In many data structures, the operation of "undo" on the last update can be implemented easily: we can (usually) maintain a stack of the updates, where each update on the stack holds the memory cells it changed, and their original values. To undo an operation, just revert all changes from the top update on the stack. To maintain good complexity, we require the updates to operate in non-amortized time. I've seen this being used multiple times on DSU (without path compression).
If we imagine the updates as a sequence, then we can push an update to the end, and pop an update from the end by undo. Then, this sequence is a stack of updates. Here we discuss the idea of having a queue of updates: we can add a new update, or undo the oldest update still active. Specifically, this blogpost attempts to solve the following problem:
Given a data structure that can support some updates, some queries and an "undo" operation (each with their own time complexity), how can we create a data structure that supports the same updates and queries, but its undo operation works like a queue (and we don't support a stack-like undo in the new one)? And of course, creating such a data structure that adds the smallest time complexity factor we can.
Well, this is almost what this post discusses; I require the DS to have another property, which I'll call "commutativity". The best way to put it is probably: A data structure is commutative if for any sequence of updates, and a query afterwards, the result we want from the query remains the same, regardless of how we order those updates. This property holds in DSU (which was the motivation for this post): For any sequence of adding edges, after which we query whether two nodes are in the same component, the query result doesn't change for any order of edge additions. However, if the DSU query asks for the specific root of the node we query on, then this result depends on the order of edge additions, and also on the implementation. I think this query is less interesting anyway.
A data structure this won't work on is, for example, a segment tree with the update of "set in range", since the order of updates matters. Perhaps this specific DS can support queue undoing with a different algorithm, but here we discuss a general commutative data structure.
A few more notes: We build a DS from a commutative DS. We don't require any other constraint on the original DS (we don't care if its complexities are amortized, this includes the complexity of its undo operation). The data structure we create will work in amortized time, and it will also be online (which was a main purpose). Finally, I've never heard about this anywhere, yet I wouldn't be surprised if this idea is well known in China.
The Idea
Let $$$S$$$ be the stack of updates, which is initially empty. We begin by receiving updates which fill up $$$S$$$, until the first undo. What we do now, is reversing $$$S$$$: we undo all the updates and redo them in reverse order. We use commutativity here which ensures this reversal is fine. Now, to undo the first operation, we just call the undo operation on the original data structure: it pops the topmost element of $$$S$$$ which is the first update. In an ideal world, we'd hope that we only receive undo's until the stack is empty, but it is probably the case that we'll get both new updates and undoing: We must push new updates into $$$S$$$, but also must be able to pop old updates, so we have to somehow interleave new updates and old updates. We'll call this "The Stack Problem", which is the main roadblock.
The Stack Problem
We'll consider the stack problem in the following way: we have a stack $$$S$$$ of $$$n$$$ letters $$$A$$$, which represent old updates we need to pop (even while denoted the same, these $$$A$$$'s are different updates... but we don't care about their difference, we just need to remove them in order from topmost to bottommost). On $$$S$$$ we can get 2 types of operations: either pop an $$$A$$$, or add a $$$B$$$, which represents a new update. We will assume there are a total of $$$2n$$$ operations; $$$n$$$ which pop $$$A$$$ and $$$n$$$ which add $$$B$$$, and these arrive online. What we really care about is the number of $$$A$$$'s and the number of $$$B$$$'s in $$$S$$$: when we're asked to pop an $$$A$$$, we modify $$$S$$$ so that the number of $$$A$$$'s decreases by 1, and symmetrically for adding a $$$B$$$. At the end we should have a stack of only $$$B$$$'s.
You might have noticed we assume there will be exactly $$$n$$$ new updates before we pop exactly $$$n$$$ old updates. This is just to ease on solving the stack problem, and we'll later see this assumption makes no asymptotic difference.
We assume that an operation of push or pop on $$$S$$$ take $$$\mathcal{O}(1)$$$, since we care for now about minimizing stack operations. If we solve this problem in time complexity $$$\mathcal{O}(n \cdot f(n))$$$, consider this as duplicating every update and undo, $$$\mathcal{O}(f(n))$$$ times. Following is an algorithm in $$$\mathcal{O}(n \log n)$$$ time.
Solving The Stack Problem
This will be our algorithm:
- When provided a $$$B$$$ update (add B), we just push it to the top of $$$S$$$.
- When provided an $$$A$$$ update: If $$$S$$$ already had $$$A$$$ on top, we just pop. Otherwise, we begin the following process (which I'll call "fixing"): pop from $$$S$$$ and save all the elements we popped, until we popped an equal amount of $$$A$$$'s and $$$B$$$'s, or until no $$$A$$$'s remain in the stack; empty stack or only $$$B$$$'s remain (we can keep an index of this position in the stack, which will only increase). Then, push back all the elements we popped, where we first push all $$$B$$$'s, then all $$$A$$$'s (we use commutativity here). Since the top of $$$S$$$ had a $$$B$$$, and we were asked to pop an existing $$$A$$$, after fixing, the topmost element will be an $$$A$$$ which we pop.
Let's show an upperbound of $$$\mathcal{O}(n \log n)$$$ time on this algorithm. This actually might be interesting for those who want to try, before opening the spoiler:
UpperboundWe'll consider the cost of fixing as the number of $$$B$$$'s we popped and saved before we returned them. Regardless of whether we terminated because no $$$A$$$'s remained in $$$S$$$, or had an equal amount of $$$A$$$'s, the time complexity of a fix is asymptotically equal to its cost. However, I'd like to say that the number of $$$A$$$'s and $$$B$$$'s we fixed is equal, since terminating early is kind of a corner case: if we had $$$k$$$ more $$$B$$$'s than $$$A$$$'s, we add $$$k$$$ $$$B$$$'s to the bottom of the stack, which we will never touch again, and the total number of $$$B$$$'s (sum of $$$k$$$'s) we put at the bottom is at most $$$n$$$, which is negligible to the total time complexity. So let's assume that each fix reorders the same amount of $$$A$$$'s and $$$B$$$'s (for example assume that the stack had an infinite number of $$$A$$$'s while we only pop $$$n$$$).
Also, the total time complexity of the algorithm is equal to the sum of all the fixing costs, so we just bound that sum.
Let $$$O_1, ..., O_{2n}$$$ be the sequence of $$$2n$$$ operations we recieved (each of those is either $$$A$$$ or $$$B$$$). Let $$$x_i$$$ denote the fixing cost of $$$O_i$$$: if $$$O_i$$$ is of type $$$B$$$, then $$$x_i = 0$$$ as there was no fix. Otherwise $$$x_i$$$ is the actual fixing cost (which could be 0 if $$$A$$$ was on top).
Observation: for any $$$1 \leq i \lt j \leq 2n$$$, and any natural $$$k \geq 1$$$, suppose we have both $$$x_i \geq k$$$ and $$$x_j \geq k$$$. Then $$$j - i \gt k$$$.
ProofIndeed, if $$$x_i \geq k$$$, then after $$$O_i$$$ we had at least $$$k$$$ $$$A$$$'s at the top of the stack. After this block of $$$A$$$'s (below it), we have a block of at least $$$k$$$ $$$B$$$'s on the stack. If we look at the elements of the stack above this block of $$$B$$$'s, it begins with at least $$$k$$$ $$$A$$$'s, and while no fixing reaches this block of $$$B$$$'s, the following invariant holds: within the elements above the block of $$$B$$$, every operation decreases the difference between the number of $$$A$$$'s and the number of $$$B$$$'s, by exactly 1; we either add a $$$B$$$ there or remove an $$$A$$$ there.
So, at operation $$$j$$$, we the cost of fixing was at least $$$k$$$. If the fixing reached the block of $$$B$$$'s, we know that the mentioned difference above it had to be negative, for the fixing process to reach (because of the terminating condition). This difference begins with at least $$$k$$$ and decreases by 1 every time, since no operation between $$$O_i$$$ and $$$O_j$$$ ever fixed this block of $$$B$$$'s (we can assume that all costs between $$$O_i, O_j$$$ were less than $$$k$$$ for the proof, which implies none of these reached the block). So in this case we require at least $$$k+1$$$ operations before a fix reaches the block.
In the other case, $$$O_j$$$ fixed without reaching that block; so we always stayed above the block, and we fixed at least $$$k$$$ $$$B$$$'s, which means we pushed at least $$$k$$$ $$$B$$$'s between $$$O_i, O_j$$$.
Finally, if we denote $$$y_k$$$ as the number of $$$i$$$ such that $$$x_i \geq k$$$, then this implies that $$$y_k \leq \frac{2n}{k}$$$, so: $$$\sum_{i=1}^{2n}x_i = \sum_{j=1}^{2n}y_j \leq \sum_{j=1}^{2n}\frac{2n}{j} = \mathcal{O}(n \log n)$$$
But, can this algorithm be better than $$$\mathcal{O}(n \log n)$$$ in worstcase? Well... no. In the case where the operations are $$$BABA...BA$$$ (alternating between adding $$$B$$$ and popping $$$A$$$, we'll return to this case later), this algorithm takes $$$\Theta(n \log n)$$$ time (the sequence of positive fixing costs is 1, 2, 1, 4, 1, 2, 1, 8, ..., basically cost $$$i$$$ equals to the least significant bit of $$$i$$$).
The Idea, Cont.
As mentioned, we begin by pushing updates into $$$S$$$ until the first undo operation. Suppose at this time, the number of updates in $$$S$$$ was $$$s_1$$$. So we did $$$s_1$$$ updates, then we do $$$s_1$$$ undo's (on the original structure), and insert these back in reverse order, which is another $$$s_1$$$ updates (asymptotically the same). Now we execute our algorithm for the stack problem, as long as the last of the first $$$s_1$$$ updates still exists. Suppose once we undo the last of those, $$$S$$$ contains $$$s_2$$$ new updates.
Even though $$$s_1, s_2$$$ might not be equal, the proposed algorithm is still well defined. As for its complexity, we can give a simple upperbound that is tight on the worstcase: if we denote $$$n = s_1 + s_2$$$, any sequence of operations that begins with $$$s_1$$$ $$$A$$$'s and ends with $$$s_2$$$ $$$B$$$'s, is a prefix of some sequence of operations where we start with $$$n$$$ $$$A$$$'s and end with $$$n$$$ $$$B$$$'s, which takes $$$\mathcal{O}(n \log n)$$$, so we can bound by $$$\mathcal{O}((s_1 + s_2) \log (s_1 + s_2))$$$, tight when $$$s_1 = s_2$$$.
Anyway, once $$$S$$$ contains these $$$s_2$$$ new updates (which we can also assume are ordered by the order we received them), we can again reverse $$$S$$$, and begin our algorithm again until we get $$$s_3$$$ new updates, and so on.
If we had a total of $$$U$$$ updates (and upto $$$U$$$ undo's between them) asked of us, and we had $$$k$$$ "phases" of the algorithm ($$$s_1$$$ through $$$s_k$$$), then $$$U = \sum_{i=1}^{k}s_i$$$, and our time complexity in terms of push and pop into $$$S$$$:
- Across all reversals of $$$S$$$ we take $$$\mathcal{O}(\sum_{i=1}^{k}s_i) = \mathcal{O}(U)$$$.
- Across all executions of the algorithm we take $$$\mathcal{O}(\sum_{i=1}^{k-1}(s_i + s_{i+1}) \log (s_i + s_{i+1}))$$$, bounded by $$$\mathcal{O}(U \log U)$$$.
In total we take $$$\mathcal{O}(U \log U)$$$ operations on $$$S$$$: in other words, if our original data structure operated in $$$\mathcal{O}(f(U))$$$ for any sequence of $$$U$$$ operations (including undo's), then we support queue-undo's for any sequence of $$$U$$$ operations in time $$$\mathcal{O}(f(U \log U))$$$, which in most cases would imply we add a logarithmic factor to our total complexity.
Can We Do Better?
A logarithmic factor is small, but not constant. I suppose usually our original structure would have its updates run in $$$\mathcal{O}(\log n)$$$, which now becomes $$$\mathcal{O}(\log n \cdot \log U)$$$, and that's not too small...
So, can we do better than an $$$\mathcal{O}(\log U)$$$ factor? Well, for a general commutative DS (without any more assumptions), the answer is a sad no.
If we only assume a general commutative DS, we can't do any funny tricks; after each update or undo, the stack of updates of the original DS must hold exactly all the active updates. The following attempts to prove that we cannot achieve all these states of the stack in $$$\mathcal{o}(U \log U)$$$ stack operations. Some parts of this might be informal, and if it fails there I would happily hear someone point this out... I want a better factor.
First, let's define a similar problem, which we'll conveniently name $$$P$$$: Given a positive integer $$$n$$$ and an empty stack $$$S$$$, all operations we're able to do are push and pop $$$A$$$'s and $$$B$$$'s into $$$S$$$. Define the state of the stack as a pair (number of A's, number of B's). Then our goal is to pass through states $$$(n, 0), (n-1, 1), (n-2, 2), \dots, (0, n)$$$, in this order, while minimizing the number of operations. (note that for problem $$$P$$$ of order $$$n$$$ we have $$$n+1$$$ states... don't get confused with off by 1's).
We recursively define the optimal algorithm for problem $$$P$$$: Let $$$T(n)$$$ be the minimum number of operations required for problem $$$P$$$ of order $$$n$$$, with $$$T(0) = 0$$$.
A few observations on the optimal algorithm:
- It must begin by pushing $$$A$$$, since the first state we need to visit is $$$(n, 0)$$$, so if we were to push a $$$B$$$ at the start, we would end up popping it without reaching any state.
- At some moment, this $$$A$$$ at the bottom of $$$S$$$ must be replaced with $$$B$$$ since we must visit $$$(0, n)$$$ at the end. Informally I claim, that once we put the $$$B$$$ at the bottom, we never pop it again. A formal proof can probably use some exchange argument; we visited some states after we put the first $$$B$$$ at the bottom, then some more states after the second $$$A$$$ at the bottom and at some point we put a $$$B$$$ at the bottom again. So all the states visited by the first $$$B$$$ could be visited by the first $$$A$$$ with less operations, as we merge all states visited by the first $$$A$$$, first $$$B$$$ and second $$$A$$$.
So the optimal algorithm is split to two phases; an $$$A$$$ at the bottom and a $$$B$$$ at the bottom. This implies there exists some $$$1 \leq k \leq n$$$ such that we visit the first $$$k$$$ states in the first phase, and the rest $$$n+1-k$$$ states in the second phase. We can analyze how the algorithm works for any $$$k$$$ and choose the best $$$k$$$:
Now it's informal, but can probably be proven with an ugly exchange argument; for a fixed $$$k$$$, what the algorithm does is:
- At the beginning, push $$$n-k+1$$$ $$$A$$$'s into $$$S$$$.
- From this point, recursively solve a subproblem of order $$$k-1$$$, which takes $$$T(k-1)$$$ operations.
- Pop the entire stack, which is $$$n$$$ operations.
- Push $$$k$$$ $$$B$$$'s into $$$S$$$.
- From this point, recursively solve a subproblem of order $$$n-k$$$, which takes $$$T(n-k)$$$ operations.
So this running time is $$$2n+1 + T(k-1) + T(n-k)$$$. minimizing across all $$$k$$$, we get the equation:
$$$T(n) = \mathcal{O}(n) + \min_{1 \leq k \leq n}(T(k-1) + T(n-k))$$$This achieves minimum when $$$k = \frac{n}{2}$$$, resulting in $$$T(n) = \Theta(n \log n)$$$, so the optimal running time for $$$P$$$ is $$$\Theta(n \log n)$$$.
Back to our original problem; Let $$$A$$$ be an algorithm that can handle $$$n$$$ updates and $$$n$$$ undo's in running time $$$\mathcal{O}(f(n))$$$. Specifically, the following scenario is also solved in $$$\mathcal{O}(f(n))$$$: push $$$\frac{n}{2}$$$ updates, then alternate between pushing an update and undoing an update.
(Informally?) If no further assumptions are made on the updates, we must be able to operate on the stack of updates $$$S$$$, so that after each update or undo, exactly those updates that are active, should be in $$$S$$$. Now one can see that, if we name the first $$$\frac{n}{2}$$$ updates as $$$A$$$'s and the new ones as $$$B$$$'s, we pass through states $$$(\frac{n}{2}, 0), \dots, (0, \frac{n}{2})$$$. So algorithm $$$A$$$ can generate a solution to problem $$$P$$$ of order $$$\frac{n}{2}$$$ in running time $$$\mathcal{O}(n + f(n)) = \mathcal{O}(f(n))$$$ (we add $$$n$$$ since in problem $$$P$$$ we begin with an empty stack).
This implies we can solve $$$P$$$ of order $$$\frac{n}{2}$$$ in $$$\mathcal{O}(f(n))$$$ operations, but by the optimality we've shown on $$$P$$$, we get $$$f(n) = \Omega(n \log n)$$$.
Open Questions
Although we showed some kind of optimality in a general case, there are still open questions for improvement:
- If the data structure supports different updates in different complexities, can we prioritize some updates over others? Our algorithm does overall $$$\mathcal{O}(U \log U)$$$ stack operations, but it could be that some updates get called many times and some get called only a few times. Perhaps a weight function on each update in the stack, and a variant of the fixing process?
- Can a similar algorithm be applied with less assumptions (for instance, no commutativity)?
- Can a similar algorithm be applied with more assumptions, and better running time? Perhaps the same algorithm can be proven to have better running time on specific scenarios?
I've yet to try answering any of these.
Examples
My motivation problem is supporting the queue of updates on DSU (LCT probably defeats this purpose with even better complexity, so I was looking for something more general and simple). We can use it to solve this problem online in running time $$$\mathcal{O}(n \log n \log q)$$$. There also exist an offline D&C algorithm where we have monotonicity (corresponds to queue undoing), and a cool offline algorithm here where we compute for each update its "living time", split these intervals across a segment tree and perform a DFS on it (this is offline, but it doesn't even require the undoing to be in any form of stack or queue).
If I had to come up with another problem... Given an array of length $$$n$$$ of integers, an update provides $$$(l, r, x)$$$ to set all $$$A_i = \min(A_i, x)$$$ for $$$l \leq i \leq r$$$, and a query could ask for maximum in range. These updates are commutative so we could apply the idea on a lazy segment tree.
Another example could be 1386C, from BOI. Here it is interesting, because we can use the idea to solve the problem, even though we don't explicitly take a DS and modify it; we can add all edges from $$$i = 1$$$ to $$$i = n$$$, then proceed by either undoing an update from the suffix, or doing an update from the prefix.
I haven't seen many instances where this can be applied, but it's probably not difficult to come up with such. If you remember problems that can utilize this, link them in the comments.
Implementation
I was wondering if we can have a C++ generic implementation, probably using inheritance, but I don't know enough of it to come up with such. Can you find any? Maybe in another language?
Anyway, here is an implementation (of DSU-queue), solving 1386C in time $$$\mathcal{O}(m \log n \log m)$$$. Hovering over all tests, the worstcase running time was 358ms, which is actually faster than I expected. Either the constant is small or there happens to be no testcase that hits us hard (like some alternating case).
Edit: bicsi has another implementation here, using a few clean tricks to cut down implementation size. This implementation also removes some amortization, explained in his comment here.
Thanks for reading :)








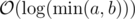 .
.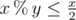 . This is due to:
. This is due to: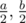 respectively. Once one of them becomes 0 the algorithm terminates, so the algorithm terminates in at most
respectively. Once one of them becomes 0 the algorithm terminates, so the algorithm terminates in at most 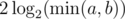 , which implies
, which implies 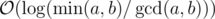
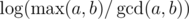 , and lastly notice that we can change the maximum to minimum, since after one step of the algorithm the current maximum is the previous minimum;
, and lastly notice that we can change the maximum to minimum, since after one step of the algorithm the current maximum is the previous minimum; 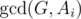 . The known time complexity analysis gives us the bound of
. The known time complexity analysis gives us the bound of 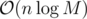 , for computing gcd
, for computing gcd 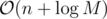 (for practical values of
(for practical values of  ). Why is that so? again, we can determine the time complexity more carefully:
). Why is that so? again, we can determine the time complexity more carefully: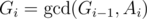
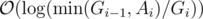 , which is worstcase
, which is worstcase 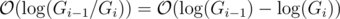 , so we will assume it's the latter.
, so we will assume it's the latter.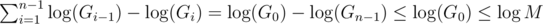
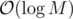 .
.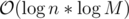 per query or update. We can use (1) to give
per query or update. We can use (1) to give 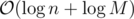 ; an update consists of a starting value, and repeatedly for
; an update consists of a starting value, and repeatedly for  steps we assign to it its gcd with some other value. Following (1), this takes the desired complexity. The same analysis is done for queries.
steps we assign to it its gcd with some other value. Following (1), this takes the desired complexity. The same analysis is done for queries.
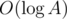 , where
, where 