


I was shown this JOI problem by Jasonwei08 today. The problem statement boils down to:
Given an array $$$A$$$ of $$$2^L$$$ integers, $$$1 \leq L \leq 20$$$, process $$$1 \leq Q \leq 10^6$$$ queries. For each query, consisting of a length-$$$L$$$ pattern of either 0, 1, or ?, report the sum of all $$$A_j$$$ where the binary representation of $$$j$$$ matches the pattern.
The ? character acts as a wild card. For example, the pattern 1? matches both 10 and 11.
We will start with the following brute force approach:
Build a binary tree whose leaves correspond to all binary strings of length $$$L$$$, in lexicographic order. Each node's parent corresponds to the string obtained by deleting its last character, e.g. the parent of 11011 is 1101. We allow the tree's root node to be the empty string. It can be shown that this procedure yields a perfect binary tree.
We can visualize each query as a set of leaves in this tree. As a very simple example, let $$$L$$$ be $$$4$$$, and the query pattern be ?1?:
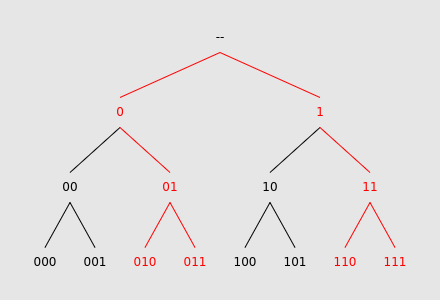
As expected, this pattern matches $$$010$$$, $$$011$$$, $$$110$$$, and $$$111$$$. Highlighted in red is the subtree whose leaves consist only of these matching strings, which we use to answer the query. By storing each array value $$$A_j$$$ within the leaf corresponding to $$$j$$$, and then performing a DFS on the subtree, we compute the answer to the query. Although this method may seem convoluted, it will allow for interesting optimizations later.
This approach yields a worst-case query complexity of $$$2^L$$$, which is unacceptable. How can we improve?
Let's look at the previous diagram again, and in particular the red subtree. Interestingly, it has a high degree of symmetry. Notice that the section rooted at node 0 has identical structure to the section rooted at node 1. If we think about how this subtree is defined, this property makes sense. Each ? in the query pattern essentially creates two sets of matching binary strings whose elements differ only at a single place value.
We can exploit this symmetry by "folding together" the tree at nodes 0 and 1, allowing two times fewer nodes to be traversed:
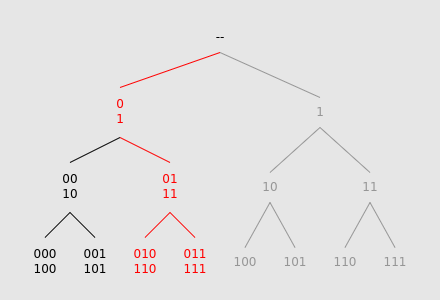
In order to support this "folding operation", we can store the tree's leaf values in an array. By cutting the array into two halves and summing their elements together, we obtain a new "leaf array" with half as many elements.
Notice that this "folding" step essentially reduces the original subtree into a line graph spanning from the root to the leaf level. This negates the need for a DFS. In fact, we can use this "leaf array" concept to implement the entire tree traversal:
As we descend down the subtree, we move to either the left child, right child, or both. In the first two cases, we can cut the leaf array in half, and select only one of them. In the third case, we "fold" as described before. Because this operation always results in a new array with exactly half the size of the previous one, our final array will contain only one element, whose value is identical to the answer of the query.
As an example, the query ?01? will be processed as follows:
Create the original leaf array
Cut the array in half, folding the two subarrays together
Cut the array in half, selecting the left one
Cut the array in half, selecting the right one
Cut the array in half and fold
By itself, this process still takes $$$2^L$$$ operations worst-case per query. However, we can improve this by leveraging cross-query similarities. In particular, if two different queries share the first couple of cut/fold operations, save the leaf array's state after such operations are applied, avoiding unnecessary recalculation.
This optimization turns out to be very useful. Because each cut/fold operation is linear with respect to leaf array size, the most costly operations run earliest, and are therefore most likely to be "memoized" by our optimization.
To implement this procedure, we collect all query patterns and build a trie. Then, we perform a depth-first search, which orders the queries optimally, avoiding all unnecessary cut/fold operations. Furthermore, if we are clever with the DFS order, we only need to store one leaf array of each size ($$$2^L, 2^{L-1}$$$, etc), which nicely bounds overall memory usage to $$$2^{L+1} - 1$$$.
Analyzing the time complexity of this algorithm is somewhat messy. Our worst-case scenario occurs when the query pattern trie has as many nodes as possible. Let us count the number of nodes at each depth level within such a worst-case trie. Each node can have at most three children, so the absolute maximum number of nodes at depth $$$i$$$ is bounded by $$$3^i$$$. Because we cannot have more nodes than the number of total queries, we restrict to $$$\min(3^i, Q)$$$. It can be shown that such a worst-case trie always exists.
A trie node at depth level $$$i$$$ operates on a leaf array of size $$$2^{L-i}$$$, so we can approximate the time complexity of the algorithm as:
To split up the $$$\min$$$, let $$$q = \left\lfloor \log_3 Q \right\rfloor$$$.
&= \sum_{i=0}^q 2^{L-i} 3^i + \sum_{q+1}^L 2^{L-i} Q \\
&= 2^L \sum_{i=0}^q 1.5^i + Q \left( 2^{L-q} - 1 \right) \\
&= 2^L \cdot 3 \cdot 1.5^q - 2^{L+1} + Q \frac{2^L}{2^q} - Q
\end{align} $$$
We can approximate $$$q$$$ as $$$\log_3 Q$$$ directly, and use change-of-base.
This is essentially on the order of $$$2^L Q^{0.369}$$$, which is very acceptable.
I have not seen this technique mentioned anywhere before. I think the original problem's intended solution was SOS DP, or at least that's how Jasonwei08 solved it. This cut/fold technique was definitely more work to implement than SOS, although probably not as complicated as it conceptually seems.
Generally, this technique can solve all sorts of pattern-matching problems, especially in situations where there are more than two types of characters and wildcards. The algorithm's time complexity scales nontrivially with respect to the number of character types, so I'm not sure how feasible it would be in extreme cases.
I do not expect this to be very useful in future contests, due to its extremely limited use case. However, I had a lot of fun discovering it, and I hope you enjoyed reading this blog. Let me know if I missed anything!







Thank you so much for sharing this technique with the community!!
Also, I do not know a lot of techniques, but I wish I do and I try to learn
Yayyyyy
nah I swear you know infinite techniques
i can confirm he does know infinite techniques, many more than me
orz idea, but how would you implement this? As in, how would you write a trie traversal that folds the tree?
Surprisingly, it wasn't very difficult. I stored $$$L+1$$$ arrays of size $$$2^L, 2^{L-1}, ...$$$, the biggest one initialized to $$$A$$$. Then, when depth-first searching the trie of queries, I cut/folded the current top-level array into the next one. So, $$$10,2,3,15,0,9,12,3$$$ would be left-cut into $$$10,2,3,15$$$, for example. Naturally at the deepest point of the dfs there would be a single value in the smallest array, and that would be the answer to the queries ending at that point in the trie.
Here's sort of what I mean:
It's a little confusing because the dfs in this situation is on the trie, not the binary sequences, which aren't represented in an explicit tree at all. The trie is traversed top-down, whereas the sequence tree is traversed bottom-up.
Also, I realize that 'folding' is a little misleading. It's more of an overlaying, as none of the children change order, as they might in a topological folding. I called it 'folding' because the way I was visualizing it was as if the leaves of the tree were a strip of paper and I were manipulating it to make different sections overlap.
Damn, that's smart as hell. So this entire trie traversal would end up being something like O(L*2^L) right?
Something like that. Theoretically if the trie traversal goes through every possible pattern, it works out to something like $$$2^L + 2^{L-1} \times 3 + 2^{L-2} \times 3^2 + \dots + 2 \times 3^{L-1} + 3^L$$$, because each node in the trie can have three children. But there is a bound on $$$Q$$$, the number of patterns, so I think we get something considerably closer to $$$L \times 2^L$$$.
Either way, it pretty comfortably passed under time limit. :P
Auto comment: topic has been updated by iframe_ (previous revision, new revision, compare).
This sounds like an abstracted version of SOS DP: https://mirror.codeforces.com/blog/entry/45223 Or maybe I am misunderstanding the difference.
I think I see what you mean — a pattern $$$P$$$ composed of
0s and?s will match all binary sequences that are a subset of the binary string $$$P'$$$ formed by replacing all the?in $$$P$$$ with1. So, SOS can be seen as sort of similar to my approach.However, in SOS we compute the subset sum of every sequence. In my case there were too many patterns to construct, and so the cut-and-fold approach intentionally only builds the patterns it needs to.
Also, cut-and-fold is theoretically able to support more complicated types of patterns. I don't believe SOS has an equivalent to patterns of
0,1, and wildcard?. An even more extreme example is sequences of decimal digits, where the characterEstands as a wildcard for any even digit, andOfor any odd digit. Maybe SOS can be adapted to support this; I'm not sure.Good connection, though! (And a helpful reminder that I should look more in-depth into SOS :p)
Yeah I think all of these things are things you can do through extension on SOS.
To handle wildcard, essentially we add a new "digit" to every position that depends on every other digit. This sort of transforms the original linear dependence in SOS dp to a tree
Normal: a -> b -> c
Now: a -> b and a -> c
Some very messy code that does this: (in base 3, 0 encodes wildcard, 1 is a '0', 2 is a '1'): ~~~~~ int div = 1; for(int i{}; i < n; ++i){ for(int m = amt-1; m >= 0; --m){ if((m/div)%3 == 0){ int lower = m — (m/div)*div; dp[m] += dp[(m/div + 1)*div + lower]; dp[m] += dp[(m/div + 2)*div + lower]; } } div *= 3; } ~~~~~
This idea that SOS dp works on trees of implications allows this to be used for the second example you also posed.
Theoretically, it could be used for dags?? but that would get very messy very quickly I think.
I think I see what you're getting at. If I'm understanding correctly, your code functions somewhat along the lines of this?
This is indeed fairly similar to the cut-and-fold approach, though it doesn't perform the folding step, and 'branches out' to every leaf instead.
When using SOS in this way, every possible DP state needs to be computed. In the task I was using cut-and-fold for, this requires storing $$$3^{20}$$$ states. Not only does this far exceed the memory limit, but the time limit as well.
Writing it as a memoized function can get around this but will add an extra log factor. This memory issue is precisely the reason why I fold together the tree instead of branching.
Processing a DAG shouldn't be that bad. I think you just need to ensure that each 'parent state' is processed before each 'child state', which can be achieved by arranging them in toposorted order, similarly to how you reordered the states
0,1,?such that the wildcard came first.I see I see, that makes sense. Thanks!
Auto comment: topic has been updated by iframe_ (previous revision, new revision, compare).
iframe orz
Jasonwei08 common orz moment
nou
iframe orz
nou
alter orz ifrm orz