|
+3
OK, thank you! I thought Serge would be able to say that there are exactly k people lying (no matter which), not that there are exactly k people for which he knows that they are lying. |
|
+11
I have some trouble understanding Div1D. If 0<k<n, then nobody can answer 0. How can Serge with such answers find out that not everybody is a liar (if everybody is a liar, then everybody can answer anything)? |
|
+14
It took me much time to find out that the c++ compiler on the grading server does not support %Lf (to output long double). Maybe there could be added a warning if you submit code containing %Lf (as with %lld). |
|
-21
What exactly do you mean by "map" and how do you know that map is too slow only by a constant factor? At least I could imagine that in some cases map compares people with many friends too often. (As an extreme example: Let's not use a map but sort the people (I guess this doesn't make a huge difference). The runtime depends on the internals of the sorting algerithm: The sorting algorithm might be "stupid" and first compare the two persons with the most friends with each other n times and then do quicksort. This sorting algorithm works in O(n log(n)) if comparison could be done in O(1) but it can take O(nm) when persons have to be compared lexicographically.). |
|
+15
I think I found an O((n+m)log(n)) solution without hashing. Unfortunately it seems to be too slow by a constant factor. It works as follows: (1) Let v(i) be the list of friends of i. (2) Sort v(i). Create the list 1..n. Sort it by length(v(i)). Then sort each chunk of this list with constant length(v(i)) by v(i) (lexicographically). Afterwards you can easily divide this list into chunks with equal v(i) in time O(n+m). This gives the number of doubles (i,j) which are not friends. (3) Add i to v(i) and repeat step 2. This time you get the number of doubles (i,j) which are friends. |
| # | User | Rating |
|---|---|---|
| 1 | Benq | 3792 |
| 2 | VivaciousAubergine | 3647 |
| 3 | Kevin114514 | 3603 |
| 4 | jiangly | 3583 |
| 5 | strapple | 3515 |
| 6 | tourist | 3470 |
| 7 | dXqwq | 3436 |
| 8 | Radewoosh | 3415 |
| 9 | Otomachi_Una | 3413 |
| 10 | Um_nik | 3376 |
| # | User | Contrib. |
|---|---|---|
| 1 | Qingyu | 158 |
| 2 | adamant | 152 |
| 3 | Proof_by_QED | 146 |
| 3 | Um_nik | 146 |
| 5 | Dominater069 | 144 |
| 6 | errorgorn | 141 |
| 7 | cry | 139 |
| 8 | YuukiS | 135 |
| 9 | chromate00 | 134 |
| 9 | TheScrasse | 134 |




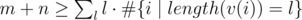 , so this step takes at most time O((n+m)log(n)).
, so this step takes at most time O((n+m)log(n)).