


[The first few paragraphs of this blog, above the first spoiler, are just for story purposes and are irrelevant to the problem statement]
One fateful day, a naive and young version of me from about 5 days ago had a dream. A dream to stop being so terrified of hard problems. A dream to conquer the most challenging stuff that CF ever had to offer. A dream to... ok, enough of that, that's so stupid. Basically, I've been grinding 3500s lately, mostly for fun (and my god, has it been fun).
Two days prior, I found myself solving 1919G. That went fine, but after getting it, I noticed that despite G being 3500, it wasn't even the hardest problem in the contest — that honor went to the next problem, 1919H (the subject of this blog), which had no solves in-contest. I concluded that I would have to be insane to try that, and moved on to other problems.
Well, yesterday, I decided I was indeed insane. So I opened H again and gave it a serious attempt (with said attempt carrying into today). Obviously, it took me a while — it was somewhere within a 6-8 hour solve (which is also not the longest; probably its no-solve status came from the fact that G was also very hard and this problem can have a lot of implementation/casework if you don't do it smartly [guess who I'm talking about!]).
But I did eventually solve it. Right after, I went back to the problem statement to check my reward, and... lo and behold...
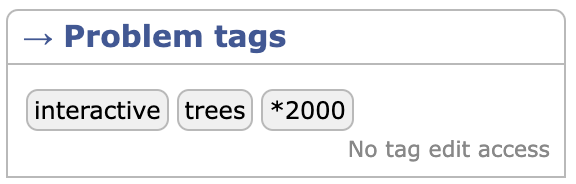
that's it, game is broken, never using this site again
So clearly this isn't what the rating is supposed to be. As an alternate example, the two contest-unsolved problems from Pinely 2 have their appropriate 3500 ratings. There are roughly four examples of this I know of:
- 1919H [2000], as previously mentioned
- 1909I [1900] — this also had no solves (except for zh0ukangyang, whose participation was later nullified, not sure if that nullification was before or after problem ratings were calculated)
- 1810H [2900] — not as bad, but come on, its only solvers were jiangly, rainboy (orange at the time), and a (at-the-time) blue who ended up 5th. I even attempted this problem a few months back because I didn't suspect that it was not, in fact, actually 2900 (it shouldn't be hard to guess how that went).
- 1603F [2700] — also solved by two LGMs and rainboy. Funny enough, there's also an unofficial submission? I don't know what's up with that, but it probably doesn't affect the rating much anyway, so whatever
- Another is mentioned here, but it's much older and thus perhaps subject to greater weirdness. I won't mention it further. Feel free to suggest more if you have other examples though.
Interestingly, for both of the first two mentioned problems, the first post-contest accepted submission was also from rainboy. Clearly there's a common thread here...
I'm not sure if upsolving is a factor in problem ratings (in particular the first upsolve or submissions shortly after the contest/system testing ended), but most other contest-unsolved problems do have the appropriate difficulty, so maybe it is. Basing the difficulty off of the rating of users who solved it definitely works in general, but when there are a single-digit number of data points, the fact that there exists a user who stays below 2300 rating and solves every contest backwards and actually gets the hardest problem semi-frequently seems to severely mess with the rating system in a few instances.
In the past, problem ratings in such extreme cases were adjusted (perhaps manually), so I think it's reasonable to ask that at least these few problems be bumped up to their appropriate difficulty (3500, clearly, based on how other 3500s are treated). In terms of making the rating more generally accurate, there should definitely be some special case handling for problems with very few solves, particularly against the fact that some users are much more skilled than their rating would indicate (this is not an issue with many solves, but for the first two mentioned problems, it seems that rainboy was the only solver that affected the problems' ratings). However, since this seems to be a somewhat rare case, maybe it can just be handled manually when it does happen.
Extra stuff (unrelated to the rest)
Footnotes
(the asterisks don't actually reference anything in the text, these are more in response to the entire blog)
* I recognize that this is about as first-world as problems get. But 3500s are also first-world problems, and I just solved one. Give it to me, dammit!
** Of course, this is more funny than anything. Obviously I'm not actually mad about this. But given that 1919H is, by many definitions, the hardest problem I've ever solved, I'd like it to at least be the proper (highest) difficulty.
*** The pings are fake (try clicking them).







a huge educational platform vs one rainy boy: 0:1
we should ban him!
I will have to be honest this so unnecessary
What is so unnecessary?
can we get more than 10 downvotes on this comment
Probably it's better to leave it as is or to rate problems by different aspects, like observation, implementation and technique. Because rating a problem that no one solved during contest but that becomes obvious after just 8hours think as 2000 is not entirely correct
Yeah, it's relatable. Like many problems which has very easy solution, but with some trick (Like Dijkstra problem which is 1900!) are easier than some 1700 which has some insane solution(for me).
CLIST ratings seem very accurate, why can't Codeforces use a similar system?
is it possible to filter problems in CLIST that we have solved? Would love to know stats on problem ratings for known problems!
Yes, if you add your username in the clist profile it will show which problems you did/failed.
We are working to make our problem ratings better. Stay tuned for updates!
Actually, on clist there are many weird ratings too. I can't say it is perfect:
There are more examples like these if you examine clist carefully.
In my opinion, there should be at least these factors influencing problem rating. Note that I don't know how problem ratings are computed, but I am sure some of these factors can be factored into the computation in a much better manner than currently done.
Priors from contest setters as an initial estimate: since problem authors try to order problems in order of perceived difficulty, a good initial estimate for difficulty (that can supposedly be corrected incrementally after the contest) can be a prior that comes from the usual rating distribution from a round that has a similar structure. For example, in a 5 problem Div2, the "seed" ratings can be just some kind of weighted mean of the last few 5-problem Div2 contests, and/or a rating distribution that could be proposed by the author based on testers' perception. This will be particularly helpful for problems with a small number of solves.
Inverse variance contribution: people who stay at a similar rating tend to have sharper boundary of what they can solve in-contest and what they cannot. Also, people who have a higher rating variance either don't do contests with an optimal strategy in mind, or they just have some topics that they are much stronger at, compared to other topics. Thus, giving more weight to people with lower rating variance (or just some norm of rating change) should be beneficial.
More contribution to in-contest solvers: this is probably already accounted for, but it is more important to look at who solved problems in-contest. Only in case there are too few in-contest solves does it make sense to rely on out of contest solvers. However we often see newbies and other low rated people just copy-paste submissions, so this is not as robust as relying on the prior implied by the authors, unless there are a large number of appropriately rated solvers.
Set rating variance of people within first few contests (or participating for the first time in a very long time) to be higher than usual — this can be done in a continuous manner too instead of just defining arbitrary discrete cutoffs.
I am also curious about how problem ratings are currently computed, so I hope to know how it works and that these suggestions are taken into account.
Also, does the contest length affect the problem difficulty?
A 2400 may solve a 3000 rated problem given enough time. Although maybe not under 2 hours along with all other problems.
(For the sake of the argument, consider for the time being that "3000 rated problem" makes sense as a construct, and the rating of the problem is universally apliable as a means to determine how hard a problem is for some individual)
While it's on the docket (though this may be asking for too much at once) — the 3500 cap was introduced four years ago, where the average performance for 2nd place was 3600-3700 (performance for 1st can be used but is somewhat ill-defined). Nowadays, it's 3800-3900 (less so very recently because competition at the top has become very tight and no one person has significantly more rating).
I think it would thus make sense that problem ratings up to 3700 are as "well-defined" now as problem ratings up to 3500 were when the cap was introduced (any 3700 problem would likely have $$$\leq 3$$$ or $$$4$$$ solves in contest, a similar metric to what 3500 used to mean). Maybe the cap could be raised a bit to make the hardest of problems slightly more distinguishable?
(I have no comment on the lower bound of 800)
I am facing the same issue, so i decide to rate the problem based on the number of contestants solved the problem during the contest, if the problem got solved ~1000->3000 for me is like a challenging problem and i can solve it..., and less than 1000 it's still hard problems that i can't solve at the moment.
Just stop taking care of the problems rate cause in same problems i found them so easy than 1200 1300 problems and when i see their rating i found ~>=1600 just because the have some prerequisite knowledge like segment-Tree, DP, graphs...etc
Of course subjective difficulty is a very different thing from objective difficulty, which is the case in the examples you gave, but OP is talking about objective ratings being extremely low, for example, in the first example he gave, it should be rated ~3400-3500 because it had only one in-contest solve but it got rated 2000 which is completely incorrect according to both the rating system, and subjective difficulty.
I've also noticed this. I have a spreadsheet with my upsolving and starting from some point I input problem difficulties in it as soon as they are available.
Your first two examples used to be $$$3500$$$! It appears that they've changed quite recently. I started maintaining my spreadsheet after your fird example was released, so I don't know if it used to be higher as well or not, but it also surprised me when I was solving it
$$$3500!\approx 2.39112819947764952509538749369364118451622972442875157035\times 10^{10886}$$$
Initially, I read this as
3500 != 2.39..Is also correct
Easy solution: delete the problem rating system.
I think it could be better if the algorithm to calculate problem ratings is made open so that people can review and improve that.
I have solved 1810H - Last Number on my own :)
1967F - Next and Prev why *3200?