


Introduction
On 23 and 24 May, 7 countries participated in the South East Asia Team Selection Test.
As the only contestant who AKed both days, I decided to write an editorial for the bugaboos. (The bugaboos are here.)
1A (Two Exams)
My solution was the same as blackscreen1's solution, but I found it in a different way. First, I tried binary searching on the answer, so it reduces to checking if $$$P[i] - i \leq K$$$.
Rather than setting $$$P^{-1}[0], P^{-1}[1], \cdots$$$, giving each index $$$i$$$ a deadline of $$$i + K$$$, I decided to use the reverse order; first set $$$P^{-1}[N-1]$$$, then $$$P^{-1}[N-2]$$$, and so on. This means that each index $$$i$$$ is only "usable" from "time" $$$i+K$$$ onwards. Then, $$$P^{-1}[i]$$$ must be the remaining student with highest $$$A$$$ or highest $$$B$$$.
Now, the key observation is that the only way we can "die" is if none of these two students are usable. This means that there is no "better" student to choose; Both choices simply remove a student from the current pool of "viable" students (a viable student is a student that can be removed at the current point in time by repeatedly removing a usable student with highest $$$A$$$ or highest $$$B$$$).
Going back to the main bugaboo, it becomes obvious that we should choose the remaining student with higher index as $$$P^{-1}[i]$$$; if $$$\text{ans} \lt i - (\text{lower index})$$$, we have to choose the higher one to proceed; if $$$\text{ans} \geq i - (\text{lower index})$$$, choosing either student is fine. In both cases, choosing the higher index is not harmful.
#include "exam.h"
#include <bits/stdc++.h>
using namespace std;
#define all(v) begin(v),end(v)
#define REP(i,a,b) for(int i=a;i<b;i++)
int minimum_dissatisfaction(int N, std::vector<int> A, std::vector<int> B) {
vector<int> apq(N), bpq(N);
for(int i=0;i<N;i++) {
apq[A[i]] = i;
bpq[B[i]] = i;
}
bool taken[N];
memset(taken,0,sizeof(taken));
int ans = 0;
for(int i=N;i--;) {
while(taken[apq.back()])
apq.pop_back();
while(taken[bpq.back()])
bpq.pop_back();
if(apq.back() > bpq.back()) {
taken[apq.back()] = 1;
ans = max(ans, i - apq.back());
} else {
taken[bpq.back()] = 1;
ans = max(ans, i - bpq.back());
}
}
return ans;
}
1B (Country Ranks)
When I first saw the bugaboo, I believed that someone was expecting me to get $$$574$$$ points. Turns out that the scores were just randomly sampled from IOI Gold Medallists in 2025. On hindsight, it would have been funny if I intentionally chose to get $$$574$$$ by adding useless gates in the OO.
I first created a provisional country list as follows: When we see a student with rank $$$x$$$, find a country with exactly $$$x$$$ people, and add the student to the country.
Note that whenever two countries have the same number of people, we can swap them and get another valid assignment. This means that if country $$$1$$$ and country $$$2$$$ both have $$$k$$$ people at some point in time, the $$$\geq (k+1)^{st}$$$ and $$$\leq k^{th}$$$ people in country $$$1$$$ do not necessarily belong to the same country.
Thus, for each country, we can store all these "cut points", and use them to find the consecutive ranges of people guaranteed to be in the same country.
#include "country.h"
#include <bits/stdc++.h>
using namespace std;
#define all(v) begin(v),end(v)
#define REP(i,a,b) for(int i=a;i<b;i++)
long long count_same_country(int N, std::vector<int> country_rank) {
vector<int> ppl(N,0);
vector<int> time[N];
for(int x: country_rank) {
int add = upper_bound(all(ppl),x) - begin(ppl) - 1;
ppl[add]++;
if(add != N - 1 && ppl[add] == ppl[add+1]) {
time[add].push_back(ppl[add]);
time[add+1].push_back(ppl[add]);
}
}
long long ans = 0;
for(int i=0;i<N;i++) {
int prv = 0;
for(int x: time[i]) {
ans += (x - prv) * (x - prv - 1LL) / 2;
prv = x;
}
ans += (ppl[i] - prv) * (ppl[i] - prv - 1LL) / 2;
}
return ans;
}
My solution was the same as blackscreen1's solution, but I found it in a different way.
Define a country state as a pair containing the current "time" (i.e. the number of students already processed) and the number of people in the country. We can draw a graph of country states, where an edge from $$$(t, cnt)$$$ to $$$(t+1, cnt_1)$$$ means there is a country with $$$cnt$$$ people at time $$$t$$$, and $$$cnt_1$$$ people at time $$$t+1$$$.
Claim: Suppose that:
- there exists a path from $$$(0,0)$$$ to $$$(t_1, x_1)$$$
- $$$t_0 \leq t_1$$$
- There exists a path from $$$(t_0, x_0)$$$ to $$$(t_1, l)$$$ and $$$l \leq x_1$$$
- There exists a path from $$$(t_0, x_0)$$$ to $$$(t_1, r)$$$ and $$$r \geq x_1$$$
Then there exists a path from $$$(t_0, x_0)$$$ to $$$(t_1, x_1)$$$.
Proof:
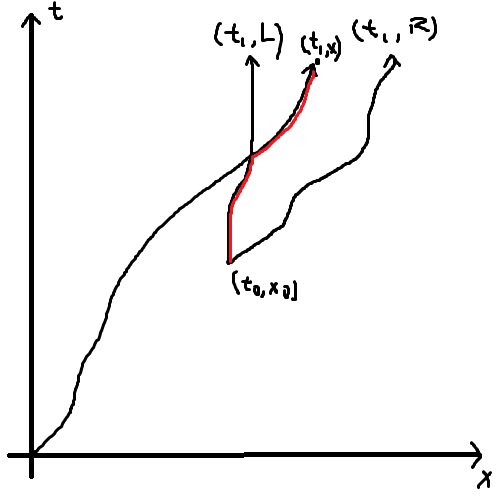
Thus, for each student, we just need to keep track of the leftmost and rightmost points it can end up in at various points in time. Since we only care about the number of students, we can use two frequency arrays, $$$L$$$ and $$$R$$$. Refer to the implementation for more details.
struct fenwick { int n; vector f; fenwick(int _n): n(_n+1), f(_n+1,0) {} void up(int x, int u) { for(x++;x<n;x+=(x&-x)) f[x] += u; } int qry(int x) { int ans = 0; for(x++;x;x-=(x&-x)) ans += f[x]; return ans; } }; long long count_diff_country(int N, std::vector country_rank) { fenwick lft(N), rgt(N); long long ans = 0; vector ppl(N,0); for(int i=0;i<N;i++) { int x = country_rank[i]; int add = upper_bound(all(ppl),x) — begin(ppl) — 1; int lx = lft.qry(x); int lxm = lft.qry(x-1); int rx = rgt.qry(x); int rxm = rgt.qry(x-1); ans += i — lx; ans += rxm; rgt.up(x+1,rx — rxm); rgt.up(x,-(rx — rxm)); if(add == 0 || ppl[add-1] < x) { lft.up(x+1,lx — lxm); lft.up(x,-(lx — lxm)); } ppl[add]++; rgt.up(x+1,1); lft.up(x+1,1); } return ans; }
1C (XOR Teleport)
Ideas
Looking at the $$$W \leq 1$$$ subbugaboo, we see that it is helpful to colour nodes based on the XOR of edges on the path to $$$0$$$. Let this value be $$$d_u$$$. In the $$$W \leq 1$$$ subbugaboo, the answer is $$$0$$$ if and only if there exists a common ancestor $$$L$$$ of $$$U$$$ and $$$V$$$, with $$$d_L = d_U = d_V$$$.
We can generalise this to compute $$$\lfloor \log_2 \text{ans} \rfloor$$$. We note that if $$$\text{ans} \lt 2^k$$$, we can only jump between nodes $$$u$$$ and $$$v$$$ with $$$d_u \oplus d_v \lt 2^k \implies (d_u \gg k) = (d_v \gg k)$$$. Thus, there must be a common ancestor $$$L$$$ of $$$U$$$ and $$$V$$$, with $$$(d_L \gg k) = (d_U \gg k) = (d_V \gg k)$$$. Let us compute $$$par(u,k)$$$ (which we will discuss later), the highest ancestor of $$$u$$$ such that $$$d_{par(u,k)} \gg k = d_u \gg k$$$. Then, this reduces to checking if $$$par(U,k)=par(V,k)$$$.
Suppose we have found out that $$$2^k \leq \text{ans} \lt 2^{k+1}$$$. Any jumps with $$$d_u \oplus d_v \lt 2^k$$$ are now "free". Using only "free jumps", we can jump from $$$U$$$ to any node $$$u$$$ such that $$$(d_u \gg k) = (d_U \gg k)$$$ and $$$u$$$ is a descendant of $$$par(U,k)$$$ (it is easy to check these two conditions are both necessary and sufficient). Call the set of such nodes $$$S_U$$$, and define $$$S_V$$$ similarly. Also, if $$$(d_u \gg (k+1)) \neq (d_v \gg (k+1))$$$, jumping from $$$u$$$ to $$$v$$$ is bad since $$$d_u \oplus d_v \geq 2^{k+1}$$$.
There are two cases here.
Case 1: $$$par(U,k)$$$ is an ancestor of $$$par(V,k)$$$.
In this case, $$$(d_V \gg k) \neq (d_U \gg k)$$$ (since if they were equal, $$$par(V,k)$$$ would not be the highest parent). In this case, to get from $$$U$$$ to $$$V$$$, we must jump from $$$S_U$$$ to $$$S_V$$$ at some point in time. Suppose we jump from $$$u \in S_U$$$ to $$$v \in S_V$$$. Then we need to minimise $$$d_u \oplus d_v$$$ over all such $$$u$$$ and $$$v$$$.
Let $$$x$$$ be the lower node. Then, we want to minimise $$$d_x \oplus d_y$$$, given that $$$y$$$ is an ancestor of $$$x$$$, and the most significant bit $$$d_x$$$ and $$$d_y$$$ differ is the $$$k$$$-th bit. Let this be $$$f(x,k)$$$. We thus have to find the minimum value of $$$f(x,k)$$$, where $$$x$$$ is in the subtree of $$$par(V,k)$$$ and $$$(d_x \gg (k+1)) = (d_{par(V,k)} \gg (k+1))$$$. Call this $$$g(par(V,k),k+1)$$$. We will discuss how to compute $$$f$$$ and $$$g$$$ later.
Case 2: $$$par(U,k)$$$ and $$$par(V,k)$$$ are not ancestors of each other.
In this case, we first jump out of the subtree of $$$par(U,k)$$$, for a cost of $$$g(par(U,k),k+1)$$$, then jump into the subtree of $$$par(V,k)$$$, for a cost of $$$g(par(V,k),k+1)$$$.
Implementation Notes
$$$par$$$ and $$$f$$$ can be computed easily with a trie. DFS from node $$$0$$$, and add $$$d_x$$$ to the trie when we enter it, then remove $$$d_x$$$ when we leave it.
I avoided implementation messiness by using an array segtree rather than pointers. I had an array of size $$$2^{21}$$$, and the left and right children of node $$$x$$$ are $$$2x$$$ and $$$2x+1$$$. The root is node $$$1$$$, and nodes $$$[2^{20},2^{21})$$$ are the leaves.
Note that $$$g(x,k)$$$ is the minimum value of $$$f(y,k-1)$$$ where $$$(d_y \gg k) = (d_x \gg k)$$$. We store a map, where the key is $$$(k, d_y \gg k)$$$, and the value is the minimum $$$f(y,k-1)$$$. Two maps can be merged using small-to-large merging to achieve a complexity of $$$N \log N \log A + Q \log \log A$$$. (Since I used regular rather than unordered maps, and found $$$k$$$ by linear search rather than binary search, my code's complexity was $$$N \log^2 N \log A + Q \log A$$$).
In my implementation, I lumped $$$(k, d_y \gg k)$$$ into a single integer.
#include "teleport.h"
#include <bits/stdc++.h>
using namespace std;
int par[50'005][21];
map<int,int> mpScore[50'005];
int minScore[50'005][21];
int dist[50'005];
int pre[50'005], post[50'005];
int seg[1<<21];
void init(int N, std::vector<int> P, std::vector<int> W) {
fill(seg,seg+(1<<21),50005);
vector<vector<pair<int,int>>> child(N);
for(int i=1;i<N;i++)
child[P[i]].push_back({i,W[i]});
int cnt = 0;
auto dfs = [&child,&cnt](auto &dfs, int x, int p) -> void {
pre[x] = cnt++;
int v = dist[x] + (1<<20);
for(int i=v;i;i>>=1)
seg[i] = min(seg[i],x);
for(int i=0;i<21;i++)
par[x][i] = seg[v>>i];
for(int i=0;i<20;i++) {
int cur = (v >> i) ^ 1;
int j = i;
if(seg[cur] == 50005)
continue;
while(cur < (1<<20)) {
j--;
int pref = (cur << 1) | ((v>>j) & 1);
if(seg[pref] == 50005)
cur = pref ^ 1;
else
cur = pref;
}
cur ^= v;
int k = v >> (i + 1);
if(mpScore[x].count(k))
mpScore[x][k] = min(mpScore[x][k], cur);
else
mpScore[x][k] = cur;
}
for(auto [i, w]: child[x])
if(i != p) {
dist[i] = dist[x] ^ w;
dfs(dfs, i, x);
if(mpScore[i].size() > mpScore[x].size())
swap(mpScore[x], mpScore[i]);
for(auto [k, v]: mpScore[i]) {
if(mpScore[x].count(k))
mpScore[x][k] = min(mpScore[x][k], v);
else
mpScore[x][k] = v;
}
}
for(int i=1;i<21;i++)
minScore[x][i] = (mpScore[x].count(v>>i)?mpScore[x][v>>i]:50005);
for(int i=v;i;i>>=1)
if(seg[i] == x)
seg[i] = 50005;
post[x] = cnt;
};
dfs(dfs, 0, -1);
}
int minimum_energy(int U, int V) {
int layer;
for(layer=0;layer<21;layer++) {
if(par[U][layer] == par[V][layer])
break;
}
if(layer == 0)
return 0;
return max(minScore[par[U][layer-1]][layer],minScore[par[V][layer-1]][layer]);
}
2A (Triple Circuit)
2B (Car Gathering)
Let $$$f_i(p)$$$ be the cost function when $$$C[j]$$$ is replaced by $$$1$$$ if $$$C[j] \gt i$$$ and $$$0$$$ otherwise, and let $$$f(p)$$$ be the original cost function. Note $$$f(p) = \sum_{i=0}^{99} f_i(p)$$$.
$$$f_i(p)$$$ is the sum of the $$$k_i$$$ largest distances from $$$p$$$ to the cars, for some constant $$$k_i$$$. It can thus be shown that $$$f_i(p)$$$ is convex since the distance to each car is a convex function. Hence $$$f$$$ is convex and we can apply ternary search. This is still too slow as $$$N \leq 10^7$$$.
To speedup, note that we can compute $$$f_i(p)$$$ by binary searching for the distance $$$d$$$, such that $$$k_i$$$ cars are further away than $$$d$$$ from point $$$p$$$. Once we have $$$d$$$, compute $$$L$$$ to $$$R$$$ such that the cars far enough from $$$p$$$ have index $$$ \lt L$$$ or $$$ \gt R$$$, and find the sum of distances for these cars. This runs in $$$O(N + 100 \log N \log^2 X)$$$.
#include "gather.h"
#include <bits/stdc++.h>
using namespace std;
const int INF = 1e9 + 3;
int car_gathering(int N, std::vector<int> X, std::vector<int> C) {
vector<long long> pre(N+1,0);
vector<int> pos(100);
for(int i=0;i<100;i++)
pos[i] = upper_bound(C.begin(),C.end(),i)-C.begin();
for(int i=0;i<N;i++)
pre[i+1] = pre[i] + X[i];
auto comp1 = [&N,&X,&pre](int v, int p) {
// >= v elements, dist <= d
long long l = -1, h = 10LL*INF;
while(h - l > 1) {
long long m = l + (h - l) / 2;
int lft = (p >= m - INF ? lower_bound(X.begin(), X.end(), p - m) - X.begin() : 0);
int rgt = (p <= INF - m ? upper_bound(X.begin(), X.end(), p + m) - X.begin() : N);
if(rgt - lft >= v)
h = m;
else
l = m;
}
int lft = (p >= h - INF ? lower_bound(X.begin(), X.end(), p - h) - X.begin() : 0);
int rgt = (p <= INF - h ? upper_bound(X.begin(), X.end(), p + h) - X.begin() : N);
return (1LL * p * lft - pre[lft] + (pre[N] - pre[rgt]) - 1LL * p * (N - rgt) + 1LL * (rgt - lft - v) * h);
};
auto compAll = [&pos,&comp1](int p) {
long long ans = 0;
for(auto x: pos)
ans += comp1(x, p);
return ans;
};
// smallest st f(x) <= f(x+1)
int l = -INF, h=INF;
while(h - l > 1) {
int m = l + (h - l) / 2;
if(compAll(m) <= compAll(m+1))
h = m;
else
l = m;
}
return h;
}
2C (Troublesome Trip)
Let the "layer" of a node be its distance from 0, and its parent be any parent in the BFS tree. Let the weight of an edge be the maximum distance of one endpoint to node 0.
The main idea is this: Fix the lowest species encountered, L, and build a psuedo-Minimum Spanning Tree using just the nodes at "layer" $$$L$$$. Formally, define the distance between two nodes of "layer" $$$L$$$ as the minimum weight of a path that doesn't pass through nodes in "layer" $$$L-1$$$, where the weight of a path is the maximum weight of edges it passes through. Then, we will ensure that the distance between any two nodes is the same in both the psuedo-MST and the original graph.
If we can build this psuedo-MST, then we can find an ancestor of $$$A$$$ and an ancestor of $$$B$$$ on layer $$$L$$$, and calculate their distance. Doing so for all $$$L$$$ will solve the bugaboo.
To build the psuedo-MST, we will observe that we only need the following edges:
- $$$(u, v)$$$ where $$$u$$$ and $$$v$$$ are in layer $$$L$$$
- $$$(par[u], v)$$$ where $$$u$$$ is in layer $$$L+1$$$ and $$$v$$$ is in layer $$$L$$$
- $$$(par[u], par[v])$$$, where $$$(u, v)$$$ is an edge in the MST of layer $$$L+1$$$
Therefore we build a psuedo-MST using these edges.
Regarding complexity: The total number of edges of the first two types is equal to $$$M$$$. The third type only has $$$(\text{# of nodes in layer L+1}) - 1$$$ edges, which is \leq N$ when we sum over all layers, so this algorithm runs in $$$O(N \alpha(N))$$$ (assuming $$$N=M$$$).
Funny thing: I found this solution in-contest, and it took me several additional minutes to realise it was $$$N+M$$$ and not $$$N^2+M$$$.
#include "trip.h"
#include <bits/stdc++.h>
using namespace std;
struct ufds {
vector<int> par, sz;
ufds(int n): sz(n,1), par(n) {
iota(par.begin(),par.end(),0);
}
int findSet(int x) {
if(par[x] == x)
return x;
return par[x] = findSet(par[x]);
}
bool unite(int x, int y) {
x = findSet(x);
y = findSet(y);
if(x == y)
return 0;
if(sz[x] > sz[y])
swap(x, y);
sz[y] += sz[x];
par[x] = y;
return 1;
}
};
int min_distinct(int N, int M, int A, int B, std::vector<int> U, std::vector<int> V) {
queue<int> q;
int dist[N], par[N];
vector<int> adj[N];
vector<int> nodes[N];
memset(dist,-1,sizeof(dist));
dist[0] = 0;
q.push(0);
for(int i=0;i<M;i++) {
adj[U[i]].push_back(V[i]);
adj[V[i]].push_back(U[i]);
}
while(q.size()) {
int x = q.front();
nodes[dist[x]].push_back(x);
q.pop();
for(auto y: adj[x])
if(dist[y] == -1) {
dist[y] = dist[x] + 1;
par[y] = x;
q.push(y);
}
}
ufds u(N);
vector<tuple<int,int,int>> prv;
int ans = N;
int orig = max(dist[A], dist[B]);
for(int h=N;h--;) {
int sz = nodes[h].size();
if(sz == 0)
continue;
if(dist[A] > h)
A = par[A];
if(dist[B] > h)
B = par[B];
if(A == B)
ans = min(ans, orig - h);
vector<tuple<int,int,int>> nw;
for(auto x: nodes[h])
for(auto y: adj[x])
if(dist[x] == dist[y] && u.unite(x, y)) {
nw.push_back({h, x, y});
if(u.findSet(A) == u.findSet(B))
ans = min(ans, orig - h);
}
for(auto x: nodes[h])
for(auto y: adj[x])
if(dist[y] > dist[x] && u.unite(x, par[y])) {
nw.push_back({h+1, x, par[y]});
if(u.findSet(A) == u.findSet(B))
ans = min(ans, max(orig, h+1) - h);
}
for(auto [w, x, y]: prv) {
x = par[x];
y = par[y];
if(u.unite(x, y)) {
nw.push_back({w, x, y});
if(u.findSet(A) == u.findSet(B))
ans = min(ans, max(orig, w) - h);
}
}
prv = nw;
nw.clear();
}
return ans+1;
}

