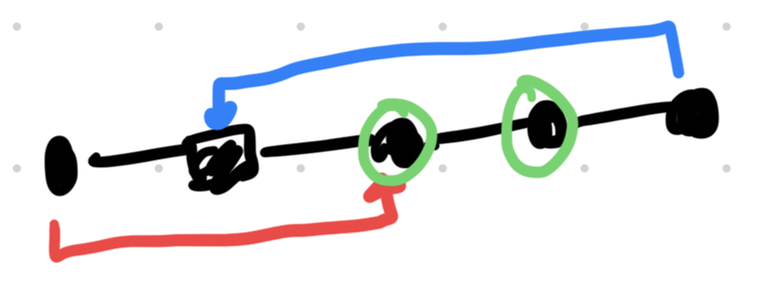
The midpoints are circled in green (lengths are the same as in the above image). Note that if the second-from-left node is a square, the third-from-left node must also be a square. Therefore, the configuration shown here is invalid.
However, just like before, it turns out that any optimal configuration is actually valid!
Proof. Consider the cost of upgrading each node, $$$C(u)-c(u)$$$. Plotting, it should look something like this:
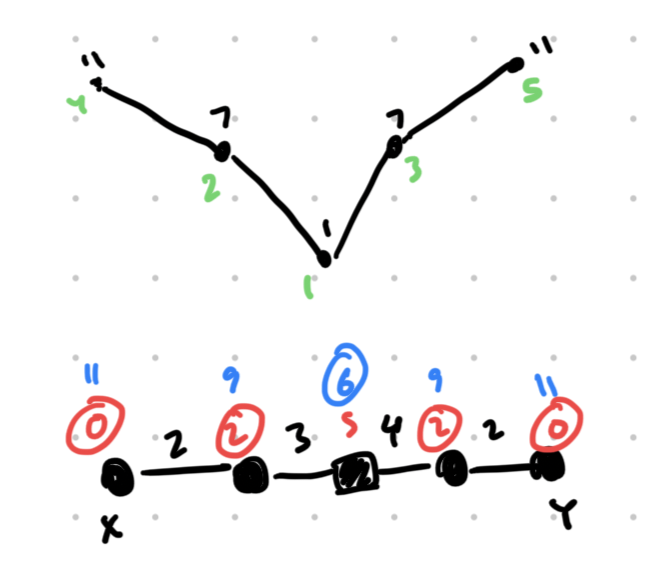
The cost will decrease until the first midpoint, then increase after the second midpoint (costs are shown above the graph in black, and the order of upgrades is indicated by the green numbers). Therefore, upgrades always radiate outward from the center, which corresponds to a valid solution.
Thus, our final algorithm is as follows:
- First, upgrade nodes to shaded circles in order of increasing $$$c(u)$$$ while we still can.
- If any nodes remain unshaded, terminate.
- Otherwise, upgrade circles to squares in order of increasing $$$C(u)-c(u)$$$.
The final answer is $$$(\text{# of shaded circles})+2\times(\text{# of squares})$$$.
Tree
To generalize our line solution, we claim the following solution works for any tree:
- First, find the answer under the assumption that no node is reachable twice (this is the Subtask 1 solution).
- Otherwise, assume some node is reachable twice: this means that all nodes on the path from $$$X$$$ to $$$Y$$$ must be upgraded at least once.
- From here, make any additional upgrades: we claim that any choice of upgrades that minimizes total cost necessarily corresponds to a valid solution.
If the claim in point 3 is true (which we will prove momentarily), the problem reduces to the following:
You are presented with $$$n$$$ boxes. From box $$$i$$$ you can take zero items for cost 0, one item for cost $$$c_i$$$, and two items for cost $$$C_i$$$. It is guaranteed $$$c_i \le C_i$$$. Find the maximum number of items that can be taken given that the total cost must not exceed $$$K$$$.
To solve this, we can split boxes into two types:
- When $$$c_i \le C_i-c_i$$$: We can split this box into two single-item boxes with cost $$$c_i$$$ and $$$C_i-c_i$$$ respectively. Note that we should never take the second box without taking the first box, so any valid solution with this reduction corresponds to a valid solution for the original problem as well.
- When $$$2c_i \gt C_i$$$: Note that if we take two half-boxes of this type, it's always better to instead take the entire box with smaller $$$C_i$$$.
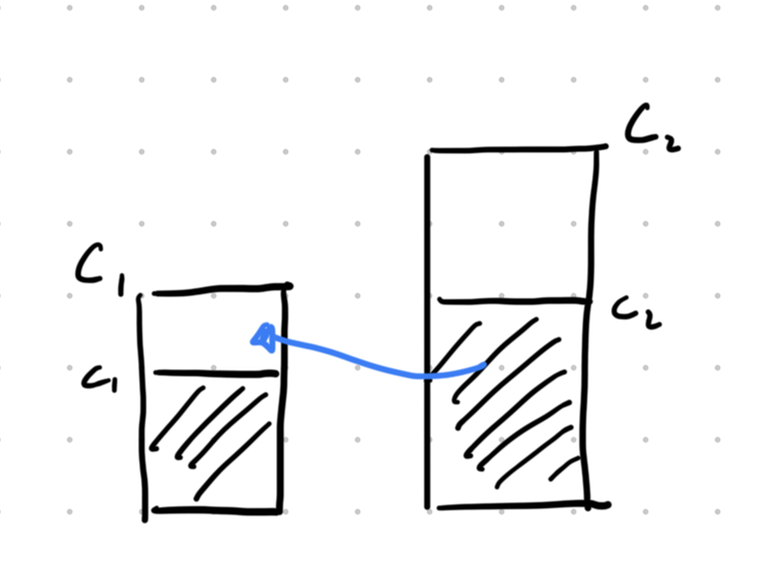
Two half-boxes. A lower-cost solution can be achieved by making the swap indicated by the blue arrow.
Therefore, we will take at most one half-box of this type, and the remaining full boxes should then be taken in order of increasing $$$C_i$$$. So, sorting these boxes by $$$C_i$$$, we will always take a prefix with the exception of at most one element (which should be the element with maximum $$$C_i-c_i$$$ or some later element with minimal $$$c_i$$$).
So, we can just enumerate all prefixes of type 2 boxes, as well as whether we choose one of these boxes to be a half-box, then find the maximum number of type 1 boxes (which have been reduced to single item-boxes) we can take afterward. This can all be done in $$$\mathcal{O}(n \log n)$$$.
Proof of claim. We wish to show that the optimal solution found by the above algorithm (which relaxes the original problem constraints) actually always corresponds to a valid solution under the original constraints as well.
First, let $$$S$$$ be the set of nodes upgraded any number of times in an optimal solution.
Lemma. If the solution is optimal, then $$$S$$$ will be connected.
Proof. Recall that all nodes on the path from $$$X$$$ to $$$Y$$$ are necessarily part of $$$S$$$. For other nodes in $$$S$$$, if its parent (when the tree is rooted at $$$X$$$) is not in $$$S$$$, it cannot be worse to replace this node with its parent.
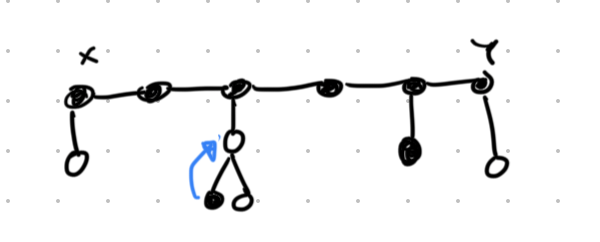
If $$$S$$$ is not connected, the blue move cannot increase cost.
Now, we just need to show that the selection of squares in an optimal solution leads to a valid configuration as well. This can be shown as follows:
- First, decide $$$S$$$ and upgrade all nodes in $$$S$$$ to circles.
- Then, additionally upgrade some of these nodes to squares in increasing order of $$$C(u)-c(u)$$$.
The key thing to note here is that within each subtree hanging off the path from $$$X$$$ to $$$Y$$$, the value of $$$C(u)-c(u)$$$ is constant.

Each subtree is shown with the upgrade cost corresponding to every node in that subtree.
Therefore, just as before, our upgrades will radiate from the center subtree outward. Furthermore, because upgrade cost is constant within a subtree, we can always upgrade in a way such that shallower nodes are upgraded first. It can be shown that these conditions will always result in a valid solution.
Code
My QOJ submission
















