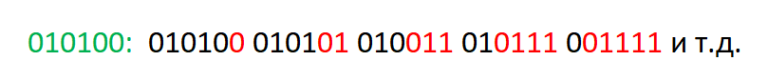В этом году проходил BSUIR Open XIV, мне было очень приятно съездить в Минск и на само соревнование. Но еще больше мне понравилась задачу, которую я туда предложил. В целом я не видел эту идею раньше, но она кажется достаточно простой, чтобы появиться раньше на каких-нибудь соревнованиях. Так что если вы знаете, где раньше встречалась это идея, то поделитесь, пожалуйста.
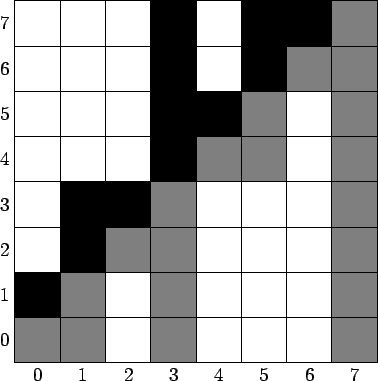
Задача. (*BSUIR OPEN XIV*) Дано клеточное поле $$$100 \times 100$$$, в котором между некоторыми клетками проведены стены, также стены проведены по границе поля. Луч запускается из центра клетки $$$(r,c)$$$ в направлении $$$(x,y)$$$. Требуется определить, в какой клетке он окажется, пройдя расстояние $$$\sqrt{x^2+y^2}$$$, если луч отражается от стен.
Решение задачки
Взглянем на вектор $$$(x,y)$$$ и посмотрим, в каком порядке он пересекает вертикальные и горизонтальные линии сетки. В точке $$$(0,0)$$$ пересечение с линиями сетки учитывать не будем, но будем учитывать пересечения в точке $$$(x,y)$$$, причем по формальным причинам мы будем считать, что сначала происходит пересечение с вертикальной прямой.

Последовательность пересечений можно записать в виде строки:
- $$$R$$$ обозначает пересечение вертикальной линии сетки (перемещение на клетку вправо),
- $$$U$$$ обозначает пересечение горизонтальной линии сетки.
Тогда каждому вектору $$$(x,y)$$$ можно сопоставить строку $$$s(x, y)$$$, содержащую последовательность этих пересечений. Например,
Предположим, что $$$x \ge y$$$. Это означает, что вектор «пологий», и перед каждым пересечением горизонтальной линии происходит пересечение вертикальной. А именно, перед $$$k$$$-м символом U стоит
подряд идущих символов R.
Таким образом, перед каждым символом U стоит блок, состоящий как минимум из $$$\left\lfloor x/y \right\rfloor$$$ символов R; эти блоки вместе с символами U можно сжать в один символ. Например,
Таким образом, можно предположить, что если $$$s(x, y, R, U)$$$ — это строка $$$s(x,y)$$$, где на месте символов R и U стоят строки $$$R$$$ и $$$U$$$, то верно равенство:
Ясно, что это правда. Например, в случае $$$x \ge y$$$ достаточно убедиться в том, что перед $$$k$$$-м символом $$$U$$$ после подстановки сохраняется количество подряд идущих букв R:
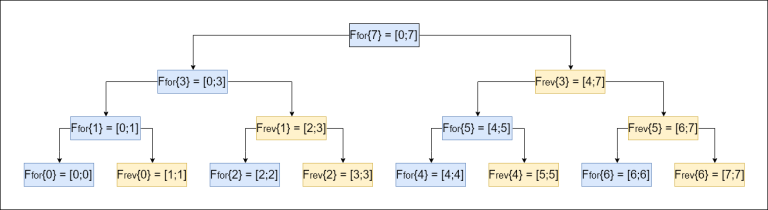
Таким образом, строку $$$s(x,y)$$$ можно вычислять с помощью алгоритма Евклида. Разумеется, в общем случае нам нужна не строка, а какая-то более полезная информация. Символы R и U могут принадлежать произвольному моноиду, для которого можно эффективно вычислять следующие операции:
- произведение элементов;
- возведение элемента в степень.
Например, в качестве моноида могут выступать перестановки, матрицы или любые другие объекты, которые можно поддерживать в дереве отрезков. В частности, в подстроке $$$s(x,y)$$$ можно поддерживать количество подпоследовательностей UR, что соответствует вычислению значения floor_sum (только в таком случае надо аккуратно разобраться с приоритетами символов R и U).
Обобщённо алгоритм трекинга вектора может быть реализован следующим образом:
Другие обобщения
В ходе алгоритма можно строить не композицию моноидов $$$R$$$ и $$$U$$$, а последовательность неполных частных вместе со всеми промежуточными вычислениями. Например, при входных данных $$$(x,y)$$$ таблица вычислений будет выглядеть следующим образом. Напомним, что
| Шаг | Вычисленное значение | $$$q$$$ | $$$x$$$ | $$$y$$$ |
|---|---|---|---|---|
| 1 | RU | 1 | 4 | 3 |
| 2 | RURUR | 2 | 1 | 3 |
| 3 | RURURRU | 1 | 1 | 1 |
Работая со всеми промежуточными вычислениями, можно дополнительно обрабатывать следующие сценарии:
- композицию моноидов $$$R$$$ и $$$U$$$ на любом подотрезке $$$(l,r)$$$ строки $$$s(x,y)$$$.
Так, если запускать вектор не из точки $$$(0,0)$$$, а из произвольной точки $$$(\alpha, \beta)$$$, то может получиться строка $$$s(x,y,\alpha,\beta)$$$, отличная от $$$s(x,y)$$$. Но также ясно, что строка $$$s(x,y,\alpha,\beta)$$$ получается циклическим сдвигом строки $$$s(x,y)$$$.
Чтобы понять, что именно это будет за циклический сдвиг, вспомним, что строку $$$s$$$ можно представить в виде объединения блоков вида R...RU, где количество букв R перед $$$k$$$-й буквой U вычисляется по формуле:
Таким образом, если вектор запускается из произвольной точки $$$(\alpha/y, 0)$$$, то длина $$$k$$$-го блока будет вычисляться по похожей формуле:
В случае взаимной простоты $$$x$$$ и $$$y$$$ можно сделать замену
И тогда число $$$k_0$$$ и будет искомым циклическим сдвигом.
Таким образом, предлагаемый алгоритм является универсальным (и, вероятно, не лучшим по константе времени исполнения) способом для решения многих задач-обобщений floor_sum. В частности,
можно вычислить за время
в общем случае, что достаточно приятно.