


I didn't see any documentary and blog on this topic, so I guess it's Codeforce blog time .
Blog in HackMD if you prefer it
Prerequisite:
- Convex Hull Trick.
1) The OG Convex Hull Trick:
This blog is not a tutorial to Convex Hull Trick, so I would assume that you guys already know about it before reading this. However, I'll briefly recap for the sake of completeness.
Problem Statement: Given $$$n$$$ lines of the form $$$y = a_i * x + b_i$$$ and $$$q$$$ random queries $$$x_j$$$. For each query, calculate the value $$$max(a_1*x_j + b_1, a_2*x_j + b_2, ..., a_n*x_j + b_n)$$$.
- Constraint: $$$n, q \leq 3*10^5$$$, $$$a_i, b_i, x_j \leq 10^9$$$.
- Time limit: 1s
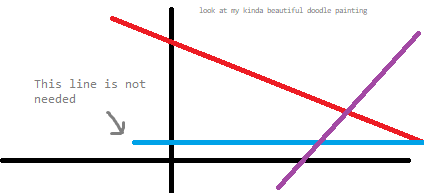
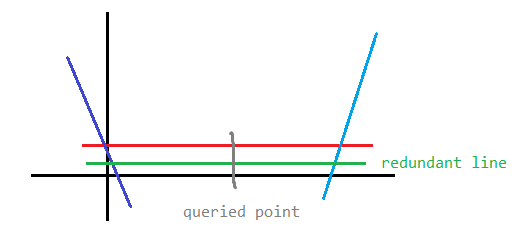
This is a well-known problem, and you can find tutorial for this basically everywhere. In short, we will sort all the lines in ascending order of their slope, and remove all of the redundant lines, as shown in my beautiful painting below (A line is redundant if it lies entirely "below" its two adjacent lines). This is solvable in $$$O(n)$$$ using stacks and some geometry.
Figure 1: How a redundant line looks.
From this, we observe that the resulting function is convex (since slopes are sorted). Each slope is optimal for one continuous segment, starting from and ending with its intersection with its two adjacent lines in the hull.
Figure 2: How the convex hull should looks, alongside its intersections.
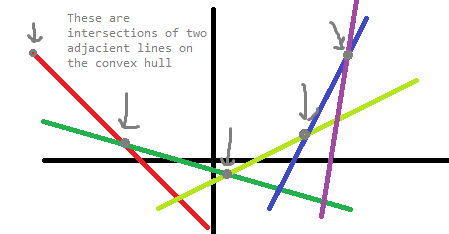
Once the convex hull is constructed, the problem is basically just binary searching over the intersections of the convex hull to find the optimal line for queried point $$$x_j$$$.
Time complexity: $$$O(n * log_2(n))$$$ for the preprocessing, and $$$O(log_2(n))$$$ for each query.
2) Extended CHT problem:
Problem Statement: Given $$$k$$$ and $$$n$$$ lines of the form $$$y = a_i * x + b_i$$$ and $$$q$$$ random queries of the form $$$x_j$$$. First, we denote $$$c_i = a_i * x_j + b_i$$$. For each query $$$x_j$$$, find the $$$k$$$ largest values of the array $$$c$$$.
- Constraint: $$$n, q \leq 3*10^5$$$, $$$k \leq 10$$$, $$$a_i, b_i, x_j \leq 10^9$$$.
- Time limit: 5s.
Since the lines in the convex hull are sorted by slope, we observe that the further a line from the queried point, the less relevant it is.
But why is that? Let's consider two adjacent lines $$$(b)$$$ and $$$(c)$$$ to the left of $$$x_j$$$ ($$$(c)$$$ is further from $$$x_j$$$). These two lines intersect at the same point, but because $$$(b)$$$ slope is greater than $$$(c)$$$, the value of $$$(b)$$$ at $$$x_j$$$ ends up being greater.
Figure 3: Illustration of the lines $$$(b)$$$ and $$$(c)$$$ to the left of $$$x_j$$$, and how $$$(b)$$$ is more relevant than $$$(c)$$$.
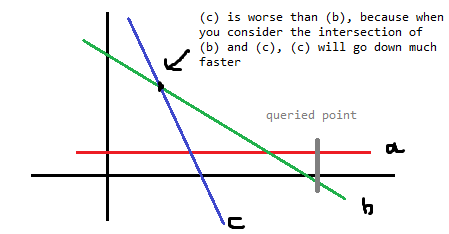
Thus, we only need to focus on the $$$k$$$ nearest lines from $$$x_j$$$, both to the left and to the right.
Figure 4: How the algorithm may work.
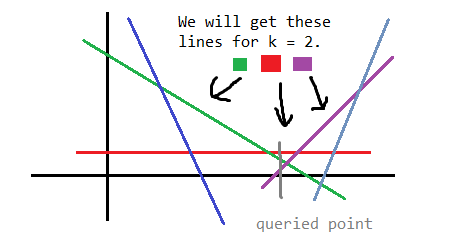
However, there is a flaw to this approach. For example, for $$$k = 2$$$, what if the "redundant line" is actually the second largest line?
Figure 5: How the second largest line might not be on the convex hull.
There is an easy fix! We will keep track of all of the "redundant lines" from our first run of constructing the CHT data structure, and we will use these lines to make a second CHT. So for the previous example, it would look like this.
Figure 6: How the 2-layer CHT would look like.
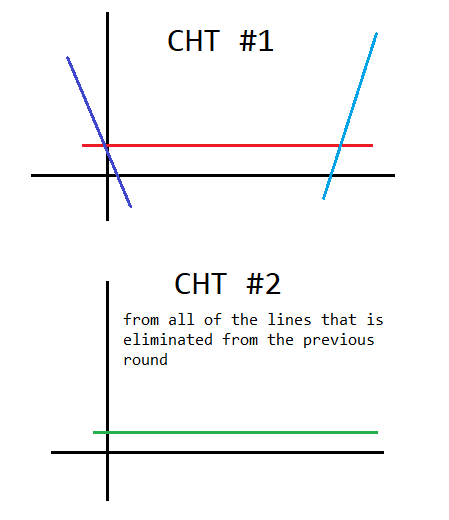
Then we will do the same thing for the second CHT i.e. brute forcing through the $$$k$$$ nearest lines from the queried point, both to the left and to the right.
Extending to the general case was pretty simple. We can just make $$$k$$$ CHT, with each one using all of the redundant lines from the previous CHT. We know that this is optimal, because on each layer, we only need to go to the left and right at most $$$k$$$ times, and we only need to dive down at most $$$k$$$ layers (Anything on the $$$k+1^{th}$$$ layer is just not needed, since all of the lines on the previous layers are better).
Time complexity: $$$O(n * k * log_2(n))$$$ for the preprocessing, and $$$O(k^2 + k*log_2(n))$$$ for each query.
The complexity in both the preprocessing and querying could be further optimized, but I'll leave it as an exercise for readers.
Are there any problem that feature this algorithm? Well uhh... I don't know, this is like mythical stuff that you will probably never encounter all your life. But now you have :))







It can be done faster with lichao tree
This can be constructed in $$$O(n*k)$$$, and queried in $$$O(k*log_2(n))$$$ if you try hard enough.
meh
Could be a relevant problem: https://loj.ac/p/3047