


Всем привет!
Меня зовут Леша, и я уже более 10 лет наслаждаюсь возможностью наблюдать за ростом студентов в Школе анализа данных. За это время много представителей сообщества codeforces окончили программу и получили значительный буст в индустриальной карьере и науке. Но сегодня я хочу сообщить, что самое время подать заявку на поступление в 2025, т.к. времени осталось не слишком много.
Доступ к контесту открыт, мы постарались сделать интересными задачи и по математике, и по программированию.
Если вы еще не заполнили анкету — то скорее заполняйте. Рекомендуем не затягивать — прием анкет до 4 мая, а тестирование занимает время.
Про контест:
- Стартовать можно в любое время до 19:00 5 мая MSK, после этого времени стартовать уже нельзя;
- У вас будет 5 часов на выполнение теста.
Важно: В задачах по программированию вы сразу увидите результат проверки на всех тестах (как открытых, так и скрытых), по математике — нет.
Мы за честность и прозрачность, поэтому убедительная просьба не делиться условиями, решениями и подсказками в открытом доступе.
Удачи! Будет сложно, но вам понравится!
P.S. Также оставлю ссылку на наш уютный канал, где обсуждаем жизнь в ШАД и интересные задачи.






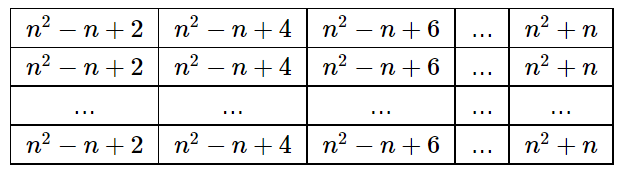
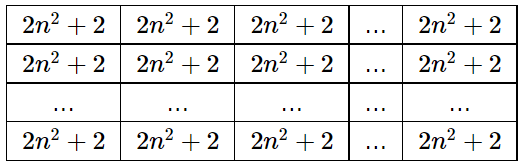


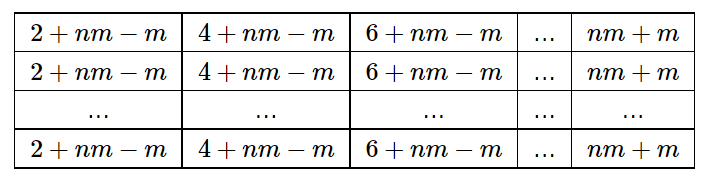
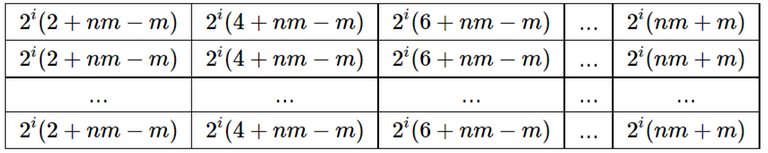
 .
.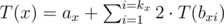
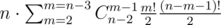
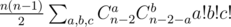 ;
;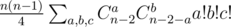 ;
;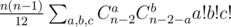 .
.
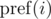 должна вычислить результат на префиксе числа
должна вычислить результат на префиксе числа 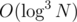 , но вы его можете ускорить до
, но вы его можете ускорить до 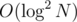 . Может даже быстрее?
. Может даже быстрее?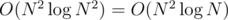 . Теперь рассмотрим все пары чисел. Для каждой пары шестерней с диаметрами
. Теперь рассмотрим все пары чисел. Для каждой пары шестерней с диаметрами 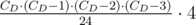 , для каждой пары диаметров
, для каждой пары диаметров 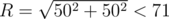 .
.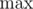 и
и 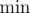 . Затем в цикле считываем
. Затем в цикле считываем  .
.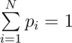 . Довольно просто можно показать, что система всегда будет совместной; система может быть решена, например, методом Гаусса.
. Довольно просто можно показать, что система всегда будет совместной; система может быть решена, например, методом Гаусса.