Hello, Codeforces!
Following the recent motivation of writing educational blogs thanks to peltorator (context), I decided to write another blog on strings, specifically on variations of the very classic String Matching Problem.
Prerequisites
1. KMP — cp-algorithms
2. Aho-Corasick — cp-algorithms
3. FFT — blog by -is-this-fft-
Throughout this blog, $$$n$$$ will be the size of the text (or sum of sizes of texts, if applicable), and $$$m$$$ will be the same for the pattern.
Simple Pattern Matching
Input: text $$$T$$$, pattern $$$P$$$.
Updates: none.
Query: in which positions does $$$P$$$ occur in $$$T$$$?
This is just KMP.
Complexity: $$$\mathcal O(n + m)$$$
Multiple Patterns
Input: text $$$T$$$, several patterns $$$P_i$$$.
Updates: none.
Query: what is the total number of occurrences of all $$$P_i$$$'s in $$$T$$$?
This is just Aho-Corasick.
Complexity: $$$\mathcal O((n + m) \log |\Sigma|)$$$
Adding and Removing Patterns
Input: several texts $$$T_i$$$, several patterns $$$P_j$$$.
Updates: add / remove pattern $$$P_j$$$ to a set $$$S$$$.
Query: what is the total number of occurrences of strings in $$$S$$$ in $$$T_i$$$?
This is 710F - String Set Queries.
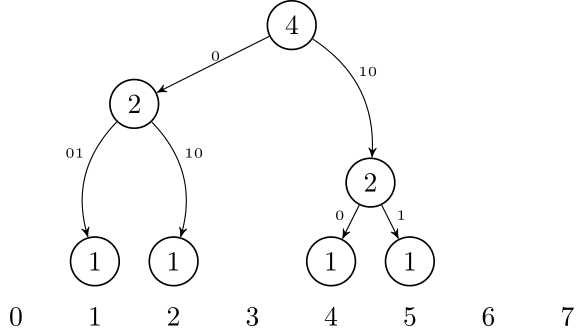
Let's first consider only the addition of strings. What we can do is maintain several Aho-Corasick (AC) structures: for every $$$p$$$, we will have at most one AC with $$$2^p$$$ strings, so we have at most $$$\log m$$$ non-empty ACs. We will do this in the following manner: $$$p$$$'s with non-empty AC of size $$$2^p$$$ will be the binary representation of the number of strings we already added.
For example, if we currently have 6 strings, we will have one AC with 2 strings and another with 4 strings. So, how do we add a string? If we do not have an AC with size 1, we just create a new AC with this string. Now suppose there is already an AC with size one. If there is no AC with size 2, we just delete the AC with size 1 and create a new AC from scratch with these 2 strings. So it is basically binary incrementation: we take all strings in the suffix of active ACs, destroy the ACs and create a new AC with all these strings.
Detailed exampleInitially we have 6 strings, v, w, r, s, t, u. They are in two separate ACs of sizes 2 and 4.
2 -> {v, w}
4 -> {r, s, t, u}
Adding x:
1 -> {x}
2 -> {v, w}
4 -> {r, s, t, u}
Adding y:
1 -> {y}
1 -> {x}
2 -> {v, w}
4 -> {r, s, t, u}
2 -> {x, y}
2 -> {v, w}
4 -> {r, s, t, u}
4 -> {v, w, x, y}
4 -> {r, s, t, u}
8 -> {r, s, t, u, v, w, x, y}
We can easily see that each string can be promoted at most $$$\log m$$$ times, and its contribution to the time complexity is its size times the number of times it is promoted. Therefore, we pay in total $$$\mathcal O(m \log m)$$$ time to build the ACs. For the query, we just sum over the query in all ACs, so this costs us $$$\mathcal O(n \log m)$$$ time.
Finally, to remove strings, just create another instance of this data structure and subtract the queries.
Complexity: $$$\mathcal O((n+m) \log m \log|\Sigma|)$$$
Code: 133199770
Pattern Query
Input: text $$$T$$$, several patterns $$$P_i$$$.
Updates: none.
Query: how many times does $$$P_i$$$ occur in $$$T$$$? This query needs to be answered online, that is, we do not know all $$$P_i$$$'s in advance.
This is the topic of this edu section.
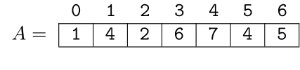
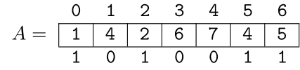
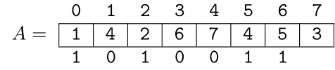
This can be solved with suffix data structures. I will describe a solution using suffix array (SA). First we build the SA of the text. It is not hard to see that the indices of the matches of any pattern are contiguous in the SA, so we associate a pattern with this range (for the empty pattern, the range is $$$[0, n)$$$, and the range is empty for non-occurring patterns).
Now, to find the occurrences of $$$P_i$$$ in $$$T$$$, we process each character of $$$P_i$$$ at a time, and each time we possibly reduce our range. This is easy to do with binary search, since suffixes are sorted. At the end, the number of occurrences of $$$P_i$$$ in $$$T$$$ is the size of the range, and the actual occurrences are the values in the SA in this range.
Complexity: $$$\mathcal O(n + m \log n)$$$
Code: link
Dynamic Pattern
Input: text $$$T$$$, pattern $$$P$$$.
Updates: Change a character in $$$P$$$.
Query: how many times does $$$P$$$ occur in $$$T$$$?
This is a bit trickier and has a lot of nuances. It turns out that if we have the SA range associated with some pattern (and this pattern occurs in the text), we can update the pattern not only with character addition to the right, but also with character removal to the right, and character addition / removal to the left (we can remove several characters at once), all in $$$\mathcal O(\log n)$$$ via binary searches and LCP queries. In fact, if we have the ranges of two patterns, we can compute the range of the concatenation of these patterns in $$$\mathcal O(\log n)$$$!
This breaks if the pattern does not occur in the text, but we can fix this by representing "maximal" occurring pattern substrings: a partition of the pattern such that every part occurs in the text (or is a single character that does not occur), but the concatenation of adjacent parts does not occur. We can maintain this partition in a Treap, for example, and this property is easy to maintain.
To answer the query, if the size of the partition is greater than one, the answer is zero, otherwise it is the size of the single range.
I might write a blog describing how to do this in detail in the future.
Complexity: $$$\mathcal O((n+m) \log (n + m))$$$
Code: 136951123
Dynamic Text
Input: text $$$T$$$, several patterns $$$P_i$$$.
Updates: Add / remove a character to the beginning of $$$T$$$.
Query: how many times does $$$P_i$$$ occur in $$$T$$$?
It turns out that we can maintain the SA of the text under these updates. I explained how to do this in [Tutorial] Dynamic Suffix Arrays.
Complexity: $$$\mathcal O((n+m) \log n)$$$
At most $$$k$$$ mismatches
Input: text $$$T$$$, pattern $$$P$$$, integer $$$k$$$.
Updates: none.
Query: how many times does $$$P$$$ occur in $$$T$$$, allowing for at most $$$k$$$ character mismatches in each match?
We will solve this using polynomials. Let's compute, for every character in our alphabet $$$\Sigma$$$, the number of characters that the pattern matches with the text for every possible starting position of a match. For example, if the pattern is $$$\tt aba$$$ and the text is $$$\tt aaba$$$, we would like to know that the character $$$\tt a$$$ has one match at position 0 and two at position 1, and for $$$\tt b$$$, zero at position 0 and one at position 1.
So let's fix some character $$$c$$$. We define a polynomial $$$R_c(x) = \sum_i [T[i] == c] x^i$$$, that is, we consider only the positions that are equal to $$$c$$$ in the text. We do the same for the pattern, but reversed: $$$S_c(x) = \sum_i [P[i] == c] x^{|P|-1-i}$$$. It is not hard to see that the coefficient of $$$x^{|P|-1}$$$ of $$$R*S$$$ is equal to the number of characters $$$c$$$ that match if we try to match $$$P$$$ at position 0 in $$$T$$$, the coefficient of $$$x^{|P|}$$$ of $$$R*S$$$ is equal to the number of characters $$$c$$$ that match if we try to match $$$P$$$ at position 1 in $$$T$$$, and so on.
Now we just do this for every character and add the result, and we have how many characters match at every position. This requires $$$|\Sigma|$$$ polynomial multiplications, so we can achieve $$$\mathcal O(|\Sigma| (n+m) \log (n + m))$$$ using FFT.
Complexity: $$$\mathcal O(|\Sigma| (n+m) \log (n + m))$$$
Wildcards
Input: text $$$T$$$, pattern $$$P$$$. Pattern and text may have wildcards, that match with any other character.
Updates: none.
Query: in which positions does $$$P$$$ occur in $$$T$$$?
This solution is described in https://www.informatika.bg/resources/StringMatchingWithFFT.pdf, and it also uses polynomials. First, if we did not have wildcards, one way to solve matching with FFT is to compute, for every $$$i$$$:
$$$ \sum_{j=0}^{m-1}(P[j] - T[i + j])^2 $$$If this value is zero, then all the terms are zero, so we have a match a position $$$i$$$. Now we can expand this out:
$$$ \sum_{j=0}^{m-1}(P[j] - T[i + j])^2 = \sum_{j=0}^{m-1}(P[j]^2 - 2 * P[j] T[i + j] + T[i + j]^2) $$$The first term does not depend on $$$i$$$, so we can trivially precompute it. The last term is also easy to compute, via prefix sums. The middle term can be computed using polynomial multiplication (FFT), as we did on the last problem.
Not we introduce wildcards. If we define the value of the characters such that the wildcard is zero and the other character are positive, we can see that, for matching at position $$$i$$$,
$$$ \sum_{j=0}^{m-1}P[j]T[i+j](P[j] - T[i + j])^2 $$$Gives us what we want: for this to be zero, every term has to be zero, so every character either matches or at least one is a wildcard, which is exactly what we wanted. Expanding it, we get:
$$$ \sum_{j=0}^{m-1}(P[j]^3T[i+j] - 2P[j]^2T[i+j]^2 + P[j]T[i + j]^3) $$$Each of these 3 terms can be computed using FFT: if $$$R$$$ and $$$S$$$ are the polynomials associated with $$$P$$$ and $$$T$$$, respectively (like in the previous problem) the first term can be computed as $$$\lbrace r_i^3\rbrace * S$$$, the second as $$$\lbrace r_i^2\rbrace * \lbrace s_i^2\rbrace $$$, and the last as $$$R * \lbrace s_i^3\rbrace $$$. Here $$$\lbrace r_i^3\rbrace$$$ means cubing each term of the polynomial. We sum this up for each term that we want to check and if we get zero, this means we have a match.
Complexity: $$$\mathcal O((n+m) \log (n + m))$$$
Code: link
Conclusion
We have seen several variations of the String Matching Problem. Other variations can get very complicated very quickly, such as trying to update an arbitrary position in the text and maintain, for example, its Suffix Array.
I hope you could learn something from this blog, and feel free to ask for more details on specific parts if needed.









 $$$\hspace{30pt}$$$
$$$\hspace{30pt}$$$