


I have been trying to understand this code, but still don't get the idea of the implementation.
The question that I am interested in is: Given an integer array, answer queries of the form (li, ri) by returning the number of distinct integers in that subarray. The code that I posted is a solution to the stated problem, plus an additional condition, but I only care for this subproblem.
I thought of an offline solution that answers queries in log n time each — Process each integer value in the array, and create a new interval for each pair of equal value integers that are "close" to one another. E.g. [1,x,x,1,x,1], x != 1 -> when I am processing the value 1, I will create two intervals (0,3), (3,5) Then, the answer to each query is the (ri-li+1) — number of intervals that are within (li, ri)
I could only think of an offline solution to this modified problem using BIT.
The solution from the code seems to handle the queries online. Can anybody help me understand the code?
Thanks!!







there is a similar problem on spoj (DQUERY), you can see the discussion here http://apps.topcoder.com/forums/?module=RevisionHistory&messageID=1369039
You can also check my solution (Offline solution). http://ideone.com/eVutNI
Oh, your offline approach is way simpler than what I envisioned!! That's cool. Right.. if you sort everything ascendingly based on the right endpoints, then to count the number of distinct elements, for each distinct integer you just keep track of the rightmost occurrence, and make this rightmost element have value = 1 in the BIT, else 0. This looks very similar to the code I posted, except that he uses a "persistent segment tree" to do it online, which your topcoder link also mentions.
I will look into the online solution later. Thanks!
By far the simplest way to solve this task is with Mo's algorithm in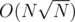 offline.
offline.
http://mirror.codeforces.com/blog/entry/7383
Just sort the queries and keep an array cntx which represents the count of some number. Note you might have to compress the numbers, but you should be easily able to "insert" and "delete" numbers from cnt array in O(1)
I haven't studied much the online solution, but here are few things that might help you.
First things first : study this http://discuss.codechef.com/questions/6548/query-editorial (just the part about persistance)
Now query(L, R) is the number of such numbers that their last occurrence in interval(L, R) is >= L.
Alright, now can you use a segment tree to solve the queries of type (1, R) for every R? I haven't thought much but this step should be possible.
Once we have a segment tree which represent our solution for (1, R) we need a new segment tree that represents the solution in range (2, R), we do this step by updating index[1] of the first segment tree, instead of updating and chaging the tree we just add another path from root to new index[1] with O(logN) (this is the persistent part) nodes and we remember the root. And so on...
After we do the preprocessing for each query (L, R) we just roll-back (or roll-forward) to a segment tree that holds the answers for (L, X) queries, and we just answer for (L, R).
Instead of having O(N2) in segment tree nodes, or N segment trees for (L, R) for every possible L, we have O(NlogN) nodes by using persistent segment tree.
Anyway that should be the main idea behind it, now see if you can do it, is it easier to implement the idea from the front or from the back, or some combination of both etc etc.. It's not an exact solution it's just a rough sketch to understand how persistence could be helpful here.
about d-query link
For a similar problem of spoj:DQUERY you can answer the queries online using persistent segment tree
My AC solution passed in 0.31 seconds
link:http://ideone.com/Ccc8wc