


(For the tutorial, skip to the second paragraph)
The recently held Educational Codeforces Round 87 was full of controversies. The delay in its start, the overlap with Google Code Jam and then the many complaints that problems B, C1, C2 and D were all google-able! In particular, problem D was heavily criticised due to its strict memory limit which didn't help non-C++ users. The authors have given their reasons for this — to discourage the use of memory heavy data structures such as policy-based data structures (gnu pbds) and treaps. I personally found the contest to be "educational" indeed and I'm sure the same authors will now deliver even better contests in the future.
Here I discuss the problem D — Multiset and some of the ways in which it could be solved. This blog is aimed at beginners. I hope to provide you with a gentle introduction to this fast and easy-to-implement data structure called Fenwick Tree, or Binary Indexed Tree (BIT).
The problem: Given a multiset with $$$n$$$ integers (where each element $$$x \in [1, n]$$$), perform the following queries $$$q$$$ times:
Insert some integer $$$k$$$ ($$$k \in [1, n]$$$) into the multiset
Find the $$$k^{th}$$$ order statistic in the multiset and remove exactly one copy of it from the multiset
Constraints: $$$(1≤n, q≤10^6)$$$
To solve this problem, we need to maintain a memory-efficient data structure that can perform these operations in $$$O(log(n))$$$.
Let us imagine an array $$$freq[n + 1]$$$ of size $$$n + 1$$$. Index $$$i$$$ of this array corresponds to the frequency of the element $$$i$$$ in our multiset. Adding an integer $$$k$$$ to the multiset is now equivalent to incrementing $$$freq[k]$$$ and removing it is equivalent to decrementing it by 1. To find the $$$k^{th}$$$ order statistic, we need to find the $$$smallest$$$ $$$i$$$ : $$$cumulative$$$ $$$frequency$$$ $$$of$$$ $$$i$$$ $$$ \gt =$$$ $$$k$$$. The cumulative frequency of $$$i$$$ is nothing but the prefix sum $$$\sum\limits_{j = 1}^i{freq[j]}$$$. By now, you may have imagined that the $$$k^{th}$$$ order statistic can be found easily by binary search on the array of cumulative frequencies. However, the update operations on such an array would be costly. Fenwick trees provide us with a way to implement dynamic frequency tables. Fenwick tree is implicitly defined by an array, say $$$bit[n + 1]$$$. Rather than storing the sum of frequencies from 1 to $$$x$$$ at position $$$x$$$, we instead store the sum from $$$(x -$$$ ($$$x$$$ & $$$-x$$$) + $$$1)$$$ to $$$x$$$. Here ($$$x$$$ & $$$-x$$$) gives the value obtained by resetting the least significant 1-bit of $$$x$$$ in binary notation. In other words, the length of an interval at position $$$x$$$ is the same as the least significant 1-bit of $$$x$$$.
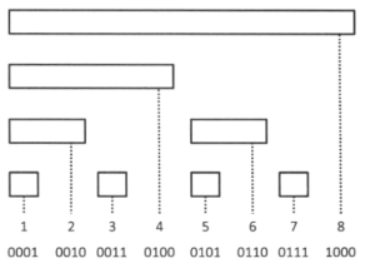
Example:
For $$$x$$$ = 6 which is $$$(110)_2$$$ , $$$x$$$ & $$$-x$$$ = $$$010$$$
Length of interval = $$$(010)_2$$$ = 2 Starting position = 6 — 2 + 1 = 5
$$$bit[6]$$$ = $$$\sum\limits_{j = 5}^6{freq[j]}$$$
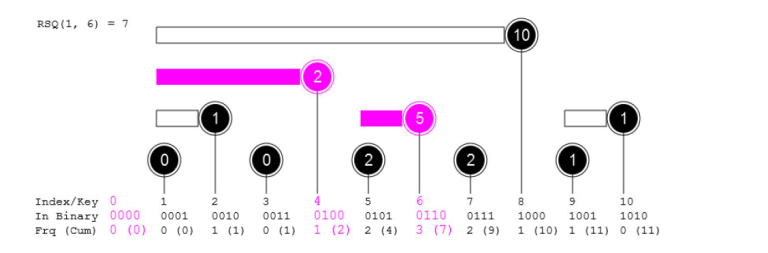
How to get the cumulative frequency of $$$x$$$ a.k.a the range sum query for $$$[1, x]$$$ on the $$$freq$$$ array that we imagined? Notice that every index has exactly one interval ending there. Furthermore, every range $$$[1, x]$$$ is constructible from the given intervals. To keep adding the sum from position $$$x$$$ until 0, all we need is to keep updating the index to one less than the starting position of the current interval. Starting with $$$i = x$$$, we update $$$i =$$$ $$$i$$$ — $$$(i$$$ & $$$-i)$$$ to go to the next interval from right to left until $$$i$$$ becomes 0.
Example for range sum query of [1, 6]
We are now ready to write some code.
int bit[MAX_N + 1]; // MAX_N is the maximum allowed value of an element in the multiset
int sum(int i) { // Returns the sum from freq[1] to freq[i]
int s = 0;
while (i > 0) {
s += bit[i]; // Add the sum corresponding to the interval covered by position i
i -= i & -i; // Update i to get the next interval
}
return s;
}
To get the sum for a range L to R, simply calculate $$$sum(R) - sum(L - 1)$$$.
The $$$sum(x)$$$ function runs in $$$O(log(n))$$$ as every range can be broken down into at most $$$log_2n$$$ intervals.
Now back to the problem we were solving. As we had concluded earlier, the order statistics can be found by using binary search as we now have a cost-effective way of calculating the cumulative frequency of each position (element in multiset). Before we explore this, we need to discuss the update operations — adding and removing elements from the multiset, which corresponds to adding 1 and -1 to the corresponding frequency table and updating the Fenwick tree accordingly.
Let's say we want to add $$$cnt$$$ to position $$$i$$$. This will affect all those intervals which contain $$$i$$$. If you draw a vertical line from any position in the first figure, you will find that it intersects exactly the intervals which we are interested in updating.
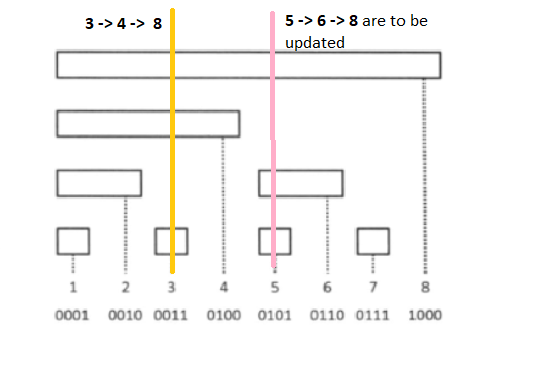
How to find this interval? Simply update $$$i =$$$ $$$i$$$ + $$$(i$$$ & $$$-i)$$$. To get the intuition for this, think which intervals should you not update? If you add anything less than $$$LSB(i)$$$ to $$$i$$$, the interval at that position will end before reaching $$$i$$$. So you need not update it.
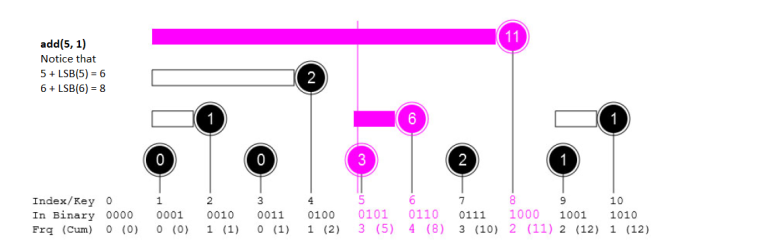
Let's implement it.
void add(int i, int cnt) {
while (i <= MAX_N) {
bit[i] += cnt;
i += i & -i;
}
}
That was easy! We now have everything from a data structure perspective to solve this infamous problem. The below code finds the $$$k^{th}$$$ order statistic by finding the position (element in multiset) which comes at the $$$k^{th}$$$ place in sorted order. As stated earlier, this is the smallest index $$$pos$$$ such that $$$\sum\limits_{i = 1}^{pos}{freq[i]} \gt = k$$$.
int findByOrder(int k) { // kth order statistic
int left = 1, right = MAX_N;
int pos = 0;
while (left <= right) {
int mid = (left + right) / 2;
if (sum(mid) >= k) {
pos = mid;
right = mid - 1;
} else left = mid + 1;
}
return pos;
}
The above code for findByOrder(int k) runs in $$$O(log(n) * log(n))$$$ which is good enough to get AC verdict. What if I tell you that there is a way to compute this function in $$$O(log(n))$$$ only? This is possible using the technique of binary expansion or binary lifting. This excellent blog by sdnr1 explains this in detail. Basically we search for the rightmost position which has a cumulative sum less than $$$k$$$. To do this, we iterate only on $$$log_2n$$$ indices and take advantage of the fact that the cumulative sum function is monotonically increasing. I suggest reading the blog for further clarity.
This brings us to the end of our short journey. I'd be glad if even one person got something out of this post.
My submission using Fenwick Tree: $$$O(nlog^2n)$$$ 80601530
Using Fenwick Tree with binary lifting: $$$O(nlog(n))$$$ 80603435
In the above submissions, you will find a template that you can modify as per your wish and store for later use.
The official editorial has an elegant solution using binary search that doesn't calculate the $$$k^{th}$$$ order statistic. It takes advantage of the fact that you need to show only one remaining node at the end. For a general use case, you still need to use either Fenwick trees, segment trees, treaps or some policy based data structures.
Thanks for reading!
UPDATE:
Q. How to build the Fenwick tree? (Filling array $$$bit$$$ at the beginning)
--> If you are given a multiset, as in this problem, iterate through all the elements and add 1 to its position (incrementing its count).
int A[6] = {4, 5, 2, 2, 3, 5} // Multiset
for (int i = 0; i < 6; i++)
add(A[i], 1);
// sum [L, R] = sum(R) - sum(L - 1); Returns count(L) + ... + count(R)
// sum [4, 5] = 3
--> If you are given an array and asked to do range sum queries on it, then treat the array as the frequency array from our discussion.
int A[6] = {0, 1, 3, 2, 5}; // Array on which we want to do range sum queries with updates
for (int i = 0; i < 5; i++)
add(i + 1, A[i]); // We are using 1-based indexing for BIT
// sum [L, R] on A => sum(L + 1, R + 1) = sum(R + 1) - sum(L); Returns A[L] + ... + A[R]
// sum [2, 4] = 3 + 2 + 5 = 10






