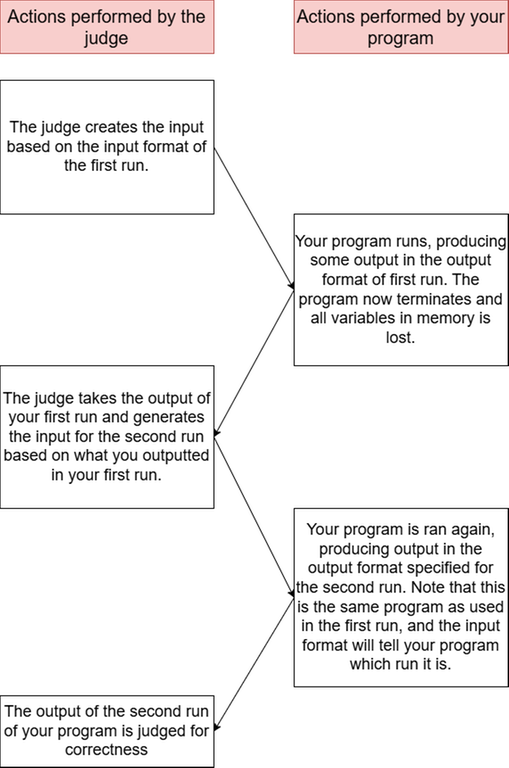
| Predictor | A | B | C | D | E | F | G | H |
|---|---|---|---|---|---|---|---|---|
| Proof_by_QED | 800 | 1300 | (1400-2000) | 1700 | 2100 | 2400 | 2600 | 3500 |
| nifeshe | 800 | 1400 | (1400-1900) | 1800 | 2200 | 2600 | 3000 | 3500 |
| dinohaur | 800 | 1200 | (1400-1700) | 2100 | 2300 | 2600 | 2900 | 3300 |
| _istil | 800 | 1200 | (1300-1800) | 1900 | 2300 | 2500 | 2800 | 3300 |
| Dragos | 800 | 1400 | (1400-1900) | 1800 | 2100 | 2400 | 2800 | 3500 |
| Argentum47 | 800 | 1300 | (1400-2000) | 1900 | 2200 | 2500 | ? | ? |
| simplelife | 800 | 1200 | (1200-1800) | 1600 | 2000 | 2500 | 6700 | 6700 |
| AksLolCoding | 800 | 1000 | (1100-1800) | 1600 | 1900 | 2400 | ? | ? |
| nik_exists | 800 | 1100 | (1100-?) | 1800 | 2000 | ? | ? | ? |
2211A - Antimedian Deletion
Problem Credits: nifeshe, Proof_by_QED
You are allowed to delete two elements in any valid subarray, but you only need to keep one.
A lower bound for the answer for each element is $$$2$$$ (or $$$1$$$ if $$$n=1$$$), as if the array size is $$$2$$$ or less, then no operations are even possible.
This bound is achievable for any element in any permutation. We can choose our subarray of size $$$3$$$ arbitrarily. Suppose $$$x$$$ is the value we want to keep in the array. If $$$x$$$ is the minimum element, we can delete the largest element. Otherwise, we can delete the smallest element.
def solve():
n = int(input())
a = list(map(int, input().split()))
if n==1:
print("1\n")
else:
for i in range(n):
print("2 ")
print("\n")
t = int(input())
for i in range(t):
solve()
2211B - Mickey Mouse Constructive
Problem Credits: Proof_by_QED
Since the array consists only of $$$1$$$ and $$$-1$$$, the growth rate of the cumulative sum must be $$$1$$$ or $$$-1$$$. In other words, you can't skip a number. What can you say about a lower bound of the answer from this?
For an array $$$a$$$, denote $$$p_i=a_1+a_2+\ldots+a_i$$$. Define $$$p_0=0$$$. We can see that the sum of the subarray from $$$l$$$ to $$$r$$$ is $$$p_r-p_{l-1}$$$.
Let's lower bound our answer. First, suppose that $$$x \ne y$$$. Without loss of generality that $$$x \ge y$$$ (so $$$p_{x+y} \gt 0$$$). Fix $$$d$$$ to be a divisor of $$$|x-y|$$$. Since our array contains only $$$1$$$ and $$$-1$$$ (and thus $$$p_i$$$ changes by only $$$1$$$ or $$$-1$$$ every time), and that $$$p_0=0$$$ while $$$p_{x+y}=x-y$$$, there must exist an index $$$i$$$ where $$$p_i=d$$$ (this is the discrete version of the Intermediate Value Theorem). Let this index be $$$i_1$$$. By the same logic, there must be an index $$$i_2$$$ between $$$i_1$$$ and $$$x+y$$$ such that $$$p_{i_2}=2\cdot d$$$. Continuing this process, we can see that for every divisor $$$d$$$ of $$$x-y$$$, there must exist at least one valid partition with all subarrays having equal sum. Therefore, a lower bound for the answer is the number of divisors of $$$x-y$$$. The case of $$$x \le y$$$ is analogous.
Then, can we reach this lower bound? It turns out the construction $$$[1, 1, \ldots, 1, -1, -1, \ldots, -1]$$$ reaches this lower bound. For a fixed divisor $$$d$$$, there is only one valid index $$$i$$$ each time, except for $$$x-y$$$, of which there are two indices. However, since the last subarray in the partition must reach $$$n$$$, this doesn't matter to us.
This solves the case for $$$x \ne y$$$. But what about $$$x=y$$$? Our above analysis of Intermediate Value Theorem breaks, as the start and final value are both $$$0$$$. The answer is at least $$$1$$$, since the full array is valid. We can reach this lower bound using the same construction above (as there does not exist any indices other than $$$0$$$ and $$$x+y$$$ with $$$p_i=0$$$).
import sys
input = sys.stdin.readline
t = int(input())
for _ in range(t):
x, y = map(int, input().split())
s = x - y
a = []
for _ in range(x):
a.append(1)
for _ in range(y):
a.append(-1)
ans = 0
for i in range(1, abs(s) + 1):
if s % i == 0:
ans += 1
if s == 0:
ans = 1
print(ans)
print(*a)
2211C1 - Equal Multisets (Easy Version)
Problem Credits: Proof_by_QED
Special thanks to __baozii__ for suggesting this subtask.
Consider the cases of $$$k=n$$$ and $$$k=n-1$$$. What do you notice?
Our first observation is that $$$b$$$ has to be a permutation (after replacing all $$$-1$$$'s). This is because since $$$a$$$ is a permutation, and each element appears in at least one valid subarray, if $$$b$$$ is not a permutation then at least one element does not exist in $$$b$$$, meaning that the answer must be no.
It may help to visualize this problem using some examples first:
- If $$$k=n$$$, then the answer is only YES if there are no repeat elements in $$$b$$$.
- What if $$$k=n-1$$$? Now, the requirements are more strict. If you have $$$b_1 \ne a_1$$$, $$$a_1$$$ would need to appear somewhere later. But then this means that in the subarray $$$[2,n-1]$$$, $$$a_1$$$ appears in the subarray in $$$b$$$ but not in $$$a$$$. Similarly, $$$a_n$$$ must be the same as $$$b_n$$$. We can see that the remaining $$$n-2$$$ elements are allowed to be any rearrangement of the middle $$$n-2$$$ elements in $$$a$$$.
Continuing on to $$$k=n-2$$$, using the same logic, we see that the first and last $$$2$$$ elements of $$$a$$$ must match with the first and last $$$2$$$ elements of $$$b$$$, with the middle $$$n-4$$$ numbers being allowed to be anything.
We now see that this forms a pattern: the first $$$n-k$$$ elements and the last $$$n-k$$$ elements in $$$a$$$ and $$$b$$$ must match, and the middle $$$2k-n$$$ elements must be rearrangements of each other. If $$$2k \lt n$$$, then we must have $$$a=b$$$ naturally. Let's now show that it works.
Consider the union of all size $$$k$$$ intervals: starting from $$$[1,k]$$$, then $$$[2,k+1]$$$, and so on. The interval that is inside all of these intervals is the union of $$$[1,k]$$$ and $$$[n-k+1,n]$$$ (intuitively, we can see this is true because $$$[1,k]$$$ is the leftmost interval, and $$$[n-k+1,n]$$$ is the rightmost one. Therefore, any point inside both of these intervals must be shared among all length $$$k$$$ intervals). The length of the intersection is $$$\max(2k-n,0)$$$. Any point not in this common interval must be the same in $$$a$$$ and $$$b$$$, as there exists an interval that doesn't contain it.
2211C2 - Equal Multisets (Hard Version)
Problem credits: Proof_by_QED
Consider the transition from the interval $$$[l,r]$$$ to $$$[l+1,r+1]$$$. What do you "gain"? What do you "lose"?
We need to take a different approach from problem C1. Consider transferring from the interval $$$[l,r]$$$ to $$$[l+1,r+1]$$$. In the multiset of $$$b$$$, we need to "lose" the element $$$a_l$$$ and "gain" the element $$$a_r$$$. At first glance, this seems very restrictive: is there even any cases where $$$a_l \ne b_l, a_r \ne b_r$$$ and this can still work out?
In fact, the only other case that doesn't break the condition is if $$$a_l=a_r$$$ and $$$b_l=b_r$$$. Otherwise, you would need $$$b_r$$$ to "recover" the lost element from $$$a_r$$$ and also whatever element was lost at $$$b_l$$$ at the same time, which is impossible (if $$$a_l=a_r$$$, then $$$a_r$$$ "recovered" the element $$$a_l$$$ in the multiset).
This motivates us to split the arrays $$$a$$$ and $$$b$$$ into $$$k$$$ subsequences, depending on their indices modulo $$$k$$$. In each subsequence, if all elements of $$$a$$$ are the same, then all elements of $$$b$$$ must be the same. Otherwise, we must have $$$a_i=b_i$$$ for each index in the subsequence.
There is one more requirement: we need to ensure that the first $$$k$$$ elements of $$$a$$$ and $$$b$$$ can match. Our transition conditions ensure that if $$$[l,r]$$$ works, then $$$[l+1,r+1]$$$ also does. But we would need the "base" interval $$$[1,k]$$$ to work first (this process is much like the process of induction). Once we fill in values of $$$b$$$ that is required in our previous step, all we need to do is ensure that no number in the first $$$k$$$ indices appears more often in $$$b$$$ than $$$a$$$.
#include <bits/stdc++.h>
using namespace std;
#define int long long
void solve() {
int n, k; cin >> n >> k;
vector<int> a(n), b(n);
for (auto &x : a) cin >> x;
for (auto &x : b) cin >> x;
vector<bool> vis(n);
vector<int> pos(k);
map<int, int> cnt;
for (int i = 0; i < k; i++) {
pos[i] = a[i];
for (int j = i + k; j < n; j += k) {
if (pos[i] != a[j]) pos[i] = -1;
}
if (pos[i] != -1) cnt[pos[i]]++;
if (pos[i] == -1) {
for (int j = i; j < n; j += k) {
if (b[j] != -1 && b[j] != a[j]) {
cout << "NO" << "\n";
return;
}
}
}
}
map<int, int> cnt2;
vector<int> ans(k);
for (int i = 0; i < k; i++) {
if (pos[i] != -1) {
set<int> d;
for (int j = i; j < n; j += k)
d.insert(b[j]);
d.erase(-1);
if (d.size() >= 2) {
for (int j = i; j < n; j += k)
if (b[j] != -1 && b[j] != a[j]) {
cout << "NO" << "\n";
return;
}
}
if (d.size() == 1)
cnt2[*d.begin()]++;
}
}
for (auto [k, x] : cnt2) {
if (x > cnt[k]) {
cout << "NO" << "\n";
return;
}
}
cout << "YES" << "\n";
}
signed main() {
int T;
cin >> T;
while (T--)
solve();
}
2211D - AND-array
Problem credits: nifeshe
How is the checker implemented? In other words, given $$$a$$$ find $$$f(a)$$$.
Let $$$\text{cnt}_l$$$ be the number of $$$i$$$ such that $$$a_i$$$ has the bit $$$l$$$ set. $$$f(a)$$$ only depends on the array $$$\text{cnt}$$$.
$$$f(a)_k = \sum\limits_{l = 0}^{28} 2^l \cdot \binom{\text{cnt}_l}{k}$$$.
Look at $$$b_n$$$. This value tells us all the bits $$$l$$$ that have $$$\text{cnt}_l = n$$$.
We can remove all the bits in $$$b_n$$$: for all set bits in $$$b_n$$$ and $$$1 \le k \lt n$$$ set $$$b_k = b_k - \binom{n}{k} \cdot 2^l$$$. After that no bit occurs $$$n$$$ times in $$$a$$$, so set $$$n = n - 1$$$.
Since $$$a$$$ is guaranteed to exist, each bit will be removed at most once, so the time complexity is $$$O(n \log A)$$$.
Given $$$a$$$, how can we find $$$f(a)$$$? Consider each bit separately: assume $$$a_i$$$ is either $$$0$$$ or $$$1$$$. If there are $$$m$$$ ones in $$$a$$$, then $$$f(a)_k = \binom{m}{k}$$$ — the number of ways to pick $$$k$$$ ones from $$$m$$$, since every index in the subsequence has to be a $$$1$$$.
This can be generalized to all $$$a$$$: let $$$\text{cnt}_l$$$ be the number of $$$i$$$ such that $$$a_i$$$ has the bit $$$l$$$ set. $$$f(a)$$$ only depends on the array $$$\text{cnt}$$$, and $$$f(a)_k = \sum\limits_{l = 0}^{28} 2^l \cdot \binom{\text{cnt}_l}{k}$$$.
Now we need to restore $$$a$$$ from $$$f(a)$$$. Look at $$$b_n$$$. This value tells us all the bits $$$l$$$ that have $$$\text{cnt}_l = n$$$.
We can remove all the bits in $$$b_n$$$: for all set bits in $$$b_n$$$ and $$$1 \le k \lt n$$$ set $$$b_k = b_k - \binom{n}{k} \cdot 2^l$$$.
After that no bit occurs $$$n$$$ times, and since $$$f(a)$$$ only depends on the array $$$\text{cnt}$$$, we can assume that $$$n = n - 1$$$ and repeat the same procedure. This way we can uniquely determine the array $$$\text{cnt}$$$.
The only thing left is the actually find any feasible $$$a$$$. We can do that the following way: for all bits $$$l$$$ and $$$i$$$ in $$$[1, \text{cnt}_l]$$$ set the $$$l$$$-th bit in $$$a_i$$$. This $$$a$$$ corresponds to the found array $$$\text{cnt}$$$.
The only concern is the time complexity. However, since the answer is guaranteed to exist we will delete each bit at most once, so the final solution is $$$O(n \log A)$$$.
#include <bits/stdc++.h>
using namespace std;
const int mod = 1e9 + 7;
const int MAX = 2e5 + 5;
const int LG = 29;
int binpow(int x, int n) {
int ans = 1;
while(n) {
if(n & 1) ans = (long long) ans * x % mod;
n >>= 1;
x = (long long) x * x % mod;
}
return ans;
}
int fact[MAX], inv[MAX];
int C(int n, int k) {
if(n < k || k < 0) return 0;
return (long long) fact[n] * inv[k] % mod * inv[n - k] % mod;
}
void solve() {
int n;
cin >> n;
vector<int> b(n);
for(auto &i : b) {
cin >> i;
}
vector<int> cnt(LG);
for(int i = n - 1; ~i; i--) {
for(int l = 0; l < LG; l++) {
if(b[i] >> l & 1) {
cnt[l] = i + 1;
for(int j = 0; j <= i; j++) {
int subtract = (long long) C(i + 1, j + 1) * (1 << l) % mod;
b[j] -= subtract;
if(b[j] < 0) b[j] += mod;
}
}
}
}
vector<int> a(n);
for(int l = 0; l < LG; l++) {
for(int i = 0; i < cnt[l]; i++) {
a[i] |= 1 << l;
}
}
for(auto i : a) cout << i << " "; cout << '\n';
}
signed main() {
fact[0] = 1; for(int i = 1; i < MAX; i++) fact[i] = (long long) fact[i - 1] * i % mod;
inv[MAX - 1] = binpow(fact[MAX - 1], mod - 2);
for(int i = MAX - 1; i; i--) inv[i - 1] = (long long) inv[i] * i % mod; assert(inv[0] == 1);
ios_base::sync_with_stdio(0); cin.tie(0); cout.tie(0);
int tests = 1;
cin >> tests;
for(int test = 0; test < tests; test++) {
solve();
}
}
2211E - Minimum Path Cover
Problem credits: Proof_by_QED
The reason why most naive DP approaches fail is because you cannot factorize $$$2\cdot 10^5$$$ numbers of scale $$$10^{18}$$$ fast. How do you avoid this?
The solution to the problem does not change if "each node is covered by exactly one path" was replaced by "each node is covered by at least one path"
Read the hints.
The most naive approach is something like $$$dp(node,x)$$$ to the minimum number of paths used to cover the subtree of $$$node$$$, such that the path from $$$node$$$ has GCD $$$x$$$. With potentially up to $$$d(a_{node})$$$ different states of DP at each node (where $$$d(x)$$$ is the number of divisors of $$$x$$$), this will easily get the Time Limit Exceeded verdict.
However, we take advantage of the fact that in a tree, each node can have only one parent. In other words, there can only be one path going upwards starting at each node. For simplicity, assume that each path must end as a prime number (if the path instead ends with something like $$$6$$$, it is counted as both ending in $$$2$$$ and $$$3$$$). We can then perform a DP like $$$dp(node,x)$$$ being the smallest number of paths to cover the subtree of $$$node$$$, assuming that the path going up from $$$node$$$ is $$$x$$$ (where $$$x$$$ must be prime).
Unfortunately, finding the prime factors of the numbers is still impossible. However, what if we don't need to? Consider a greedy strategy where you extend every path from the children of node $$$x$$$ upwards if the GCD does not become $$$1$$$. (because of our analysis above, the solution to the problem does not change if "each node is covered by exactly one path" is replaced by "each node is covered by at least one path"). While we cannot store all possible values of a path, we can store the LCM of all such paths. It's not hard to show that storing the LCM is functionally the same as storing all possible values of a path.
So the solution is as follows: let $$$dp(x)$$$ represent the minimum number of paths to cover the subtree of $$$x$$$, and let $$$val(x)$$$ be the LCM of all paths that can pass through $$$x$$$. When trying to find the answers for $$$x$$$, we first set $$$val(x)=1$$$. For each child $$$c$$$ of $$$x$$$, set $$$val(x)=\text{LCM}(val(x), val(c))$$$. Set $$$dp(x)$$$ to be the sum of $$$dp(c)$$$, and add $$$1$$$ if $$$val(x)=1$$$ (as well as updating $$$val(x)=a_x$$$). This solution is very simple and runs in $$$O(n \log A)$$$
Since the values of $$$a_i$$$ are large, we must calculate LCM as $$$a/\text{GCD}(a,b)\cdot b$$$ instead of $$$(a\cdot b)/\text{GCD}(a,b)$$$. However, note that the calculations will never overflow $$$64$$$-bit integers, as they are upper bounded by $$$a_i$$$.
As an alternative to maintaining the LCM, you can actually maintain the set of possible GCD values, but ensure that they are pairwise coprime. This solution is expected to run in $$$O(n \log ^2{A})$$$
#include <bits/stdc++.h>
using namespace std;
#define rep(i,a,n) for (int i=(a);i<(n);i++)
#define per(i,a,n) for (int i=(n)-1;i>=(a);i--)
#define pb push_back
#define eb emplace_back
#define mp make_pair
#define all(x) (x).begin(),(x).end()
#define fi first
#define se second
#define SZ(x) ((int)(x).size())
typedef vector<int> VI;
typedef basic_string<int> BI;
typedef long long ll;
typedef pair<int,int> PII;
typedef double db;
mt19937 mrand(random_device{}());
const ll mod=676767677;
int rnd(int x) { return mrand() % x;}
ll powmod(ll a,ll b) {ll res=1;a%=mod; assert(b>=0); for(;b;b>>=1){if(b&1)res=res*a%mod;a=a*a%mod;}return res;}
// head
const int N=201000;
int n,dp[N];
ll d[N],v[N];
ll a[N];
void solve() {
scanf("%d",&n);
per(i,1,n+1) {
int k;
scanf("%lld",&a[i]);
scanf("%d",&k);
VI s;
dp[i]=0;
bool val=0;
rep(j,0,k) {
int x;
scanf("%d",&x);
s.pb(x);
dp[i]+=dp[x];
d[x]=gcd(v[x],a[i]);
val|=d[x]>1;
}
if (val) {
ll z=1;
for (auto x:s) if (d[x]>1) z=lcm(z,d[x]);
v[i]=z;
} else {
dp[i]+=1;
v[i]=a[i];
}
printf("%d\n",dp[i]);
fflush(stdout);
}
}
int _;
int main() {
for (scanf("%d",&_);_;_--) {
solve();
}
}
2211F - Learning Binary Search
Problem credits: Proof_by_QED
Unfortunately, it seems like there are a lot of cheaters on this problem. We will do the best to clear them out, but keep in mind this is out of our control.
Consider what the contribution of a number is.
Come up with $$$O(nm)$$$ or $$$O(n^2)$$$ solution first. There is an identity that can simplify.
Simulate the binary search so we get the weight of each index. Now, we want to partition it into $$$m$$$ segments (potentially empty) where the weight of each segment is the minimum number that it covers.
Suppose we fix the number $$$x$$$, as well as the interval that it covers $$$[l,r]$$$. This means that we need to cover the interval $$$[1,l-1]$$$ with the numbers $$$1$$$ through $$$x-1$$$, and the interval $$$[r+1,n]$$$ with the numbers $$$x+1$$$ through $$$m$$$. Denote $$$y=m-x$$$. Then, using stars and bars, we get the number of ways to fill other numbers as:
This sum is to be taken over all $$$x$$$ from $$$2$$$ to $$$m-1$$$ (ignore the edge cases of $$$x=1$$$ and $$$x=m$$$ for now). Using Vandermonde's identity, this simplifies to
As a further optimization, note that everything above is a constant except for $$$r-l$$$, which is dependent on the size of the interval. Therefore, we are motivated to loop over the size of $$$r-l$$$. Note that the above should also be multiplied by the minimum weight on the interval from $$$l$$$ to $$$r$$$. Therefore, our problem is now trying to find the sum of minimum of all length $$$k$$$ subarrays for all $$$k$$$ from $$$1$$$ to $$$n$$$.
To solve this subproblem, we can use a monotonic stack to calculate the bounds in which $$$i$$$ is the minimum (to break ties, we use strict inequality on one side but not the other). Then, noting that the contribution of an index for $$$k$$$ increases by $$$1$$$ until some point, then decreases by $$$1$$$. This can be optimized by creating the $$$2$$$-nd order difference array. The problem is solved in $$$O(n)$$$ time.
Thanks to Dragos for writing up the following solution.
First, let’s count nondecreasing arrays.
How many nondecreasing arrays of length $$$n$$$ have last element exactly $$$m$$$?
This is a classical problem. Instead of looking at the array itself, look at its difference variables: $$$d_1 = a_1 - 1$$$ and $$$d_i = a_i - a_{i-1}$$$ for $$$i \ge 2$$$. Since the array is nondecreasing, every $$$d_i$$$ is non-negative, and $$$d_1 + d_2 + \cdots + d_n = a_n - 1 = m - 1.$$$ So this becomes the standard stars-and-bars count.
What about arrays where the last element is $$$\le m$$$?
This is equivalent to having $$$n$$$ non-negative variables with sum $$$\le m-1$$$. The standard trick is to introduce one extra variable that absorbs the remaining value, so this becomes counting $$$n+1$$$ non-negative variables with sum exactly $$$m-1$$$.
Now let’s solve the original problem. We simulate the binary search and go through all intervals $$$[l,r]$$$ that can appear in the recursion tree. For each such interval, let $$$mid = \lfloor (l+r)/2 \rfloor$$$. We count how many arrays make the search terminate at this state, and multiply that count by the current depth of the search.
Suppose we are at interval $$$[l,r]$$$. To terminate here, we need $$$a_{mid}$$$ to be the searched value. Also, if $$$l \gt 1$$$ then the search must previously have inspected position $$$l-1$$$ and concluded that its value is smaller than the target, so we need $$$a_{l-1} \lt a_{mid}$$$. Similarly, if $$$r \lt n$$$ then we need $$$a_{mid} \lt a_{r+1}$$$. Since we are already counting only nondecreasing arrays, these are the only extra constraints that matter.
So we are left with the following question: how many good arrays satisfy $$$a_{l-1} \lt a_{mid} \lt a_{r+1}$$$?
Let $$$S = \binom{n+m-1}{n}$$$ be the number of all good arrays. We now remove the bad arrays by inclusion-exclusion.
The bad arrays are those with $$$a_{l-1} = a_{mid}$$$ or $$$a_{mid} = a_{r+1}$$$. The condition $$$a_{l-1} = a_{mid}$$$ means that every difference variable corresponding to positions $$$l, l+1, \dots, mid$$$ must be $$$0$$$. So we can count such arrays by simply removing those variables from the stars-and-bars count. Similarly, the condition $$$a_{mid} = a_{r+1}$$$ means that every difference variable corresponding to positions $$$mid+1, mid+2, \dots, r+1$$$ must be $$$0$$$, and we count those in the same way.
Finally, we add back the arrays counted twice, namely those with $$$a_{l-1} = a_{mid} = a_{r+1}$$$, which is equivalent to forcing all difference variables for positions $$$l, l+1, \dots, r+1$$$ to be $$$0$$$.
One last thing to note is that if $$$l=1$$$ (or $$$r=n$$$), then the corresponding boundary restriction does not exist, so we do not subtract that case.
Since there are $$$O(n)$$$ intervals, and each interval can be computed in $$$O(1)$$$, the final complexity is $$$O(n)$$$.
#include <bits/stdc++.h>
using namespace std;
// using namespace std;
using ll = long long;
#define vt vector
#define int long long
#define add push_back
#define FOR(i,a,b) for (int i = (a); i < (b); ++i)
#define F0R(i,a) FOR(i,0,a)
#define ROF(i,a,b) for (int i = (b)-1; i >= (a); --i)
#define R0F(i,a) ROF(i,0,a)
const ll mod = 676767677;
const ll inf = 1e18;
template<typename T> using min_pq = std::priority_queue<T, std::vector<T>, std::greater<T>>; //defines min_pq
mt19937_64 rnd(chrono::steady_clock::now().time_since_epoch().count());
int rand_num(int l, int r) {
return rnd()%(r-l+1)+l;
}
int bexpo(int b, int e) {
int ans = 1;
while(e) {
if(e&1) ans=ans*b%mod;
e>>=1;
b=b*b%mod;
}
return ans;
}
signed main() {
ios_base::sync_with_stdio(false);
cin.tie(0);
// freopen("input.txt" , "r" , stdin);
// freopen("output.txt" , "w", stdout);
int t;
cin >> t;
vt<int> fact(2e6+5), ifact(2e6+5);
fact[0]=ifact[0]=1;
FOR(i, 1, 2e6+5) {
fact[i]=fact[i-1]*i%mod;
ifact[i]=bexpo(fact[i], mod-2);
}
auto nck = [&](int n, int k)->int{
if(k<0 || k>n) {
return 0;
}
return fact[n]*ifact[k]%mod*ifact[n-k]%mod;
};
while(t--) {
int n,m;
cin >> n >> m;
vt<int> time(n);
auto fill = [&](auto self, int l, int r, int start)->void{
if(l>r) return;
int mid = (l+r)/2;
time[mid]=start;
self(self, l, mid-1, start+1);
self(self, mid+1, r, start+1);
};
fill(fill, 0, n-1, 1);
vt<int> l(n,-1),r(n, n);
stack<int> s;
F0R(i, n) {
while(s.size() && time[s.top()]>time[i]) {
r[s.top()]=i;
s.pop();
}
s.push(i);
}
while(s.size()) s.pop();
R0F(i, n) {
while(s.size() && time[s.top()]>=time[i]) {
l[s.top()]=i;
s.pop();
}
s.push(i);
}
// cout << time << " " << l << " " << r << endl;
vt<int> v(n+10);
F0R(i, n) {
// cout << i << endl;
int left = i-l[i]-1;
int right = r[i]-i-1;
if(left>right) swap(left,right);
v[1]+=time[i];
v[left+2]-=time[i];
v[right+2]-=time[i];
v[left+right+3]+=time[i];
}
FOR(i, 1, n+1) v[i]+=v[i-1];
FOR(i, 1, n+1) v[i]+=v[i-1];
// cout << v << endl;
int ans = 0;
FOR(sz, 1, n+1) {
int out = n-sz;
ans+=v[sz]*nck(out+m-2, m-3)%mod;
}
int mn = inf;
F0R(i, n) {
mn=min(mn, time[i]);
ans+=nck(n-i-1+m-2, m-2)*mn;
ans%=mod;
}
mn = inf;
R0F(i, n) {
mn=min(mn, time[i]);
ans+=nck(i+m-2, m-2)*mn;
ans%=mod;
}
cout << ans << endl;
}
return 0;
}
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef vector<int> vi;
typedef pair<int, int> pii;
typedef pair<double, double> pdd;
#define pb push_back
#define mp make_pair
#define fs first
#define sc second
#define rep(i, from, to) for (int i = from; i < (to); ++i)
#define all(x) x.begin(), x.end()
#define sz(x) (int)(x).size()
#define FOR(i, to) for (int i = 0; i < (to); ++i)
typedef vector<vector<int>> vvi;
typedef vector<vector<pii>> vvpi;
typedef vector<ll> vll;
typedef vector<vll> vvll;
typedef vector<pair<int, int>> vpi;
typedef pair<ll, ll> pll;
#define MOD 676767677
template<int MODX>
struct ModInt {
unsigned x;
ModInt() : x(0) { }
ModInt(signed sig) : x(((sig%MODX)+MODX)%MODX) { }
ModInt(signed long long sig) : x(((sig%MODX)+MODX)%MODX) { }
int get() const { return (int)x; }
ModInt pow(ll p) { ModInt res = 1, a = *this; while (p) { if (p & 1) res *= a; a *= a; p >>= 1; } return res; }
ModInt &operator+=(ModInt that) { if ((x += that.x) >= MODX) x -= MODX; return *this; }
ModInt &operator-=(ModInt that) { if ((x += MODX - that.x) >= MODX) x -= MODX; return *this; }
ModInt &operator*=(ModInt that) { x = (unsigned long long)x * that.x % MODX; if (x < 0) x += MODX; return *this; }
ModInt &operator/=(ModInt that) { return (*this) *= that.pow(MODX - 2); }
ModInt operator+(ModInt that) const { return ModInt(*this) += that; }
ModInt operator-(ModInt that) const { return ModInt(*this) -= that; }
ModInt operator*(ModInt that) const { return ModInt(*this) *= that; }
ModInt operator/(ModInt that) const { return ModInt(*this) /= that; }
bool operator<(ModInt that) const { return x < that.x; }
friend ostream& operator<<(ostream &os, ModInt a) { os << a.x; return os; }
};
typedef ModInt<MOD> mint;
// N ~ 10^6
class Combinations {
public:
vector<mint> inv, fact, ifact;
Combinations(int N) {
inv.resize(N+10), fact.resize(N+10), ifact.resize(N+10);
inv[1] = fact[0] = fact[1] = ifact[0] = ifact[1] = 1;
for(int i=2;i<=N;++i) {
inv[i] = inv[MOD%i] * (MOD - MOD/i);
fact[i] = fact[i-1]*i;
ifact[i] = ifact[i-1]*inv[i];
}
}
// a > b
mint comb(ll a, ll b) {
if(a < b) return mint(0);
return fact[a] * ifact[b] * ifact[a-b];
}
};
Combinations comb(2010100);
// Stars and bars
mint SB(int K, int S) {
return comb.comb(S+K-1, K-1);
}
int n,m;
mint ret = 0;
void dfs(int l, int r, int depth) {
if (l > r) return;
// Last two checked positions.
int lp = l - 1;
int rp = r + 1;
int mid = (l + r)/2;
mint TOT = SB(n+1, m);
ret += TOT * depth;
// If we saw a position for which ARR[l-1] < ARR[mid]
if (lp != -1) {
ret -= SB(n+1 - (mid - lp), m) * depth;
}
// If we saw a position for which a[mid] < a[r+1]
if (rp != n) {
ret -= SB(n+1 - (rp - mid), m) * depth;
}
// If we saw both a[l-1] < a[mid] < a[r+1] add the double counted arrays back
if (lp != -1 && rp != n) {
ret += SB(n + 1 - (rp - lp), m) * depth;
}
dfs(mid+1, r, depth+1);
dfs(l, mid-1, depth+1);
}
int main() {
cin.sync_with_stdio(0);
cin.tie(0);
int T;
cin >> T;
while(T--) {
cin >> n >> m;
--m;
ret = 0;
dfs(0, n-1, 1);
cout << ret << "\n";
}
return 0;
}
Solve this problem for $$$n,m \lt =10^6$$$ but there is no limit on sum of $$$n$$$ or $$$m$$$ across all test cases.
2211G - Rational Bubble Sort
Problem credits: chromate00. Special thanks: BurnedChicken
Consider the graph of prefix sums.
Let's take the prefix sums $$$b_i=a_1+a_2+\ldots+a_i$$$ instead of $$$a_i$$$ (including $$$b_0=0$$$), and consider what it means when $$$a_i$$$ is sorted in non-decreasing order. We can see that $$$a_i$$$ being non-decreasing is equivalent to the points $$$(i,b_i)$$$ forming a chain that is convex from below. The operation on index $$$i$$$ makes the segment from $$$(i-1,b_{i-1})$$$ to $$$(i+1,b_{i+1})$$$ completely straight, and to sort $$$a$$$ we need to be able to make the chain convex using the operation.
Notice the following observation.
- Observation: any chain $$$(i-1,b_{i-1}),(i,b_i),\ldots,(j,b_j)$$$ can be made arbitrarily close to the line from $$$(i-1,b_{i-1})$$$ to $$$(j,b_j)$$$.
In other words, $$$a_i,a_{i+1},\ldots,a_j$$$ can be made arbitrarily close to their average value.
Because their mean is constant when we don't perform operations outside this range, we can easily reason about their variance. Let's say their mean is $$$\mu$$$. Then, $$$(a_i-\mu)^2+(a_{i+1}-\mu)^2 \ge 2 \cdot (\frac{a_i+a_{i+1}}{2}-\mu)^2$$$ due to the convexity of the function $$$f(x)=(x-\mu)^2$$$. Equality holds if and only if $$$a_i=a_{i+1}$$$. In other words, as long as there is at least one unequal adjacent pair (unless all $$$j-i+1$$$ values are equal, there definitely will be one), the variance can decrease indefinitely (that is, arbitrarily close to $$$0$$$). The variance becomes $$$0$$$ if and only if all $$$j-i+1$$$ values are equal.
Now, let's see if there is a point $$$(i,b_i)$$$ strictly below the line from $$$(0,0)$$$ to $$$(n,b_n)$$$. Then, we can make the segments almost straight from $$$(0,0)$$$ to $$$(i,b_i)$$$ and from $$$(i,b_i)$$$ to $$$(n,b_n)$$$. The fact that we can make a segment almost (yet not completely) straight is important. After we make them straight enough, let's call their slopes $$$\mu_{1,l}$$$ and $$$\mu_{1,r}$$$, and we can perform the operation on index $$$i$$$ so that the segment from $$$(i-1,b_{i-1})$$$ to $$$(i+1,b_{i+1})$$$ is straight. This slope $$$s_{1,1}$$$ certainly satisfies $$$\mu_l \lt s_{1,1} \lt \mu_r$$$. If this does not hold, then we could certainly go back, make the segments flatter, and it will definitely hold at some point when we perform the operation on index $$$i$$$.
We'll now set $$$l=i-1$$$, $$$r=i+1$$$, and maintain an invariant that the segment $$$[l,r]$$$ is convex. If we perform the operation on indices $$$i-1$$$ and $$$i+1$$$, we get two slopes $$$s_{2,1}$$$ and $$$s_{2,2}$$$ such that $$$\mu_{2,l} \lt s_{2,1} \lt s_{2,2} \lt \mu_{2,r}$$$, where $$$\mu_{2,l}$$$ is the slope from $$$(0,0)$$$ to $$$(l-1,b_{l-1})$$$ and $$$\mu_{2,r}$$$ is the slope from $$$(r+1,b_{r+1})$$$ to $$$(n,b_n)$$$. We have now expanded the segment to $$$[l-1,r+1]$$$ while maintaining convexity.
Repeating this process, we can expand $$$[l,r]$$$ to $$$[0,n]$$$, and the chain can become entirely convex.
Now the only case left is when all points are either on or above the line from $$$(0,0)$$$ to $$$(n,b_n)$$$. We can only make them non-decreasing by making them all equal. However, if two consecutive points are above the line, we can't put them right on the line because we're still moving a point to somewhere above the line. However, if only one point $$$(i,b_i)$$$ is above the line, we can make the segment from $$$(i-1,b_{i-1})$$$ to $$$(i+1,b_{i+1})$$$ completely straight. Therefore, if there are no two consecutive points above the line, we can perform the operation on all points above the line, and the chain will be completely straight. We have shown that the outlined two cases are the only cases in which we can make $$$a$$$ sorted in non-decreasing order.
The problem is solved in $$$\mathcal{O}(n)$$$ time.
#include<bits/stdc++.h>
using namespace std;
using ll=long long;
using pii=pair<int,int>;
#define all(a) a.begin(),a.end()
#define pb push_back
#define sz(a) ((int)a.size())
signed main(){
ios_base::sync_with_stdio(0),cin.tie(0);
int t;cin>>t;
while(t--)
{
ll n; cin >> n;
vector<ll> a(n);
for(int i=0; i<n; ++i) cin >> a[i];
vector<ll> sum(n+1);
for(int i=0; i<n; ++i) sum[i+1]=sum[i]+a[i];
vector<ll> exact(n+1);
exact[0]=exact[n]=1;
bool found=0;
for(int i=1; i<n; ++i){
if(1ll*sum[i]*(n-i)<1ll*(sum[n]-sum[i])*i){
cout << "Yes\n";
found=1;break;
}
if(1ll*sum[i]*(n-i)==1ll*(sum[n]-sum[i])*i){
exact[i]=1;
}
}
if(found)continue;
for(int i=0; i+1<=n; ++i){
if(!exact[i]&&!exact[i+1]){
cout << "No\n";
found=1;break;
}
}
if(found)continue;
cout << "Yes\n";
}
}
2211H - Median Deletion
Problem credits: nifeshe
We can reduce a fixed subarray $$$[l, r]$$$ of $$$p$$$ to two elements: the minimum and the maximum.
The answer is at most $$$5$$$. Try to determine whether we can get the answer of $$$4$$$.
Consider the minimum/maximum in $$$[1, i - 1]$$$ and minimum/maximum in $$$[i + 1, n]$$$. There is only one non-trivial case: $$$[1, 4, 3, 5, 2, 6]$$$ for $$$p_i = 3$$$.
Let $$$a, b$$$ be the positions of prefix minimum and prefix maximum in $$$[1, i - 1]$$$ accordingly, and $$$c, d$$$ be the positions suffix minimum and suffix maximum. WLOG assume that $$$a \lt b$$$. The case is $$$a \lt b \lt i \lt c \lt d$$$, WLOG assume we have to remove $$$p_b$$$ using an element from $$$[i + 1, c - 1]$$$.
Apart from the trivial cases the condition is this: let $$$l = \max(a, b)$$$ and $$$r = \min(c, d)$$$, then the answer is $$$\le 4$$$ iff there is an element $$$l \le j \le r$$$ such that $$$p_j \lt \min(p_l, p_r)$$$ or $$$p_j \gt \max(p_l, p_r)$$$.
To determine if it's $$$3$$$ consider two cases: $$$\text{pos}_1 \lt i \lt \text{pos}_n$$$ and $$$\text{pos}_1 \lt \text{pos}_n \lt i$$$. The first case is significantly easier.
If the answer is at most $$$4$$$ when $$$\text{pos}_1 \lt i \lt \text{pos}_n$$$, we can reduce $$$[\text{pos}_1, \text{pos}_n]$$$ to only $$$[1, p_i, n]$$$.
If there is an extremum before $$$\text{pos}_1$$$ or after $$$\text{pos}_n$$$, we can't do anything about it. Now consider the $$$\text{pos}_1 \lt \text{pos}_n \lt i$$$ case.
The two main cases are: $$$[1, n, p_i, H, L]$$$ and $$$[1, n, p_i, L, H]$$$, where $$$L = p_c$$$ and $$$H = p_d$$$. Consider $$$[1, n, p_i, L, H]$$$ first.
We can remove any element bigger than $$$p_i$$$ using $$$n$$$. Since the answer is at least $$$4$$$, we can remove $$$L$$$. After that we remove $$$H$$$ using $$$n$$$, so the answer is $$$3$$$. Now consider $$$[1, n, p_i, H, L]$$$
We could easily remove $$$H$$$ using $$$n$$$, however after that we wouldn't be able to remove $$$L$$$. It is sometimes possible to remove both, consider $$$p = [1, 7, 2, 6, 4, 5, 3]$$$ for $$$p_i = 4$$$.
We do $$$[1, 7, 2, 6, 4, 5, 3] \rightarrow [1, 7, 2, 6, 4, 3] \rightarrow [1, 7, 2, 4, 3] \rightarrow [1, 7, 2, 4, 3] \rightarrow [1, 7, 2, 4] \rightarrow [1, 7, 4]$$$. So we need to find indices $$$j$$$ and $$$k$$$ such that: $$$\text{pos}_n \lt k \lt j \lt i$$$, $$$p_k \lt L \lt p_i \lt H \lt p_j$$$, and we can first clear $$$[j + 1, i - 1]$$$ and then clear $$$[k + 1, j]$$$. Greedy does not work as we have to be able to clear the intervals. For example, for $$$p = [1, 8, 3, 7, 2, 5, 6, 4]$$$ and $$$p_i = 5$$$ the answer is $$$4$$$, not $$$3$$$, as we cannot remove $$$2$$$ after choosing $$$p_k = 3$$$ and $$$p_j = 7$$$.
Choose $$$k$$$ to be the minimum in $$$[\text{pos}_n, i]$$$, $$$j$$$ to be the maximum in $$$[k + 1, i]$$$, then you can always clear the intervals.
First of all, we trivially can never delete $$$1$$$ or $$$n$$$, since they are always the smallest and the largest elements. Furthermore, for a fixed subarray $$$[l, r]$$$, where $$$p_x$$$ is the minimum and $$$p_y$$$ is the maximum in the subarray, we can trivially turn it $$$[p_l, p_{l + 1}, \ldots, p_r]$$$ into $$$[p_x, p_y]$$$ or $$$[p_y, p_x]$$$ (depending on their order) by continuously applying operation on the subarray. We call that sequence operations a reduction of $$$[l, r]$$$.
From this immediately follows that the answer for any $$$p_i$$$ is at most $$$5$$$: leave at most $$$2$$$ elements in $$$[1, i - 1]$$$, leave $$$p_i$$$, and at most $$$2$$$ elements in $$$[i + 1, n]$$$. Moreover, if $$$p_i$$$ is not $$$1$$$ or $$$n$$$, the answer is at least $$$3$$$, since we can't delete $$$1$$$ or $$$n$$$. Therefore, the problem is determining whether the answer is $$$3$$$, $$$4$$$ or $$$5$$$ (for $$$p_i = 1$$$ or $$$p_i = n$$$ it is trivially $$$2$$$).
Let's try to determine if we can get an answer $$$\le 4$$$ first. Let's get rid of the trivial cases first: if $$$p_i$$$ is suffix/prefix minimum/maximum, one of $$$[1, i]$$$ or $$$[i, n]$$$ can be reduced to only $$$2$$$ elements, and the other part can be reduced to $$$2$$$ elements as well, so an answer of $$$4$$$ can be trivially achieved.
Now assume that $$$p_i$$$ is not a suffix/prefix minimum/maximum. Let $$$a, b$$$ be the positions of prefix minimum and prefix maximum in $$$[1, i - 1]$$$ accordingly, and $$$c, d$$$ be the positions suffix minimum and suffix maximum. WLOG assume that $$$a \lt b$$$, so the prefix minimum appears earlier than the prefix maximum.
Notice that since $$$i$$$ is not an extrema we must have $$$p_a, p_c \lt p_i \lt p_b, p_d$$$. Therefore, if $$$d \lt c$$$ we can reduce both $$$[1, i - 1]$$$ and $$$[i + 1, n]$$$, and then do an operation on $$$[p_b, p_i, p_d]$$$ which will delete either $$$p_b$$$ or $$$p_d$$$ and achieve an answer of $$$4$$$.
Therefore assume that the elements are positioned as $$$[\ldots, p_a, \ldots, p_b, \ldots, p_i, \ldots, p_c, \ldots, p_d, \ldots]$$$. Notice that we cannot remove $$$p_a$$$ or $$$p_d$$$ without removing $$$p_i$$$, $$$p_b$$$ or $$$p_c$$$. For example to delete $$$p_a$$$ we need an element greater than $$$p_a$$$, and the next one can only be located after $$$p_i$$$, so we have to remove either $$$p_b$$$ or $$$p_i$$$.
Therefore we need to remove $$$p_b$$$ or $$$p_c$$$. WLOG assume that we are trying to remove $$$p_b$$$ first. We cannot do that only with elements in $$$[1, i]$$$, so assume that we use an index $$$i \lt j \lt c$$$ for that. We perform an operation on $$$[p_b, p_i, p_j]$$$. This deletes $$$p_b$$$ iff $$$p_b \lt p_j$$$.
Therefore, there needs be an index $$$j$$$ satisfying $$$i \lt j \lt c$$$ and $$$p_j \gt p_b$$$ for $$$p_b$$$ to be deletable. For simplicity, take $$$j$$$ to be the maximum of $$$[i, c]$$$. Then we can achieve an answer of $$$4$$$ this way: reduce $$$[i + 1, c]$$$ which will leave us with $$$[p_j, p_c]$$$, reduce $$$[1, i - 1]$$$, reduce $$$[c, n]$$$. After this we end up with $$$[p_a, p_b, p_i, p_j, p_c, p_d]$$$. Remove $$$p_b$$$ in $$$[p_b, p_i, p_j]$$$ and then remove $$$p_j$$$ in $$$[p_j, p_c, p_d]$$$. At the end we will have $$$[p_a, p_i, p_c, p_d]$$$.
The case of removing $$$p_c$$$ is identical. Therefore we have a complete solution for determining whether the answer is $$$\le 4$$$. A simple way to frame it is this: let $$$l$$$ be $$$\max(a, b)$$$ and $$$r$$$ be $$$\min(c, d)$$$. The answer is $$$3$$$ or $$$4$$$ iff one of the following holds: $$$i = l$$$, $$$i = r$$$, $$$\max([p_l, p_{l + 1}, \ldots, p_r]) \gt \max(p_l, p_r)$$$ or $$$\min([p_l, p_{l + 1}, \ldots, p_r]) \lt \min(p_l, p_r)$$$. The last two conditions mean that there is an element that we can use to remove $$$p_l$$$ or $$$p_r$$$.
Now we have to determine if the answer is $$$3$$$ or $$$4$$$. From now assume that the condition above holds. Note that to get $$$3$$$ we have to end up with exactly $$$3$$$ elements: $$$1$$$, $$$n$$$ and $$$p_i$$$. Denote $$$\text{pos}_x = i$$$ as $$$i$$$ such that $$$p_i = x$$$. WLOG assume that $$$\text{pos}_1 \lt \text{pos}_n$$$. Consider two cases: $$$\text{pos}_1 \lt i \lt \text{pos}_n$$$ and $$$\text{pos}_n \lt i$$$. The case of $$$\text{pos}_1 \gt i$$$ is identical to $$$\text{pos}_n \lt i$$$.
Consider $$$\text{pos}_1 \lt i \lt \text{pos}_n$$$ first. Notice that we can remove everything in $$$[\text{pos}_1, \text{pos}_n]$$$ while keeping $$$p_i$$$. Since the answer is $$$\le 4$$$ we can leave at most $$$4$$$ elements in $$$[\text{pos}_1, \text{pos}_n]$$$, let them be $$$1$$$, $$$n$$$, $$$p_i$$$ and $$$p_j$$$. Then if $$$p_i \lt p_j$$$ we remove $$$p_j$$$ using $$$n$$$ and if $$$p_i \gt p_j$$$ we remove it using $$$1$$$. Therefore we only need to make sure that there is nothing left in $$$[1, \text{pos}_1 - 1]$$$ and $$$[\text{pos}_n + 1, n]$$$.
Remember that we already proved that if the prefix maximum of $$$[1, i]$$$ is in $$$[1, \text{pos}_1 - 1]$$$ we cannot remove it without removing $$$1$$$, and if the suffix minimum of $$$[i, n]$$$ is in $$$[\text{pos}_n + 1, n]$$$ we cannot remove it without removing $$$n$$$.
Therefore let $$$b$$$ be the index of prefix maximum in $$$[1, i]$$$ and $$$c$$$ be the index of prefix minimum in $$$[i, n]$$$. The answer is $$$3$$$ iff $$$b \ge \text{pos}_1$$$ and $$$c \le \text{pos}_n$$$ and $$$4$$$ otherwise.
Now the last case is $$$\text{pos}_1 \lt \text{pos}_n \lt i$$$. Let $$$a$$$ be the suffix minimum of $$$[i, n]$$$ and $$$b$$$ be the suffix maximum, and $$$p_a = L$$$ and $$$p_b = H$$$.
Let's get rid of trivial cases. If $$$a = i$$$ we can reduce $$$[\text{pos}_n, n]$$$ and then $$$[1, \text{pos}_n]$$$ to get an answer of $$$3$$$. If $$$b = i$$$ we need to remove $$$p_a$$$ with something in $$$[\text{pos}_n, i - 1]$$$. Similarly to our solution for $$$\le 4$$$ we need $$$\min(p_{\text{pos}}, \ldots, p_{i - 1}) \lt p_a$$$ for this, which is sufficient.
Now assume $$$a \neq i$$$ and $$$b \neq i$$$. If $$$a \lt b$$$, since the answer is $$$\le 4$$$ we can remove $$$p_a$$$ using $$$[\text{pos}_n, i - 1]$$$, so the case is the same as $$$a = i$$$ and is always $$$3$$$.
The only case left is $$$b \lt a$$$, which is $$$[1, n, p_i, H, L]$$$. We need to remove $$$H$$$ using $$$[\text{pos}_n, i - 1]$$$ and then remove $$$L$$$ using that same interval. Assume we will remove $$$H$$$ using $$$p_j$$$ and $$$L$$$ using $$$p_k$$$.
To do this we need to have $$$p_k \lt L \lt H \lt p_j$$$. Since we first remove $$$H$$$ then $$$L$$$, we need to clear $$$[j + 1, i - 1]$$$ without removing $$$p_k$$$, therefore we also need to have $$$k \lt j$$$. We also need to clear $$$[k + 1, j]$$$ after that to remove $$$L$$$.
Claim: it is optimal to choose $$$k$$$ to be the index of minimum in $$$[\text{pos}_n, i]$$$. Suppose we don't and the index of the minimum is $$$l$$$.
If we choose $$$k \lt l$$$ we cannot clear $$$[k + 1, j]$$$ since we cannot delete $$$l$$$: $$$[i + 1, b - 1]$$$ can't be used for that because it needs to be cleared to remove $$$H = p_b$$$, and $$$[1, \text{pos}_n - 1]$$$ can't be used as well because $$$n$$$ and $$$p_k$$$ cannot be removed.
Therefore, $$$p_k \ge p_l$$$ and $$$p_j \le \max(p_{l + 1}, \ldots, p_i)$$$. Notice that choosing $$$k$$$ and $$$j$$$ to be exactly these value is always optimal: we can clear $$$[j + 1, i - 1]$$$ by reducing $$$[k, i - 1]$$$, and then remove $$$p_j$$$ in $$$[n, p_k, p_j]$$$. Since we need to have $$$p_k \lt L \lt H \lt p_j$$$, minimizing $$$p_k$$$ and maximizing $$$p_j$$$ is needed.
Therefore, the condition is: let $$$k$$$ be the minimum in $$$[\text{pos}_n, i]$$$ and $$$j$$$ be the maximum in $$$[k + 1, i]$$$. Then the answer is $$$3$$$ iff $$$p_k \lt L \lt H \lt p_j$$$ and $$$4$$$ otherwise. This covers all the cases and solves the problem.
The final solution is $$$O(n)$$$ or $$$O(n \log n)$$$ depending on the implementation. It can be implemented without considering too much symmetrical cases, refer to the code below.
#include <bits/stdc++.h>
using namespace std;
const int LG = 20;
vector<int> get_default(vector<int> p) {
int n = p.size();
vector<int> pos(n + 1);
for(int i = 0; i < n; i++) pos[p[i]] = i;
vector<int> ans(n, 5);
int pos_1 = pos[1], pos_n = pos[n];
if(pos_1 > pos_n) return ans;
vector<int> pos_suff_min(n, n - 1), pos_suff_max(n, n - 1);
for(int i = n - 2; ~i; i--) {
pos_suff_min[i] = pos_suff_min[i + 1];
if(p[i] < p[pos_suff_min[i]]) pos_suff_min[i] = i;
pos_suff_max[i] = pos_suff_max[i + 1];
if(p[i] > p[pos_suff_max[i]]) pos_suff_max[i] = i;
}
vector<int> pos_pref_min(n), pos_pref_max(n);
for(int i = 1; i < n; i++) {
pos_pref_min[i] = pos_pref_min[i - 1];
if(p[i] < p[pos_pref_min[i]]) pos_pref_min[i] = i;
pos_pref_max[i] = pos_pref_max[i - 1];
if(p[i] > p[pos_pref_max[i]]) pos_pref_max[i] = i;
}
vector<vector<int>> t_min(n, vector<int>(LG));
for(int i = 0; i < n; i++) t_min[i][0] = p[i];
for(int l = 1; l < LG; l++) {
for(int i = 0; i + (1 << l) <= n; i++) {
t_min[i][l] = min(t_min[i][l - 1], t_min[i + (1 << l - 1)][l - 1]);
}
}
auto get_min = [&](int l, int r) {
int L = __lg(r - l + 1);
return min(t_min[l][L], t_min[r - (1 << L) + 1][L]);
};
vector<vector<int>> t_max(n, vector<int>(LG));
for(int i = 0; i < n; i++) t_max[i][0] = p[i];
for(int l = 1; l < LG; l++) {
for(int i = 0; i + (1 << l) <= n; i++) {
t_max[i][l] = max(t_max[i][l - 1], t_max[i + (1 << l - 1)][l - 1]);
}
}
auto get_max = [&](int l, int r) {
int L = __lg(r - l + 1);
return max(t_max[l][L], t_max[r - (1 << L) + 1][L]);
};
for(int i = pos_1; i < n; i++) {
if(p[i] == 1 || p[i] == n) {
ans[i] = 2;
continue;
}
if(i == 0 || i == n - 1) {
ans[i] = 3;
continue;
}
int a = pos_pref_min[i], b = pos_pref_max[i];
int c = pos_suff_min[i], d = pos_suff_max[i];
int l = max(a, b), r = min(c, d);
int min_all = get_min(l, r), max_all = get_max(l, r);
if(l == i && r == i) {
ans[i] = 3;
continue;
}
if(l == i || r == i) ans[i] = 4;
if(abs(p[r] - p[l]) != max_all - min_all) ans[i] = 4;
if(ans[i] != 4) continue;
// 1 p[i] n
if(i < pos_n) {
// H 1 p[i] n
if(b < pos_1) continue;
// 1 p[i] n L
if(c > pos_n) continue;
ans[i] = 3;
continue;
}
// 1 n p[i]
// 1 n p[i] H
if(pos_suff_min[i] == i) ans[i] = 3;
// 1 n p[i] L H, can't remove L
if(get_min(l, i) > p[pos_suff_min[i]]) continue;
// 1 n p[i] L, can remove L
if(r == i) ans[i] = 3;
// 1 n p[i] L H, first remove L, then H
if(c < d) ans[i] = 3;
// 1 n p[i] H L, pick k and j
int k = pos[get_min(pos_n, i)];
int j = pos[get_max(k, i)];
if(p[k] < p[c] && p[d] < p[j]) ans[i] = 3;
}
for(auto &i : ans) i = min(i, n);
return ans;
}
vector<int> get(vector<int> p) {
int n = p.size();
vector<int> ans(n, n);
for(int t_reverse = 0; t_reverse < 2; t_reverse++) {
for(int t_invert = 0; t_invert < 2; t_invert++) {
auto curr_ans = get_default(p);
if(t_reverse) reverse(curr_ans.begin(), curr_ans.end());
for(int i = 0; i < n; i++) ans[i] = min(ans[i], curr_ans[i]);
for(auto &i : p) i = n + 1 - i;
}
reverse(p.begin(), p.end());
}
return ans;
}
void solve() {
int n;
cin >> n;
vector<int> p(n);
for(auto &i : p) {
cin >> i;
}
auto ans = get(p);
for(auto i : ans) cout << i << " "; cout << '\n';
}
signed main() {
ios_base::sync_with_stdio(0); cin.tie(0);
int ttt = 1;
cin >> ttt;
while(ttt--) {
solve();
}
}