


Thank you for participation! We apologize for problem D that turned out to be harder than expected. Still, we hope that you liked most of the problems.
In case you found C2 tedious to implement or found many cases to deal with, I would recommend you to have a look at the intended solution. I think it is interesting and easy to implement.
It is easy to observe that the second operation needs to be performed at most once. Now, we just need to check $$$2$$$ cases, one in which the re-arrangement operation is used, and one in which it is not.
If the re-arrangement operation is to be used, then we just need to make the counts of $$$0$$$s and $$$1$$$s in $$$a$$$ equal to that of $$$b$$$. Without loss of generality assume $$$a$$$ contains $$$x$$$ more $$$0$$$s than $$$b$$$, then the cost in this case will just be $$$x + 1$$$ (extra one for re-arrangement cost).
If the re-arrangement operation is not to be used, then we just need to make each element of $$$a$$$ equal to the corresponding element of $$$b$$$.
Finally, our answer is the smaller cost of these $$$2$$$ cases.
Time complexity is $$$O(n)$$$.
#include <bits/stdc++.h>
using namespace std;
#define ll long long
void solve(){
ll n; cin>>n;
ll sum=0,ans=0;
vector<ll> a(n),b(n);
for(auto &it:a){
cin>>it;
sum+=it;
}
for(auto &it:b){
cin>>it;
sum-=it;
}
for(ll i=0;i<n;i++){
ans+=(a[i]^b[i]);
}
ans=min(ans,1+abs(sum));
cout<<ans<<"\n";
}
int main()
{
ios_base::sync_with_stdio(false);
cin.tie(NULL);
ll t; cin>>t;
while(t--){
solve();
}
}
Take $$$a_0 = a_{n+1} = 1$$$.
Now take $$$b_i=lcm(a_{i-1},a_i)$$$ for $$$1 \leq i \leq n+1$$$. If $$$b$$$ gives us $$$a$$$ after performing the $$$\gcd$$$ operations, then the answer is YES, otherwise the answer is NO. (When answer is NO, we would get a case like $$$\gcd(b_i, b_{i + 1}) = k \cdot a_i$$$(where $$$k \gt 1$$$ for some $$$i$$$).
Suppose $$$c$$$ is some valid array which gives us $$$a$$$. So, $$$c_i$$$ should be divisible by $$$b_i$$$. This means $$$\gcd(c_i, c_{i+1}) \geq \gcd(b_i, b_{i + 1})$$$.
So, if $$$\gcd(b_i, b_{i + 1}) \gt a_i$$$ for any $$$i$$$, we should also have $$$\gcd(c_i, c_{i+1}) \gt a_i$$$. This implies that $$$c$$$ is not valid if $$$b$$$ is not valid.
Time complexity is $$$O(n \cdot \log(bmax))$$$.
#include <bits/stdc++.h>
using namespace std;
#define ll long long
ll lcm(ll a,ll b){
ll g=__gcd(a,b);
return (a*b/g);
}
void solve(){
ll n; cin>>n;
vector<ll> a(n+2,1);
for(ll i=1;i<=n;i++){
cin>>a[i];
}
vector<ll> b(n+2,1);
for(ll i=1;i<=n+1;i++){
b[i]=lcm(a[i],a[i-1]);
}
for(ll i=1;i<=n;i++){
if(__gcd(b[i],b[i+1])!=a[i]){
cout<<"NO\n";
return;
}
}
cout<<"YES\n";
}
int main()
{
ios_base::sync_with_stdio(false);
cin.tie(NULL);
ll t; cin>>t;
while(t--){
solve();
}
}
1736C1 - Good Subarrays (Easy Version)
Suppose $$$l[i]$$$ represents the leftmost point such that subarray $$$a[l[i],i]$$$ is good.
Notice that the array $$$l$$$ is non-decreasing.
So suppose $$$dp[i]$$$ denotes the length of longest good subarray which ends at index $$$i$$$.
Take $$$dp[0]=0$$$.
Now $$$dp[i]=min(dp[i-1]+1,a[i])$$$.
Suppose $$$a[i] \geq dp[i-1]+1$$$. Now we claim that $$$dp[i]=dp[i-1]+1$$$. We know $$$a[i-dp[i-1],i-1]$$$ is \t{good}. Now if we look at array $$$b=a[i-dp[i-1],i]$$$, $$$b_i \geq i $$$ for $$$ 1 \leq i \leq dp[i-1]$$$. For $$$b$$$ to be good, last element of $$$b$$$(which is $$$a[i]$$$) should be greater than or equal $$$dp[i-1]+1$$$(which is consistent with our supposition). So $$$b$$$ is good.
We can similarly cover the case when $$$a[i] \lt dp[i-1]+1$$$.
So our answer is $$$ \sum_{i=1}^{n} dp[i]$$$. Time complexity is $$$O(n)$$$.
#include <bits/stdc++.h>
using namespace std;
#define ll long long
void solve(){
ll n; cin>>n;
vector<ll> dp(n+5,0);
ll ans=0;
for(ll i=1;i<=n;i++){
ll x; cin>>x;
dp[i]=min(dp[i-1]+1,x);
ans+=dp[i];
}
cout<<ans<<"\n";
}
int main()
{
ios_base::sync_with_stdio(false);
cin.tie(NULL);
ll t; cin>>t;
while(t--){
solve();
}
}
1736C2 - Good Subarrays (Hard Version)
Let us continue the idea of C1.
Suppose $$$track[i]$$$ denotes $$$\sum_{j=i}^{n} dp[j]$$$ if $$$dp[i]=a[i]$$$.
We can precalculate array $$$track$$$.
Now suppose $$$a_p$$$ is changed to $$$x$$$ and $$$adp[i]$$$ denotes the length of longest good subarray which ends at index $$$i$$$ in the updated array.
It is easy to see that $$$adp[i]=dp[i]$$$ for $$$ 1 \leq i \lt p$$$. Now let $$$q$$$ be the smallest index greater than $$$p$$$ such that $$$adp[q]=a[q]$$$(It might be the case that there does not exist any such $$$q$$$ which can be handled similarly). So we have $$$3$$$ ranges to deal with — $$$(1,p-1)$$$, $$$(p,q-1)$$$ and $$$(q,n)$$$.
Now $$$\sum_{i=1}^{p-1} adp[i]$$$ = $$$\sum_{i=1}^{p-1} dp[i]$$$(which can be stored as prefix sum).
Also $$$\sum_{i=q}^{n} adp[i]$$$ = $$$track[q]$$$.
Now we only left with range $$$(p,q-1)$$$. An interesting observation is $$$adp[i]=adp[i-1]+1$$$ for $$$p \lt i \lt q$$$.
This approach can be implemented neatly in many ways(one way is answer each query offline).
Time complexity is $$$O(n \cdot \log(n))$$$.
#include <bits/stdc++.h>
using namespace std;
#define ll long long
#define f first
#define s second
int main()
{
ios_base::sync_with_stdio(false);
cin.tie(NULL);
ll n; cin>>n;
vector<ll> track(n+5,0),sum(n+5,0);
vector<pair<ll,pair<ll,ll>>> trav;
vector<ll> pref(n+5,0),dp(n+5,0);
for(ll i=1;i<=n;i++){
ll x; cin>>x;
sum[i]=sum[i-1]+i; trav.push_back({x-i,{i,0}});
dp[i]=min(dp[i-1]+1,x); pref[i]=pref[i-1]+dp[i];
}
ll q; cin>>q;
vector<ll> ans(q+5,0);
for(ll i=1;i<=q;i++){
ll p,x; cin>>p>>x; x=min(dp[p-1]+1,x);
trav.push_back({x-p,{p,i}});
}
set<ll> found; found.insert(n+1);
sort(trav.begin(),trav.end());
for(auto it:trav){
if(it.s.s){
ll r=*found.upper_bound(it.s.f);
ans[it.s.s]=pref[it.s.f-1]+track[r]+sum[r-it.s.f]+(it.f+it.s.f-1)*(r-it.s.f);
}
else{
ll r=*found.lower_bound(it.s.f); found.insert(it.s.f);
track[it.s.f]=track[r]+sum[r-it.s.f]+(it.f+it.s.f-1)*(r-it.s.f);
}
}
for(ll i=1;i<=q;i++){
cout<<ans[i]<<"\n";
}
}
#include <bits/stdc++.h>
#include <ext/pb_ds/tree_policy.hpp>
#include <ext/pb_ds/assoc_container.hpp>
using namespace __gnu_pbds;
using namespace std;
#define ll long long
const ll INF_MUL=1e13;
const ll INF_ADD=1e18;
#define pb push_back
#define mp make_pair
#define nline "\n"
#define f first
#define s second
#define pll pair<ll,ll>
#define all(x) x.begin(),x.end()
#define vl vector<ll>
#define vvl vector<vector<ll>>
#define vvvl vector<vector<vector<ll>>>
#ifndef ONLINE_JUDGE
#define debug(x) cerr<<#x<<" "; _print(x); cerr<<nline;
#else
#define debug(x);
#endif
const ll MOD=1e9+7;
const ll MAX=100010;
ll cal(ll n){
ll now=(n*(n+1))/2;
return now;
}
class ST {
public:
vector<ll> segs;
ll size = 0;
ll ID = INF_ADD;
ST(ll sz) {
segs.assign(2 * sz, ID);
size = sz;
}
ll comb(ll a, ll b) {
return min(a, b);
}
void upd(ll idx, ll val) {
segs[idx += size] = val;
for(idx /= 2; idx; idx /= 2) segs[idx] = comb(segs[2 * idx], segs[2 * idx + 1]);
}
ll query(ll l, ll r) {
ll lans = ID, rans = ID;
for(l += size, r += size + 1; l < r; l /= 2, r /= 2) {
if(l & 1) lans = comb(lans, segs[l++]);
if(r & 1) rans = comb(segs[--r], rans);
}
return comb(lans, rans);
}
};
void solve(){
ll n; cin>>n;
vector<ll> a(n+5,0),use(n+5,0),pref(n+5,0);
for(ll i=1;i<=n;i++){
cin>>a[i];
use[i]=min(use[i-1]+1,a[i]); pref[i]=pref[i-1]+use[i];
}
ST segtree(n+5);
auto get=[&](ll l,ll r,ll till,ll pos,ll tar){
while(l<=r){
ll mid=(l+r)/2;
if(segtree.query(pos,mid)>=tar){
till=mid,l=mid+1;
}
else{
r=mid-1;
}
}
return till;
};
vector<ll> track(n+5,0);
for(ll i=n;i>=1;i--){
segtree.upd(i,a[i]-i); ll till=get(i,n,i,i,a[i]-i);
track[i]=track[till+1]+cal(a[i]+till-i)-cal(a[i]-1);
}
ll q; cin>>q;
while(q--){
ll p,x; cin>>p>>x; ll target=min(x,use[p-1]+1);
ll till=get(p+1,n,p,p+1,target-p);
ll ans=pref[p-1]+track[till+1]+cal(target+till-p)-cal(target-1);
cout<<ans<<nline;
}
return;
}
int main()
{
ios_base::sync_with_stdio(false);
cin.tie(NULL);
#ifndef ONLINE_JUDGE
freopen("input.txt", "r", stdin);
freopen("output.txt", "w", stdout);
freopen("error.txt", "w", stderr);
#endif
ll test_cases=1;
//cin>>test_cases;
while(test_cases--){
solve();
}
cout<<fixed<<setprecision(10);
cerr<<"Time:"<<1000*((double)clock())/(double)CLOCKS_PER_SEC<<"ms\n";
}
1736D - Equal Binary Subsequences
It is easy to see that a necessary condition for a solution to exist is that the number of $$$1$$$ in $$$s$$$ should be even. It turns out that this condition is sufficient too.
Here is one valid construction:
We make $$$n$$$ pairs of the form $$$(s[2i-1],s[2i])$$$ for $$$(1 \leq i \leq n)$$$.
Assume we have $$$x$$$ pairs in which both elements are different and $$$n-x$$$ pairs in which both elements are same.
\textbf{Claim} — $$$x$$$ should be even.
\textbf{Proof} — Assume that among the $$$n-x$$$ pairs in which both elements are same, we have $$$y$$$ pairs in which both elements are $$$1$$$. So number of $$$1$$$ in $$$s$$$ is $$$x+2 \cdot y$$$. We know that number of $$$1$$$ in $$$s$$$ is even, so for $$$x+2 \cdot y$$$ to be even, $$$x$$$ should also be even.
Now we will select $$$x$$$ indices; exactly one index from each of the $$$x$$$ pairs in which both elements are distinct. Take the index of $$$0$$$ from $$$i_{th}$$$ pair if $$$i$$$ is odd, else take the index of $$$1$$$. Thus our selected characters = $$${0,1,0,1, \dots ,0,1}$$$
Now on cyclically shifting the selected characters clockwise once, we can see that elements at selected indices got flipped.
Since, elements in those $$$x$$$ pairs were distinct initially, and we flipped exactly one character from each of those $$$x$$$ pairs, both elements of those $$$x$$$ pairs are same now.
Hence, in updated $$$s$$$, $$$s[2i-1]=s[2i]$$$.
So, for $$$s_1$$$, we can select characters of all odd indices.
Finally we'll have $$$s_1 = s_2$$$. Time complexity is $$$O(n)$$$.
#include <bits/stdc++.h>
using namespace std;
#define ll long long
void solve(){
ll n; cin>>n;
string s; cin>>s;
ll freq=0;
vector<ll> ans;
ll need=0;
for(ll i=0;i<2*n;i+=2){
if(s[i]!=s[i+1]){
freq++;
ans.push_back(i+1);
if(s[i]-'0'!=need){
ans.back()++;
}
need^=1;
}
}
if(freq&1){
cout<<"-1\n";
return;
}
cout<<ans.size()<<" ";
for(auto it:ans){
cout<<it<<" ";
}
cout<<"\n";
for(ll i=1;i<=2*n;i+=2){
cout<<i<<" \n"[i+1==2*n];
}
}
int main()
{
ios_base::sync_with_stdio(false);
cin.tie(NULL);
ll t; cin>>t;
while(t--){
solve();
}
}
As the constraints suggest, we should use dp to solve this problem.
Let's write the original indices of the array that are added during this process — $$$p_1, p_2, \ldots, p_n$$$. None of added numbers are zeroed in an optimal answer. It gives that $$$p_1 \le p_2 \le \ldots \le p_n$$$ and the answer is equal to the sum of $$$a[p_k]$$$ ($$$1 \leq k \leq n$$$).
To get the optimal answer we'll use $$$dp[t][last][m]$$$ = maximum score on $$$t$$$-th turn if $$$p_t = last$$$ and we have performed $$$m$$$ swapping moves (the first dimension can be omitted). Note that $$$m \leq i$$$. It can be updated by considering the next index but it will take $$$O(n^4)$$$. The most straightforward way to improve it to $$$O(n^3)$$$ is to use prefix maximums.
Here are some details.
We have only two cases:
$$$p_t=p_{t-1}$$$ — In this case, our transition is just $$$dp[t][last][m]=dp[t-1][last][m-1]+a[last]$$$
$$$p_t \gt p_{t-1}$$$ — Let us make some observations. First of all, $$$p_t \ge t$$$. So number of swaps to bring $$$p_t$$$ to index $$$t$$$ is fixed. It is $$$p_t-t$$$. So $$$dp[t][last][m]=\max_{j=1}^{last-1} (dp[t-1][j][m-(p_t-t)])+a[last]$$$. Note that we can find $$$\max_{j=1}^{last-1} (dp[t-1][j][m-(p_t-t)])$$$ in $$$O(1)$$$. Hint — use prefix maximum.
Time complexity is $$$O(n^3)$$$.
#include <bits/stdc++.h>
using namespace std;
const int MAX=505;
vector<vector<vector<int>>> dp(MAX,vector<vector<int>>(MAX,vector<int>(MAX,-(int)(1e9))));
int main()
{
int n; cin>>n;
vector<int> a(n+5);
for(int i=1;i<=n;i++){
cin>>a[i];
}
vector<vector<int>> prefix(n+5,vector<int>(n+5,0));
int ans=0;
for(int i=1;i<=n;i++){
for(int j=1;j<=n;j++){
for(int k=0;k<=i;k++){
if(k){
dp[i][j][k]=dp[i-1][j][k-1]+a[j];
}
if(j>=i){
int need=j-i;
if(need>k){
continue;
}
dp[i][j][k]=max(dp[i][j][k],prefix[k-need][j-1]+a[j]);
}
}
}
for(int j=1;j<=n;j++){
for(int k=0;k<=i;k++){
prefix[k][j]=max(prefix[k][j],dp[i][j][k]);
}
}
for(int j=0;j<=i;j++){
for(int k=1;k<=n;k++){
prefix[j][k]=max(prefix[j][k],prefix[j][k-1]);
ans=max(ans,prefix[j][k]);
}
}
}
cout<<ans;
}







Please update the contest announcement page and the contest page to reflect the editorial, some people could not find this and are waiting for it!
i have never seen a post without your comments and shares (LOL) keep going and good luck.
negative contribution god
Why do editorialists still do this? Making it a challenge to read problem solutions without spoiling solutions of other problems that one hasn't solved. Do they not know of the existence of the spoiler option?
As I read the editorial for problem C, I now have an extra challenge to avoid any sneak peak/peripheral vision from wandering by chance/accident to solution for B and C2, both of which lie directly above and below resp. to the solution to the problem I'm reading.
It's pathetic. I wish editorialists weren't this lazy.
Post-Contest Editorial Rage.
Fixed it.
Maybe the way you put it was a bit too harsh, but I really don't know why you are being downvoted to oblivion !? You have raised a valid point.
Is there any better explanation for problem B?
Since a2=gcd(b2,b3), both b2 and b3 has to be divisible by a2 Similarly both b3 and b4 has to be divisible by a3 So the common element which has to be divisible by both a2 and a3 is b3 That's why b3=lcm(a2,a3) Now that you have b3 just check if gcd(b2,b3) is equal to a2 or not. If it is not then answer is "no". Otherwise continue till n
Why can't b3 = a2*a3? Why will this assumption fail?
Let's start with an example... We have an array like 4 3 2 , According to your assumption. array a = 4 3 2 array b = 4 12 6 2 Here you can see a1 is gcd of b1&b2 but a2 & a3 case fail cause gcd of b2 & b3 is not equal to a2 and similar to a3. Hope you understood.
Your explanation is greater than the editorial. thanks:)
Given array a1 a2 a3
Let the output array as
b1 b2 b3 b4
So gcd(b1, b2) = a1
gcd(b2, b3) = a2
gcd(b3, b4) = a3
i.e b1 = x1 * a1
b2 = x2 * a1
Such that gcd(x1, x2) = 1
b2 = x3 * a2
b3 = x4 * a2
Such that gcd(x3, x4) = 1
b3 = x5 * a3
b4 = x6 * a3
Such that gcd(x5, x6) = 1
Now
x2 * a1 = x3 * a2
x2/x3 = a2/a1
=> x2 = a2 / gcd(a1, a2)
=> x3 = a1 / gcd(a1, a2)
Similarly
x4 * a2 = x5 * a3
x4/x5 = a3/a2
=> x4 = a3 / gcd(a2, a3)
=> x5 = a2 / gcd(a2, a3)
X1 and x6 can be any prime number.
Now check whether gcd (x1, x2) = gcd(x3, x4) = gcd(x5, x6) = 1 and if we have passed this criteria the answer will be yes otherwise no.
From x2/x3 = a2/a1 how you were able to conclude that => x2 = a2 / gcd(a1, a2)
=> x3 = a1 / gcd(a1, a2)
C1 binary search approach:
Suppose we have a range [L,R] which isn't a good subarray.
For this range, the worst element is the element a[j] for which a[j]-j is too low (minimum on the range [L,R]).
So we can have another array b for which b[i]=a[i]-i, then we build a Sparse Table over array b. Now we can iterate over all indices of array a, and binary search the farthest length of good subarray [i,R] for all 1<=i<=n.
And because, whatever the minimum b[j] on range [i,R] is going to be, it still shares the same prefix i-1 with all the elements on the range [i,R], then we can check if query(i,R)+i-1 is bigger than or equal to zero, or not, to edit our searched range.
The binary search is going to be like this:
Here is my submission: https://mirror.codeforces.com/contest/1736/submission/175452764
I had same idea :D
shit
屮
I think D and C2 indeed had the correct difficulty for the 4th and 5th problem; the only issue was their positions that confused participants. I'm pretty sure that if participants spent more time on D than C2, there would have been more solves for D.
satyam343, thanks for amazing problems and please fix broken \t{good} in the editorial of C1.
Explanation of c2 with few examples would be helpful.
Fixed it.
I am glad that you found the problems interesting.
C2 was intended to be harder than D. That is why we kept score of C1+C2 high.
Surprisingly we had predicted that this round would be easier than usual Div 2 rounds.
My expected ratings(after testing) were :
A — 800, B — 1200, C1 — 1400, C2 — 2100, D — 1900 and E — 2200
Am I the only one who receives RTE on test 4 for no reason? I tried modifing it with NMAX to 1e3, but it's a long long issue. If I change it in int it receives WA
https://mirror.codeforces.com/contest/1736/submission/175448716
Problem C1 ( Good Subarrays ) Easy O(N) Solution:
some explanation ??
While traversing in the array, I sum the minimum of the index and the element i.e. min(i+1, a[i]) {i+1, because of 1-indexing)
But in this the problem is that if we encounter a number which is smaller than its index, then it gives wrong answer.
E.g. 4 3 1 2 8
While counting for the element 8, it gives min(5, 8) =5, however it should give 3 only, because a smaller element 2 is present ahead it.
So, everytime I encounter such small element, I reduce the effective array by "j" length from starting, which is equal to the difference of index and the element.
So now, when 8 is encountered, the array is thought of 1 2 8, and hence min(3,8) = 3 is added.
Please upvote if helpful, though I'm not quite good in explaining :'(
E is pretty nice, it uses a very similar dp as this problem. link
For problem C1, I have a solution using Segment Tree to maintian the maximum value of a segment. share it. click here
My solution for C1:
Claim: If $$$a[l], a[l+1], ..., a[r]$$$ is a good subarray, then , for all $$$x, y$$$, such that $$$l \le x \le y \le r$$$, we have that $$$a[x], a[x+1], ... a[y]$$$ is a good subarray.
With that claim in mind, let's make a two pointers approach. For all $$$l, r$$$ that the interval $$$[l, r]$$$ is good, we have $$${r-l+2}\choose 2$$$ sub-intervals of $$$[l, r]$$$ that is good. So, lets make the following algorithm:
Code: link
Is there better explanation for C2?
I think I have a simpler code for C2, in which I don't use any complex data structures except simple arrays.
thx, it's a clear idea
Here is an explaination for B I came up with Let a = {a1,a2,a3} b={b1,b2,b3,b4} Since a1 = gcd(b1,b2) => b1 and b2 are multiple of a1 similarly b2 and b3 are multiple of a2
Since b2 is multiple of a1 & a2 => b2 = k1 * lcm(a1,a2) (multiple of lcm) since b3 is multiple of a2 and a3 => b3 = k2 * lcm(a2,a3)
Now a2 = gcd(b2,b3) = gcd(k1*lcm(a1,a2) , k2*lcm(a2,a3)) = GCD GCD will be decided by lcm and multiple factors k1&k2 k1 and k2 can be used to multiply an integer to the gcd(lcm(a1,a2) , lcm(a2,a3))
From the above observation a[2] must be divisible by the GCD (we can set k1 and k2 to reach a[2])
Coulnt do this in contest :(
Link to submission
"From the above observation a[2] must be divisible by the GCD (we can set k1 and k2 to reach a[2])" i'm sorry i'm not able to understand this line
i get it it's about finding k1 and k2 ....but i'm confused can you explain ?
see gcd(k1*lcm(a1,a2) , k2*lcm(a2,a3)) will always have the gcd(lcm(a1,a2),lcm(a2,a3)) rest will be contribute by gcd(k1,k2) the contribution from both the terms must take us to a2
I code part of c1 why declaring dp with size n + 5 when n + 1 can also do the work.
It's a good practice to make your array sizes a bit larger than what you expect their maximum size to be. There isn't much downside to this, since the extra few slots in takes negligible time to declare and it shouldn't affect the correctness of the code if it is based on the actual number of elements (as opposed to the max size).
There are some problems where you discover later that you might need the extra indices, e.g., due to switching between 0-indexing and 1-indexing, or because the nature of your solution to the problem would benefit from stepping further ahead, etc, and it's more convenient to mindlessly declare it as a larger size every time than to rely on consciously adjusting the declaration when you need to, which you might forget (like if you were really deep into writing some part of the solution at the time) or miss (like if there are multiple such arrays affected and you overlook one).
Waiting for 1736E — Swap and Take Editorial!
Added.
Sorry for the delay.
Can anyone explain me what this code is doing ?
In problem C2, what is the offline approach?
Refer to this comment.
Regarding problem C2 : how to find such q ?
Suppose $$$adp[p]=z$$$.
So $$$q$$$ is the smallest index greater than $$$p$$$ such that $$$a_q \leq z + q - p$$$.
Now $$$a_q-q \leq z-p$$$. Note that $$$z-p$$$ is fixed. So you can make a new array $$$b$$$ such that $$$b_i=a_i-i$$$. You can make $$$b$$$ before reading queries. You can use segment tree to find $$$q$$$ now. In the intended solution, I am processing the values in sorted order. Thus this way I was able to avoid segment tree.
Edit: I have included segment tree solution in the editorial.
In the C1 Editorial, what do you mean by a[i−dp[i−1],i−1] and a[i−dp[i−1],i]? Array a is 1D array. But you used comma between the calculation of the array index.
$$$a[l,r]$$$ represents the subarray $$$a_l,a_{l+1}, \dots a_r$$$.
In C1, how can we solve it using two pointers, why is this approach failing :
Is the algorithm mentioned in the editorial for C2 always correct?
Edit after reply: Yes, it is; I just misunderstood the track[i] definition :p
Take n = 10 and a = [8, 8, 8, 8, 8, 8, 1, 8, 8, 8].
Consider the query: p = 7, x = 10
The new a would be b = [8, 8, 8, 8, 8, 8, 10, 8, 8, 8].
dp[i] = min(dp[i-1] + 1, a[i])
adp[i] = min(adp[i-1] + 1, b[i])
dp:
dp[1] = 1
dp[2] = 2
dp[3] = 3
dp[4] = 4
dp[5] = 5
dp[6] = 6
dp[7] = 1
dp[8] = 2
dp[9] = 3
dp[10] = 4
adp:
adp[1] = 1
adp[2] = 2
adp[3] = 3
adp[4] = 4
adp[5] = 5
adp[6] = 6
adp[7] = adp[p] = 7
adp[8] = 8 = a[8]
adp[9] = 8 = a[9]
adp[10] = 8 = a[10]
Let q be the smallest index greater than p such that adp[q] = a[q]. So q = 8.
Indeed, adp[1] + adp[2] + ... + adp[p-1] = dp[1] + dp[2] + ... + dp[p-1].
However, adp[q] + adp[q+1] + ... + adp[n] = adp[8] + adp[9] + adp[10] = 24,
while dp[q] + dp[q+1] + ... + dp[n] = dp[8] + dp[9] + dp[10] = 9.
So, $$$\sum_{\ i=q}^{\ n} adp[i] \neq track[q]$$$!
To further increase my confusion, I ran the code for offline queries with this data and it gave me the right answer. (52)
Is there an error in the solution written in words? Is there an error in my understanding of the editorial? And how is the offline queries code different than the solution in words? (e.g. what is "dp" in the offline queries code, if "len[i] = min(len[i-1]+1, a[i])"?)
Any help would be appreciated!
Here's how you calculate $$$track[8]$$$.
First assume $$$dp[8]=a[8]$$$.
Now $$$dp[9]=min(dp[8]+1,a[9])=8$$$ and $$$dp[10]=min(dp[9]+1,a[10])=8$$$.
So $$$track[8]=dp[8]+dp[9]+dp[10]=24$$$ if $$$dp[8]=a[8]$$$.
For confusion between $$$len$$$ and $$$dp$$$, I have edited the code.
Ah, I had misunderstood the assumption part — I thought track[i] is set to 0 if dp[i] != a[i] and track[i] = dp[i] + dp[i+1] + ... + dp[n] if dp[i] == a[i]... Thanks a lot!
For C2, Could you please explain how to find q both online and offline.
I have figured it out now. But another thing is, how to precalculate the track[i]
Use similar idea which we are using while answering all queries.
Suppose $$$dp[i]=a[i]$$$. Now let $$$q$$$ be the smallest index greater than $$$i$$$ such that $$$dp[q]=a[q]$$$ if $$$dp[i]=a[i]$$$. So $$$track[i]=\sum_{j=i}^{q-1} dp[j] + track[q]$$$. Please note that I am assuming that $$$dp[i]=a[i]$$$(it is hypothetical, so actual values of $$$dp[i]$$$ are different from what we have when we assume $$$dp[i]=a[i]$$$).
Now note that $$$dp[j]=a[i]+j-i$$$ for $$$i \leq j \lt q$$$ if $$$dp[i]=a[i]$$$. So you can easily compute the sum of this arithmetic progression.
Please refer to "Code(Online queries)" in editorial. I hope it would make sense now.
Thank you very much!
In C2, how can I find q (let q be the smallest index greater than p such that adp[q]=a[q])?
Refer to this comment
You need to find the smallest index $$$q$$$ greater than $$$p$$$ such that $$$b_q \leq z-p$$$. You can easiy do it using binary search and range minimum query(which I have used in "Code(Online queries)").
One more question, why do we need track? Because I thought track[i] = prefix[n]-prefix[i-1] (with prefix[i] calculate i first dp value)
Refer to this comment
If we're using binary search and RMQ using segment tree, then the time complexity would be $$$n log^2(n)$$$ instead of $$$n logn$$$ right. I tried something similar, but it was giving TLE, so I had to use sparse table for RMQ to make it $$$nlogn$$$. Is there any other workaround?
Check this out.
Also my binary search + rmq solution runs in less than 600ms. Submission
I find C2 pretty damn good, but would be better if they just get rid of C1 entirely and place C2 as E instead.
I am glad that you liked it (:
I thought putting C1 would result in a balanced round, but sadly it didn't help much :(
I have a way way simpler solution(online) for C2.
We can basically find out for each index i, if i is the start of a subarray, what are the first two bad points (bad points being points at which the given condition gets violated). We can do this in O(n) using queues (just observe monotonicity of bad points wrt starting points). Why is calculating only till the second point important? Because the only increase in answer for some start point happens when its first bad point gets resolved.
Now for each query, we can do some casework, and use prefix sums to calculate delta (this is the easy part so I wont go into it).
Implementation: link
Alternate solution for problem E which has same time complexity as the editorial solution, but uses only $$$O(n^2)$$$ memory:
Key observation:
In atleast one of the optimal solutions, the result of all swap operations can be viewed as the following:
So the array can be modelled as something like: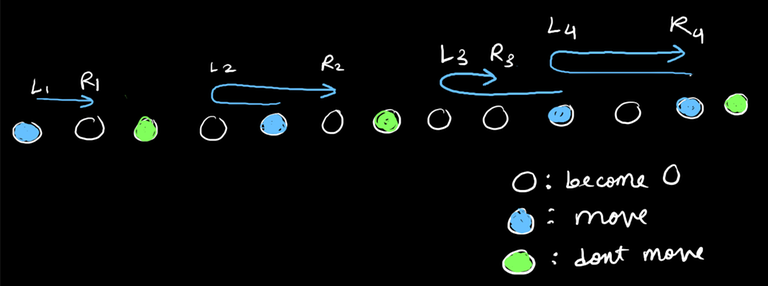
Coming up with DP States and Transitions:
Define the dp state as $$$dp[i][j]$$$, which holds maximum score we can get from the last $$$i$$$ elements, if we need to make atleast $$$j$$$ swaps before the $$$i$$$'th element to be able to transition from this state.
The transitions can be made in the following manner: Iterate over $$$i$$$ from $$$n$$$ to $$$1$$$, and then iterate over $$$L_i$$$ from $$$i$$$ to $$$1$$$, notice that all that really matters about the state which you transition from is its second parameter, so basically maintain an array which stores best possible transition for each value of second parameter, and keep trying to improve it as $$$L_i$$$ decreases.
Implementation: link
Alternative way to solve C2 (actually it is pretty similar to the editorial):
First we need to talk about C1. Let $$$dp_i$$$ is the first position to the left of $$$i$$$ such that $$$a_{dp_i}, a_{dp_i + 1}, ..., a_i$$$ is invalid. Then $$$dp_i = max(dp_{i - 1}, i - a_i)$$$. The answer to C1 is sum of $$$i - dp_i$$$ for all $$$1 \leq i \leq n$$$, or $$$n \cdot (n + 1) / 2 - \sum_{i = 1}^{n} {dp_i}$$$. Submission for C1. If you notice, the $$$dp$$$ array is actually the prefix maximum of $$$i - a_i$$$ for each $$$i$$$. So I use an array $$$b$$$ with $$$b_i = i - a_i$$$ for future usage in C2.
Now turn to C2. Let's call $$$pref_i$$$ is the prefix sum of $$$dp_i$$$, and $$$suf_i$$$ is the sum of $$$\sum_{i = j}^{n}{dp[i]}$$$ supposed we start calculating $$$dp$$$ from $$$j$$$ (this is actually similar to the $$$track$$$ array in editorial, but with a different definition). Calculating $$$suf$$$ can easily be done by monotonic stack with the help of array $$$b$$$. Now, for each query, applying $$$a_p = x$$$ equivalents to changing $$$dp_i = max(dp_{i - 1}, p - x) = d$$$. Then $$$d$$$ will propagate among our $$$dp$$$, and we want to find the first position $$$q$$$ such that $$$d$$$ stops propagating at $$$q - 1$$$. For example, if $$$dp = [0,0,2, 3, 3, 3, 4, 6, 7]$$$ and we want to change $$$dp_5 = d = 5$$$, then $$$q = 8$$$ and our new $$$dp$$$ will be $$$[0,0,2,3,5,5,5,...,...]$$$. Here we can't assure that the last two elements in $$$dp$$$ are $$$6$$$ and $$$7$$$ after the change, but we can calculate the sum of those $$$'...'$$$, and it actually is $$$suf_q$$$. So, the sum of $$$dp$$$ after the change will be: $$$\sum{dp} = pref_{p - 1} + d * (q - p) + suf_{q}$$$, and answer for each query is: $$$n \cdot (n + 1) / 2 - \sum{dp}$$$.
To find the position $$$q$$$, I use binary search and max range query using sparse table. Hence the time complexity will be $$$O(nlogn)$$$. Submission to C2
Is it possible to solve D without rotations in polynomial time?
No
The testcase I am failing is giving the correct answer on my system, how? https://mirror.codeforces.com/contest/1736/submission/351551251