


| # | User | Rating |
|---|---|---|
| 1 | Benq | 3792 |
| 2 | VivaciousAubergine | 3647 |
| 3 | Kevin114514 | 3603 |
| 4 | jiangly | 3583 |
| 5 | strapple | 3515 |
| 6 | tourist | 3470 |
| 7 | dXqwq | 3436 |
| 8 | Radewoosh | 3415 |
| 9 | Otomachi_Una | 3413 |
| 10 | Um_nik | 3376 |
| # | User | Contrib. |
|---|---|---|
| 1 | Qingyu | 158 |
| 2 | adamant | 152 |
| 3 | Proof_by_QED | 146 |
| 3 | Um_nik | 146 |
| 5 | Dominater069 | 144 |
| 6 | errorgorn | 141 |
| 7 | cry | 139 |
| 8 | YuukiS | 135 |
| 9 | chromate00 | 134 |
| 9 | TheScrasse | 134 |
|
0
|
|
0
Uh nope not at all, I just found something to read/write png then it's just an array of numbers to me and I wrote a few helper functions to decorate the output to debug. |
|
+8
At least that one didn't have several identically fully black (or white) pieces like some others where you can't do anything. Abusing the colors in the output i get : Spoiler So this one is about matching noise, I didn't do anything specific and I get garbage because I use only the outer two columns/rows on each piece. But you might get a bit better than random if you match some statistics on the noise ? (there seems to be more or less densely (1,1,1) vs (0,0,0) areas for instance) |
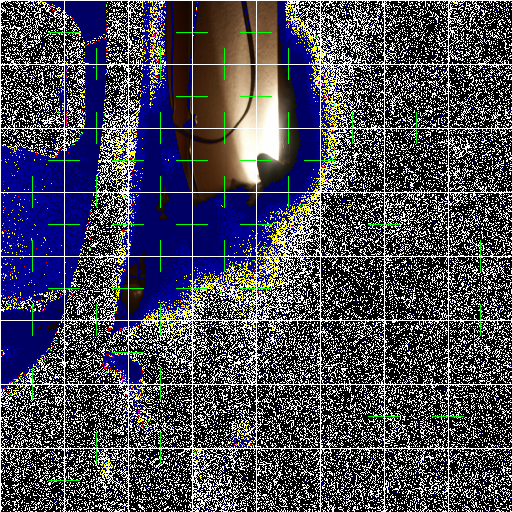
|
+2
Congrats to the winners :) Does anybody have original ideas to share ? I assume most of us had a heuristic for edge-edge compatibility, then a strategy for assembly.
In particular has anyone used linear programming for the assembly ? It looked powerful but I was too lazy to try. When having many small optimizations/variations around I found it hard to tweak and set the parameters (I've never done any machine learning also, maybe that's why). |
|
+25
I got this answer :
|
|
+39
I read the rules in registration but it's still not clear to me :
Does this means it's not allowed to implement, or even take inspiration of research papers on the topic, even if its only a subpart of our solution ? It's not like automatic jigsaw puzzle solving has never been investigated before, and it feels strange to say you have 2 weeks but can't use the internet to see what has been done already... |
|
On
BledDest →
Codeforces Round #585 (Div. 2, based on Qualification Stage of Southern and Volga Russia Regional Contest), 7 years ago
+23
Oh nice ! thanks. Too bad for weak systest though. |
|
On
BledDest →
Codeforces Round #585 (Div. 2, based on Qualification Stage of Southern and Volga Russia Regional Contest), 7 years ago
0
True ! But my unproved solution needs only 78ms 60641026 EDIT : it's been hacked, bad assumption and weak systests... |
|
On
BledDest →
Codeforces Round #585 (Div. 2, based on Qualification Stage of Southern and Volga Russia Regional Contest), 7 years ago
0
20^2 * 2^20 (~4e8) felt slow to me when I thought about it but it's true there's 4s |
|
On
BledDest →
Codeforces Round #585 (Div. 2, based on Qualification Stage of Southern and Volga Russia Regional Contest), 7 years ago
0
I didn't prove it, but I couldn't find a counter-example, it felt true, and it gets AC so it should be good ? Kudos if you find a hack or a proof :-) It's faster also, just the complexity of precomputing inversions in 20 * 4e5 |
|
On
BledDest →
Codeforces Round #585 (Div. 2, based on Qualification Stage of Southern and Volga Russia Regional Contest), 7 years ago
0
Compute for each pair of color i,j the cost of putting color i before j and the cost of putting j before i (number of inversions between the two colors), and add the minimum to the result. |
|
+5
For undirected graphs, the edges of one color form a tree so atmost $$$n-1$$$ edges, but the graph can have $$$\frac{n(n-1)}{2}$$$ edges so it is clear the bound of 2 will not hold. |
|
+20
To find if there is a cycle in a directed graph, you can do a DFS marking differently vertex currently treated and vertex you finished treating. If you encounter a vertice still in treatment, it means it's an ancestor in the DFS and you have a cycle. |
|
On
ch_egor →
Codeforces Round #583 (based on Olympiad of Metropolises) (div. 1 + div. 2), 7 years ago
0
Your DFS has a problem, because you unmark cells when you exit a dead-end, they might get visited again. On a map like this your code will be super slow : So either you leave cells marked like I do (and think about why it won't change the validity of the algorithm), or you make an extra boolean map keeping if each cell has been visited. |
|
On
ch_egor →
Codeforces Round #583 (based on Olympiad of Metropolises) (div. 1 + div. 2), 7 years ago
+1
The intuition as others said is :
|
|
On
ch_egor →
Codeforces Round #583 (based on Olympiad of Metropolises) (div. 1 + div. 2), 7 years ago
+1
http://mirror.codeforces.com/contest/1214/submission/60006023 In the code I make the second path (B-path) greedily rightward but it's not necessary. pt() just prints the map for debug. |
|
On
ch_egor →
Codeforces Round #583 (based on Olympiad of Metropolises) (div. 1 + div. 2), 7 years ago
+13
Simple solution : I did two DFS, the first to find a path going greedily downwards before rightward, and marking the cells with 'A'. If there is no A-path the answer is 0 Then try to find another path that does not use the 'A' cells, if there is one the answer is 2, else it's 1. |
|
+3
The two parts of the algorithm have O(K) and O(N/K) complexities but the constant factor will not necessarily be the same (e.g. we do a modulo and use more memory for the small x part and always update K elements, while the naive algorithm for large x just sums N/x values which is only at most N/K... many things to consider). Pushing K on one side or the other of sqrt(N) will increase the time spent on one part and reduce the other, so because of the constant factors the optimal sum of complexities might be for 0.7sqrt(N) or 3.5sqrt(N) or whatever. Here sqrt(N) is 750 but experimentaly i got the lowest execution time with K around 400. Do people really test this in competition though ? Or just guess and round a bit up or down ? |
|
0
|
|
+1
You just forgot the factorial on each degree, but it's that. See my comment above for an explanation http://mirror.codeforces.com/blog/entry/67446?#comment-516861 |
|
+28
First observation is that the solution is valid if and only if each subtree is in consecutive points on the circle. When given a subtree of root $$$i$$$ and a range of points of its size, how many ways to place it ? It has $$$deg(i)-1$$$ subtrees of its own that can be in any order which gives $$$(deg(i)-1)!$$$ and the root can be anywhere between them, $$$(deg(i)-1)+1=deg(i)$$$ possibilities which gives $$$deg(i)!$$$ and the same goes for each subtree independantly. For the root it's almost the same, you have $$$n$$$ positions for the root on the circle and then $$$deg(root)!$$$ for placing the $$$deg(root)$$$ subtrees. |
|
+1
Don't be sorry :-) If the graph is undirected, the edges of a leaf in the DFS tree can only be ancestors : - if an edge were to a previously visited branch, because edges are bidirectionnal then the DFS would have visited our leaf in that previous branch too. - if an edge is to a not-yet-visited branch, then the DFS would visit it from our leaf (which wouldn't be a leaf anymore). |
|
0
You won't necessarily get the spanning tree with largest depth, but the argument works for any tree you'll get that way. (it's possible that sometimes both CYCLES and PATH solutions exist but the argument guarantees that if your dfs tree has depth < n/k then the CYCLE solution works) |
|
0
It's the spanning tree you run through when you do a Depth First Search (DFS) on your graph (the root is the vertex you start with, etc). |
|
+1
You're moving the two pointers i,k in the wrong order : what you're doing is for all k increase i until (i,i+1,k) is valid, then move onto k+1. But it's possible that increasing i further for the same i yields a better result : try "4 1000 1 100 101 200" You need to increase i one by one, and for each i it's true that the largest possible k (as long as e[k]-e[i]<=u) gives the best possible answer for this i. |
|
0
not sure about where is the bug in your code, but it fails on the more simple test : 2 1 2 2 2 (it answers 2 instead of 1) |
|
0
You might have a component larger than one but with one self loop, in that case you do *2 but you should not. |
|
0
That wouldn't work with e.g. 4 5 20 0 3 0 1 0 1 2 0 2 3 0 0 2 5 1 3 5 because you will take the shortest path with the three '0' edges, fix them as 1,1,18, but then there will be a path of length 6 through one of the '5' edges. |
|
0
Don't you have a union find that makes it technically O(nloglogn) or O(n\alpha(n)) ? |
