


| # | User | Rating |
|---|---|---|
| 1 | Benq | 3792 |
| 2 | VivaciousAubergine | 3647 |
| 3 | Kevin114514 | 3611 |
| 4 | jiangly | 3583 |
| 5 | strapple | 3515 |
| 6 | tourist | 3470 |
| 7 | Radewoosh | 3415 |
| 8 | Um_nik | 3376 |
| 9 | maroonrk | 3361 |
| 10 | XVIII | 3345 |
| # | User | Contrib. |
|---|---|---|
| 1 | Qingyu | 162 |
| 2 | adamant | 148 |
| 3 | Um_nik | 146 |
| 4 | Dominater069 | 143 |
| 5 | errorgorn | 141 |
| 6 | cry | 138 |
| 7 | Proof_by_QED | 136 |
| 8 | YuukiS | 135 |
| 9 | chromate00 | 134 |
| 10 | soullless | 133 |
|
+16
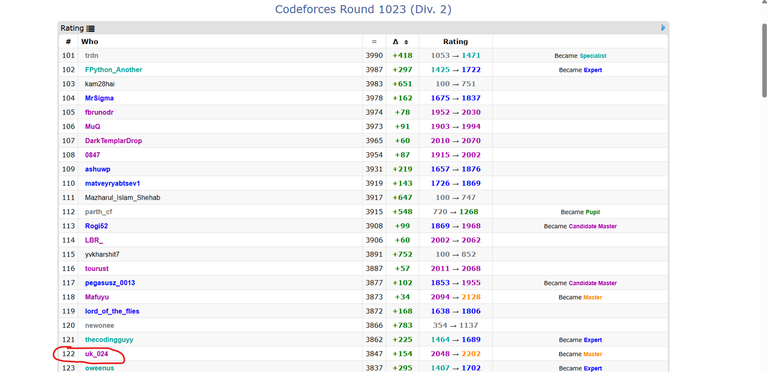
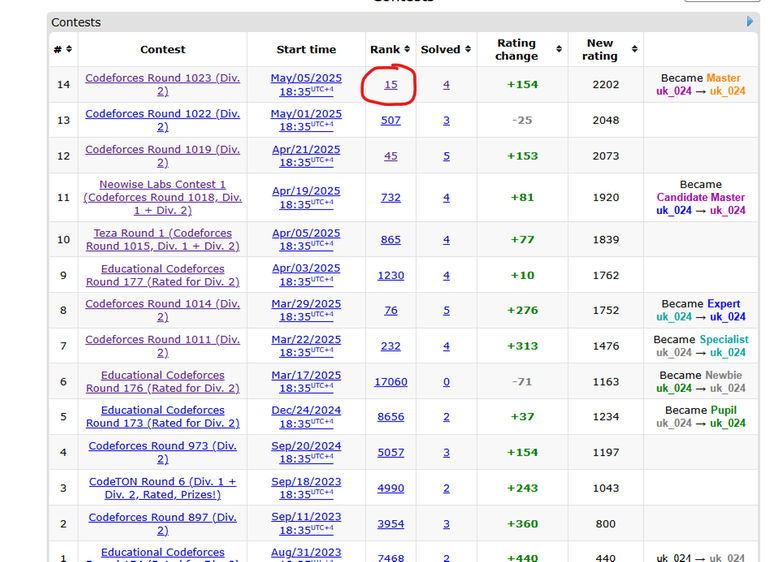
I submitted ~200 lines of persistent segment tree code for the last problem with just a few seconds left — without even compiling it — and it turned out to be bug-free :) It got a TLE on the last subtask. My solution has a time complexity of O(n log n + q log² n). Was this time complexity intended to get full score, or could one of the log factors have been avoided? TheSensei |
|
+20
|
|
0
|
|
+23
Don't know the exact version of CMS that's been used during the Olympiad, but in general CMS supports sort of subtask dependency. It is possible to include same test in any subtask using regex in the scoring section based on the codenames of the tests. You don't need to create the same test several times. |
|
+3
For each number $$$i (1 \lt =i \lt =n)$$$ let $$$l[i], r[i]$$$ be the start position of the first and the last segment of size $$$K$$$ in permutation $$$q$$$ containing $$$i$$$ respectively. Now you can iterate over $$$p$$$ and add $$$1$$$ to range $$$[l[p[i]], r[p[i]]]$$$ and add $$$-1$$$ to range $$$[l[p[i — k], r[p[i — k]]]$$$ and keep track of Max and their Counts (this is just sliding window). This can be done using lazy segment tree. In order to get $$$100$$$ points, you can store $$$N$$$ versions of this segment tree (make it persistent) and for each swap of consecutive numbers you only need to update $$$2$$$ out of these $$$N$$$ segment trees. Let $$$t$$$ and $$$t+1$$$ be the positions we swap. One can easily notice that only the segments ending at $$$t$$$ and starting at $$$t+1$$$ changes (for sure if such a segment of size $$$K$$$ exists). You can use another segment tree (a simple one) in order to find $$$(Max, Count)$$$ over the roots of these $$$N$$$ segment trees. |
|
0
Note: I haven't submitted this code during the contest, so I'm not sure if it is bug free or not. Works on samples. |
|
+18
Better alternative |
|
+15
Only the divisors of k are important and they are quite less. |
|
+17
Thank you for the online mirror. Problems were nice! Do you plan to add them to CF GYM or some other judge? |
|
On
Mamedov →
International Lotfi Zadeh Olympiad (ILO) 2021 for the 1st time — Online Mirror, 4 years ago
0
Auto comment: topic has been updated by Mamedov (previous revision, new revision, compare). |
|
On
Mamedov →
International Lotfi Zadeh Olympiad (ILO) 2021 for the 1st time — Online Mirror, 4 years ago
+8
Sorry for that. A few guys asked me to extend it, but I forgot to post about it here. Now updated |
|
On
Mamedov →
International Lotfi Zadeh Olympiad (ILO) 2021 for the 1st time — Online Mirror, 4 years ago
0
Auto comment: topic has been updated by Mamedov (previous revision, new revision, compare). |
|
On
Mamedov →
International Lotfi Zadeh Olympiad (ILO) 2021 for the 1st time — Online Mirror, 4 years ago
0
We're glad you liked it! Yes, we will post the editorials in the official website after the mirror contest |
|
On
Mamedov →
International Lotfi Zadeh Olympiad (ILO) 2021 for the 1st time — Online Mirror, 4 years ago
+1
Auto comment: topic has been updated by Mamedov (previous revision, new revision, compare). |
|
+2
You can store consecutive elements as decimal numbers since these elements are digits in base k. This way you will get rid of one L factor. |
|
In problem Servers, I come up with the following idea: If server a stores data chunk d, then there should be an increasing path form node d to node a if we add weighted edges to the graph (tree), where weights are just the query indexes. Now Q type of queries can be solved using binary lifting if we build the tree offline and we can check whether these two nodes are in the same component using DSU. This increasing path idea maybe can be applied to C type off queries. I don't know exactly how, but the idea is the number of servers that contains chunk d is the number of nodes that has an increasing path from d |
|
0
Thanks |
|
+15
Strange |

|
+3
There is a shitty bug in the code. I couldn't find it during the contest. The solution is actually correct for both E1 & E2 except that blinder |
|
0
try to find the bug and feel that pain Maybe time to quit CP :) |
|
0
Auto comment: topic has been updated by Mamedov (previous revision, new revision, compare). |
|
+14
Yeap. I also didn't receive my Google Code Jam and Russian Code Cup T-shirts. |
|
+1
Please could someone explain, why this 19701013 solution got AC? İt's complexity is O(n*max(ai)). |
|
+1
|
|
+15
Thanks a lot sokian. I got this idea. |
|
0
In our case modulo M is not a prime, it can be any number, but by this way we will need to calculate modular inverse. |
|
0
Auto comment: topic has been updated by Mamedov (previous revision, new revision, compare). |
|
0
Auto comment: topic has been updated by Mamedov (previous revision, new revision, compare). |
|
0
Thank a lot bro |
|
0
Who can explain problem D ? We solved it with binary_search, and for any step of binary_search we just check if it fits the given size or not, but we get Wrong Answer on test 2. |
