


2139A — Maple and Multiplication
Idea: installb Preparation: installb,2014CAIS01
If $$$a=b$$$ we need $$$0$$$ steps.
If $$$a$$$ can be divided by $$$b$$$, we only need $$$1$$$ step, which is to multiply $$$b$$$ by $$$\frac{a}{b}$$$. Same for the case when $$$b$$$ can be divided by $$$a$$$.
Otherwise, we need at most $$$2$$$ steps. As both $$$a$$$ and $$$b$$$ are positive integers, we can first multiply $$$a$$$ by $$$b$$$ and then multiply $$$b$$$ by the original value of $$$a$$$. Both number will be equal to $$$a\times b$$$.
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
int solve(){
int a,b;
cin >> a >> b;
if(a == b) return 0;
if(a % b == 0 || b % a == 0) return 1;
return 2;
}
int main(){
ios::sync_with_stdio(false);
int TC;
cin >> TC;
while(TC --){
cout << solve() << '\n';
}
return 0;
}
Idea: installb Preparation: installb
The number of cakes collected from an oven depends only on the last time Maple visits it. Therefore, in the optimal strategy, she should visit distinct ovens in the last $$$\min(m,n)$$$ seconds.
Let's think in reverse: suppose we fix an order $$$p_1,\dots,p_n$$$ of the ovens. Then at second $$$m$$$ we visit oven $$$p_1$$$, at second $$$m-1$$$ we visit oven $$$p_2$$$, and so on. For the $$$i$$$-th oven in this order, we collect $$$a_{p_i}\cdot \max(0, m-i+1)$$$ cakes.
To maximize the total number of cakes collected, ovens with larger $$$a_i$$$ should be visited later (i.e., assigned larger multipliers). Thus we sort $$$a$$$ in non-increasing order first.
The final answer is $$$\sum_{i=1}^n a_i \cdot \max(0, m-i+1)$$$.
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int INF = 0x3f3f3f3f;
void solve(){
int n,t;
cin >> n >> t;
ll ans = 0;
vector <int> a(n);
for(int i = 0;i < n;i ++) cin >> a[i];
sort(a.begin(),a.begin() + n,greater <int>());
for(int i = 0;i < n;i ++) ans += 1ll * a[i] * max(0,t - i);
cout << ans << '\n';
}
int main(){
ios::sync_with_stdio(false);
int TC;
cin >> TC;
while(TC --){
solve();
}
return 0;
}
Idea: wjy666 Preparation: wjy666
You can backtrack from the final state.
Denote the state $$$(a,b)$$$ that indicates Chocola has $$$a$$$ cakes and Vanilla has $$$b$$$ cakes.
After one operation of type $$$1$$$, Vanilla's number of cakes will definitely be at least half of the total, and similarly for operation $$$2$$$. If $$$0 \lt a \lt 2^{k}$$$, then $$$2^{k} \lt b \lt 2^{k+1}$$$, meaning the previous operation must have been type $$$1$$$. Similarly, if $$$0 \lt b \lt 2^{k}$$$, the previous operation must have been type $$$2$$$.
Therefore, you can backtrack from the final state $$$(x,2^{k+1}-x)$$$, until it reaches the initial state $$$(2^k,2^k)$$$.
Now let's analyze how many steps we need to do during the process.
For the state $$$(a, b)$$$, where $$$a, b \neq 0$$$, assume $$$a = i \cdot 2^{p_a}$$$ and $$$b = j \cdot 2^{p_b}$$$, $$$i$$$ and $$$j$$$ are positive odd integers.
Since $$$a + b = 2^{k+1}$$$, it must be true that $$$ 0 \le p_a = p_b \le k$$$ , and after one operation $$$1$$$ or $$$2$$$, both $$$p_a$$$ and $$$p_b$$$ decrease by exactly $$$1$$$.
Therefore, the whole process takes at most $$$k$$$ steps, so we solve the problem with $$$O(tk)$$$ time complexity.
#include <bits/stdc++.h>
using namespace std;
int main(){
int t; cin>>t;
while(t--){
long long k,x,kk; cin>>k>>x; kk=1ll<<k;
if (!x||x==kk*2) {cout<<"-1\n"; continue;}
long long y=kk*2-x;
vector<int> ans; ans.clear();
while(x!=kk){
if (x>y) ans.push_back(2),x-=y,y*=2;
else ans.push_back(1),y-=x,x*=2;
}
cout<<ans.size()<<"\n";
while(!ans.empty()) cout<<ans.back()<<' ',ans.pop_back();
cout<<"\n";
}
return 0;
}
2138B — Antiamuny Wants to Learn Swap
Idea: tarjen Preparation: installb,tarjen,2014CAIS01
For array $$$b$$$, we can prove that $$$f(b)\neq g(b)$$$ if and only if there exists indexes $$$1\le i \lt j \lt k\le m$$$ which satisfies $$$b_i \gt b_j \gt b_k$$$.
Since $$$a$$$ is a permutation, all elements in $$$b$$$ should be distinct. $$$g(b)$$$ is equal to the number of inversions in $$$b$$$. When there exists some index $$$i$$$ that satisfies $$$a_i \gt a_{i+1} \gt a_{i+2}$$$, we can reduce the number of inversions by $$$3$$$ by applying operation $$$2$$$, allowing $$$f(b)$$$ to become less than $$$g(b)$$$. This is the only case where you can reduce more than $$$1$$$ inversion with one operation.
If there exists indexes $$$1\le i \lt j \lt k\le m$$$ which satisfies $$$b_i \gt b_j \gt b_k$$$. We can first choose index $$$i,k$$$, then move all elements greater than $$$b_i$$$ to the right of $$$b_k$$$ and move all elements less than $$$b_k$$$ to the left of $$$b_i$$$ by swapping adjacent numbers (applying the first operation). Now all elements $$$b_p$$$ between $$$b_i,b_k$$$ satisfy $$$b_i \gt b_p \gt b_k$$$. We then swap them to the left of $$$b_i$$$ until there is only one element $$$b_j$$$ left. Now $$$b_i \gt b_j \gt b_k$$$ and they are adjacent, and we can apply operation $$$2$$$ on the current index of $$$b_i$$$.
If we only apply operation 1 on indexes $$$i$$$ which satisfy $$$b_i \gt b_{i+1}$$$, there will never exist any index $$$i$$$ satisfying $$$b_i \gt b_{i+1} \gt b_{i+2}$$$ in $$$b$$$ during the process. If we apply an operation $$$1$$$ on some index $$$i$$$ where $$$b_i \lt b_{i+1}$$$, the number of inversions will be increased by $$$1$$$ instead of decreased by $$$1$$$, which makes it impossible to reach $$$f(b) \lt g(b)$$$ with one operation $$$2$$$, even i it decreases number of inversions by $$$3$$$. Therefore, in this case $$$f(b)=g(b)$$$.
For each element $$$a_i$$$, we define:
- $$$l_i$$$: the maximum index $$$ \lt i$$$ such that $$$a_{l_i} \gt a_i$$$,
- $$$r_i$$$: the minimum index $$$ \gt i$$$ such that $$$a_{r_i} \lt a_i$$$.
Then the answer to a query $$$[l, r]$$$ is $$$\texttt{NO}$$$ if and only if some segment $$$[l_i, r_i]$$$ lies fully inside $$$[l, r]$$$.
To answer multiple queries, you can preprocess the smallest $$$r$$$ for every $$$l$$$ such that the answers for all $$$[l,x](x\ge r)$$$ should be $$$\texttt{NO}$$$.
The time complexity is $$$O(n)$$$ if you find $$$l_i,r_i$$$ with the Monotonic Stack trick. $$$O(n\log n)$$$ solutions can also pass.
#include <bits/stdc++.h>
using namespace std;
void solve()
{
int n, q;
cin >> n >> q;
vector<int> a(n + 2);
for (int i = 1; i <= n; i++)
{
cin >> a[i];
}
vector<int> mxl(n + 1), mir(n + 1);
for (int i = 1; i <= n; i++)
{
mxl[i] = i - 1;
while (mxl[i] > 0 && a[mxl[i]] < a[i])
mxl[i] = mxl[mxl[i]];
}
for (int i = n; i >= 1; i--)
{
mir[i] = i + 1;
while (mir[i] <= n && a[mir[i]] > a[i])
mir[i] = mir[mir[i]];
}
vector<int> L(n + 1, 0);
for (int i = 2; i < n; i++)
{
if (mxl[i] > 0 && mir[i] <= n)
{
L[mir[i]] = max(L[mir[i]], mxl[i]);
}
}
for (int i = 1; i <= n; i++)
{
L[i] = max(L[i], L[i - 1]);
}
for (int i = 0; i < q; i++)
{
int l, r;
cin >> l >> r;
if (l <= L[r])
cout << "NO\n";
else
cout << "YES\n";
}
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);
int T;
cin >> T;
while (T--)
{
solve();
}
}
2138C1 — Maple and Tree Beauty (Easy Version)
2138C2 — Maple and Tree Beauty (Hard Version)
Idea: installb Preparation: installb,tarjen,2014CAIS01
2139D — Antiamuny and Slider Movement
Idea: tarjen,StarSilk Preparation: installb,tarjen,StarSilk
Let’s define $$$b_i$$$ as the position of the $$$i$$$-th slider decreased by $$$i$$$. Every operation on the sliders can be interpreted as a modification of the array $$$b$$$.
If we increase the position of slider $$$i$$$, then $$$b_i$$$ increases. At the same time, every suffix element $$$b_{i+1}, b_{i+2}, \dots, b_n$$$ gets updated to $$$b_j := \max(b_j, b_i)$$$.
If we decrease the position of slider $$$i$$$, then $$$b_i$$$ decreases. At the same time, every prefix element $$$b_1, b_2, \dots, b_{i-1}$$$ gets updated to $$$b_j := \min(b_j, b_i)$$$.
Since the array $$$b$$$ always remains non-decreasing, we can reinterpret operations as follows:
- Every operation simultaneously applies a $$$\min$$$ operation to all elements on the left, and a $$$\max$$$ operation to all elements on the right.
For a fixed slider $$$b_i$$$, the effect of each operation on the slider should be one of the following:
- $$$b_i := \max(b_i, x)$$$
- $$$b_i := \min(b_i, x)$$$
- $$$b_i := x$$$ (assignment)
Our task is to compute the sum of final values of $$$b_i$$$ after all possible sequences of operations.
We sort all operations by their parameter $$$x$$$. If multiple operations share the same $$$x$$$, we give them a consistent order and then assume all $$$x$$$ are distinct in the following part of the editorial.
We first suppose that the position of the slider is changed at least once. Suppose the final value for slider $$$i$$$ is $$$b_e$$$, let’s consider which operation sets $$$b_i = b_e$$$ at the very end.
At this point, we no longer care about the exact value of $$$b_i$$$ during the process — only whether it is less than, equal to, or greater than $$$b_e$$$.
All operations of type $$$\max$$$ with $$$x \lt b_e$$$ and type $$$\min$$$ with $$$x \gt b_e$$$ are irrelevant. We can insert them anywhere after deciding the order of other operations without affecting the result. We won't consider these operations in the following parts of the editorial.
All assignment operations b := x can be reinterpreted:
- If $$$x \lt b_e$$$, treat it as
min(x). - If $$$x \gt b_e$$$, treat it as
max(x).
The last operation, that makes $$$b_i = b_e$$$ must be the one with parameter $$$x = b_e$$$.
If this operation is assignment, then all other operations can appear in any order.
If this operation is $$$\max$$$ type, then immediately before it we must have $$$b_i \lt b_e$$$.
-
- Either the last preceding valid operation is some $$$\min$$$ type operation making $$$b_i \lt b_e$$$;
-
- Or no other effective operation occurs, and the initial value of $$$b_i$$$ was already smaller than $$$b_e$$$.
If this operation is
min(x), it is symmetric: either the last preceding valid operation is a $$$\max$$$ type operation, or the initial value of $$$b_i$$$ was already larger than $$$b_e$$$.
Finally, don’t forget the case where a slider is never touched, where it simply keeps its initial value.
For each of the $$$n$$$ sliders, we need to check contributions over all $$$m$$$ operations. The overall time complexity is $$$O(nm)$$$.
#include<bits/stdc++.h>
using namespace std;
const long long mod=1000000007;
long long a[5000],ans[5000],tt[5001],inv[5001];
struct apos{
long long id;
long long x;
friend bool operator<(apos a,apos b){
return a.x<b.x;
}
}ap[5000];
int main(){
ios::sync_with_stdio(false),cin.tie(0);
int T,flag;
long long n,m,p,q,x,i,j,cl,cr;
tt[0]=1;
for(i=1;i<=5000;i++)tt[i]=tt[i-1]*i%mod;
inv[1]=1;
for(i=2;i<=5000;i++)inv[i]=(mod-mod/i)*inv[mod%i]%mod;
for(cin>>T;T>0;T--)
{
cin>>n>>m>>p;
for(i=0;i<n;i++)
{
cin>>a[i];
a[i]-=i;
}
for(i=0;i<p;i++)
{
cin>>ap[i].id>>ap[i].x;
ap[i].id--;
ap[i].x-=ap[i].id;
}
sort(ap,ap+p);
for(i=0;i<n;i++)
{
flag=0;
for(j=0;j<p;j++)
{
if(ap[j].id<=i&&ap[j].x>=a[i])flag=1;
if(ap[j].id>=i&&ap[j].x<a[i])flag=1;
}
if(!flag)
{
ans[i]=a[i]+i;
continue;
}
ans[i]=0;
cl=0;
cr=0;
for(j=0;j<p;j++)
{
if(ap[j].id<=i)cr++;
}
for(j=0;j<p;j++)
{
if(ap[j].id<=i)cr--;
if(ap[j].id==i)ans[i]=(ans[i]+(ap[j].x+i)*inv[cl+cr+1])%mod;
if(ap[j].id<i)
{
if(cl==0&&cr==0&&a[i]<=ap[j].x)ans[i]=(ans[i]+ap[j].x+i)%mod;
else ans[i]=(ans[i]+(ap[j].x+i)*inv[cl+cr+1]%mod*inv[cl+cr]%mod*cl)%mod;
}
if(ap[j].id>i)
{
if(cl==0&&cr==0&&a[i]>ap[j].x)ans[i]=(ans[i]+ap[j].x+i)%mod;
else ans[i]=(ans[i]+(ap[j].x+i)*inv[cl+cr+1]%mod*inv[cl+cr]%mod*cr)%mod;
}
if(ap[j].id>=i)cl++;
}
}
for(int x = 0;x < n;x ++)
{
cout<<ans[x]*tt[p]%mod<<' ';
}
cout<<'\n';
}
return 0;
}
2139E1 — Determinant Construction (Easy Version)
Idea: wjy666 Preparation: wjy666
Thanks to jqdai0815 for his significant contribution to this solution.
We can consider transforming the construction of a matrix into the construction of a directed graph, as the determinant and permutations are closely related to the cycle covers of a directed graph.
If we have a directed graph with $$$n$$$ vertices, a cycle cover is a set of $$$n$$$ edges such that each vertex has exactly one incoming edge and one outgoing edge in this set (self-loops are allowed). In other words, these $$$n$$$ edges form one or more cycles that together cover all vertices in the graph.
In a complete directed graph (with self-loops), every permutation of the vertices determines a cycle cover and vice versa. (The cycles of the permutation are precisely the cycles in the cover.)
We consider the definition of the determinant:
This summation goes over all permutations $$$B$$$, in other words, over all cycle covers of the directed graph determined by the adjacency matrix $$$M$$$. We can also interpret $$$m_{i,j}=0$$$ as "the edge from $$$i$$$ to $$$j$$$ does not exist at all". Thus, the product term $$$\prod_{i=0}^{n-1}m_ {i,b_{i}}$$$ is non-zero only if all $$$m_ {i,b_{i}} \neq 0$$$, which corresponds to the existence of a cycle cover in the graph.
We want to construct a directed graph such that the sum of the weights of its cycle covers equals $$$x$$$. Since the current problem only allows the use of $$$-1, 0, 1$$$, the edge weights can only be $$$1$$$ or $$$-1$$$, and the contribution of a valid cycle cover to the answer can only be $$$1$$$ or $$$-1$$$.
PS: You can refer to pages 56-58 of https://ipsc.ksp.sk/2012/real/solutions/booklet.pdf for more information.
There might be many ways to construct a legal directed graph. We will demonstrate a method that transforms the problem into constructing a DAG with exactly $$$x$$$ paths from source vertex $$$1$$$ to sink vertex $$$n$$$.
For a directed acyclic graph $$$G$$$ with source vertex $$$1$$$ and sink vertex $$$n$$$, we can construct the following adjacency matrix:
- $$$g_{i,j} = -1$$$ if there is an edge $$$i \rightarrow j$$$ in $$$G$$$. Set the weight of all original edges in $$$G$$$ to $$$-1$$$.
- $$$g_{i,i} = 1$$$ for all $$$1 \lt i \lt n$$$. Add a self-loop with weight $$$1$$$ to all vertices in $$$G$$$ except the source and sink.
- $$$g_{n,1} = 1$$$. Add an edge from the sink to the source with weight $$$1$$$.
- Everything else $$$= 0$$$.
We analyze all cycle covers of this new graph. Due to the presence of the edge $$$n \rightarrow 1$$$ , any cycle cover must contain a main cycle that includes nodes $$$1$$$ and $$$n$$$, formed by a path $$$P$$$ from $$$1$$$ to $$$n$$$ in $$$G$$$ and the edge $$$n \rightarrow 1$$$. For nodes not on path $$$P$$$ (i.e., intermediate nodes not covered by path $$$P$$$), they must be covered by self-loops with weight $$$1$$$. Therefore, each cycle cover uniquely corresponds to a path $$$P$$$ from $$$1$$$ to $$$n$$$.
Since there are $$$x$$$ paths in $$$G$$$, we only need to ensure that the contribution of each cycle cover is $$$1$$$ to obtain a determinant value of $$$x$$$. Next, we will analyze how to achieve this by setting the weight of all original edges in $$$G$$$ to $$$-1$$$.
For each cycle cover, first consider the product of all edge weights:
- The main cycle has $$$k$$$ edges, among which $$$k-1$$$ edges come from path $$$P$$$ (each with weight $$$-1$$$), and one edge is $$$n \rightarrow 1$$$ (with weight $$$1$$$). Thus, the product term is $$$(-1)^{k-1}$$$.
- The weights of all other self-loops are $$$1$$$.
Therefore, the product of all edge weights is $$$(-1)^{k-1}$$$.
Then we consider the sign term $$$(-1)^{\mathrm{inv}(B)}$$$. In fact, the parity of the number of inversions $$$\mathrm{inv}(B)$$$ in the permutation is consistent with the parity of the number of even cycles in the permutation. The main cycle is a cycle of length $$$k$$$, and the self-loops are all cycles of length $$$1$$$. Therefore, the sign term is $$$(-1)^{k-1}$$$.
Thus, the contribution of each cycle cover is $$$(-1)^{k-1} \cdot (-1)^{k-1}=1$$$.
Due to the constraints in the problem that the matrix size is at most $$$80$$$ and there are at most $$$3$$$ non-zero entries per row and column, we need to construct a DAG that satisfies:
- Exactly $$$x$$$ paths from source vertex $$$1$$$ to sink vertex $$$n$$$.
- At most $$$80$$$ nodes.
- The in-degree of each node $$$\le 2$$$ and the out-degree of each node $$$\le 2$$$.
Since $$$80$$$ is a loose boundary, there might be many constructions that satisfy it. We will introduce a construction method that encodes $$$x$$$ in base three.
The basic unit shown in the figure can form a base-three digit because the number of paths from $$$1$$$ to $$$3$$$ is $$$2$$$, and from $$$1$$$ to $$$4$$$ is $$$3$$$. Node $$$4$$$ can be connected to the next unit, forming a chain of units, where each unit corresponds to a base-three digit. Nodes $$$3$$$ and $$$4$$$ have one free out-degree, which can contribute to the final answer.
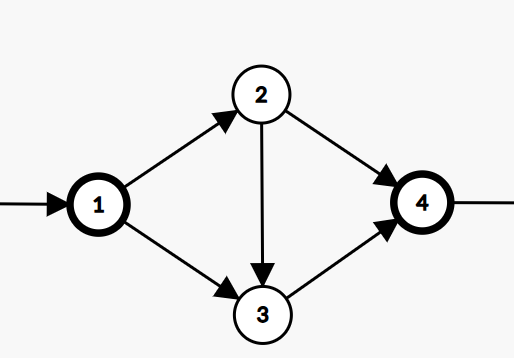
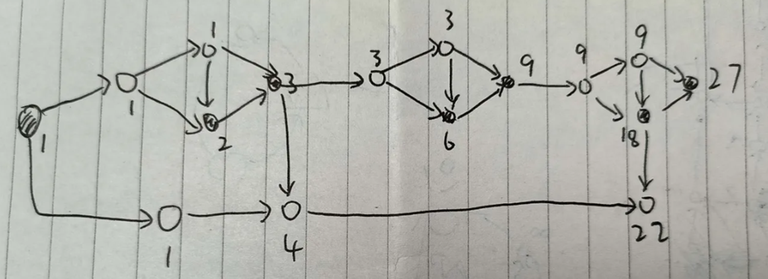
The example figure below shows how to construct $$$22=1+3+2 \cdot 3^2$$$ in this way. There are $$$\log_3 n$$$ basic units, each with $$$4$$$ nodes. The answer chain has at most $$$\log_3 n$$$ nodes. Therefore, the total number of nodes is $$$5\log_3 n + O(1)$$$, which can pass the problem.
We can consider using Tridiagonal Matrices, where the advantage lies in transforming the calculation of the determinant value into a recursive formula.
Let $$$d_{i,j}$$$ denote the element in the i-th row and j-th column of matrix $$$D$$$, $$$D_k$$$ represents the submatrix composed of the upper-left $$$k \times k$$$ elements, and $$$A_k$$$ denotes the determinant value of $$$D_k$$$.
When $$$k \ge 2$$$, there are two ways to obtain $$$D_{k+1}$$$ from $$$D_k$$$:
- Let $$$ d_{k+1,k+1}=1, d_{k+1,k}=1,d_{k,k+1}=1$$$ to get $$$A_{k+1}=A_k-A_{k-1}$$$
- Let $$$ d_{k+1,k+1}=1, d_{k+1,k}=1,d_{k,k+1}=-1$$$ to get $$$A_{k+1}=A_k+A_{k-1}$$$
Thus, we transform the problem into constructing a sequence $$$A_1,\ldots,A_m$$$ satisfying:
- $$$A_1 = |D_1|, A_2 = |D_2|$$$
- For any $$$k=2,3,\ldots,m-1$$$, one of the following two equations holds: $$$A_{k+1}=A_k-A_{k-1}$$$, or $$$A_{k+1}=A_k+A_{k-1}$$$
- $$$A_m=n (m \le 80)$$$
Consider recursively generating the entire sequence from $$$A_m=n$$$ backwards.
Choose a positive integer as $$$A_{m−1}$$$.
At a certain moment, we have $$$A_k$$$ and $$$A_{k+1}$$$, and obtain $$$A_{k−1}$$$ as follows:
If $$$A_k \gt A_{k+1}$$$, let $$$A_{k-1}=A_k-A_{k+1}$$$; otherwise, let $$$A_{k-1}=A_{k+1}-A_k$$$
This ensures that each number in the sequence is a non-negative integer.
If at some point there exist $$$D_1,D_2$$$ satisfying $$$A_k = |D_1|, A_{k+1} = |D_2|$$$, successfully finish the construction.
For example,if we have $$$A_m=7$$$ and $$$A_{m−1}=3$$$, the final sequence will be $$$1,2,3,1,4,3,7$$$, and we will generate the matrix as
Denote $$$(A_k,A_{k+1})=(x,y)$$$.
When $$$x \gt y$$$, the recursion process can be written as $$$(x,y) \rightarrow (x-y,x) \rightarrow (y,x-y)$$$, increasing the length of the sequence by $$$2$$$, completing one iteration of subtraction.
When $$$x \le y$$$, the recursion process can be written as $$$(x,y) \rightarrow (y-x,x)$$$, increasing the length of the sequence by $$$1$$$, completing one iteration of subtraction.
The process will eventually lead to $$$(x,0)$$$ or $$$(0,x)$$$, where $$$x$$$ is the GCD of $$$A_m$$$ and $$$A_{m−1}$$$.
When $$$A_m$$$ and $$$A_{m−1}$$$ are coprime, we have $$$x=1$$$, meeting the requirements for the sequence. In fact, we can stop earlier when $$$(1,2)$$$, and the sequence is still legal.
When $$$A_m$$$ and $$$A_{m−1}$$$ are not coprime, we have $$$x \gt 1$$$, and this method can't obtain a sequence that meets the requirements.
Given $$$A_m=n$$$, we need to find a suitable $$$A_{m−1}$$$ such that the length of the final sequence is less than or equal to $$$80$$$.
Since $$$80$$$ is a relaxed constraint, and you only need to find one valid $$$A_{m−1}$$$, you can try various approaches.
For example, you could enumerate all possibilities within the range $$$[1, n-1]$$$ for some large $$$n$$$, and then discover that there are many valid $$$A_{m−1}$$$ values that meet the criteria.
If you randomly search for $$$A_{m−1}$$$ within the range, the expected number of attempts required is very low. In fact, the verification program tested all integers $$$n$$$ from $$$10$$$ to $$$10^7$$$, randomly selecting $$$1000$$$ possible $$$A_{m−1}$$$ values for each n and testing them. The results showed that in the worst case (when $$$n = 9827370$$$), there were still $$$24$$$ valid $$$A_{m−1}$$$ values that met the requirements out of the $$$1000$$$ randomly chosen values.
#pragma GCC optimize(3)
#include<bits/stdc++.h>
using namespace std;
int fl[1005],inf=1e9,cnt;
int work(int x,int y){
int ans=0,tmp;
while(y&&ans<=80){
++ans; tmp=y;
if (x>y) y=x-y; else y=y-x;
x=tmp;
}
if (x>1) return inf;
return ans;
}
void gen(int x,int y){
//printf("%d\n",work(x,y));
vector<int> seq; seq.clear(); seq.push_back(x); seq.push_back(y);
int tmp;
while(!(x==2&&y==1)){
tmp=y;
if (x>y) y=x-y; else y=y-x;//x=tmp;
x=tmp;
seq.push_back(y);
}
int ans[105][105]={0};
int pre=seq.back(),n=1; seq.pop_back(); ans[1][1]=1;
while(!seq.empty()){
++n;
if (seq.back()>pre) ans[n][n]=1,ans[n][n-1]=1,ans[n-1][n]=-1;
else ans[n][n]=1,ans[n][n-1]=1,ans[n-1][n]=1;
pre=seq.back(); seq.pop_back();
}
//
for (int r = n+1; r <= 80; r++) ans[r][r]=1; n=80;
//
printf("%d\n",n);
for(int i=1;i<=n;++i){
for(int j=1;j<=n;++j){
printf("%d ",ans[i][j]);
}
printf("\n");
}
}
int main(){
int _; cin>>_; random_device rd;
while(_--){
int n; cin>>n;
if (n==0) {printf("1\n0\n"); continue;}
if (n==1) {printf("1\n1\n"); continue;}
while(1){
int y=rd()%(n-1)+1;
int tmp=work(n,y);
if (n<=5000000){
if (tmp<=80) {gen(n,y); break;}
}
else{
if (tmp>=77&&tmp<=80) {gen(n,y); break;}
}
}
}
return 0;
}
Verification Program:
2139E2 — Determinant Construction (Hard Version)
Idea: wjy666 Preparation: wjy666
Since $$$50$$$ is a very tight constraint, the author did not find a method to construct the DAG for G2 as in Solution 1 of G1. If you have a better solution, please leave a comment below.
In Solution 2, the first two steps remain consistent with G1, but we need a better method to find a suitable $$$A_{m−1}$$$ such that the length of the final sequence is less than or equal to $$$50$$$. Randomly searching for $$$A_{m−1}$$$ within the range $$$[1, n-1]$$$ may result in TLE.
We noticed that if $$$A_{m−1}$$$ and $$$A_m$$$ are two adjacent fibonacci numbers, the sequence will converge rapidly (with a length within $$$40$$$). Although not all $$$A_m=n$$$ are fibonacci numbers, we can still draw inspiration from this.
We attempt to decompose $$$n$$$ as $$$n=a \cdot \operatorname{fib}(i)+b \cdot \operatorname{fib}(i-1), a,b \ge 0$$$, where $$$\operatorname{fib}(i)$$$ denotes the $$$i$$$-th fibonacci number.
Then, we set $$$A_{m-1}=a \cdot \operatorname{fib}(i-1)+b \cdot \operatorname{fib}(i-2)$$$
By iterating further, we obtain $$$A_{m-2}=a \cdot \operatorname{fib}(i-2)+b \cdot \operatorname{fib}(i-3)$$$, $$$\dots$$$
The purpose of this is to make the iteration process rapidly decrease the value in the initial steps, similar to the fibonacci sequence. Intuitively, the larger the $$$i$$$ chosen, the higher the probability of finding a legal $$$A_{m-1}$$$.
The author did not provide a rigorous mathematical proof for this, but using a verification program which found a legal $$$A_{m-1}$$$ for all $$$A_m=n \in [2,10^7]$$$ within one minute. Therefore, it is feasible to prove the correctness of this approach within the data range during the contest.
We note that for the fibonacci sequence, $$$\lim_{x \to \infty} \frac{\operatorname{fib}(x-1)}{\operatorname{fib}(x)} = \frac{\sqrt 5 -1}{2}$$$, which suggests that searching for $$$A_{m-1}$$$ around $$$\frac{\sqrt 5 -1}{2}n$$$ might be a promising approach.
In fact, directly enumerating $$$A_{m-1}$$$ starting from $$$\frac{\sqrt 5 -1}{2}n$$$ and trying each one is a efficient method. The author also verified through a verification program that for all $$$A_m=n \in [2,10^7]$$$, a legal $$$A_{m-1}$$$ was found within one minute. Thus, it is feasible to prove the correctness of this approach within the data range during the contest.
Considering that the time limit for this problem is relatively loose (5s), most attempts to search for $$$A_{m-1}$$$ around $$$\frac{\sqrt 5 -1}{2}n$$$ may be able to pass.
cpp
2139F — Ode to the Bridge Builder
Idea: installb Preparation: installb
For convenience, we mark the targets point and the points on the initial segment with $$$A(0,0),B(1,0),C(p,q)$$$.
The problem asks us to do at most $$$\left\lceil 2|AC|\right\rceil$$$ moves. This constraint is actually not quite usual. We can first show that the theoretical lower bound should be $$$x=\left\lceil |AC|\right\rceil+\left\lceil |BC|\right\rceil−1$$$. We can show we can't get less moves by following: If we have already constructed the final structure, then $$$AC$$$ and $$$BC$$$ should be connected with a path, and we can find a path from $$$A$$$ to $$$C$$$ and a path from $$$B$$$ to $$$C$$$ that don't intersect (except at point $$$C$$$), otherwise the structure can't be built with non-degenerate triangles.
And we have to alternate progressing through two paths every time we construct a triangle, otherwise we must draw a line longer than $$$1$$$. The last triangle will cover both paths, so the number of steps will be decreased by one. The optimal path is two straight segments (which is not always possible).
Case 1.1: We first try some simple strategies. Two triangles can form a parallelogram, so we can connect $$$AC$$$, choose a point $$$D$$$ on $$$AC$$$ which makes $$$|AD|=\frac{|AC|}{\lceil|AC|\rceil}$$$, which is always in range $$$[0.5,1]$$$ when $$$|AC|\ge 1$$$. And from $$$\triangle ADB$$$ we can construct a parallelogram. We draw a line passing $$$D$$$ that is parallel to $$$AB$$$, a line passing $$$B$$$ that is parallel to $$$AC$$$, and they intersects at $$$E$$$. Then we pile up the same parallelogram structure until we reach $$$C$$$. This always works when $$$30^\circ\le\angle CAB\le60^\circ$$$.
Proof: We first prove that all segments has length between $$$0.5$$$ and $$$1$$$. Because we stack the same parallelogram structure, all segments have length equal to $$$AB,BD$$$ or $$$AD$$$. $$$AB$$$ and $$$AD$$$ already meets the requirement. When $$$30^\circ\le\angle CAB\le60^\circ$$$, the length of $$$BD$$$ is at least $$$0.5$$$ as the distance between two parallel lines is at least $$$0.5$$$, and at most $$$1$$$ as $$$AB=1$$$ and $$$\angle CAB$$$ is never the largest angle in $$$\triangle DAB$$$. We can calculate that the number of moves we used is $$$2\left\lceil |AC|\right\rceil-1\le\left\lceil 2|AC|\right\rceil$$$ which matches the requirement (for the last parallelogram we only need one triangle).
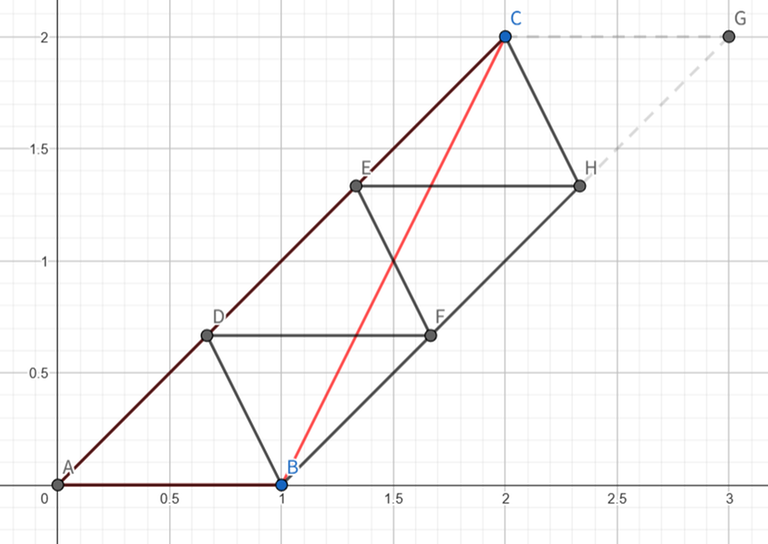
Case 1.2: We can change the way we construct parallelograms (with sides $$$AB,BC$$$) and this method always works when $$$30^\circ\le\angle CBx\le60^\circ$$$. The number of moves is $$$\left\lceil2|BC|\right\rceil\le \left\lceil 2|AC|\right\rceil$$$. This case is actually necessary, which will be explained in the following part.
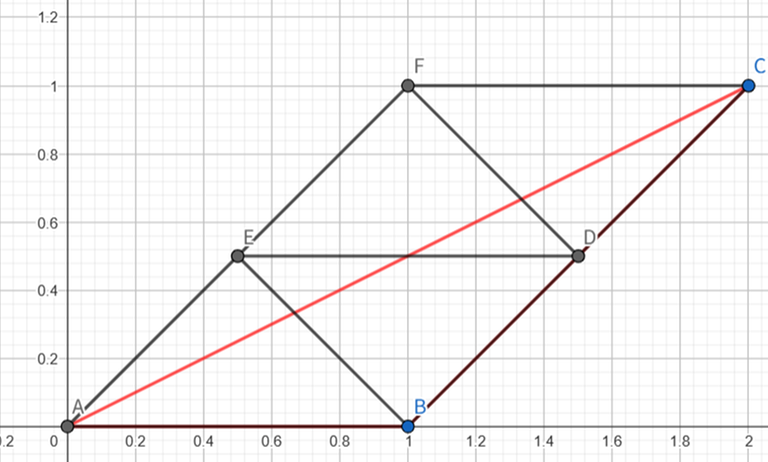
Case 2: If $$$\angle CAB \lt \angle CBx \lt 30^\circ$$$. We first build a point $$$D$$$ which makes $$$AD=1$$$ and $$$\angle DAB=30^\circ$$$ and construct $$$\triangle DAB$$$.
We can show that the constraint is actually easier to meet in this situation, because when $$$\angle CAB \lt \angle CBx \lt 30^\circ$$$, $$$|BC| \lt |AC|-0.5$$$. With this, $$$\left\lceil |AC|\right\rceil+\left\lceil |BC|\right\rceil−1=\left\lceil 2|AC|\right\rceil-1$$$ always holds, allowing us one extra move.
Then we draw a line passing $$$D$$$ parallel to $$$BC$$$. We can show that if $$$\angle DAB=30^\circ$$$ and $$$0\le \angle CAB\le 30^\circ$$$, the distance from $$$D$$$ to line $$$BC$$$ is at least $$$0.5$$$. So all segments with ends on different lines will have length $$$\ge 0.5$$$.
Then we select a point $$$E$$$ on $$$BC$$$, which makes $$$DE=1$$$. We can show that $$$\sqrt{3}-1\le |BE|\le 1$$$ based on some calculations in this case. Then we do a similar parallelogram construction process to $$$C$$$. The total number of moves is $$$2\left\lceil |CE|\right\rceil+2$$$.
There are still two cases here to analyze to prove the number of steps fulfills our requirement. We write $$$|BC|=a+b$$$ where $$$a$$$ is the integer part of $$$|BC|$$$, then we analyze cases about $$$b$$$.
Case 2.1: When $$$b\ge\sqrt{3}-1$$$ or $$$b=0$$$, we can show that $$$2\left\lceil |AC|\right\rceil=\left\lceil 2|AC|\right\rceil$$$, and $$$\left\lceil |AC|\right\rceil=\left\lceil |BC|\right\rceil+1$$$ if $$$|AC|\ge 2$$$. The number of steps is $$$2\left\lceil |EC|\right\rceil+2\le 2\left\lceil |BC|\right\rceil+2=2\left\lceil |AC|\right\rceil$$$.
Case 2.2: When $$$0 \lt b \lt \sqrt{3}-1$$$, we can show that $$$\left\lceil |EC|\right\rceil=\left\lceil |BC|\right\rceil-1$$$. Total moves equals to $$$2+2\left\lceil |CE|\right\rceil=2\left\lceil |BC|\right\rceil\le \left\lceil |AC|\right\rceil+\left\lceil |BC|\right\rceil=\left\lceil 2|AC|\right\rceil$$$.
Be careful with small cases where $$$|BC|$$$ is too short, which may make $$$|DF|=|EG| \lt 0.5$$$.
Note that there are some cases where $$$\angle CBx \gt 30^\circ$$$ and $$$\angle CAB \lt 30^\circ$$$, where Case 2 strategy doesn't work. So case 1.2 is required.
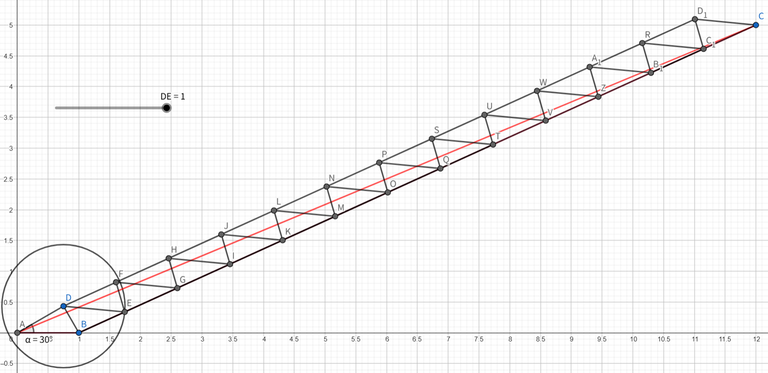
Case 3: If $$$\angle CBx \gt \angle CAB \gt 60^\circ$$$. We first build a point $$$D$$$ which makes $$$AD=1$$$ and $$$\angle DAB=60^\circ$$$ and construct $$$\triangle DAB$$$. We write $$$|AC|=a+b$$$ where $$$a$$$ is integer, then we analyze two cases about $$$b$$$.
Case 3.1: When $$$b \gt 0.5$$$ or $$$b=0$$$, $$$2\left\lceil |AC|\right\rceil=\left\lceil 2|AC|\right\rceil$$$. We begin a same parallelogram construction as Case 1 where the sides of parallelogram are $$$BC,BD$$$. We can show that $$$30^\circ\le\angle CBD\le60^\circ$$$. So it is possible to pile up to $$$C$$$ from $$$BD$$$ in $$$2\left\lceil |BC|\right\rceil-1$$$ moves. And in total we need $$$2\left\lceil |BC|\right\rceil\le2\left\lceil |AC|\right\rceil=\left\lceil 2|AC|\right\rceil$$$ moves.
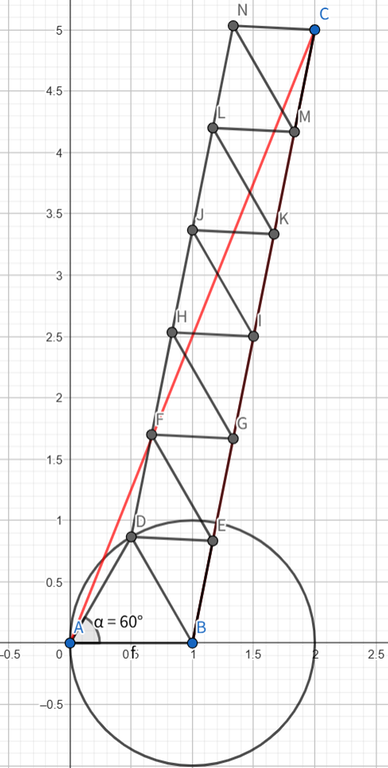
Case 3.2: When $$$0 \lt b\le 0.5$$$, $$$2\left\lceil |AC|\right\rceil=\left\lceil 2|AC|\right\rceil+1$$$. We instead connect $$$CD$$$ and construct parallelogram with sides $$$DC,DB$$$. We can show that $$$120^\circ\le\angle CDB\le150^\circ$$$ so we can still do the parallelogram construction. When $$$|AC|\ge \sqrt{3}$$$, $$$\left\lceil |CD|\right\rceil=\left\lceil |AC||\right\rceil-1$$$, making the number of moves $$$2\left\lceil |CD|\right\rceil+1=2\left\lceil |AC|\right\rceil-1=\left\lceil 2|AC|\right\rceil$$$.
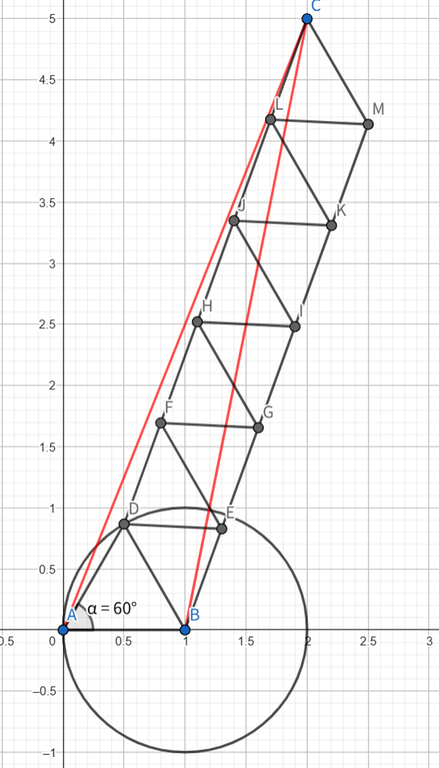
Actually case 1.1 is not required, because it is impossible to construct a testcase where $$$\angle CAB \lt 60^\circ, \angle CBx \gt 60^\circ,0 \lt b\le 0.5$$$ and Case 3.2 fails.
#include <bits/stdc++.h>
using namespace std;
typedef double db;
const db pi = acos(-1.0);
const int N = 1000005;
inline int sgn(db x){
if(x < 1e-13 && x > -1e-13) return 0;
if(x > 0) return 1;
return -1;
}
struct point{
db x,y;
point (db _x = 0.0,db _y = 0.0) : x(_x), y(_y) {}
};
point operator + (const point &p1,const point &p2){
return point(p1.x + p2.x,p1.y + p2.y);
}
point operator - (const point &p1,const point &p2){
return point(p1.x - p2.x,p1.y - p2.y);
}
point operator * (db x,const point &p){
return point(x * p.x,x * p.y);
}
bool operator == (point x,point y){
return sgn(x.x - y.x) == 0 && sgn(x.y - y.y) == 0;
}
inline db dot(point p1,point p2){
return p1.x * p2.x + p1.y * p2.y;
}
inline db det(point p1,point p2){
return p1.x * p2.y - p2.x * p1.y;
}
inline db len(point p){
return sqrtl(1.0 * p.x * p.x + 1.0 * p.y * p.y);
}
point project_point(point x,point ya,point yb){
point v = yb - ya;
return ya + (dot(v,x - ya) / dot(v,v)) * v;
}
db distp(point x,point ya,point yb){
return fabs(det(ya - x,yb - x)) / len(yb - ya);
}
point line_circle_intersec_point(point o,point la,point lb){
db dis = distp(o,la,lb),l;
point pj = project_point(o,la,lb);
l = sqrt(1.0 - dis * dis);
point ret = pj + (l / len(lb - la)) * (lb - la);
return ret;
}
tuple <int,int,int> ans[N];
point p[N],target;
int step;
bool check(int n){
set <pair <int,int> > st;
st.insert({1,2});
if(n > step) return 0;
db eps_len = 1e-8,eps_dis = 1e-4;
int fl = 0;
for(int i = 1;i <= n;i ++){
auto [u,v,w] = ans[i];
if(u > v) swap(u,v);
if(st.find({u,v}) == st.end()) return 0;
if(len(p[u] - p[w]) < 0.5 - eps_len || len(p[u] - p[w]) > 1.0 + eps_len) return 0;
if(len(p[v] - p[w]) < 0.5 - eps_len || len(p[v] - p[w]) > 1.0 + eps_len) return 0;
st.insert({u,w}); st.insert({v,w});
if(len(p[w] - target) <= eps_dis) fl = 1;
}
return 1;
}
int solve1a(){
point dir = target - p[1];
int split = ceil(len(dir) - 1e-9);
int c = 2;
for(int i = 1;i < split;i ++){
++ c; p[c] = p[1] + (1.0 * i / split) * dir;
ans[c - 2] = {c - 2,c - 1,c};
++ c; p[c] = p[2] + (1.0 * i / split) * dir;
ans[c - 2] = {c - 2,c - 1,c};
// construct one parallelogram
}
++ c; p[c] = target;
ans[c - 2] = {c - 2,c - 1,c};
if(check(c - 2)) return c - 2;
return 0;
}
int solve1b(){
point dir = target - p[2];
int split = ceil(len(dir) - 1e-9);
int c = 2;
for(int i = 1;i <= split;i ++){
++ c; p[c] = p[1] + (1.0 * i / split) * dir;
ans[c - 2] = {c - 2,c - 1,c};
++ c; p[c] = p[2] + (1.0 * i / split) * dir;
ans[c - 2] = {c - 2,c - 1,c};
}
if(check(c - 2)) return c - 2;
return 0;
}
int solve2(){
p[3] = point(sqrt(3.0) / 2,0.5);
p[4] = line_circle_intersec_point(p[3],p[2],target);
if(len(p[4] - p[2]) > 1)
p[4] = p[2] + (1.0 / len(target - p[2])) * (target - p[2]);
ans[1] = {1,2,3};
ans[2] = {2,3,4};
point dir = target - p[4];
int split = ceil(len(dir) - 1e-9);
int c = 4;
for(int i = 1;i <= split;i ++){
++ c; p[c] = p[3] + (1.0 * i / split) * dir;
ans[c - 2] = {c - 2,c - 1,c};
++ c; p[c] = p[4] + (1.0 * i / split) * dir;
ans[c - 2] = {c - 2,c - 1,c};
}
if(check(c - 2)) return c - 2;
return 0;
}
int solve3a(){
p[3] = point(0.5,sqrt(3.0) / 2);
ans[1] = {1,2,3};
point dir = target - p[2];
int split = ceil(len(dir) - 1e-9);
int c = 3;
for(int i = 1;i < split;i ++){
++ c; p[c] = p[2] + (1.0 * i / split) * dir;
ans[c - 2] = {c - 2,c - 1,c};
++ c; p[c] = p[3] + (1.0 * i / split) * dir;
ans[c - 2] = {c - 2,c - 1,c};
}
++ c; p[c] = target;
ans[c - 2] = {c - 2,c - 1,c};
if(check(c - 2)) return c - 2;
return 0;
}
int solve3b(){
p[3] = point(0.5,sqrt(3.0) / 2);
ans[1] = {1,2,3};
point dir = target - p[3];
int split = ceil(len(dir) - 1e-9);
int c = 3;
for(int i = 1;i <= split;i ++){
++ c; p[c] = p[2] + (1.0 * i / split) * dir;
ans[c - 2] = {c - 2,c - 1,c};
++ c; p[c] = p[3] + (1.0 * i / split) * dir;
ans[c - 2] = {c - 2,c - 1,c};
}
if(check(c - 2)) return c - 2;
return 0;
}
int solve(){
if(int res = solve1a()) return res;
if(int res = solve1b()) return res;
if(int res = solve2()) return res;
if(int res = solve3a()) return res;
if(int res = solve3b()) return res;
return 0;
}
int main(){
int TC; scanf("%d",&TC);
p[1] = point(0,0);
p[2] = point(1,0);
while(TC --){
int tx,ty;
scanf("%d %d %d",&tx,&ty,&step);
step = ceil(2.0 * sqrt(1.0 * tx * tx + 1.0 * ty * ty));
target = point(tx,ty);
int n = solve();
assert(n > 0);
printf("%d\n",n);
for(int i = 1;i <= n;i ++){
auto [u,v,w] = ans[i];
printf("%d %d %.12lf %.12lf\n",u,v,p[w].x,p[w].y);
}
}
return 0;
}

