


Привет, сообщество CodeForces!
Недавно вспомнил одну интересную задачу на C++. Если кратко: можно ли написать такие функции action и cond так, чтобы следующие куски кода работали по-разному:
// Snippet #1:
action();
while (cond()) {
action();
}
// Snippet #2:
do {
action();
} while (cond());
Более формально: у вас есть следующие три файла:
common.h
main_while.cpp
main_do_while.cpp
Вам разрешено менять лишь common.h. Сделайте это так, чтобы слово Action напечаталось разное количество раз для запусков main_while.cpp и main_do_while.cpp.
Одно из возможных решений (настоятельно рекомендуется сначала подумать самостоятельно!):
Dirty hack
Скидывайте свои решения в комментариях, не забывайте прятать под спойлеры! Было бы интересно посмотреть на более умные решения (например на такие, которые будут применимы в любом языке, где есть аналоги while и do-while).






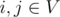 . Тогда диаметр графа определяется как максимально возможное среди всех кратчайших расстояний между парой вершин:
. Тогда диаметр графа определяется как максимально возможное среди всех кратчайших расстояний между парой вершин: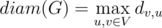
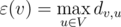
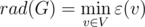
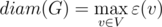
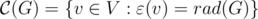
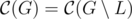
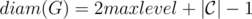 и
и 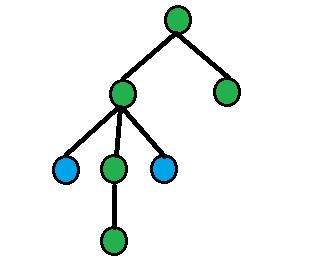
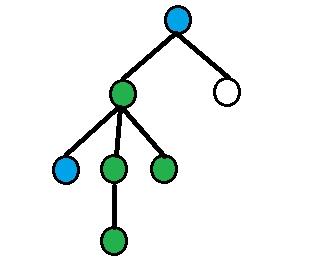
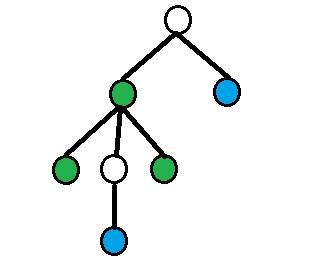

 .
. 
{kind=link}