I think the editorial for Round#810 is not out yet, and I found a solution for 810C: XOR Triangle which I thought was interesting, even if my solution is probably more complicated the intended solution, so I wanted to write it up both because I want to share it with others and because I feel like explaining a solution can help myself remember it better. My implementation is here.
First, notice that, since every leg of the triangle $$$a\oplus b, a\oplus c, b\oplus c$$$ is the XOR of the other two legs in the triangle, and it is well-known that $$$x+y\geq x\oplus y$$$ for all positive integers $$$x, y$$$, the triangle is degenerate if and only if $$$x+y=x\oplus y$$$ for some legs $$$x, y$$$ of the triangle, i.e. $$$x+y \lt x\oplus y$$$ is not a possibility. I will be using this assumption implicitly throughout my solution.
Let's say the binary string in the test case is $$$b_{N-1} \dots b_0$$$ (rightmost bit is labelled $$$b_0$$$, because it is the least significant bit). The first idea behind my solution is that you can solve it using DP, where you loop from right to left in the binary string and compute the answer for $$$n=b_i\dots b_0$$$ for all $$$i=0$$$ to $$$N-1$$$, where $$$N$$$ is the length of the given binary string. That is, you compute the answer for every $$$n$$$ which is a suffix of the binary string in the given test case.
Now, let's say we are trying to find the answer for $$$n=b_i\cdots b_0$$$. If $$$b_i=0$$$, then the answer is just whatever the last answer for $$$n=b_{i-1}\cdots b_0$$$ was, which we already know from the previous DP answer. Otherwise if $$$b_i=1$$$, we have to do some work.
If $$$b_i=1$$$, I split the answer into four cases and then I add the answers from each of the four cases up to get the total answer:
- Number of triples where exactly 0 of $$$a,b,c$$$ have their $$$i$$$ th bit set to 1
- Number of triples where exactly 1 of $$$a,b,c$$$ have their $$$i$$$ th bit set to 1
- Number of triples where exactly 2 of $$$a,b,c$$$ have their $$$i$$$ th bit set to 1
- Number of triples where exactly 3 of $$$a,b,c$$$ have their $$$i$$$ th bit set to 1
For the rest of the post, let $$$lastVal$$$ be the value of $$$b_{i-1}\cdots b_0$$$, mod $$$998244353$$$. It is easy to compute $$$lastVal$$$ for all $$$i$$$ using a simple for loop, adding $$$2^i$$$ wherever $$$b_i$$$ is set in the binary string.
Case where 0 numbers have $$$i$$$ th bit set to 1
In this case, since the $$$i$$$th bit of all of $$$a,b,c$$$ are $$$0$$$, it is obvious that $$$a,b,c \lt n$$$, so $$$a,b,c$$$ are just arbitrary $$$i$$$-bit numbers. Let $$$d=a\oplus b$$$ and $$$e=a\oplus c$$$. Then, the legs of the triangle have lengths $$$d, e, d\oplus e$$$. Again, $$$d$$$ and $$$e$$$ are just arbitrary $$$i$$$-bit numbers, since $$$a,b,c$$$ are arbitrary $$$i$$$-bit numbers. Overall, there are $$$2^i\cdot 2^i$$$ possible values of $$$(d, e)$$$, and there are three cases where the triangle is degenerate:
- $$$d+e=d\oplus e$$$: This happens when $$$d$$$ and $$$e$$$ are disjoint, i.e. there is no $$$j$$$ where both $$$d$$$ and $$$e$$$ have their $$$j$$$th bit set to $$$1$$$. There are $$$3^i$$$ possibilities where this could occur, because there are $$$3$$$ possibilities for each bit: each of the $$$i$$$ bits are either in $$$d$$$, in $$$e$$$, or in neither.
- $$$d+(d\oplus e)=e$$$: This happens when $$$d$$$ is a subset of $$$e$$$, i.e. there is no $$$j$$$ where $$$d$$$ has its $$$j$$$ th bit set but $$$e$$$ does not have its $$$j$$$ th bit set. There are $$$3^i$$$ possibilities where this could occur, because there are $$$3$$$ possibilities for each bit: each of the $$$i$$$ bits are either in $$$d$$$, in both $$$d$$$ and $$$e$$$, or in neither.
- $$$e+(d\oplus e)=d$$$: This happens when $$$e$$$ is a subset of $$$d$$$, similar to above case, there are $$$3^i$$$ possibilities where this could occur.
Now, we need to account for the intersections of these cases:
- Both $$$d$$$ and $$$e$$$ are disjoint and $$$d$$$ is a subset of $$$e$$$ when $$$d=0$$$ -> $$$2^i$$$ possibilities
- Both $$$d$$$ and $$$e$$$ are disjoint and $$$e$$$ is a subset of $$$d$$$ when $$$e=0$$$ -> $$$2^i$$$ possibilities
- $$$d$$$ is a subset of $$$e$$$ and $$$e$$$ is a subset of $$$d$$$ when $$$d=e$$$ -> $$$2^i$$$ possibilities
Finally, all three cases occur at the same time when $$$d=e=0$$$ -> $$$1$$$ possibility
Thus, total number of pairs $$$(d,e)$$$ which lead to a non-degenerate triangle is: $$$4^i-3^i-3^i-3^i+2^i+2^i+2^i-1=4^i-3\cdot 3^i+3\cdot 2^i-1$$$
Finally, notice that for every pair $$$(d,e)$$$, there are $$$2^i$$$ triples $$$(a,b,c)$$$ where $$$(a\oplus b,a\oplus c)=(d,e)$$$. This is because for every pair $$$(d,e)$$$, any pair of the form $$$(a,b,c)=(f, f\oplus d, f\oplus e)$$$ for an arbitrary $$$i$$$-bit number $$$f$$$ will lead to $$$(a\oplus b,a\oplus c)=(d,e)$$$, and there are $$$2^i$$$ possibilities for $$$f$$$. Ergo, we need to multiply the above answer by $$$2^i$$$.
Case where 1 numbers have $$$i$$$ th bit set to 1
Without loss of generality, assume $$$a$$$ has $$$i$$$ th bit set to 1 and $$$b$$$ and $$$c$$$ have $$$i$$$ th bit set to 0. (We'll multiply the answer from this case by $$$3$$$ at the end to account for this arbitrary choice.) Thus, $$$a=2^i+f$$$ for some $$$0\leq f \leq lastVal$$$ and $$$b$$$ and $$$c$$$ are arbitrary $$$i$$$-bit numbers. The triangle has legs $$$2^i+(b\oplus f), 2^i+(c\oplus f), (b\oplus c)$$$. If we let $$$g$$$ and $$$h$$$ be $$$b\oplus f$$$ and $$$c\oplus f$$$, respectively, then the triangle has legs $$$2^i+g, 2^i+h, g\oplus h$$$. Like the last case, the number of possibilities for the pair $$$(g,h)$$$ is $$$2^i\cdot 2^i=4^i$$$.
There are two cases where the triangle could be degenerate (notice that $$$2^i+g+2^i+h=g\oplus h$$$ is not possible because the left side is at least $$$2^i$$$ while the right side is an $$$i$$$-bit number):
- $$$2^i+g+(g\oplus h)=2^i+h$$$: This happens when $$$g$$$ is a subset of $$$h$$$, so there are $$$3^i$$$ possibilities
- $$$2^i+h+(g\oplus h)=2^i+g$$$: This happens when $$$h$$$ is a subset of $$$g$$$, so there are $$$3^i$$$ possibilities
Finally, the intersection of both cases occur when $$$h=g$$$, so there are $$$2^i$$$ possibilities for the intersection
Thus, total number of pairs $$$(g,h)$$$ which lead to a non-degenerate triangle is: $$$4^i-3^i-3^i+2^i=4-2\cdot 3^i+2^i$$$
Finally, notice that for every pair $$$(g,h)$$$, there are $$$lastVal+1$$$ triples $$$(a,b,c)$$$ where $$$a=2^i+f$$$ and $$$(b\oplus f, c\oplus f)=(g,h)$$$. In the last case, this was $$$2^i$$$ because $$$f$$$ could be any arbitrary $$$i$$$-bit number, but here, it is $$$lastVal+1$$$ because we have the restriction $$$0\leq f\leq lastVal$$$, and there are only $$$lastVal+1$$$ $$$i$$$-bit numbers which satisfy this inequality. Ergo, we need to multiply the above answer by $$$lastVal+1$$$, and then multiply by $$$3$$$ to account for the arbitrary choice of making $$$a$$$ have the $$$1$$$ bit.
Case where 2 numbers have $$$i$$$ th bit set to 1
Without loss of generality, assume that both $$$a$$$ and $$$b$$$ have their $$$i$$$ th bit set to $$$1$$$ and $$$c$$$ has its $$$i$$$ th bit set to $$$0$$$. (We'll multiply the answer from this case by $$$3$$$ at the end to account for this arbitrary choice.) Then, $$$a=2^i+f$$$ and $$$b=2^i+g$$$ for $$$0\leq f,g\leq lastVal+1$$$ and $$$c$$$ is an arbitrary $$$i$$$-bit number. The legs of the triangle have lengths $$$f\oplus g, 2^i+(f\oplus c), 2^i+(g\oplus c)$$$, and there are $$$(lastVal+1)\cdot (lastVal+1)\cdot 2^i$$$ total possibilities for the triple $$$(f,g,c)$$$ (and there is a one-to-one mapping between triples $$$(a,b,c)$$$ and triples $$$(f,g,c)$$$ by the equations $$$a=2^i+f$$$ and $$$b=2^i+g$$$, so it suffices to count the number of triples $$$(f,g,c)$$$ for this case).
The triangle is degenerate in two cases: (notice that $$$2^i+(f\oplus c)+2^i+(g\oplus c)=f\oplus g$$$ is not possible because the left side is at least $$$2^i$$$ while the right side is an $$$i$$$-bit number):
- $$$2^i+(f\oplus c)+(f\oplus g)=2^i+(g\oplus c)$$$: In this case, $$$(f\oplus c)+(f\oplus g)=(g\oplus c)$$$, meaning that $$$f\oplus c$$$ is a subset of $$$g\oplus c$$$. In terms of sets, XOR is like symmetric difference so this means $$$c$$$ contains all of $$$f\setminus g$$$ and is disjoint with $$$g\setminus f$$$. In other words, $$$c$$$ has a $$$1$$$ bit wherever $$$f$$$ has a $$$1$$$ bit and $$$g$$$ has a $$$0$$$ bit and $$$c$$$ has a $$$0$$$ bit wherever $$$g$$$ has a $$$1$$$ bit and $$$f$$$ has a $$$0$$$ bit. Ergo, if we fix $$$f$$$ and $$$g$$$, then every bit in $$$c$$$ where the bits of $$$f$$$ and $$$g$$$ differ is determined, but every other bit in $$$c$$$ is free, i.e. every other bit could be either $$$0$$$ or $$$1$$$. The bits where $$$f$$$ and $$$g$$$ differ are exactly those bits where $$$f\oplus g$$$ has a $$$1$$$ bit. Ergo, there are $$$popcnt(f\oplus g)$$$ bits where that bit in $$$c$$$ is determined, so $$$i-popcnt(f\oplus g)$$$ bits in $$$c$$$ are free, meaning there are $$$2^{i-popcnt(f\oplus g)}$$$ possible values for $$$c$$$. (Note that $$$popcnt$$$ is a function that takes in a nonnegative integer and returns the number of $$$1$$$ bits.) Ergo, the total number of triples $$$(f,g,c)$$$ where this occurs is: $$$\sum_{0\leq f\leq lastVal} \sum_{0\leq g\leq lastVal} 2^{i-popcnt(f\oplus g)}$$$
- $$$2^i+(g\oplus c)+(f\oplus g)=2^i+(f\oplus c)$$$: Same number of possibilities as previous case, so we'll just multiply the number of possibilities we got from the previous case by two.
Finally, the intersection of both cases happens only when $$$f\oplus g=0$$$, i.e. when $$$f=g$$$. Since there are $$$lastVal+1$$$ possibilities for $$$f$$$ and, in this case, $$$c$$$ could be any $$$i$$$-bit number, there are $$$2^i\cdot (lastVal+1)$$$ possibilities for the intersection.
Thus, in total, the number of triplets where $$$(f,g,c)$$$ leads to a nondegenerate triangle is:
$$$2^i\cdot (lastVal+1)^2-2\left(\sum_{0\leq f\leq lastVal} \sum_{0\leq g\leq lastVal} 2^{i-popcnt(f\oplus g)}\right)+2^i\cdot lastVal$$$Factor out $$$2^i$$$ from everything for convenience:
$$$2^i\left( (lastVal+1)^2-2\left(\sum_{0\leq f\leq lastVal} \sum_{0\leq g\leq lastVal} 2^{-popcnt(f\oplus g)}\right)+lastVal \right)$$$Notice that negative exponents are OK because we are working in modular arithmetic, and $$$2$$$ is invertible modulo the modulus they give us.
Let $$$y_i=\sum_{0\leq f\leq b_i\dots 0} \sum_{0\leq g\leq b_i\dots b_0} 2^{-popcnt(f\oplus g)}$$$. I'll explain how to compute $$$y_i$$$ using DP at the end of this post, but for now, just notice that we can replace the big sum in the expression above with $$$y_{i-1}$$$.
Finally, don't forget to multiply by $$$3$$$ due to the arbitrary choice we made at the beginning.
Case where 3 numbers have $$$i$$$ th bit set to 1
In this case, there are numbers $$$f, g, h$$$ such that $$$0\leq f,g,h\leq lastVal$$$ such that $$$a=2^i+f, b=2^i+g, c=2^i+h$$$ and the legs of the triangle have lengths $$$f\oplus g, f\oplus h, g\oplus h$$$, i.e. the $$$i$$$ th bits cancel out when we take the XORs since every number has their $$$i$$$ th bit set. Ergo, the answer for this case is just the answer we computed for $$$n=b_{i-1}\dots b_0$$$ previously, so just use that previous answer for this case.
We finally went through all four cases, so we are basically done. Now we just need to figure out how to compute $$$y_i$$$ for all $$$i=0$$$ to $$$N-1$$$.
First, the base case is $$$y_{-1}=1$$$. I treat $$$b_{-1}\dots b_0$$$ as an "empty" number which is equal to $$$0$$$, and it is easy to verify that $$$\sum_{0\leq f\leq 0}\sum_{0\leq g\leq 0} 2^{-popcnt(f\oplus g)}=2^{-0}=1$$$.
Now let's handle the recurrence case: First, if $$$b_i=0$$$, then $$$y_i=y_{i-1}$$$ so we can just use the previous answer. Otherwise, if $$$b_i=1$$$, we split the sum into four cases:
- $$$2^i\leq f, g\leq b_i\dots b_0$$$: In this case, both $$$f$$$ and $$$g$$$ has their $$$i$$$th bit set, so $$$f\oplus g$$$ cancels the $$$i$$$ th bit out. Ergo, this is the same as summing over $$$0\leq f,g\leq b_{i-1}\dots b_0$$$, so we just use the previous answer of $$$y_{i-1}$$$ in this case.
- $$$2^i\leq f\leq b_i\dots b_0$$$ and $$$0\leq g\leq 2^i-1$$$: In this case, notice that for any fixed $$$f$$$, $$$f\oplus g$$$ is some $$$(i+1)$$$-bit number with its $$$i$$$ th bit set, which we can represent as $$$2^i+z$$$ for some $$$i$$$-bit number $$$z$$$. Moreover, for any $$$i$$$-bit number $$$z$$$, the only solution to the equation $$$f\oplus g=2^i+z$$$ is $$$g=f\oplus (2^i+z)$$$. In other words, for every $$$i$$$-bit number $$$z$$$, there is exactly one $$$g$$$ such that $$$f\oplus g=2^i+z$$$, so we have: $$$\sum_{0\leq g\leq 2^i-1} 2^{-popcnt(f\oplus g)}=\sum_{0\leq z\leq 2^i-1} 2^{-popcnt(2^i+z)}=\sum_{0\leq z\leq 2^i-1} 2^{-(1+popcnt(z))}=2^{-1}\sum_{0\leq z\leq 2^i-1}2^{-popcnt(z)}$$$. Let $$$x_i=\sum_{0\leq z\leq 2^i-1}2^{-popcnt(z)}$$$. I'll explain how to compute $$$x_i$$$ at the very end of this post. Thus, since $$$\sum_{0\leq g\leq 2^i-1} 2^{-popcnt(f\oplus g)}$$$ doesn't actually depend on the value of $$$f$$$, we find that $$$\sum_{2^i\leq f\leq b_i\dots b_0}\sum_{0\leq g\leq 2^i-1} 2^{-popcnt(f\oplus g)}=(lastVal+1)\cdot 2^{-1}\cdot x_i$$$, since there are $$$lastVal+1$$$ possible values for $$$f$$$.
- $$$2^i\leq g\leq b_i\dots b_0$$$ and $$$0\leq f\leq 2^i-1$$$: Same as previous case, so we can just multiply the answer by the previous case by $$$2$$$, which gets rid of the $$$2^{-1}$$$
- $$$0\leq f,g\leq 2^i-1$$$: Similar to the previous case, for any fixed $$$f$$$, and for any $$$i$$$-bit number $$$z$$$, there is exactly one $$$g$$$ such that $$$f\oplus g=z$$$, so $$$\sum_{0\leq g\leq 2^i-1} 2^{-popcnt(f\oplus g)}=\sum_{0\leq z\leq 2^i-1} 2^{-popcnt(z)}=x_i$$$. Since the value of this sum doesn't depend on $$$f$$$ and there are $$$2^i$$$ possible values of $$$f$$$, we find that $$$\sum_{0\leq f,g\leq 2^i-1} 2^{-popcnt(f\oplus g)}=2^i\cdot x_i$$$.
Now we know how to compute $$$y_i$$$, but we need to compute $$$x_i=\sum_{0\leq z\leq 2^i-1}2^{-popcnt(z)}$$$ for all $$$i=0$$$ to $$$N-1$$$. First, $$$x_0=1$$$, because $$$\sum_{0\leq z\leq 0} 2^{-popcnt(z)}=2^{-0}=1$$$.
Now let's handle the recurrence case: We split the sum into two cases:
- $$$0\leq z\leq 2^{i-1}-1$$$: $$$\sum_{0\leq z\leq 2^{i-1}-1} 2^{-popcnt(z)}$$$ is just $$$x_{i-1}$$$, so we just use the previous answer of $$$x_{i-1}$$$ in this case.
- $$$2^i\leq z\leq 2^i-1$$$: Here, every $$$2^i\leq z\leq 2^i-1$$$ can be written as $$$z=2^i+w$$$ for some $$$0\leq w\leq 2^{i-1}-1$$$, and $$$popcnt(z)=popcnt(2^i+w)=1+popcnt(w)$$$, so we have $$$\sum_{2^{i-1}\leq z\leq 2^i-1} 2^{-popcnt(z)}=\sum_{0\leq w\leq 2^{i-1}-1} 2^{-(1+popcnt(w))}=2^{-1} \sum_{0\leq w\leq 2^{i-1}-1} 2^{-popcnt(w)}=2^{-1}\cdot x_{i-1}$$$.
Ergo, the recurrence for $$$x_i$$$ is simply $$$x_i=(1+2^{-1})x_{i-1}$$$, and with this, we have all the info we need to solve the problem.









 edges per query.
edges per query.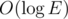 to process. There are
to process. There are 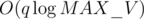 edges, meaning each edge is
edges, meaning each edge is 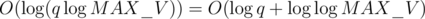 to process.
to process.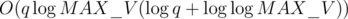 overall. However,
overall. However, 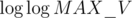 term and simply has
term and simply has 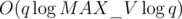 . How did they get rid of the
. How did they get rid of the 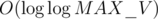 term in the analysis? Did I do something wrong here?
term in the analysis? Did I do something wrong here?