


When I first learn Möbius function, all the resources I found just explain everything algebraically (e.g. substitute $$$[\gcd = 1]$$$ using the identity $$$\sum\limits_{d | \gcd}\mu(d) = [\gcd = 1]$$$ when solving certain kind of gcd counting problem, then start to do a bunch of algebra and boom! the problem is solved, and I don't know why it works lol) which is not very motivated in my opinion. But after rethinking about it after solving this problem, I think I can shed some light on the motivation behind Möbius function, from a combinatorics perspective.
Definition of Möbius function
What a weird function? Why do we want to define something based on number of prime divisors and why do we want to let everything not square-free to be zero? You might ask.
But before I explain the motivation behind it, let's first recall how to find the sum of elements in a rectangular region of a 2D suffix sum array, for some reason. So we have the following problem now.
Problem: Given a 2D suffix sum array $$$g$$$ obtained from another 2D array $$$f$$$, i.e. $$$g(i, j) = \sum\limits_{i' \ge i}\sum\limits_{j' \ge j}f(i', j')$$$, and a query $$$(l, r, d, u) (l \le r, d \le u)$$$, find the sum of elements in the respective rectangular region $$$[l, r] \times [d, u]$$$ of $$$f$$$, i.e. $$$\sum\limits_{i = l}^r\sum\limits_{j = d}^u f(i, j)$$$.
Solution: We can solve the above problem by adding the region $$$[l, -] \times [d, -]$$$, excluding $$$[r + 1, -] \times [d, -]$$$ and $$$[l, -] \times [u + 1, -]$$$ then adding $$$[r + 1, u + 1]$$$ back. So the answer is just $$$g(l, d) - g(r + 1, d) - g(l, u + 1) + g(r + 1, u + 1)$$$.
Ok, but how does this problem related to Möbius function? Isn't we have some prime divisor stuff at the beginning?
Actually, we can map natural number to an array with infinite dimensions, where the $$$k$$$-th dimension correspond to the count of $$$k$$$-th prime of certain number's prime factorization. For example, when $$$x = 20 = 2^2 \times 5^1$$$, its corresponding position in the array is $$$(2, 0, 1, 0, 0, \ldots)$$$ because $$$20$$$ have two $$$2$$$, zero $$$3$$$, one $$$5$$$, etc...
I would call such mapping from natural numbers to multidimension array "prime factorization mapping" in the rest of the article.
For convenience, let's assume we only have two dimension now. That is, we only consider natural numbers whose prime divisors are only $$$2$$$ or/and $$$3$$$. The following picture gives an example on how these natural numbers correspond to each position.
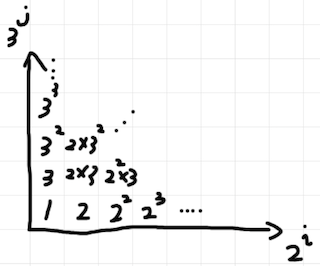
We can found that for a fix $$$(i, j)$$$, $$$2^i \times 3^j$$$ would divide $$$2^k \times 3^l$$$ if and only if $$$i \le k, j \le l$$$ hold. Thus the $$$k$$$-th entry of suffix sum array should contain everything that is multiple of $$$k$$$ and the rectangular region $$$[l, r] \times [d, u]$$$ would correspond to all natural numbers divisible by $$$2^l \times 3^d$$$, but not divisible by $$$2^{r + 1}$$$ and $$$3^{u + 1}$$$. So if we repharse the above problem in the context of "prime factorization mapping", we would get the following problem.
Problem: Given a suffix sum array $$$g$$$ obtained from another array $$$f$$$, where the suffix sum is defined in the manner of divisibility, i.e. $$$g_n = \sum\limits_{n | m}f(m)$$$, and a query $$$(l, r, d, u) (0 \le l \le r, 0 \le d \le u)$$$, find the sum of elements in the entries divisible by $$$2^l \times 3^d$$$ but not divisible by $$$2^{r + 1}$$$ and $$$3^{u + 1}$$$, i.e. $$$\sum\limits_{(i, j) \in [l, r] \times [d, u]}f(2^i3^j)$$$.
Solution: By similar logic, we can add everything that is multiple of $$$2^l3^d$$$ then excluding everything that is multiple of $$$2^{r + 1}3^d$$$ and $$$2^l3^{u + 1}$$$ then adding everything that is multiple of $$$2^{r + 1}3^{u + 1}$$$ back. So the answer is $$$g(2^l3^d) - g(2^{r + 1}3^d) - g(2^l3^{u + 1}) + g(2^{r + 1}3^{u + 1})$$$.
Now let's consider a variation of above problem, where $$$l = r, d = u$$$ hold, and the dimension of "prime factorization mapping" become infinite, so we can generalize things to all natural number instead of numbers with prime factors $$$\in \{2, 3\}$$$.
Problem: Given a suffix sum array $$$g$$$ obtained from another array $$$f$$$, where the suffix sum is defined by the divisibility relation, i.e. $$$g(n) = \sum\limits_{n | m}f(m)$$$, and a query $$$n$$$, find $$$f(n)$$$.
Solution: Similar to above problems, except we have infinite dimension rather than 2 dimension. So we can add everything that is multiple of $$$n$$$, excluding everything that is multiple of $$$2n, 3n, 5n\ldots$$$ then adding multiple of $$$2\times 3n, 2\times 5n, 2\times 7n, \ldots, 3\times 5n, 3 \times 7n\ldots$$$ etc. Then the answer would be $$$\sum\limits_{r \in \mathbb{N}}g(rn)[r \text{ don't have duplicate prime factor}](-1)^{\text{number of prime factors } r \text{ have}}$$$, by the inclusion-exclusion principle.
If you can't convince yourself the above solution is correct, let's recall how we solve the first version of problem, and imagine we have a $$$3$$$ dimension array with axis correspond to prime factors $$$2, 3, 5$$$, then what we are doing above is just take all elements that are multiple of $$$n$$$, then excluding red blocks (multiple of $$$2n, 3n, 5n$$$), adding blue blocks (multiple of $$$2\times 3 n, 2 \times 5 n, 3 \times 5 n$$$) then excluding the purple block (multiple of $$$2\times 3 \times 5 n$$$) in the following pictures
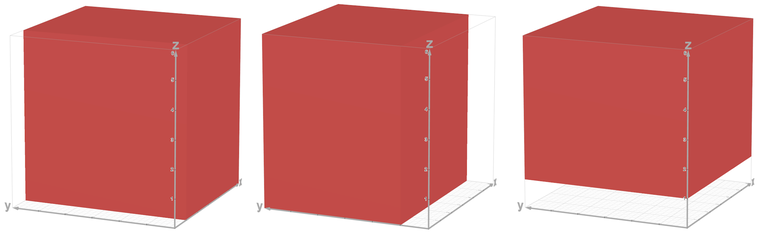
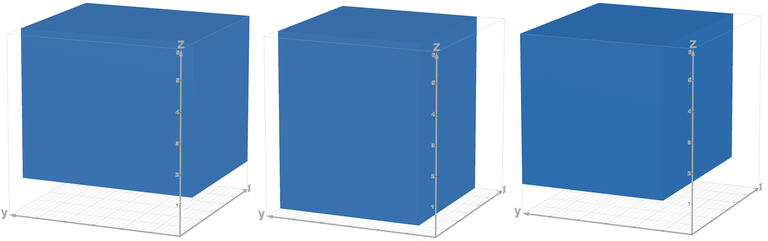
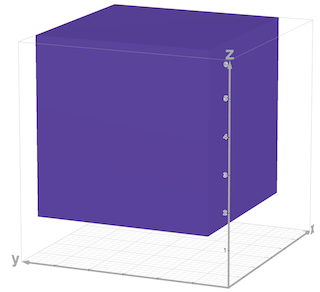
(I can't find a 3D graphic renderer draws better than this, sorry. But you got the idea.)
And one can find that, this is equivalent to $$$\sum\limits_{r \in \mathbb{N}}g(rn)\mu(r)$$$. Then it become quite motivated why we want to define $$$\mu$$$ like that. It's just a convenient function for us to do inclusion-exclusion for the suffix sum array with divisibility relation. Btw, this is what you would get when using the substitution $$$\sum\limits_{d | \gcd}\mu(d) = [\gcd = 1]$$$ if you know what it is.
Now let's talk about another thing related to Möbius function.
the Möbius inversion formula
Let $$$f, g$$$ be a function defined on natural number, and $$$g$$$ satisfy
for every $$$n \in \mathbb{N}$$$, then
holds for every $$$n \in \mathbb{N}$$$.
Again, let's consider everything under the context of "prime factorization mapping". the first equation is esentially tell us $$$g$$$ is obtained by doing prefix sum on $$$f$$$ under divisibility relation, so we can relate it to the following problem.
Problem: Given a prefix sum array $$$g$$$ obtained from another array $$$f$$$, where the prefix sum is defined by the divisibility relation, i.e. $$$g(n) = \sum\limits_{d | n}f(d)$$$, and a query $$$n$$$, find $$$f(n)$$$.
Solution: the only difference compared to previous problem is we got the prefix sum array instead of suffix sum array, so the solution is almost the same, i.e. add everything that is divisor of $$$n$$$, exclude everything that is divisor of $$$\frac{n}{d}$$$ for every prime divisor $$$d$$$ of $$$n$$$, then adding everything that is divisor of $$$\frac{n}{d_1d_2}$$$ for every prime divisor $$$d_1 \neq d_2$$$ of $$$n$$$, etc. In other word, the answer is $$$\sum\limits_{d | n} g(\frac{n}{d})[d \text{ don't have duplicate prime factor}](-1)^{\text{number of prime factors } d \text{ have}}$$$, which is equivalent to $$$\sum\limits_{d | n}g(\frac{n}{d})\mu(d)$$$, then you can find that, again, $$$\mu$$$ is just a convenient function for us to do inclusion-exclusion for the prefix sum array with divisibility relation.
And again, you can refer above 3D block picture, rotate it by $$$180$$$ degree to convience yourself this is correct.
wrap-up
So in conclusion, the Möbius function and Möbius inversion formula is just doing inclusion-exclusion on the prefix/suffix sum array under divisibility relation.
And if you wonder why we want to do such thing, well, in some circumstance, it's easier to find the prefix/suffix sum array compared to finding the original array directly, if you wonder what's the exact circumstance, I refer you to another blog about Möbius function, which contain a few related problems, but now you can solve it while having intuition on what and why are you doing exactly in each step!
Finally I invite you to challenge the problem mentioned in the beginning, and I would leave a few hint if you need.







{kind=link}