


Всем доброго времени суток,
25 апреля в 11:00 MSK состоится очередной раунд Codeforces #242 для участников из 2 дивизиона. Традиционно, участники из первого дивизиона могут написать соревнование вне конкурса.
Подготовкой задач занимался коллектив программистов Национального исследовательского Томского политехнического университета: Павел Хаустов (pkhaustov), Олеся Голуб (Taube), Николай Кузиванов (Carups), Дмитрий Саввинов (Dsavvinov), Алексей Ветров (noxwell).

Отдельное спасибо Владимиру Чалышеву (cmd) и Алексею Дергунову (dalex) за огромную помощь в подготовке раунда.
Кроме того, выражаем благодарность коллективу Codeforces и, в частности, Геральду Агапову (Gerald) за помощь в подготовке и Марии Беловой (Delinur) за перевод условий задач на английский язык.
Распределение баллов по задачам: 500-1000-1500-2500-3000
Желаем всем участникам удачи!







Почему так рано раунд?
Чтобы в соседних вузах занятия пропускались. А мне пофиг, я прям там напишу.
Жлобы даже ручку не дали, С не решил из за этого.
Возможно, это не самое подходящее время для раунда в будний день.
Это спорный вопрос. Не все живут в средней полосе России... Думаю, многие будут рады такому времени проведения. И тем более, в Томске в это время два часа дня будет. А, к примеру, во Владивостоке — 18:00
Why are there so many contests at 3 AM US time. :(
In china,we usually play it at 23:00!Sometime,we can't help falling asleep at that time.
Искреннее спасибо от жителей азиатской части России (и некоторых стран Азии) за проведение дневного раунда (абсолютное большинство раундов проходит поздней ночью).
I think most of the contestants aren't comfortable with the time of the contest start , it's been like this with coder-strike too
Please reconsider this in the next contests .
And many thanks to the authors
I am sorry to hear that you feel uncomfortable with the time.
However, I like the time very much :) It is 15:00 in Hong Kong (UTC+8), but I will be at school as it is Friday... The usual time of contest will be at 23:00 in Hong Kong and I can't help falling asleep at that time.
I hope that the time could be modified so as to cater most people's need.
I'm glad to hear that =) , I hope so too
Same in Vietnam :) (UTC+7)
Same in Beijing.
In Romania the contest starts at 10AM, but I have school then. Hope that the old hour(6PM in Romania) will be used more in the future :D
Div1 users won't be rated? Only div2 users will be rated with a separated ranking?
as usual, div1 wont be rated
Am I the only guy who read pkhaustov as Khaustov Patel? :P
PS: Khaustov Patel is a typical Indian name.
yes.
Patel is common Indian name and not Khaustov. https://www.google.com/search?q=Khaustov+Patel
And his name does not contain Patel! I don't see many people making this mistake :)
This time is ok, if it's not friday. Friday is
Jummah day(a special day for the muslims). And in Bangladesh, the time when contest will be started, is the jumma time. :(So going to miss this contest... :'(
*** If anyone wants to know about Jummah, can check it here
I'm sorry to to hear that many people feel uncomfortable with the time.
However, it's obvious that the time can't make all contestants happy and some people participate the contest at midnight.
The usual time will be at 23:30 in Beijing.When the contest ends,it will be at 1:30am.And I think it's more uncomfortable for Japanese and other east Asian countries' contestants. But there are still many east Asian countries' contestants to participate the contest. I think the reason is that we love coding and enjoy the contests. But I have to say the usual time of the contest is better for most contestants. Hope we can understand author and understand each other.
I am happy with this time. It will be 3 AM EST here in FL, US but it is a good time to write code relaxed, lol. The usual time is complicated (11:30 AM EST) for me because either I am working and I can't focus very well or I am at home where my daughter doesn't stop playing with me while I am solving the problems. As always, enjoy the contest, GL & HF!!!
Same point of view here. I prefer midnight contests to daytime contests, too. Fortunately, regular Codeforces time favors me well (11.30pm). Typical coders don't go to bed early, right? :P
Yes. At the end, coders don't go to sleep early. I would like to participate in more contests after midnight.
I prefer 3 AM to 11:30 AM because I'm more likely to be awake at the former time ;)
Our mid-term exam is about to finish today morning, so just be able to take part in... Sorry to hear that it' s an uncomfortable time for others. (Start at China Standard Time 15:00)
Unfortunately cannot participate in the contest cause its jummah time .
30 mins to start the contest .... It will be a good contest as always . wish you luck all :)
Скажите, пожалуйста, какая будет разбалловка?
Взломов 0, как я понимаю. Могли бы хоть в B сделать s<=10^6.
How did you solve Div 2 C?
I received time limit on pretest 12.
What did you try? Bruteforce will fail obviously.
q[i]=p[i]^(i%1)^(i%2)^...^(i%n) Q = q[1]^q[2]^...^q[n] = (p[1]^...^p[n]) ^ (^ for i=1..n for k=1..n (i%k)) = (p[1]^...^p[n]) ^ (^ for k=1..n for i=1..n (i%k)). Let P=p[1]^...^p[n]. So, Q = P ^ (^ for k=1..n for i=1..n (i%k)). Now we have to calculate these xors for all k: (^ for i=1..n (i%k)). ^ for i=1..n (i%k) = 0^1^2^...^(k-1) ^ 0^1^2^...^(k-1) ^ ... ^ 0^1^2^...^(k-1) [(n/k) times] ^ 0^1^2...^(n%k) = ((n/k)%2)*(0^1^2^...^(k-1)) ^ (0^1^2...^(n%k)). We can pre-calculate all xor sums like (0^1^2^...^(k-1)). The rest is obvious.
Also there is a formula for prefix xors
0 ^ 1 ^ .... ^ k:can you explain this formula?
This is a nice formula for long values of k . To prove it you take
F(3) = 0 ^ 1 ^ 2 ^ 3 = 0
because in binary
0000 ^ 0001 ^ 0010 ^ 0011 = 0000
and operating BIT for BIT
F( 7 ) = F( 3 ) ^ 0100 ^ 0101 ^0110 ^ 0111 = 0000
F( 7 ) = F( 3 ) ^ (01)00 ^ (01)01 ^(01)10 ^ (01)11 = 0000
We can note that () repeats four times , and four is even then (x)^(x)^(x)^(x) = 0 is ever zero
But in this problem is not necesarry because we can precalculate al values <= 10^6
A problem that you really need this formula.
Link to problem
PSDATA: you need know nim numbers before solve Industrial Nim.
Awesome, thanks! I know this problem just needed a simple precomputation, but it's still nice to understand this formula.
I think that most coders have checked this post
But without this, you can also do a precomputation :D
could you please format your comment to make it more readable. thanks!
We know that xor is asociative then we can reagrup de expression as p1 xor p2 .... xor p3 * E where E is a new expression and again reagruping :
E = (1 mod 1 xor 2 mod2 ... n mod1 ) xor (1 mod 2 xor 2 mod 2 ... n mod2 ) ....
Then we can get F = 1 mod i xor 2 mod i xor .... n mod i efficiently
Exactly, but what after that? I understood that part, but I could not form a relation afterwards.
We can get
F = 1 mod i xor 2 mod i xor .... n mod i
if we take every package of size i then we have
F = [ 1 mod i xor 2 mod i xor .... i mod i ]
xor [ (i + 1) mod i xor (i+2) mod i .. (2*i) mod i ] ...
then
F = [ 1 mod i xor 2 mod i xor .... i mod i ] xor [ 1 mod i xor 2 mod i xor .... i mod i ]......
Finally [ ] repeats q = n/i and if q is even there [ ] = 0 else [] = [ 1 mod i xor 2 mod i xor .... i mod i ] and we can consider r = n%i too.
for solve G = [ 1 mod i xor 2 mod i xor .... i mod i ] we can see that is equal to
G = [ 1 xor 2 xor .... i ]
And everthing depends only of G we can precalcalculate with a array.
My Solution
Sorry for my bad english.
I have formed an matrix on a paper of n x n rows represent n and cols mod i
as you can see, every column is a cycle of length i, and you can cancel (n/i)/2 cycles, because x ^ x = 0, obviously you will not always have cycles that pairs, so you need the xor of the parts that can't be paired, lets call it rest[i] finally with a for i do ans ^= p[i] ^ rest[i]
my submission 6467752
Почему-то был уверен, что в задаче D 300*150*300*150 спокойно залезет за 4.5 секунды. Обломился ^.^
у меня четыре фора претесты прошли за 4100, но только там не больше 2*10^9, я рядом в цикле посчитал.
UPD это то же самое похоже
UPD2 вообще зашло, мда (MS C++)
PS это что-то с чем-то, когда не обновляешь страницу с решением, чтобы система не выдала TL.
UPD3 на GNU C++ валится, без шансов вообще
у меня cin зашел в С, где ввод 10^6 чисел за секунду
Был бы удивлен, если нет. На вузовской олимпиаде авторы говорили что он у нас scanf обгонял.
UPD хотя если как ты не ускорять его, то может и упасть, конечно. Но я не экстремал.
Я был близок)) 920мс
Ну, оптимизированный cin, особенно, на C++11 обгоняет scanf. Можно видеть из этой статьи, например.
Контесты без какой-либо возможности взломать кого-то — очень уныло, ребята.
Создавать новый аккаунт участнику div1, чтобы принять официальное участие в div2 раунде, тоже уныло
С чего вы взяли? Для div1 я как-то очень уж посредственно написал, не находите?
Зарегистрирован: 17 часов назад. + "Контесты без какой-либо возможности взломать кого-то — очень уныло, ребята."
намекает
Не занимался спортивным программированием больше трёх лет, но с системой знаком и интересуюсь. Захотел вспомнить былое, и сделал аккаунт перед контестом. Что со мной не так?
Создавать новый аккаунт участнику div2, чтобы принять официальное участие в div2 раунде, тоже уныло
Made my day :D
A contest with no successful hacking attempt!
may be there was hack in E. :p
http://mirror.codeforces.com/contest/424/submission/6467778
Кажется, я написал правильное решение D, но из-за небольшой ошибки, оно искало не минимальный по разности с заданным временем маршрут, а просто с минимальным временем прохождения. и я не успел это исправить :(. Интересно, зайдёт ли с исправлением этой оплошности...
P.S. А там вообще проходит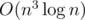 ?
?
У меня зашло.
Ну, если учесть, что у кого-то из комментариев сверху прошло O(n4)...
Я заслал O(n3) за пару секунд до конца, но, видимо, что-то не учёл :(
А вообще контест весёлый, да, респект.
Эээ...А как куб сделать, какая идея?
Ну, возможно, я, конечно, не прав, но идея такая. Фиксируем точку. Отходим от неё на максимальную ширину прямоугольника вправо (чтобы время стало больше, чем то, что нам нужно). После этого двумя указателями уменьшаем ширину и увеличиваем высоту, пока можно. Таким образом мы переберём все "интересные" прямоугольники в данной точке за линейное время.
Так ведь время по вертикали может настолько сильно меняться, что у нас в итоге время от ширины будет не монотонным и мы можем остановиться раньше времени, не?..
Кажется, при уменьшении прямоугольника, время не обязательно должно уменьшаться — так что два указателя не должны прокатывать...
Точно... Справедливо.
Эх, писал бы за лог и не выпендривался =_=
Нельзя так делать, там нет никакой монотонности, например в одном из двух соседних столбцов трасса может вся идти на подъем, а в другом на спуск. А потом снова на подъем. С двумя указателями такое не проверить. Авторское решение работает за N3logN, и ниже его уже описали.
Я бы вообще хотел поднять проблему раздельных таймлимитов для разных языков (например выделить Pascal и C++ в группу "быстрых" языков, и иногда понижать им ТЛ). Например мое решение на эту задачу на C++ работает 2 секунды. Когда я переписал его на Java, оно стало работать 3.5 секунды. Потому что TreeSet и объекты. А тупое за N4 у нас работало 5.5 секунд. Сейчас раздельные TL отсутствуют, поэтому Паша решил поставить 4.5 секунды, и в результате некоторые запихали N4.
UPD. Кстати на Java 8 залетело за 2.3 секунды.
Возникает философский вопрос, что олимпиады — вроде как решение задач, а языки — инструменты для этого. Каждый инструмент обладает своими преимуществами и недостатками, к наиболее значимым из которых относится синтаксис и время работы. А тут предлагается искусственно нивелировать недостаток некоторых языков программирования в конкретной области, не затрагивая других аспектов. С той же логикой можно в задачах с написанием длинки, делать тесты для с++, умещающиеся в лонгах, что выглядит абсурдно.
Предлагается сделать так, чтобы одинаковые правильные решения заходили, а одинаковые неправильные решения не заходили независимо от языка.
Например, в одном языке решение использует стандартную библиотеку, а в другом — приходится своё писать. Тогда придется либо считать и эти решения одинаковыми(что достаточно спорно), либо тоже что-то делать...Это не говоря уж о том, что и на одном и том же языке можно один алгоритм написать существенно по-разному (причем, новичок и не найдет существенных отличий в коде, а время будет раза в два больше).
Хотя, вообще, этот холивар может продолжаться бесконечно — просто очень сложно строго формализовать, что именно люди хотят от олимпиад, чтобы всем понравилось...
А ты учёл, что сумма может переполнить 32-битный тип?.. И вообще, как O(n3) делать? :)
Я в своём решении, как и в классической задаче на подматрицу макс. суммы фиксировал две строки, а потом перебирал столбец и выбирал для него из set'a какой-то из предыдущих, для которого ответ ближе всего к требуемому...
P.S. Мой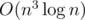 зашёл ^.^
зашёл ^.^
Блин, хорошо что я не знал о таком решении. А сейчас хорошо, что знаю.
Эм, с чего бы ей за 32 бита вылезать?
Понятия не имею, но у меня это почему-то происходит на 14 тесте Оо
Ой, натупил...
Am I the only person who are confused with problem E's sample case?
Can anyone tell me why my solution gave WA ? I did precomputation of XORs and my complexity is also good. 6468572
can you at least explain a bit your idea? and ull was not necessary
You had the right idea of precalculating xors, but what you're doing on each iteration is not right. Try this simple test:
The answer should be 2.
Yeah . Silly mistake on my part , I took mod as simply the difference and it failed on indices like 4%2 and 4%4. .
In div2 problem A, I thought that that in one minutes he made as many sit as he wish as written in question " Pasha can make some hamster ether sit down or stand up". Here instead of "some" there should be "one".
Было бы круто, если раунды с нестандартным временем начала (19.30 MSK) анонсировались намного раньше, чем за 20 до начала :( Получается сутки не заходил на КФ — пропустил раунд.
what was the idea of D?
Bruteforce and TernarySearch , my friend.
Integer ternary search Oo
You crazy person...
P.S. I thought, we can't avoid using
setin this problem. Such a surprise.Actually the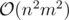 solution passes in time! >.>
solution passes in time! >.>
6467987 6468437 6468850 6467987
This solution is wrong. Ternary search doesn't work here.
6469423
Well, but his solution is AC.
And how do you think what does it mean? :)
Weak tests, round should be unrated :Ъ
Not really, I believe his solution is correct.
His ternary search function is a function of the absolute difference between both times, which is clearly a bitonic function in this problem.
Hey man i think that you are wrong , Ternary search works because my function f is crecient then g = abs( f — t ) is like a parabola then i need to calculate the minimum.
You fix left, right and top borders of the track and then find the bottom border by binary search. Let's see what bottom borders we can create.
What happens if all odd rows are decreasing (
a[i][j] > a[i][j+1]) and all even rows are increasing (a[i][j] < a[i][j+1])?If we consider the times needed to go through the parts of track built at these rows, they will be like
{d*tUp, d*tDown, d*tUp, d*tDown, ...}where d is the width of the track and tUp and tDown are numbers from the input. It's not a crescent sequence, is it? Of course we also have increasing left and right parts, but they cannot affect so much as the bottom part affects the function (e.g. if the width is very large).Oh nice counterExample , maybe in random cases my solution works well:)
I thought this during the contest, so I went for the O(N^4) solution :(
Still, in the editorial (http://mirror.codeforces.com/blog/entry/11944) the author says his solution is O(N^3 * logN).
As far as I've seen, people have used n-ary search to do this, but there are a lot of cases where that would fail, cause you can't guarantee that it's increasing or decreasing at any point.
Take dalex' example with odd decreasing/even increasing rows, you can actually have any random configuration of rows that are all increasing or decreasing and this would make any n-ary search solution fail, as far as I can understand.
So, any ideas of how to achieve the O(N^3 * log N) solution with any other method? (Or is there something that I'm missing and a n-ary search actually works?)
champero detected !! :P, Nice problem.
Any editorial?
here it is.
Could anyone help figure out what the wrong is in my two solution of Problem C? 6466959 and 6468449
In Problem C, upper limit of 'p' was 2 x 10**9. However, solutions that took 'p' as int passed.
the upper limit of
intis2147483647, which is more than2e9. so ofcourse it will pass!I am wondering if this algorithm is correct or not. http://mirror.codeforces.com/contest/424/submission/6470517 He enums all the point on the top-left , and use trinary-search twice to find the point on the bottom-right. In my view , this solution is incorrect. Just can not find a data challenge this code ? Thanks
Could anyone share your idea of problem D? I was confused with the problem for more than one hour, sticking to the O(n^4) algorithm and cannot find a way to optimize it....
Hello.
Can anyone tell me why submission 6465131 gets Compilation Error on Codeforces, as it compiled perfectly on my local machine ( Linux GCC 4.8.2, though I doubt there are any great differences between this and 4.7) ? Link: http://mirror.codeforces.com/contest/424/submission/6465131
Thanks.
Compiler thinks that
distanceis STL function to count distance between two iterators, but not yours. You haven't Compilation Error on your local machine because your local machine uses C++11 mode. If you want to use C++11 on Codeforces, you should choose "GNU C++0x 4" as language.Ok, thanks for your help.
why is
3 1 4 6not a solution to sample of D?Read the statement carefully. The side of rectangle must be at least 3.
Problem D was very misleading... During the contest, some people got Accepted with a O(n^4) algorithm, while most people thought that the required complexity was O(n^3) :P
спасибо хороший contest был