


| # | User | Rating |
|---|---|---|
| 1 | Benq | 3792 |
| 2 | VivaciousAubergine | 3647 |
| 3 | Kevin114514 | 3603 |
| 4 | jiangly | 3583 |
| 5 | strapple | 3515 |
| 6 | tourist | 3470 |
| 7 | dXqwq | 3436 |
| 8 | Radewoosh | 3415 |
| 9 | Otomachi_Una | 3413 |
| 10 | Um_nik | 3376 |
| # | User | Contrib. |
|---|---|---|
| 1 | Qingyu | 157 |
| 2 | adamant | 152 |
| 3 | Proof_by_QED | 146 |
| 3 | Um_nik | 146 |
| 5 | Dominater069 | 145 |
| 6 | errorgorn | 141 |
| 7 | cry | 139 |
| 8 | YuukiS | 135 |
| 9 | TheScrasse | 134 |
| 10 | chromate00 | 133 |
|
+1
Sorry about that :( TL,DR is that we wanted to do that but company lawyers said otherwise, so we couldn't. We will publish all test data after the round so anyone can solve the tasks for fun and practice. There are already some plans for the next iteration of the contest and AFAIK people at Wincent have actively been looking into both expanding the set of eligible countries and making unofficial participation possible, but for now giving you the test data and solutions after the round is the best we could do. |

|
+3
The qualification round has already been running for ~12 hours and will continue to run for ~36 more. Registration will remain open until the end of the round. |
|
+14
These are hopefully the final versions of English markdown for day 1: day1-markdown.zip |
|
+10
Btw, it seems that calculating determinant when removing any pair of row and column also works. Your proof seems to only work when we remove the same index on the row and column. Is it simple to modify your proof to handle this? This can easily be shown separately. In the Laplacian matrix each row is the negative sum of others. Suppose you took the Laplacian matrix and erased row x and column y, with x != y. You can now do the following:
Now you have the matrix you would have if you had erased row y and column y instead, and the transformations we did to get from there to here only affected the sign of the determinant. Thus, once you have shown that all (x,x)-cofactors of a Laplacian matrix are the same, you can deduce that the absolute values of all (x,y)-cofactors are also the same. |
|
+70
AFAIK, Jessie is working hard behind the scenes to make this exact thing happen: accounts of people who just do algorithm and marathon tracks should eventually be unbanned. (I have no idea about the final shape and form of this, sorry. Specific questions can be sent as messages to Topcoder_Updates.) The original requirement to ban those accounts did indeed come from the "gig work" part — if USA has some embargoes on Russia, having American clients pay Russian freelancers for work via your portal does indeed seem like a legal minefield. And yes, "our" tracks were a casualty. Fingers crossed that our tracks will get back to normal soon -- or at least as close to normal as is currently legally possible. |
|
+1
Here: editorial draft |
|
+3
You are writing an expression for the probability that Alice wins. Whenever you reach a state where she has already won, she wins from that state with probability 1. And whenever you reach a state where she has already lost, she wins from that state with probability 0. That's where the 1 and 0 in this formula come from. |
|
+4
After the challenge phase is over :) Edit: now that it is, here's the draft of the editorial |
|
+13
The list of the 250 people with round 1 byes is here: https://tco22.topcoder.com/competition/algorithm?tracks[algorithm-tabs]=4 (scroll down a little to the "Automatic Berths aka Byes" section) |
|
0
Thanks for the heads-up! The editorial probably got lost somewhere on its way to being published :) Here's the most recent draft of the editorial. It should be added to the published ones soon. |
|
+78
Hey y'all. I understand that this may be upsetting, and I'm sorry that this whole thing had to happen. Let me offer my personal perspective. If the round was only a fun round, it would certainly be better to let the people off with a warning, and that's what we would have done. But as the round does count towards TCO 2022 qualification and the submissions do technically violate the rules of the SRM in which they were submitted, we have to enforce the rules once we are aware of their violation. As we aren't happy with this situation either, I am currently working on a rules update for Topcoder I hope to have in place in the very near future. It should bring the rules to a more sensible modern standard: unused code only matters if loads of it are used for obfuscation, and you may submit anything you are legally allowed to submit (including others' code, as long as it was released under a license that allows you to do it). Hopefully, this will help prevent similar unfortunate situations in the future. (These rules should also be used for the upcoming TCO 2021 online finals. The finalists will be notified about this once it's official.) Note that submitting someone else's code found on the internet is still not necessarily legal, not even here in Codeforces. But, of course, the primary responsibility should be on me and our problem setters to prepare problems such that the only stuff that can reasonably get copied in order to solve a task are standard algorithms from code libraries. |
|
+3
Thanks for the report, we are looking into what may have caused that behavior. The link should currently redirect you to this URL: https://www.topcoder.com/contest/arena/ContestAppletProd.jnlp If you click this link directly, does it download? |
|
+6
It should be published soon. In the meantime, here's the draft, enjoy. |
|
+26
Each move decreases the length of the sequence by 1, so an equivalent task is to maximize the length of the final sequence. And yet another way to look at it is that you are dividing the input sequence into pieces in such a way that the sums of those pieces are non-decreasing and their number is maximized. Given a non-decreasing sequence, let its "width" be the size of the last (biggest) element. If you have two options how to make a non-decreasing sequence out of a prefix of input and the options have equal length, the one with the smaller width is better. This is because anything you can append to a wider sequence, you can also append to a narrower one. The most important observation of the task is the following one: out of all non-decreasing sequences that can be produced from a given sequence, the minimum possible width is always obtained for some sequence that also has the maximum possible length. (Comment if you can't prove this.) Thus, we can do DP on prefixes and for each prefix we just need to remember the length and width of the most narrow out of longest solutions. When processing a new sequence, you are looking for the smallest width it can have -- i.e., the smallest number of pieces in the last element sufficient that the most narrow sequence built from the rest can go before the last piece. There are some ways how to do this in O(n log n), but it's also possible to do it in O(n) by maintaining the feasible candidates in a deque. |
|
0
Thanks, I've tried that at some point but got some weird error. I tried it again now and it works. |
|
0
Are the problems available somewhere? The official page doesn't have them, even though the contest is already over :/ |
|
+19
|
|
0
Yes, I copied the wrong link :D Thanks for the reminder, should be fixed now. |
|
+18
(The proof for the div1 1000 will be added later, as it requires also adding a bit of the background on this type of games and I didn't finish it in time. I'll update this post once it's complete.) |
|
+10
How does your code perform on inputs where we select the same bag 2500 times in a row? E.g., some too-simple formulas can fail those due to division by zero. (If my quick math didn't fail me, a solution that is exactly 98% to solve any single question is about 99.6% to pass one whole 100-question test and about 93% to pass the full systests.) |
|
+14
We will look into this. (My preliminary guess is that for some reason your solution got killed due to exceeding wall clock limit, and the reported time is the processor time used until that point. This is completely unofficial and with no data, just a guess to give you an idea how something like this may occur.) Please email talgorithm@topcoder.com with an official request to look into this so that it doesn't get lost, and we'll get back to you once we know what happened. |
|
+13
Editorial isn't ready yet (IOI, no sleep, etc), so here are some quick solution ideas until then. div2 easy div2 medium div2 hard / div1 easy div1 medium and hard |
|
+75
Apologies for the naming issue. This was originally intended to be a regular SRM, hence the name in the calendar. My work hardware died recently (always a joy) and as a consequence we weren't able to provide a full SRM prepared to the standard we want, so we went with a compromise that at least allows people to solve some problems — as opposed to cancelling the round completely. Given the situation, we didn't have any ideal way of communicating the change. We tried to do what we could (including this post by Harshit). Updating the round name in the public Google calendar is certainly something we should have done, and we'll try to keep it in mind for the future. (Of course, the primary goal is not to have things like this happen at all, but having a better plan for when they do is always a good idea.) Again, sorry to everyone who was affected by the change. |
|
+2
|
|
+24
You got lucky, there are some cases where your solution fails (but not that many). The smallest N where you fail is N=250: you output 3 but there is a solution in which the polygons have 5, 35, 70 and 140 vertices. |
|
+37
Arpa's comment is about test data, he has obviously worked on the problems more in advance. The issue that caused the clarification is about the statement, and I'm the one to (mostly) blame for that omission. I was making the final proofread of the statement and I completely missed that the sentence got lost — most likely while I was making some other edits to the statement. Selective blindness — sometimes you see what you expect to see and not what's there. Your point about making those edits earlier and the implied point about checking everything more carefully are absolutely correct and I apologize if anyone lost time by being confused. |
|
+23
Sorry about that, we were not aware of this problem. I try to keep up to date on as many of the serious contests as I can but my head also has only a finite capacity and I haven't seen this round at all. |
|
+16
|
|
+6
Sorry about that, the bad constraints in the statement are my mistake, I somehow accidentally kept the old version of the constraint section even though it should have been updated when the validator changed. We had to change something because at that point the constraints and the examples section were not consistent. As this was discovered only shortly before the end of the round and testing on the examples should hopefully have caught it for most people, the easiest solution at that point was to keep the test data intact. We did make an announcement that still applies: if you believe that your solution failed only due to R=1 or C=1 tests, we can re-evaluate it. I'll take a look at yours (message me your TC handle please), and if this applies to anyone else please send me a PM here within the next 24 hours. |
|
0
That is correct, there was a clarification announced and the last example was then added as part of that clarification. Those announcements should still be available after you close the popup (In the applet look for a button that says "messages", and IIRC in the web arena there is an envelope icon in the top right corner). |
|
-27
|
|
+20
Note: As the primary goal of this round is to select the top 30 Indian students for the Humblefool Cup finals, the difficulty of the round will be significantly easier than a usual Division 1 SRM. The round is open for everyone, but top contestants will probably find the problems too easy. |
|
+12
Here's a simple version of what I wrote during the contest: simulator Main ideas:
Of course, if you want to run some local optimizations on top of this (which is what we also did), you want to wrap the simulation code into a function and make sure you are correctly initializing everything each time you call it. |
|
+13
You should compare yourself against scores people had after 1 hour Ah yes, and a team of nine mothers can give birth to a child in one month, right? :) I would say that there is no good && simple way to compare a single person to a four-person team in this competition. Some approaches need some time for thinking and implementation, so even if you had a 100-person team, they still wouldn't have them done one hour into the contest. The best comparison they can make is simply to other single-person teams. |
|
+47
For each intersection you do the following: You have a set of N incoming useful streets. You want the traffic lights for this intersection to have a period exactly N, with each street having the green light for 1 second. What remains is to determine which street will get which offset modulo N. When you start the simulation, this hasn't been determined yet — imagine that you only turn on and set each traffic light when you actually need it for the first time. For example, suppose you have an intersection with N = 5. If the first car reaches it at time 42, you will say that its street will have green light at timestamps of the form 5k+2, so this car can now cross without waiting. If the next car comes at 47 using a different street, the car would also want the offset 2 but that one is already taken, so you set this street to be green at 5k+3. The car will wait for one second and then cross. |
|
+40
|
|
+8
At least in the applet the following works. Copy an entire string that looks like this: paste it into the text box where you normally enter one element, and press the {} button. |
|
+1
|
|
+30
|
|
+2
Another O(n^3 log k) solution with the same code used in different order may be conceptually even simpler: The optimal path from U to V can be divided into the first K steps + the rest. Let W be the vertex where you are after exactly K steps in the optimal solution. Then what you did is that you first came optimally from U to W in exactly K steps, and then you used the shortest path to get from W to V. So you just need the K-th power of the given distance matrix + Floyd-Warshall for the shortest paths. For each U, V you can then try all W and pick the best one. |
|
+42
Regrettably, due to some unforeseen circumstances, today's round has been cancelled. We will see you all on Dec 4 @ 11:00 UTC-5 for the next SRM. (The next SRMs in the calendar will just be renumbered, so SRM 794 will take place when SRM 795 was previously scheduled.) Sorry if you already made time and looked forward to the contest. Please join us for the next one! |
|
0
I would be suspicious of the part where you do to_string(long double). Try rewriting that step using integer arithmetic only. (Also note that systests in the practice room will tell you the test case you are failing on.) |
|
+14
It's a fairly standard breadth-first search problem. The thing it wants to teach you is that you don't always have to have cells of the grid = vertices of the graph. Instead, you need to think in terms of states. The factory remains constant, only the two robots move. Thus, at any moment, the entire situation can be described by giving the positions of the two robots. These are the possible states = the vertices of the graph. There are (RC)^2 states. Edges represent all possible actions during the next second. ("If I'm in this state, what states are possible after one second?") |
|
+10
Thanks, glad to hear you enjoyed it :) For people who proved an upper bound on their solution, what is the best one you have? (The best one I actually proved about a solution was <= 1945 jumps but it can definitely be improved.) |
|
+8
Transparency is important, so I'll try to give some comments from our side: First, the round was certainly easier than it ideally should have been. No arguments there. Apologies for not knowing about the similar problems, both me and the round's testers (Lewin and Shef) had no idea about them. Luckily, it looks like the impact is quite small. That being said, I don't think that the difficulty was that low, and I don't think that "before the challenge phase" is a useful metric. From testing we had quite a good idea how tricky the easy can be if people rush it, and many did do that and failed. That's not solving the problem, and should not count as such. If I'm counting correctly, we had 16 people actually solving all three problems which isn't that far from what we were aiming for (which was 10 such people in an ideal world). It's quite hard to accurately set a round that ~10 people will solve fully, especially with our contest time and #problems constraints, there is quite a lot of variance involved. To give you a different perspective, from what I've seen during the round I think we would have hit the desired number if the round was about 5 minutes shorter. Happens. |
|
+16
For one row the number of valid placements of bases into n columns satisfies the recurrence ways[n]=ways[n-1]+ways[n-3], which gives an upper bound of O(1.4656^n), better than Fibonacci. (Bases must be at least 3 apart, so if you place a base into column n, you need to leave the next two free.) In a similar way we can find an even tighter bound for the number of ways to fill two consecutive rows with n columns: O(1.8393^n). Thus, solutions that only construct reachable states and then iterate over all valid ways to fill the next row actually run in O(some polynomial * 2.6957^n). That's quite less than the naive estimate of O(poly * 2^(3n)) = O(poly * 8^n). For n=13, 2.6957^n is roughly 400,000. The task is also solvable in O(poly * 2.3325^n) with a more complicated implementation: when going from one state to another you need to generate only the valid ways of filling the next row given the bases you already placed, instead of going through all ways of filling the row in vacuum and filtering out the ones that create a conflict. |
|
+31
For those lazy to look it up, the 1000-pointer for this round was written by Lewin (lg5293 at Topcoder). |
|
+25
Once the results are official, top 200 will advance. See the diagram from TCO rules |
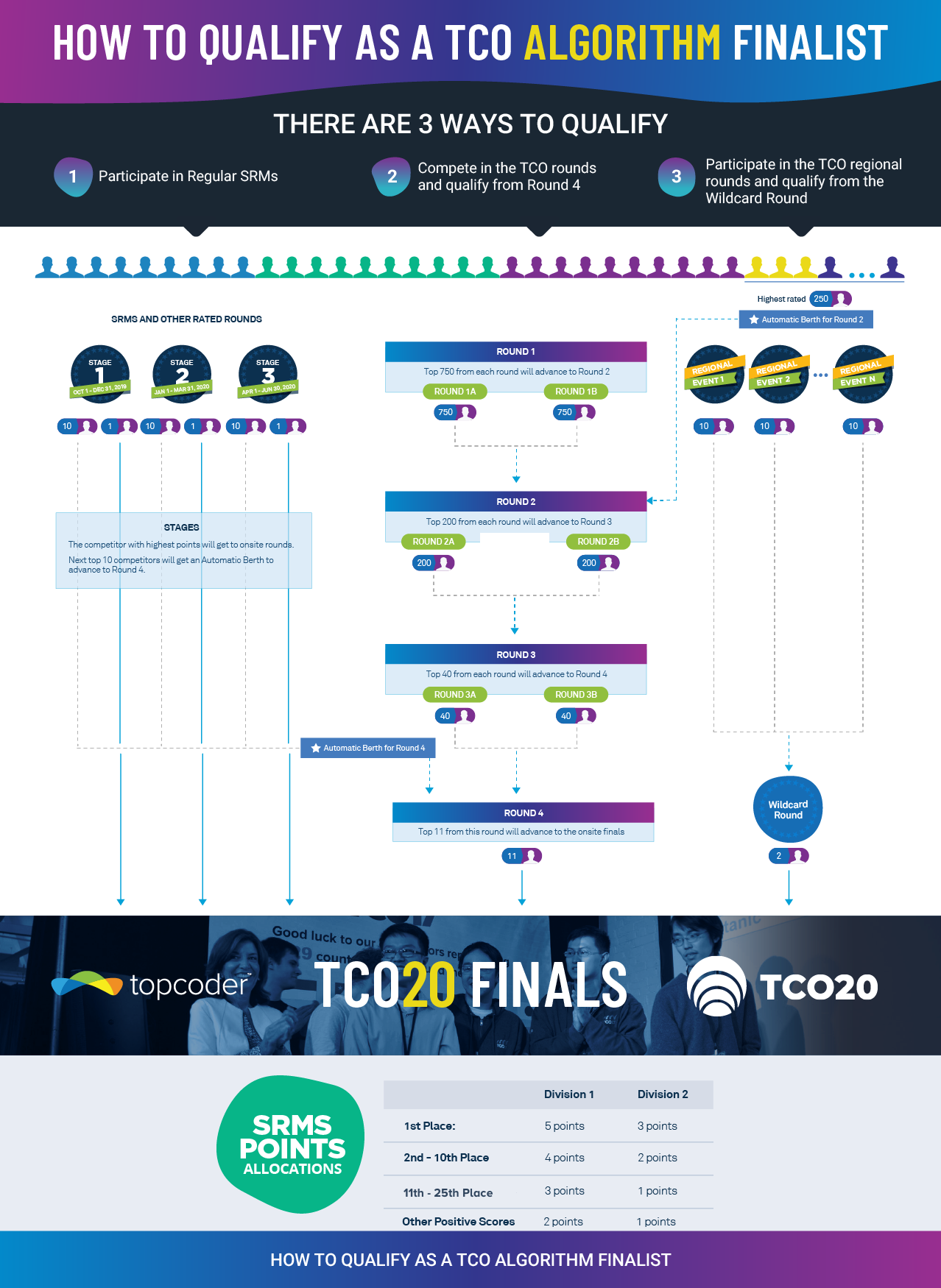{kind=link}
|
0
True. If you make the observation that a lot of swaps = close enough to the uniform distribution, you can do that :) (IIRC, in general you need roughly Theta(n log n) such random swaps to shuffle an array well enough, but I don't remember the exact math behind that at the moment. One should still use the Fisher-Yates shuffle, obviously, but it is fun to know that random swapping can actually converge to the correct distribution rather quickly. Of course, you need to allow swaps that do nothing, otherwise each swap toggles the parity of your permutation.) |
|
+17
Gaussian elimination has a small constant in its time complexity. Solving n equations requires something like n^3/3 multiplications and n^3/3 additions, if I recall correctly. (This is because you are processing smaller and smaller squares of the matrix, and sum(i^2) is roughly n^3/3.) That is something like 125M of each which shouldn't look that scary. Plus, it's cache-friendly. |
|
0
(The same thing aid said but more verbosely:) Imagine starting with N objects of different colors in a row, e.g., (red,green,blue). You can now use DP to simulate all possible swaps at the same time. After each swap, you have a collection of information of the type "the probability that now I have the order (red,blue,green) is 0.15". The main observation of the whole problem is that you just need to do this once, and not once for each starting permutation. This is because if you know that the final probability of going from (red,green,blue) to (red,blue,green) is 0.23, then for any starting permutation P=(p0,p1,p2) the probability of going from (p0,p1,p2) to (p0,p2,p1) is 0.23. |
|
0
Yes, I agree. In retrospect, the medium problem should have been worth more. |
|
+75
AFAIK, they started consistently using the "Case #" part back when you still solved the test cases on your own machine and then submitted the outputs, and (one of) the main reason(s) was that newbies were submitting all kinds of junk instead (programs, binaries, arbitrary numbers). The absence of the case labels in the submitted file was a good heuristic they could use to tell the contestant that they are probably submitting the completely wrong file. As one of my favorite sayings goes, "tradition is when you keep doing something for so long that you forget why" :) |
|
+37
Thanks for your comment (downvotes for providing correct information are sometimes hard to interpret correctly, even though in this particular case I did have a strong suspicion about what the reason might be :p ). I do like the problem, and I'll be glad to explain why. First, these sequences themselves are cool and bringing attention to them using a competitive programming problem is a good thing in my book. Patterns like this one, the more famous Collatz sequence, cellular automata, Busy Beaver Turing machines, Langton's ant, etcetera, etcetera, are scattered all over computer science and they all carry an important message about the world we live in: very small deterministic systems can often produce complex chaotic behavior that is hard to describe. Building up intuition for when this kind of behavior can occur is a useful tool for a computer scientist, and problems like this can contribute to that. Second, the problem itself is perfectly fair. It has exact constraints and within those constraints it is correctly solvable. We do not need to rely upon any unproven results. Third, it's not a new thing in programming contests either. There have been similar problems before. The one I liked most was a problem based on Langton's ant, but I was unable to find it now. I think it was most likely from a Polish (or maybe Russian?) ICPC-style contest. The problem was about having some small initial configuration of a variant of Langton's ant and having to tell its position after 10^18 steps. The core of the problem was that solvers had to either know or discover via simulation that in this particular model the initial chaotic behavior eventually always terminated and turned into periodic one. Problems like that are cool, and I think they absolutely do belong here, even if the underlying mathematical problems about the general case are still unsolved. Fourth, when compared to regular stuff you get at the div1 easy level, the problem is in some sense much closer to what some of us do in actual research. In practice you won't get a nice gift-wrapped toy problem with a solution, you are given a problem to solve and you need to use algorithms as tools to solve it. In this case, the problem was to investigate the behavior of the sequence, make an assumption about said behavior, realize that with a good implementation you have enough resources to verify that assumption using exhaustive search, do so, and submit. Going through this process of thinking and implementing stuff correctly isn't hard, but it isn't trivial either, and div1 easy still seems like an appropriate judgment of the difficulty involved. Wow, that came out longer that expected. Kudos to everyone who actually read this far. TL,DR: I think the problem is OK and I tried to explain why I think so. |
|
+6
Divide the string into blocks of equal letters. You can never erase a block completely, but you can always erase it down to the last one or two characters (based on parity) by using one character from an adjacent block and three from your block. Special case: if all letters are the same, you cannot erase anything. |
|
-17
No, determining whether all integers eventually appear in the sequence is an open problem, even for the case defaultValue = 0. See https://en.wikipedia.org/wiki/Van_Eck%27s_sequence |
|
+69
What's up with the downvotes? Do I now have a personal army of haters for some reason, or is there something actually wrong with what I wrote? |
|
+64
The smallest test case where your code fails is N = 6. The problem is that in the heap with 6 nodes the last layer isn't full yet, but there are already no leaves in the previous layer. Your solution thinks there are still some, and claims that you can have the value 5 in a leaf. |
|
+27
If you want to read without trying to solve, read general resources: textbooks, specific algorithm tutorials and such. Don't waste good problems on this. |
|
+20
|
|
0
You are wrong, this doesn't even work on the examples. The kobolds can block you from accessing parts of the rocks. Remember that the cave must be connected, you cannot just change random '#'s into '.'s. E.g., example 3 is the following: The biggest cave you can make has area=9, even though you have a lot of rocks on the right. |
|
+19
Draft of the editorial: click here |
|
+3
An insight for LandSplitter: Imagine that the land you are dividing is a complete graph on N vertices. The tax you pay when you cut into pieces is equal to the number of edges you cut. Thus, minimizing the total cost is the same as maximizing the number of edges that remain uncut in the end. |
|
+4
Primes are quite dense, so anything reasonable that goes through all possibilities will work. (I.e., iterate over all possibilities of how many digits you add, where you add them and what they are. Stop once you find a prime.) For a short correct solution, special-case N=0 and N=10^9, and for any other input N check the numbers N000 through N999. (The first sequence of 1000+ consecutive numbers occurs only somewhere after 10^15. Our numbers are smaller than 10^12, so there is certainly at least one prime among them. See Prime gap (Wikipedia)) |
|
+1
this was my code: http://ideone.com/1QRGG4 |
|
0
We are investigating the issue, but it's clear that something was wrong on our side, and that people making challenges were affected, because the results of challenges they were getting were not necessarily correct -- e.g., they would have thought that their challenge succeeded even if it should not have, and they would then use the same challenge on other coders. |
|
+64
After discussing the issues with the round we decided that Division 1 will not be rated. We deeply apologize for the issues. |
|
+5
Dijkstra isn't a div1 medium problem. Div1 450 has a linear-time solution and the intention of the author was to let only O(n) solutions pass. Apparently, a few of the O(n log n) solutions managed to fit into the time limit anyway. This was not intended. |
|
-32
Re IMO, I think I have similar expectations as you but I use different words to describe them. I do expect those problems to be uncommon in the sense that I would not have seen that exact problem before, I just expect them to be standard in the sense that I would have seen and used the techniques that work on them before. Or, more precisely, what usually makes these problems easy to me is that the techniques you'll try intuitively will work, and gaining that intuition is precisely thanks to the practice we put in. E.g., you read 2018-4, you see that it's about chess knights, you remember problems about placing many knights onto a chessboard and related invariants, and you apply those to this problem. I guess another part of the problem is that originality is not binary -- problem isn't just "original" or "not original", it's (at least) somewhere on a real-valued scale and different people with different experience will necessarily place it on different places on that scale. I agree with everyone that problems that fall on the "more original" end of the spectrum for most people are the best. I would love to have such IOI and IMO problems every year, I just don't expect that we can realistically have that, and I'm saying that the second best is still not a tragedy if we don't. |
|
-33
I haven't been involved in selecting the problems for this IOI in any way other than raising my country sign along with 70+ other people, so at least in this context "avoiding criticism" makes no sense to me -- I'm not the one being criticized when people dislike that this problem was used. I'm just trying to explain why I personally find the problem OK. Or more precisely: not great, not terrible. I don't understand the obsession with originality at all costs -- given that it's hardly possible nowadays, and it can only get worse. E.g., I also love the task Boxes, but I can easily show you older problems that are easier versions of it in the same sense in which the CF task was an easier version of the IOI task this year. There are literally hundreds of thousands of problems out there, and if you dig enough, you'll find something that uses the same idea -- especially if that idea is easier. Most of the easy IOI problems are similar to other problems that have appeared before. IMHO, on its own this should not be perceived as a bad thing. At the IMO it's common that problems 1 and 4 can be solved using standard techniques, and everybody expects that the well-prepared contestants will easily, quickly and consistently solve them, as they would have seen and solved ten similar problems before. The problems 1 and 4 are there to challenge the lower part of the field, not the crowd fighting for gold. The IOI needs to do the same. In order to be as fair as possible when handing out the medals in the end, the problem set cannot be top-heavy only. If you do that, you would have a clear winner and random noise in the middle of the ranklist. The problem set needs to have parts that discriminate well around each of the medal boundaries. If you are really lucky, someone will contribute an easy ad-hoc problem, but in past years that happened only rarely and going forward such problems will only be more rare. Most of the easy IOI problems will have to look like this one: be based on clever use and modification of standard techniques. This is precisely the type of problems for which everyone who (to use your words) "studied hard enough" will have already seen the technique and they just have to apply it to solve the problem. In my point of view, this is precisely what was going on in the Shoes problem. In particular, I'm convinced that the CF problem gave less advantage to people who solved it than e.g. any of the many problems in which you move stuff to the left of an array and use a Fenwick tree to keep track of it. That implementation is much closer to what they had to write here. |
|
+8
Yes, officially it's the case that your team leader has to submit an appeal. Before dinner we were told to submit these appeals if we have them and didn't submit them before, and there was no strict deadline on this. Get in touch with your leader, you have nothing to lose by doing so. Ideally, send them the exact name and location of the file you want rejudged. (Edit: I would recommend that your leader should send the details to the ISC by email ASAP and to formally file an appeal on paper later, if required.) |
|
0
No, 327 is the number we were told at the meeting after day 1. AFAIK, four of the contestants who were shown in the online results are contestants who were registered for the IOI but did not take part in day 1. The most likely reason is that they are not here and they won't take part in day 2 either, but I don't know for sure whether this is the case. (And in the past there were some cases when some contestants only took part in day 2 for various reasons.) |
|
+6
For the purpose of medal allocation, after day 1 the official number of contestants is 327. (This number cannot go down after day 2, and most likely it should not change.) |
|
-17
Well, if you need to downvote someone to make yourself feel better, feel free to downvote me. I was one of the delegation leaders who voted to keep the problem, and for me this was a conscious decision after thinking about the proposed problem (with the subtasks it had and everything) and feeling that the problem was different enough. The post by eduardische below shows that your "identical to" was far from being correct. I guess the problem you (and on other occasions, many other strong contestants) have is that you are only evaluating the problem from your own point of view. Sure, to you as a contestant the problem may look identical, but that's just because you are too good and you don't realize the difficulty the additional steps bring. In this particular problem, the Codeforces version is just the old "when you are arranging stuff by swapping adjacent elements, don't make unnecessary swaps". I assume that nobody who solved it in the contest spent any time to think about the faster solution, and I'm convinced nobody tried to implement it. And you are also being unfair when you claim that the editorial tells you how to solve the IOI problem. It doesn't. It's just a single sentence that tells you that you have to use an efficient data structure. Well, if you are an average IOI participant, that part is already obvious from the constraints. But while to you it may also be obvious how to use it, it definitely was not obvious to every participant. Plus, the IOI problem brings a bunch of new stuff you have to deal with: What if the leftmost shoe is a right shoe? How exactly should I handle multiple shoes of the same size (both in the idea and in the implementation)? All of these questions are suitable challenges for someone who aims for bronze. From where I'm sitting, the IOI problem is a nice generalization of the CF problem. Solving the CF problem helps a bit, but so does solving any other problem about swaps of adjacent elements, because the only thing it actually gives you is intuition on the greedy strategy. There is enough new that is neither in the CF problem, nor explained by the note in its editorial. Problems that are both easy enough and significantly more original than this one are incredibly rare. |
|
+3
You can do that with any polynomial. The transformation from the vector (...,n^3,n^2,n^1,1) to the vector (...,(n+1)^3,(n+1)^2,(n+1),1) is linear -- i.e., each value in the right vector is a fixed linear combination of the values in the left vector. |
|
0
The medium and hard were written by Errichto. Your time complexity estimate is correct. Essentially, a prefix that is not composite must end with an odd digit, and changing that digit by 1 makes the prefix even and therefore composite. (There are some extra details to handle, as you all know, but this is the main idea of the time complexity argument.) |
|
+3
Details on the environment are now online at https://ceoi.sk/environment/ Requests for additional software can be made by emailing roman.hudec at trojsten.sk in the next few days. |
|
+25
Sorry about that. This was some kind of unintentional scheduling snafu, MikeMirzayanov somehow missed the existence of this TC round when scheduling the CF round, probably because some data wasn't up to date somewhere. We try to look avoid such clashes but sometimes mistakes happen. |
|
0
Please get in touch with hmehta, he can give you the details. |
|
+15
My memory may not be what it used to be, but I'm pretty certain you took part in four IOIs, not three :) |
|
+13
[I]mplementation problems. I know misof likes them too much. Nah :) Implementation itself isn't the part I like. The part I like about such problems is the part where you have to think about how to approach the problem so that it isn't an implementation problem. Recently, the problem AddPeriodic is a nice example of what I like. The problem had a nice simple solution via fractions. The statement was written in such a way that the solution had exactly zero special cases, the constraints were chosen in such a way that with a bit of simple maths you could make sure that plain 64-bit integers won't overflow. It was possible to solve the problem in very few lines of simple code. And, in essence, I see this as another aspect of problem solving: it's still the same "find a more clever way to do it". Problem solving doesn't have to be just about finding the best asymptotic time complexity. |
|
+20
Regarding the technical issues, if you all are frustrated with them, try putting yourselves in my shoes: I can do exactly the same nothing about them as you, but I'm also on the side that is seen responsible for them. Sigh. Regarding correctness of problems, I believe we are maintaining a very high standard with clear statements and correct test data. Human errors such as "both writer and tester missed one check in the validator" do happen from time to time, but such mistakes have been few and far between. Regarding problem quality/"interestingness", well, the way I see it, this is sadly kind of tied to the backend. The current SRM system is outdated and needs to be changed in order to be able to give both tasks that are interesting for the top active participants (i.e., those that are also the most vocal in these forums) and at the same time to also give tasks that make the contests interesting and educational for the lower-rated coders (who are also people with opinions, even if they don't present them here at such rate). With the current setup, those two goals are just plain incompatible, as we've seen. As for implementing changes to the contest format, I was told a year ago about incoming plans to change the backend and whatever else, and it seemed dumb to change stuff before those changes are in place, only to have to change it again a few months later to match the possibilities of the new system. So, that is where we are now -- kinda stuck between a rock and a hard place. I'm reading these forums after each round, I'm hearing the feedback you all have (even at times when I'm too busy to reply), and I'm trying to do my best given the limited options I have. Until we can do something better, there will be some SRMs with interesting hard problems (e.g., Errichto currently has one in the pipeline), and there will also be SRMs that are on the easier side. |
|
+14
Hey :) As far as I know, the two of us didn't actually ever get to discuss this. More precisely, I believe that this is the first time I've ever heard about you making that suggestion, and I wasn't involved in the decision in any way. I'm sorry it turned you away from Topcoder. I would be happy if we could get you to write some problems again, and I can assure you that I care deeply about what I do. If you wish to discuss this issue or anything else in private, don't hesitate to send me a message here at CF or email me. |
|
+39
This seems to be the same issue Errichto described above. We'll have someone look into this. |
|
+40
That sure sounds like something is broken. I'll ping the people who are responsible for the backend to take a look at what's going on. |
|
-26
That's unfair, and you know it. This is nowhere near the same situation. Here you still had to do the correct modeling of the process described in the statement, discard unneeded parts of the polynomials after each multiplication, and reverse directions appropriately. In order to do that, you need to understand what the algorithm actually does instead of just blindly using a black box. |
|
+53
There should have been one, and it's a mistake that there wasn't one. Sorry. |
|
-65
You are not the target group for the problem. People who are now learning the technique are. From time to time, straightforward $technique problems are needed for all techniques, so that other people can learn and practice the stuff you already know. If all the problems on $technique use it in complex ways, it makes learning harder. If you already know it well, the problem should have been straightforward for you to give you more time to try to solve the hard. |
|
+26
The linear solution is the reason to have this problem. I'm sorry its beauty got spoiled by the workarounds needed for the platform. Honestly, I dislike having to do them as much as you all do and I really hope we'll finally get to use a decent backend soon. |
|
+20
One of the best books on teaching programming I've ever read is an old Czech book from 1989 "Martina si hraje s počítačem" (Martina plays with a computer) -- essentially a crossover between a novel and an exercise book that tells a story about how a young girl discovers programming via solving a graduating sequence of tasks set (in secret) by her neighbor, and invites the reader to follow along and solve the same exercises. The book is now horribly outdated, of course, but the core principles are still sound, and resemble your attempts here quite significantly. Professor Hejny (*the* living authority in teaching maths in Czechia and Slovakia nowadays) has had a lot of success with using similar approaches to help ordinary primary school kids learn maths the way it should be done: by discovering it and learning to think instead of just memorizing stuff. But make no mistake: when using this approach, a good teacher is even more important than with the classic lecture-based approach. The selection and/or preparation of good tasks is quite crucial for the approach to work as intended. One important thing I would say you are missing at the moment is interaction with peers. Kids take information from authority in a different way than from their peers. Also, being forced to communicate, explain your ideas, and (very importantly!) resolve conflicts can help your students grow immensely. And excellent materials will, in fact, sometimes intentionally introduce such conflicts as a way to help the students grow. To illustrate with a simple example, imagine showing a bunch of 7-year-olds a picture of three kids standing on a podium for the winners of a race. The one who won has their head highest, but the one who was third is taller. Now you ask the classroom: point to the kid whose height is the largest. And you let them have a disagreement. Let them voice the arguments for each option, and then have them reach a conclusion (or not). This is real maths. They are just (without knowing they do) discovering why in maths exact definitions matter, and that without them you can have all kinds of ambiguities. They are also learning how to communicate and share their ideas in a way in which the others can understand them. Good luck in your future endeavors! :) |
|
+40
Outline (I'm on the phone now): Obviously, optimal strategy is same for both players. If d is max difference, you will never play more than 2d+1 because playing 1 is at least as good for all possible choices of the other player. (This is the main observation you needed.) Then, write linear equations for the 2d+1 probabilities using "principle of indifference", there is a unique solution. (Some more proofs needed to argue correctness.) |
|
+59
There is an optimal solution that uses each Fibonacci number at most once and never uses two consecutive Fibonacci numbers. Proof: Take the lexicographically largest solution. It cannot use two consecutive numbers because such a solution would not be optimal (instead of F_n and F_{n+1} take just F_{n+2}). It cannot use 1 twice because using 2 once is better. It cannot use any bigger Fibonacci number twice because instead of F_n + F_n you can have F_{n+1} + F_{n-2} which gives you a lexicographically bigger solution with the same number of coins. Each number has exactly one representation that uses each Fibonacci number at most once and never uses two consecutive Fibonacci numbers. The greedy algorithm constructs this representation and therefore its output is always optimal. |
|
+8
Everyone with a positive score in one of the Round 3 matches gets a T-shirt (and also everyone who made it past round 3 in a different way). |
|
+5
Top 200 advance (positive score needed, but that shouldn't come up). I've reported the broken link. In the meantime, this works: https://tco19.topcoder.com/algorithm/algorithm-ways |
|
+8
The inputs (atom counts) are guaranteed to be in [1,100]. This does not mean that the outputs (atom weights) have to be in the same range. What happens for the input with molecules (1,99), (2,1), and (1,100) in this order? |
|
0
Hey, sorry I wasn't able to reply to you sooner, I was traveling. In this particular problem there was no intention to time people out. If the first Java reference solution I write runs in 0.6 seconds without any optimizations, I don't expect C++ solutions to have problems with the time limit. It's unlucky that some did. Additionally (and this was something I knew before the round and considered a part of the problem) the total number of states is very small (and, quite intuitively, the number of losing states is very small) so if you happen to time out with a correct idea but an inefficient implementation, it's both easy to realize that this is happening and to precompute the answers locally. This even has a nice algorithmic concept behind it: if you notice that "remove one match" is a valid move, you can precompute everything simply by solving the state (7,7,7,7,7,7,7,7,7) without returning early. |
|
0
Sorry for the delay, the editorial got lost on its way to you. Here's the draft (and please mention me by name to send me a notification if there is a similar issue in the future). |
|
0
FWIW, sorry about the issues with testing in the arena during the round (and especially to HIR180 whose two nice problems were affected by the bug). It turned out that this was a new issue and it was caused by some pesky whitespace that somehow made its way where it didn't belong. Now that we discovered it, it shouldn't reappear in the future. |
|
+36
Unless I'm mistaken, you mean Gray code and not a De Bruijn sequence. At least that's what the technique I have in mind uses: you order all subsets in such a way that each two consecutive subsets only differ by adding or removing one item, which allows you to compute the value for the new subset faster by just updating the value of the old subset. |
|
+23
The round was written by IH19980412. A draft of the editorial can be found here. |
