


Thank you for participating and accompanying Simons! We hope you enjoyed the problems.
| A | B | C | D | E | F | G | |
|---|---|---|---|---|---|---|---|
| Leftist_G | 800 | 800 | 1400 | 2000 | 2400 | 2600 | 2900 |
| cool_milo | 800 | 800 | 1400 | 1800 | 2400 | 2700 | 3300 |
| StayAlone | 800 | 900 | 1500 | 1900 | 2300 | 2200 | 2800 |
| liuhangxin | 800 | 900 | 1000 | 1300 | 2500 | 3100 | |
| _istil | 800 | 1000 | 1400 | 1600 | 2100 | 2400 | 2600 |
| Error_Yuan | 800 | 1000 | 1400 | 1800 | 2100 | 2400 | 2600 |
| yanghanyv | 800 | 900 | 1300 | 1400 | 1900 | ||
| Comentropy | 800 | 1000 | 1600 | 1600 | 2300 | ||
| wangzirui123 | 800 | 1000 | 1700 | 2000 | 2600 | 2100 | 2900 |
| A | B | C | D | E | F | G | |
|---|---|---|---|---|---|---|---|
| Average | 800 | 922 | 1411 | 1711 | 2317 | 2344 | 2886 |
2205A — Simons and Making It Beautiful
Author: StayAlone
Solution: StayAlone
Which index is always ugly?
Consider the lower bound of the answer.
Observe that index $$$n$$$ is always ugly, so the answer is at least $$$1$$$.
It remains to show that this lower bound is achievable.
Set $$$p_1\gets n$$$ so that for each $$$i$$$, $$$\max(p_1,p_2,\cdots,p_i)=n$$$. As a result, the only ugly index is $$$n$$$.
By StayAlone.
#include <bits/stdc++.h>
using namespace std;
int n, a[505];
void solve() {
cin >> n;
for(int i = 1; i <= n; i++) {
cin >> a[i];
if (a[i] == n) swap(a[1], a[i]);
}
for(int i = 1; i <= n; i++) printf("%d ", a[i]); puts("");
}
int main() {
int T;
cin >> T;
for (; T--; ) solve();
return 0;
}
2205B — Simons and Cakes for Success
Author: Leftist_G
Solution: Leftist_G
Consider the prime decomposition of the given $$$n$$$.
$$$n$$$ has at most $$$1$$$ prime divisor not smaller than $$$\sqrt n$$$.
Let $$$n=\prod p_i^{\alpha_i}$$$ be the prime factorization of $$$n$$$. Hence, if $$$n$$$ is a divisor of $$$k^n$$$, each $$$p_i$$$ must be a divisor of $$$k^n$$$ and then $$$k$$$.
Under constraints above, the minimum valid number is $$$k=\prod p_i$$$. Due to $$$\alpha_i\le n$$$, each $$$p_i^{\alpha_i}$$$ will be a divisor of $$$p_i^n$$$, so $$$n$$$ is a divisor of $$$k^n$$$.
Thus, we only need to find $$$\prod p_i$$$. Because $$$n$$$ has at most $$$1$$$ prime divisor not smaller than $$$\sqrt n$$$, we only need to check the prime numbers smaller than $$$\sqrt n$$$, and the remaining part is $$$1$$$ or the only prime divisor bigger than $$$\sqrt n$$$.
So we solve the problem in $$$\mathcal O(\sqrt n)$$$.
By Leftist_G.
#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10;
int tc;
int n;
vector <int> pr;
bool vis[N];
void init(int n = 31623){
for(int i = 2; i <= n; i++){
if(!vis[i]) pr.push_back(i);
for(auto j: pr){
if(i * j > n) break;
vis[i * j]=1;
if(i % j == 0) break;
}
}
}
void solve(){
cin>>n;
int ans = 1;
for(auto i: pr){
if(n % i == 0){
ans *= i;
while(n % i == 0) n /= i;
}
}
ans *= n;
cout << ans << '\n';
}
int main(){
ios::sync_with_stdio(false);
init();
cin >> tc;
while(tc--) solve();
}
By StayAlone.
import sys
import math
def read_int():
return int(sys.stdin.readline().strip())
def solve():
n = read_int()
ans = 1
for i in range(2, int(math.sqrt(n)) + 1):
if n % i == 0:
ans *= i
while n % i == 0:
n //= i
print(ans * n)
T = read_int()
for _ in range(T):
solve()
2205C — Simons and Posting Blogs
Author: Leftist_G
Solution: Leftist_G
For an array $$$a_i$$$, only the last occurrence of each element matters. Therefore, the problem reduces to the case where all elements in one array are distinct.
Think the process in reverse.
Also, throughout the whole process, only the last occurrence of each element matters, so we may determine the order by working backwards.
Fix an order (in reverse). For each array in this order, we iterate through its elements. If an element is already contained in $$$Q$$$, ignore it. Otherwise, append it to the end of $$$Q$$$.
Thus, at each step, we choose the array that is lexicographically smallest among the remaining ones. Then, for the remaining arrays, we only keep the elements that are not contained in $$$Q$$$. Comparing two arrays takes $$$\mathcal O(\min{|a_i|, |a_j|})$$$, we can solve the problem with total time complexity $$$\mathcal O(n^2+n\sum l_i)$$$.
By StayAlone.
#include <bits/stdc++.h>
#define rep1(i, l, r) for (int i = l; i <= int(r); ++i)
using namespace std;
const int MAXN = 1e6 + 10, inf = ~0U >> 2;
int n, vis[MAXN], chg[8010]; vector <int> a[8010];
void init(vector <int> &now) {
for (auto &v : now) cin >> v, vis[v] = 0;
reverse(begin(now), end(now));
vector <int> nw;
for (auto v : now) if (!vis[v]) nw.emplace_back(v), vis[v] = 1;
for (auto v : nw) vis[v] = 0;
now = nw;
}
void change(vector <int> &now) {
if (now.size() == 1 && now[0] == inf) return;
vector <int> nw;
for (auto v : now) if (!vis[v]) nw.emplace_back(v);
now = nw;
}
void solve() {
cin >> n;
rep1(i, 1, n) {
int _;
cin >> _;
a[i].resize(_); init(a[i]); chg[i] = 0;
}
rep1(i, 1, n) {
int id = 1;
rep1(j, 1, n) if (!chg[j] && a[j] < a[id]) id = j;
auto &now = a[id];
for (auto v : now) printf("%d ", v), vis[v] = 1;
now = vector <int> {inf}; chg[id] = 1;
rep1(j, 1, n) if (!chg[j]) change(a[j]);
} puts("");
}
int main() {
int T;
cin >> T;
for (; T--; ) solve();
return 0;
}
2205D — Simons and Beating Peaks
Author: cool_milo
Solution: cool_milo, Leftist_G
Simons's goal of minimizing operations means that the remaining array should be as long as possible.
Which element is absolutely impossible to remove?
The position of the maximum value cannot be removed, and we can see that splitting the array from the maximum value will result in two independent parts.
Consider the Cartesian tree of the given permutation.
It's noticed that the maximum number of each number cannot be moved, and either the left side or the right side will be removed completely, so we can solve both sides separately.
The maximum number of both sides cannot be removed, either. Accordingly, they became the same problem with smaller scale.
Build the Cartesian tree for the sequence. It's easy to see that any path from the root corresponds to a way to keep the maximum number on one side and delete the others.
Calculate the depth of each node $$$d_u$$$, then the answer is $$$n - \max d_u$$$.
The solution could be done in $$$\Theta(n)$$$, and there are also solutions based on Dynamic Programming (DP) for time complexity $$$\tilde O(n)$$$.
By yanghanyv.
#include <bits/stdc++.h>
using namespace std;
const int N=5e5+5;
int t,n,a[N],del[N],stk[N],top,ans;
void init(){
for(int i=1;i<=n;i++){
del[i]=0;
}
ans=n;
}
int main(){
scanf("%d",&t);
while(t--){
scanf("%d",&n);
init();
for(int i=1;i<=n;i++){
scanf("%d",&a[i]);
}
top=0;
for(int i=1;i<=n;i++){
while(top&&a[stk[top]]<a[i]){
top--;
}
stk[++top]=i;
del[i]+=i-top;
}
top=0;
for(int i=n;i>=1;i--){
while(top&&a[stk[top]]<a[i]){
top--;
}
stk[++top]=i;
del[i]+=n-i+1-top;
}
for(int i=1;i<=n;i++){
ans=min(ans,del[i]);
}
printf("%d\n",ans);
}
return 0;
}
2205E — Simons and Dividing the Rhythm
Author: Leftist_G
Solution: Leftist_G
Consider applying Dynamic Programming (DP) to solve the problem. What may the state be?
Assign a unique way to operate $$$s$$$ to $$$t$$$ for every different $$$s$$$.
For any $$$[l_i, r_i]$$$ you chose, consider the border of $$$t_{[l_i, r_i]}$$$. A border of an array $$$a[1 \sim n]$$$ means the subarray $$$a[1,l]$$$ such that $$$a[1,l] = a[n - l + 1,n]$$$.
Let's apply Dynamic Programming to the problem.
Assume $$$dp_i$$$ represents the different arrays $$$s[1:i]$$$ can generate $$$t[1:i]$$$.
to update $$$dp_{i + 1}$$$, consider the last subarray in the decomposition $$$dp_{[a, i + 1]}$$$. To ensure no duplicate counting, $$$dp_{[a, i + 1]}$$$ can't have a border. Which is to say, for any $$$s$$$ which could be operated to $$$t$$$, it could be realized by decomposing $$$s$$$ into subarrays without a border and reversing them.
Why can the solution above calculate the answer correctly?
Recall that a border of an array $$$a[1 \sim n]$$$ means the subarray $$$a[1,l]$$$ such that $$$a[1,l] = a[n - l + 1,n]$$$.
For two different ways to operate $$$s$$$, assume the first different pair of decomposition of $$$s$$$ be $$$[l, r_1], [l, r_2] (r_1 \lt r_2)$$$, then $$$s_{[r_2 - r_1 + l, r_2]} = s_{[l, r_1]}$$$ since after flipping, they will be mapped to the same place in $$$t$$$. So $$$[l, r_2]$$$ has a border.
So by taking the shortest possible length of the next segment $$$[a, b]$$$ every time, we can find a solution without a border. (If there's a border $$$s_{[a, r]} = s_{[l, b]}$$$, we can show that the length of shortest border $$$B \lt \frac{b - a + 1}{2}$$$ . So $$$r \lt l$$$ holds. We could reverse $$$s_{[a, r]}, s_{[r + 1, l]}, s_{[l, b]}$$$ seperately to achieve the same goal.)
To check if any $$$dp_{[l, r]}$$$ has a border, we need to apply the KMP algorithm (starting from $$$t_{1 \sim n}$$$)for $$$n$$$ times, whose time complexity is $$$O(n^2)$$$. The dp progress also takes $$$O(n^2)$$$ time. So the total time complexity is $$$O(n^2)$$$.
By Leftist_G.
#include <bits/stdc++.h>
#define fr1(i, a, b) for (int i = a; i <= b; i++)
#define fr2(i, a, b) for (int i = a; i >= b; i--)
using namespace std;
const int N = 1e5 + 10;
const int mod = 998244353;
int tc;
int n;
int a[N];
int dp[N];
int kmp[N];
void add(int & x, int y) {
x += y;
if (x >= mod) x -= mod;
}
void solve() {
cin >> n;
fr1(i, 1, n) cin >> a[i];
dp[0] = 1;
fr1(i, 1, n) dp[i] = 0;
fr1(i, 1, n) {
kmp[i] = i + 1;
int poi = i + 1;
fr2(j, i - 1, 1) {
while (a[j] != a[poi - 1] && poi != i + 1) poi = kmp[poi];
if (a[j] == a[poi - 1]) poi--;
kmp[j] = poi;
}
fr2(j, i, 1) {
if (kmp[j] == i + 1) add(dp[i], dp[j - 1]);
}
}
cout << dp[n] << '\n';
}
int main() {
ios::sync_with_stdio(false);
cin >> tc;
while (tc--) solve();
}
2205F — Simons and Reconstructing His Roads
Solution: cool_milo, StayAlone
Consider the case without any "accidents", i.e., when there are no additional restrictions on the reconstructed streets.
Observe the structure of a valid solution and try to construct a kind of "basis".
We can define each basis as a square, and assign its value as follows:
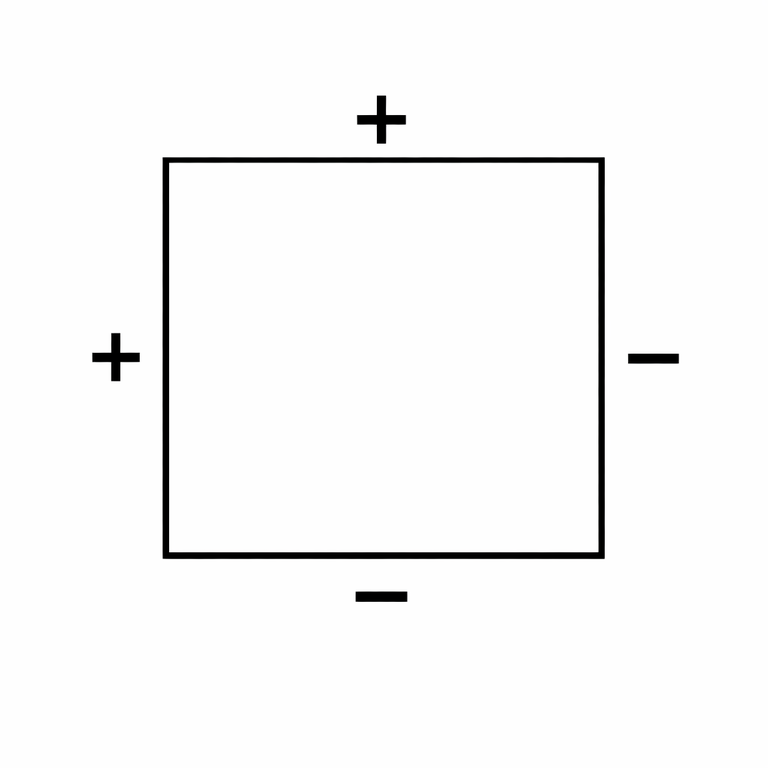
Now, it is easy to see that any subset of the bases forms a valid solution, and conversely, any valid solution can be decomposed into such bases.
Now consider a street that cannot be reconstructed. This implies that the two bases it connects must have the same state — either both are chosen, or both are not chosen. Therefore, we can use a DSU to maintain these constraints. The overall time complexity is $$$\mathcal O(nm\alpha(nm))$$$.
By yanghanyv.
#include <bits/stdc++.h>
#define ll long long
using namespace std;
const int N=2e5+5;
const int M=4e5+5;
int t,n,m,fa[M];
ll s[M],ans;
vector<int> w[N],v[N];
void init(){
for(int i=1;i<=n;i++){
w[i].clear();
v[i].clear();
}
for(int i=0;i<=(n-1)*(m-1);i++){
fa[i]=i;
s[i]=0;
}
ans=0;
}
int idx(int x,int y){
return x>=1&&x<n&&y>=1&&y<m?(x-1)*(m-1)+y:0;
}
int find(int x){
return fa[x]!=x?fa[x]=find(fa[x]):fa[x];
}
void merge(int a,int b){
if(find(a)!=find(b)){
fa[find(a)]=find(b);
}
}
int main(){
scanf("%d",&t);
while(t--){
scanf("%d%d",&n,&m);
init();
for(int i=1;i<n;i++){
w[i].resize(m+1);
for(int j=1;j<=m;j++){
scanf("%d",&w[i][j]);
}
}
for(int i=1;i<=n;i++){
v[i].resize(m);
for(int j=1;j<m;j++){
scanf("%d",&v[i][j]);
}
}
for(int i=1;i<n;i++){
for(int j=1;j<m;j++){
s[idx(i,j)]=1ll*w[i][j]-1ll*w[i][j+1]+1ll*v[i][j]-1ll*v[i+1][j];
}
}
for(int i=1;i<n;i++){
scanf("\n");
for(int j=1;j<=m;j++){
char p;
scanf("%c",&p);
if(p=='0'){
merge(idx(i,j-1),idx(i,j));
}
}
}
for(int i=1;i<=n;i++){
scanf("\n");
for(int j=1;j<m;j++){
char q;
scanf("%c",&q);
if(q=='0'){
merge(idx(i-1,j),idx(i,j));
}
}
}
for(int i=1;i<=(n-1)*(m-1);i++){
if(find(i)!=i&&find(i)!=find(0)){
s[find(i)]+=s[i];
}
}
for(int i=1;i<=(n-1)*(m-1);i++){
if(find(i)==i&&find(i)!=find(0)){
ans+=max(s[i],0ll);
}
}
printf("%lld\n",ans);
}
return 0;
}
2205G — Simons and Diophantus Equation
Author: Leftist_G
Solution: cool_milo, LiHn, liuhangxin, Leftist_G
The equation has an integral solution if and only if $$$\gcd(i\oplus j,j\oplus k)$$$ is a divisor of $$$n$$$. This is a famous theorem, called Bézout's theorem.
Considering enumerating $$$g=\gcd(i\oplus j,j\oplus k)$$$, then we calculate how many tuples $$$(i,j,k)$$$ can exactly get this $$$g$$$.
Consider Möbius inversion formula. There is a famous equation that $$$[n=1]=\sum\limits_{d|n}\mu (d)$$$, where $$$\mu$$$ is the Möbius function.
Apply Möbius' formula, and try to transform the formula we need to calculate until you have to calculate $$$f(T)$$$ for every $$$T$$$ from $$$1$$$ to $$$2m$$$, where $$$f(T)$$$ is the number of tuples $$$(i,j,k)$$$ such that $$$T$$$ is a divisor of both $$$i\oplus j$$$ and $$$j\oplus k$$$.
Consider enumerating $$$j$$$, $$$d_1T=i\oplus j$$$ and $$$d_2T=j\oplus k$$$. It's easy to see that the number of tuples $$$(j,d_1,d_2)$$$ is equal to the number of tuples $$$(i,j,k)$$$, if we ensure that $$$d_1T\oplus j \le m$$$ and $$$d_2T\oplus j\le m$$$.
Due to the series sum of Harmonic series, it can be accepted to enumerate $$$T$$$ and $$$d_1$$$.
Observation: although a pair of $$$T$$$ and $$$d_1$$$ will process a set of $$$j$$$ such that $$$d_1T\oplus j\le m$$$, these $$$j$$$ will be distributed in $$$\mathcal O(\log m)$$$ intervals.
You can prove the observation by considering the bitmask of $$$m$$$ and $$$d_1T$$$.
The sum of the number of intervals will be $$$\mathcal O(m\ln m\log m)$$$. How about applying a data structure to record the intervals?
After recording, we can enumerate $$$d_2$$$ in the same complexity. It's easy to see we need to find the intersection of some intervals (the number of $$$j$$$ that satisfy both conditions simultaneously). We will make queries on our data structure to complete it.
Trie is a suitable data structure. If you are sensitive to some observations, Fenwick Tree also works.
We will ignore a few corner cases, such as $$$i=j$$$ or $$$j=k$$$, and other corner cases involving $$$0$$$. The contributions of those cases are relatively simple or classical, so we omit them here; Consequently, some summation bounds below are not written with full formal tightness.
We actually want to compute
As usual, enumerate the value of the $$$\gcd$$$. Thus
where $$$p=i\oplus j$$$, $$$q=j\oplus k$$$, and $$$c(p,q)$$$ is the number of tuples $$$(i,j,k)$$$ with those values of $$$p$$$ and $$$q$$$.
Apply Möbius inversion to the condition $$$\gcd(p,q)=d$$$:
where $$$\mu$$$ is the Möbius function.
We now change the summation order and pull $$$d'$$$ outward.
Writing $$$T=dd'$$$ we obtain
The outer sum over $$$T$$$ runs up to $$$2m$$$ because $$$p,q\in[0,2m]$$$.
The inner quantity depends on $$$T$$$ only. Let $$$f(T)$$$ be the number of tuples $$$(i,j,k)$$$ such that $$$T$$$ is a divisor of both $$$i\oplus j$$$ and $$$j\oplus k$$$.
Then the entire sum becomes
Due to the series sum of the Harmonic series, we can enumerate $$$T$$$ and $$$d$$$ in $$$\mathcal O(m\ln m)$$$. Hence, the main task is to compute $$$f(T)$$$ efficiently for all $$$T$$$.
Fix $$$T$$$. We enumerate $$$j$$$ and count the number of pairs $$$(i,k)$$$ such that $$$i\oplus j$$$ and $$$j\oplus k$$$ are multiples of $$$T$$$.
Equivalently, we count the number of pairs $$$(d_1,d_2)$$$ under the enumerated $$$j$$$ such that
with the additional constraints $$$d_1T\oplus j\le m$$$ and $$$d_2T\oplus j\le m$$$ (because $$$(i,k)$$$ must lie in $$$[0,m]$$$).
Equivalently, if we can enumerate $$$d_1,d_2$$$ to get $$$d_1T$$$ and $$$d_2T$$$, we only need to find the number of $$$j$$$ that satisfy both constraints. If we enumerate $$$d_1$$$ to find the set of $$$j$$$ and record it, we can enumerate $$$d_2$$$ similarly, and what we need to calculate is the size of the intersection of the two sets.
Consider enumerating $$$d_1$$$ to get $$$d_1T$$$, due to bitmask theory, the $$$j$$$ such that $$$d_1T\oplus j\le m$$$ will be distributed in $$$\mathcal O(\log m)$$$ intervals.
By using Segment Tree or Fenwick Tree naively, we will solve the problem in $$$\mathcal O(m\ln m\log^2 m)$$$, which is too slow to get accepted in the problem.
By LiHn's observation, actually, we can apply a Trie instead of a Segment Tree to record the intervals, because each interval can be formed by a subtree in the Trie. This will allow us to avoid incurring a logarithmic cost to find intervals in data structures every time.
By Leftist_G's observation, there are only two types of intervals, but one type of intervals has $$$\mathcal O(\log)$$$, and another has $$$\mathcal O(1)$$$. We can avoid using Segment Tree or Fenwick Tree in the former.
By liuhangxin's observation, we can avoid using any data structure. We can naively save the intervals, sort them, and then apply two pointers to calculate the intersection. Note that if we implement the method naively, the complexity will turn to $$$\mathcal O(m\ln m\log m\log\log m)$$$ (although it may be enough to get Accepted). He used a designed order and implmented carefully to ensure his complexity.
All solutions above can solve the problem in $$$\mathcal O(m\ln m\log m)$$$.
Note that some not-so-good solutions may apply __int128 to avoid integer overflow. Don't forget to deal with corner cases.
By LiHn.
#include<bits/stdc++.h>
#define rep1(i, a, b) for(int i = a; i <= b; ++i)
#define rep2(i, a, b) for(int i = a; i >= b; --i)
#define pii pair <int, int>
#define ft first
#define sd second
#define ll long long
#define pb push_back
#define gmax(a, b) a = max(a, b)
#define gmin(a, b) a = min(a, b)
#define all(a) a.begin(), a.end()
#define debug cout << "------------------\n"
const int N = (1 << 21) + 10;
using namespace std;
int tot, ch[N][2], cnt[N], sz[N], fa[N]; ll f[N], sum[N];
int p[N], vis[N], miu[N];
void solve() {
int n, m; cin >> n >> m;
// get miu
rep1(i, 0, tot) ch[i][0] = ch[i][1] = sz[i] = fa[i] = sum[i] = cnt[i] = 0;
miu[1] = 1;
tot = 0;
rep1(i, 2, 2 * m) vis[i] = 0;
rep1(i, 2, 2 * m) {
if(!vis[i]) p[++tot] = i, miu[i] = -1;
for(int j = 1; p[j] * i <= 2 * m && j <= tot; ++j) {
vis[i * p[j]] = 1;
if(i % p[j] == 0) break;
miu[i * p[j]] = -miu[i];
}
}
// get trie
tot = 1;
rep1(i, 0, m) {
int nw = 1;
rep2(j, 19, 0) {
int &nxt = ch[nw][i >> j & 1];
if(!nxt) nxt = ++tot, fa[nxt] = nw;
nw = nxt;
}
while(nw) ++sz[nw], nw = fa[nw];
}
// get f(T)
rep1(T, 1, 2 * m) {
f[T] = 0;
rep1(d, 1, 2 * m / T) {
int nw = 1, bg = 0, v = (d * T) ^ m;
rep2(i, 19, 0) {
int x = v >> i & 1;
if(m >> i & 1) {
int u = ch[nw][x ^ 1];
if(u) ++cnt[u], sum[u] += sz[u];
}
if(!ch[nw][x]) {bg = i + 1; break;}
nw = ch[nw][x];
}
ll num = 0;
if(!bg) ++cnt[nw], ++sum[nw], ++num;
rep1(i, bg, 19) {
nw = fa[nw];
int x = v >> i & 1;
if(m >> i & 1) {
int u = ch[nw][x ^ 1];
num += sz[u];
}
sum[nw] += num;
}
}
rep1(d, 1, 2 * m / T) {
int nw = 1, v = (d * T) ^ m;
ll num = 0;
rep2(i, 19, 0) {
int x = v >> i & 1;
num += cnt[nw];
if(m >> i & 1) {
int u = ch[nw][x ^ 1];
if(u) f[T] += sum[u] + 1ll * num * sz[u];
}
nw = ch[nw][x];
if(!nw) break;
}
if(nw) f[T] += sum[nw] + 1ll * num * sz[nw];
}
rep1(d, 1, 2 * m / T) {
int nw = 1, bg = 0, v = (d * T) ^ m;
rep2(i, 19, 0) {
int x = v >> i & 1;
int u = ch[nw][x ^ 1];
cnt[nw] = sum[nw] = cnt[u] = sum[u] = 0;
nw = ch[nw][x];
}
if(nw) cnt[nw] = sum[nw] = 0;
}
}
ll ans = 0;
rep1(d, 1, 2 * m) {
if(n % d) continue;
rep1(j, 1, 2 * m / d) {
ans += miu[j] * f[j * d];
}
}
// get i == j or j == k
rep1(g, 1, 2 * m) {
if(n % g) continue;
int nw = 1, v = g ^ m;
rep2(i, 19, 0) {
int x = v >> i & 1;
if(m >> i & 1) {
int u = ch[nw][x ^ 1];
ans += 2 * sz[u];
}
nw = ch[nw][x]; if(!nw) break;
}
if(nw) ans += 2;
}
cout << ans << '\n';
}
int main() {
int T = 1; cin >> T;
while(T--) solve();
return 0;
}






Maybe my skill issue but C killed my back implemented D and got short just 1 minute :(
Hello,I‘m the provider of D and F,and I also helped with some G issues :D, thanks again for everyone who participated in this round! Please rate the problems carefully >_<
You are great!!
I have a nice solution to D, and I didn't completely get the editorial one so I will write it.
let's observe that in the end the array is decreasing and then increasing so let's see what happens if i is the index of the turning point.
I claim that I keep the indices of the monotonic stack when it's get to i, both from the left and right side, the dec monotonic.
why is that true you ask?
well let's call the next one bigger than i from the right j, such that of course j>i lets say that j is not in the final array, therefore I popped it with something bigger than it, this can go on but the point is there is an element in the final array which is bigger than the value in index j, so therefore I can just bring j back, there isn't something between i and j that is bigger and everything which is between j and the one which is bigger than him have to have been popped because j is gone so on for every index of course and the left side
Simple implementation for this : https://mirror.codeforces.com/contest/2205/submission/364584370
I came up with an identical solution on virtual contest. I didn't know cartesian trees before.
I came up with a similar solution as well. But it was getting too complicated and kept failing on some testcase in test2. So I just gave up that approach ;(
I did so much extra work with A (cry). Could've saved some time there if I could've thought straight, but it is what it is.
This is the first time the DBOI team has prepared a contest on Codeforces — and probably the last. We spared no effort, and preparing this contest really took a lot of time. The contest would not have been possible without everyone’s help, including those who contributed problems (even the rejected ones), helped with testing, and of course our coordinator.
Hope you enjoy the contest, and we truly appreciate your advice and feedback.
why "probably last"?
StayAlone and I need to prepare for the 2027 College Entrance Exam in China, and cool_milo will prepare for his graduation at Tsinghua University at that time, which is also hard work.
We have worked for the round diligently for months, so we may not have the same dedication and energy to prepare for rounds like this in the future.
Hi, I believe Task D is similar to a standard CSES task i.e. Mountain Ranges.
It can be solved via Dynamic Programming + Monotonic Stack/Range Query Data Structures too!
Recurrence is similar. I have previously solved Mountain ranges and thus got a deja vu feeling while solving today's D. But the main part is to deduce that we need to find the longest V shape in the array.
I think it's a good enough manoeuvre to appear in a rated round.
True! I do agree the task is nice, especially the fact that once one observes that there can be only one valley (or an upward/downward slope), it's essentially maximising it's length (and subsequently minimising number of operations).
The Mountain Ranges reference hit me because it felt oddly related, overall a decent task for sure!
By longest V you mean longest decreasing subsequence ending at i + longest increasing subsequence starting at i right? Or am I missing something?
yes
but if you have something like 7 6 5 15 4 3 ..... then for 3 seeing towards left,i have to consider only 15 4 3 (what stack gives) lds ending at 3 gives 7 6 5 4 3 which is not allowed because we have to take the maximums ?
fun fact about F: every planar graph has a dual, and some graph theoretic properties in the primal graph become other graph theoretic properties on the dual graph. for example, an Eulerian subgraph (all degrees are even) in the primal corresponds exactly to a cut (coloring the faces 0/1) in the dual. it turns out that thinking about the dual graph in this problem makes the weird alternating sum formula and the connectivity constraints a lot more intuitive (at least for me).
D can be solved using a stack+dp too!!
yepp!
I have an alternate and possibly easier solution for D. For array to be cool, note that it has a fixed minimum element and the array is decreasing before that and increasing after that.
Fix the index of the minimum element (
i) and now think how will the array look. Focus only on the subarray left ofi. Note that the maximum element ( call its indexl) in this range will be the first element of the final array. With some thought, it can be seen that the next element in the final array will be the maximum element in the range (l,i) and so on... . Same thought can be applied to the array at the right ofi. The implementation turns out to be easy.Congratulations to the setters for a flawless round ! Here is my opinion about each problem:
Good problem A. I think it is nice to also let people the chance to implement some kind of bruteforce/naive algorithm if they don't find the simple solution
Average problem, I'm not sure it's specifically cute, but it's not specifically bad either
I think it is a great C. In my opinion, C should be a somewhat educative problem, targeted at new contestants. This problem contains some simple ideas that are important to know about, so yeah great C.
Very cute problem, nice to see a cartesian tree problem on codeforces :)
Cute problem too, with a very simple implementation. I think what is nice is that the code is really short and natural. The solution also feels very natural.
Didn't solve it yet but the problem setup is funny and enjoyable.
Will update my opinion when I solve it.
Another (probably) unintended solution for D: Go through the elements x in increasing order. If one of the neighboouring elements is bigger, we are done with x its cost is 0. Otherwise, you need to remove all elements adjacent to x on one side untill you reach a bigger element. It is optimal to take the direction with the minimal number of removed elements minus the sum of their costs, so whenever our final array contains x we know which direction to go to. We can then set the cost of these removed elements to 0, and set the cost of x to the number of removed elements, since every valid array containing those smaller elements would also contain x, but then it would be optimal to delete them so x has a bigger neighbour. Our total cost is the sum of the elements of the array. TO get the sum of a segment and set all elements in a segment to 0, we use a lazy segment tree.
Implementation: https://mirror.codeforces.com/contest/2205/submission/364533929
glad i found someone using the same approach as me, i used recursion so the solution turned out to be really simple, implementation: https://mirror.codeforces.com/contest/2205/submission/364524538
shouldn't something like this be possible in problem F? (i'm assuming i misread/misunderstood the problem)
(the number adjacent is the degree)
It is possible, and it can be represented with one basis for each of the four outside squares (no basis for the inside square, as that would cancel out the inner edges).
i see, so i accidentally turned the problem into a different (and miles harder) problem
C was tough!
Problem C can also be solved using pointers.
Implementation : 364562915
Really nice contest. Tried solving C first. Got cooked :(
Not bad CN, it breaks my bad impression of CN.
C>>D imo. Spent ~30 mins on thinking about a greedy of C but used only ~3 mins to come up with a solution of D(The spent only 4 mins on it).
Cannot believe B has so many AC. Thanks for the contest though.
Check out my submission for G: https://mirror.codeforces.com/contest/2205/submission/364629640
It is quite a bit shorter than the editorial code. I also did inclusion-exclusion in a bit of a weird way: we only want to subtract $$$d$$$ such that $$$d$$$ does not divide $$$n$$$. Hence we can skip $$$d$$$ such that there is a $$$p | n$$$ such that $$$p^e$$$ divides $$$d$$$ but $$$p^e$$$ does not divide $$$n$$$ for some $$$e \gt 1$$$. (you can figure this out without factoring $$$n$$$!). Then we multiply by $$$\mu\left(\frac{d}{\gcd(d,n)}\right)$$$. So you can get away with not computing some $$$f(T)$$$, where either T fails the above checks, or $$$\mu\left(\frac{T}{\gcd(T,n)}\right) = 0$$$, although this is only a constant optimization.
Why does my $$$O(n^3)$$$ solution pass for C?
Sharing a very USER-FRIENDLY solution of C
http://mirror.codeforces.com/contest/2205/submission/364637515
In problem G, how to show the complexity of "naively save the intervals, sort them, and then apply two pointers" method is $$$O(m \log ^2 m \log \log m)$$$ ?
I also read jiangly's code (364548110) and I believe he used this method. Maybe I misunderstood the process of this method?
Let $$$M=2^{\lfloor \log m \rfloor+1}-1$$$, the $$$M \lt 2m$$$ .
For each $$$T$$$, There are $$$O(\frac M T)$$$ numbers that matters, these numbers will each contribute $$$O(\log M)$$$ intervals, hence there are no more than $$$O(\frac M T \log M)$$$ intervals to be sorted each time. Actually It can be proved that the number of intervals is $$$O(\frac M T \log T)$$$ for each $$$T$$$.
Continued from "each number will contribute $$$O(\log M)$$$ intervals", the lengths of the intervals would belong to $$${1,2,2^2,2^3,...,2^{\log M}}$$$, and each interval would begin from a multiple of its length. Hence there are no more than $$$1$$$ intervals of length $$$2^{\log M}$$$, no more than $$$2$$$ intervals of length $$$2^{\log M - 1}$$$, no more than $$$4$$$ intervals of length $$$2^{\log M - 2}$$$, etc. Hence there are at most $$$2\frac M T$$$ intervals longer than $$$2^{\log T}$$$, Therefore in total $$$O(\frac M T (2 + \log T))=O(\frac M T \log T)$$$ intervals
Hence the total complexity of all sorting is $$$\sum _{T=1} ^M \frac M T \log T \log (\frac M T \log T) \geq \sum _{T=M^{\frac 1 4}} ^ {M^{\frac 3 4}} \frac M T \log T \log (\frac M T)\geq \sum _{T=M^{\frac 1 4}} ^ {M^{\frac 3 4}} \frac M T \frac {\log M} 4 \frac {\log M} 4 = O(M \log ^3 M)$$$
I submitted liuhangxin's testing code at here. I considered and analysed his code for the conclusion that the complexity of the method is $$$\mathcal O(m\ln m\log m\log\log m)$$$.
I think the process is, for both $$$d_1T$$$ and $$$d_2T$$$, valid $$$j$$$-s distribute in $$$\mathcal O(\log m)$$$ uncrossed intervals, and we just need to calculate the number of $$$j$$$-s covered by two intervals. I think that if we sort the two sets of intervals independently, this can be completed using two pointers in linear complexity. Thus, the whole complexity is $$$\mathcal O(m\ln m\log m\log\log m)$$$.
I guess liuhangxin's method is a "symmetrical" method with jiangly's, according to your description. Could you please try understanding the method above?
I think liuhangxin's testing code actually used some non-trivial ways to sort the intervals. This code first sorted all $$$dT\ \mathrm{xor} \ m$$$ and then directly construct the list of sorted interval endpoints (which will be stored in
tmp) using functionvoid get(int l,int r,int d). And I believe this code is $$$O(m \ln m \log m)$$$ time, as the construction actually runs in the same logic as the solution using trie.Also, I believe jiangly's code is a different approach compare to this one.
Thanks for your thinking. I will remove the "$$$\log\log m$$$" from the complexity described in the solution.
can anyone tell me what is wrong in my solution for problem C : 364542311
You have this check
which i guess assumes something like first iteration throughout the cycle. But the size of this array can be zero not only on first iteration.
Here the same code accepted with only this place changed 365052100
Thanks for pointing out, I found that just after commenting, sad that i couldn't understand this during the contest.
For C my code does work but I have strong intuition that its O(n^3 * log(n)) that shouldn't pass can someone help me figure out what's happening
Here is my code: ~~~~~~
include <bits/stdc++.h>
using namespace std;
void solve() { int n ; cin>>n; vector<vector> v(n); for (int i = 0; i < n; i++) { int l ; cin>>l; vector temp(l); for (int j = 0; j < l; j++) { cin>>temp[j]; } reverse(temp.begin(), temp.end());
map<int, int> local_seen; for (int x : temp) { if (!local_seen[x]) { v[i].push_back(x); local_seen[x] = 1; } } } sort(v.begin(), v.end()); map<int, int> visi; for (int i = 0; i < n; i++) { for (int j=0 ; j<v[i].size(); j++) { if (!visi[v[i][j]]) { cout << v[i][j] << " "; visi[v[i][j]] = 1; } } for (int j = i+1 ; j<v.size(); j++) { vector<int> current; map<int,int> seen; for (int x = 0; x<v[j].size(); x++) { if (visi[v[j][x]] || seen[v[j][x]]) { continue; } else { current.push_back(v[j][x]); seen[v[j][x]] = 1; } } v[j] = current; } sort(v.begin() + i+1 , v.end()); } cout<<endl;}
int main() { ios::sync_with_stdio(0); cin.tie(0); int t; cin >> t; while (t--) { solve(); } return 0; }
~~~~~~
what does
It's noticed that the maximum number of each number cannot be movedeven mean in the problem D tutorial?