


Thank you for participating! We hope you enjoyed the problems and, most importantly, had fun!
2102A - Dinner Time
If you have the first $$$p$$$ elements, what happens to the rest?
What happens if $$$n\%p\neq0$$$?
How can the fact that we can also use negative numbers be useful?
The first thing to realize is that if the first $$$p$$$ elements of the array are determined, the rest will be unique ($$$a_i = a_{i-p}$$$ to hold the sum). If $$$p$$$ divides $$$n$$$, there will be $$$\frac{n}{p}$$$ blocks, each summing to $$$q$$$, so their total sum which is $$$q\cdot \frac{n}{p}$$$ should be equal to $$$m$$$. If not, the incomplete block that is created at the end can be used to cover any difference in sum, so it's always possible!
t = int(input())
for _ in range(t):
n, m, p, q = map(int, input().split())
if n % p == 0 and (n // p) * q != m:
print("NO")
else:
print("YES")
This problem was supposed to be for cyclic arrays, and also required construction, but due to D2A difficulty it was adjusted!
Do you have a solution for the cyclic array version? Comment it below
2102B - The Picky Cat
Does the initial sign and order of elements matter?
If an element is before the median in the sorted array, can you shift it forward?
What if it is initially after the median?
Before starting, we take the absolute value of all elements since their signs do not matter. Then, if the first element of the array is equal to or smaller than the $$$\left\lfloor \frac{n}{2}\right\rfloor + 1$$$ smallest element of the array, the answer is possible. Else, it is impossible. The proof is as follows:
If the first element is equal to or smaller than the $$$\left\lceil\frac{n}{2}\right\rceil$$$ smallest element of the array, we can negate the big values until the first element becomes the $$$\left\lceil\frac{n}{2}\right\rceil$$$ smallest element of the array, hence becoming the median.
If the first element is equal to the $$$\left\lfloor \frac{n}{2}\right\rfloor + 1$$$ smallest element of the array, we can negate the entire array, which results in the first element becoming the $$$\left\lceil\frac{n}{2}\right\rceil$$$ smallest element of the array.
Otherwise, if the first element of the array is larger than the $$$\left\lfloor \frac{n}{2}\right\rfloor + 1$$$ smallest element of the array, negating values smaller than it has no effect, while negating values larger than it just makes the first element further away from the median position. You can verify that negating the first element itself does not help either by using similar cases.
t = int(input())
for _ in range(t):
n = int(input())
a = list(map(int, input().split()))
pairs = [(abs(a[i]), i) for i in range(n)]
pairs.sort()
ans = [0] * n
for i in range(n // 2 + 1):
_, index = pairs[i]
ans[index] = 1
if ans[0]:
print("YES")
else:
print("NO")
Would it be easier to calculate the answer for all indices and just output for the first index?
What's up with the name of the problem?
2101A - Mex in the Grid
What is the MEX, if $$$0$$$ is not there?
When is the MEX equal to $$$k$$$?
If we want a subgrid to be included in as many other subgrids as possible, what shape should it have? What about its place?
The first fact to notice is that if the subgrid does not contain $$$0$$$, then the MEX is $$$0$$$ and we can ignore such subgrids. If the MEX is going to be $$$k$$$, it means all the values from $$$0$$$ to $$$k-1$$$ are included in the subgrid. For each $$$0\le k\le n^2$$$, we count how many subgrids have a MEX of at least $$$k$$$, aiming to maximize this.
To find the total sum of all MEX values, for each $$$k$$$ we count the number of subgrids that contain all the values from $$$0$$$ to $$$k-1$$$. Summing these counts gives us the final result.
We claim that if our subgrid is nearly square (either a perfect square or a difference of $$$1$$$ in lengths), and is placed in the middle of the grid, then the answer is maximized.
Proof: The multiplication of two numbers with the same sum is maximized when they are as close to each other as possible. Therefore, for each subgrid, if we consider the empty rows above and below it and separately consider the columns on its right and left, if one is fixed, the place is optimized to be in the middle. Now, similarly, we can say that it is optimal if the length and height of the subgrid are close to each other as well, as increasing one will cause the other one to decrease. With these two observations combined, a subgrid having the above properties is optimal when it's a nearly square subgrid in the middle of the grid.
Any ordering with this property works; an easy example is a spiral shape that starts from the center of the grid and turns around itself.
def magical_spiral(n):
arr = [[-1] * n for _ in range(n)]
if n % 2 == 0:
x, y = n // 2 - 1, n // 2 - 1
else:
x, y = n // 2, n // 2
arr[x][y] = 0
value = step = 1
dir = [(0, 1), (1, 0), (0, -1), (-1, 0)]
while value < n * n:
for d in range(4):
steps = step
step += d % 2; dx, dy = dir[d]
for _ in range(steps):
x += dx; y += dy
if 0 <= x < n and 0 <= y < n and arr[x][y] == -1:
arr[x][y] = value
value += 1
if value >= n * n:
break
if value >= n * n:
break
for row in arr:
print(" ".join(str(num) for num in row))
print()
t = int(input())
for _ in range(t):
n = int(input())
magical_spiral(n)
We had the idea of dividing this problem into two subtasks, in which the second subtask requires you to count the sum of MEX of all subgrids!
Do you have a solution for this? Comment it below
2101B - Quartet Swapping
Is it possible for an element to change its index parity after some operations?
What else is not effected by the operation?
How to combine the above two properties under the time limit?
The first observation is that the parity of the position of the elements doesn't change with the operations. Thus, if an element is at an odd or even index in the initial permutation, it will retain the same parity in the final permutation. As long as we have four elements left, we can freely adjust them within their index parity zone, but what about the last three ones? We can see that the parity of the number of inversions is fixed, so by counting the inversions of the initial permutation, the order of the last four elements will be uniquely determined.
#include <bits/stdc++.h>
#define pb push_back
#define int long long
#define F first
#define S second
#define sz(a) (int)a.size()
#define pii pair<int,int>
#define rep(i , a , b) for(int i = (a) ; i <= (b) ; i++)
#define per(i , a , b) for(int i = (a) ; i >= (b) ; i--)
#define all(a) a.begin(),a.end()
using namespace std ;
const int maxn = 1e6 + 10 ;
int a[maxn] , n , fen[maxn] ;
void upd(int x){
while(x <= n){
fen[x]++;
x += x&-x;
}
}
int que(int x){
int ans =0 ;
while(x){
ans += fen[x] ;
x -= x&-x;
}
return ans ;
}
int f(vector<int> x){
rep(i , 0, n)fen[i] =0;
int ans =0 ;
per(i , sz(x)-1 , 0){
ans += que(x[i]);
upd(x[i]) ;
}
return ans ;
}
signed main(){
ios::sync_with_stdio(0) ; cin.tie(0);
int T ;
cin >> T ;
while(T--){
vector <int> a1 , a2 ;
cin >> n ;
rep(i ,1 ,n){
int x; cin >> x;
if (i%2==1) {
a1.pb(x);
} else {
a2.pb(x);
}
}
bool v = (f(a1)%2 != f(a2)%2);
sort(all(a1)); sort(all(a2));
int x1 = 0, x2 =0;
rep (i ,1 , n) {
if (i%2==1) {
a[i] = a1[x1] ; x1++;
} else {
a[i] = a2[x2] ; x2++;
}
}
if (v) {
swap(a[n] , a[n-2]) ;
}
rep(i ,1 ,n) cout << a[i] << " ";
cout << "\n";
}
}
This problem was one of the first problems that we had, and the intended constraits were $$$n\le 3000$$$ as a D1A, but later was moved to D1B with $$$n\le 2\cdot 10^5$$$!
Do you know how to count the parity of inversions without counting the number of inversions?
2101C - 23 Kingdom
Does it matter if there are $$$2$$$ occurance of a number or $$$200$$$?
What greedy approaches can you think of?
Are they fast enough?
The first observation is that we only care about the first and last occurrences of each number in the final array, as anything in between doesn't change the maximum distance. Instead of counting the distances directly, the main idea of this problem is to break them down into pieces. For example, the distance of a pair $$$(i, j)$$$ such that $$$1\le i \lt j\le n$$$ and $$$a_i = a_j$$$ and also these indices are the farthest possible, instead of adding up $$$j-i$$$, we count one for each index in between $$$i$$$ and $$$j$$$. In Another word, for each index $$$i$$$, we count how many begins are in or before $$$i$$$, and how many ends are after $$$i$$$, adding up these values for each index gives us the sum of distances.
For each prefix and suffix of our array, we count the maximum number of different begins that we can get greedily. It can be proven that if we try to match each $$$a_i$$$ with the biggest unmatched number left, we'll end up getting the maximum number of different matches possible. Doing so can be calculated in many different ways, one using sets is shown in the implementation below.
After that, for each $$$1\le i \lt n$$$, we have a bound for the number of pairs that these indices can be in between of, as we calculated the maximum distinct matches possible for both sides (one prefix and one suffix). It can be proven that there exists an array $$$b$$$ meeting the problem conditions such that the bound for each index is held, and therefore summing up all values gives us the final answer.
#include <bits/stdc++.h>
#define int long long
// #pragma GCC target("avx2,bmi,bmi2,lzcnt,popcnt")
// #pragma GCC optimize("O3")
// #pragma GCC optimize("unroll-loops")
#define F first
#define S second
#define mp make_pair
#define pb push_back
#define all(x) x.begin(), x.end()
#define kill(x) cout << x << "\n", exit(0);
#define pii pair<int, int>
#define pll pair<long long, long long>
#define endl "\n"
using namespace std;
typedef long long ll;
// typedef __int128_t lll;
typedef long double ld;
const int MAXN = (int)1e6 + 7;
const int MOD = (int)1e9 + 7;
const ll INF = (ll)1e18 + 7;
int n, m, k, tmp, t, tmp2, tmp3, tmp4, u, v, w, p, q, ans, flag;
int arr[MAXN], f[MAXN][2];
set<int> st;
void solve() {
cin >> n;
for (int i=1; i<=n; i++) cin >> arr[i];
for (int j=0; j<2; j++) {
st.clear();
for (int i=1; i<=n; i++) st.insert(i);
for (int i=(j? n : 1); (j?i>1 : i<n); (j? i-- : i++)) {
auto it = st.upper_bound(arr[i]);
if (it != st.begin()) it--, st.erase(*it);
f[i][j] = n-st.size();
}
}
ans = 0;
for (int i=1; i<n; i++) ans += min(f[i][0], f[i+1][1]);
cout << ans << endl;
}
int32_t main() {
#ifdef LOCAL
freopen("inp.in", "r", stdin);
freopen("res.out", "w", stdout);
#else
ios::sync_with_stdio(0); cin.tie(0); cout.tie(0);
#endif
cin >> t;
while (t--) solve();
return 0;
}
We thought every greedy approach for this problem is wrong, and the intended solution used to be a $$$O(n^3)$$$ DP, but later realized we were wrong!
Can you think of a rational DP idea that despite the time limit can solve this question?
2101D - Mani and Segments
What are some characteristics of a cute subarray?
Is cuteness a monotone property?
How to find the maximal cute subarray for a fixed index $$$i$$$?
The first observation is that a subarray is cute, iff there is an index $$$i$$$, such that it is the one and only share of the LIS and LDS, and all other elements belong to either LIS or LDS.
Proof: We know that there cannot be two elements belonging to both LIS and LDS, and if there is none, the property won't be held. Therefore, we conclude that there is exactly one element shared between the LIS and LDS.
Diving deeper into the shared element, we can see that the smaller elements before it must all be ascending, and the bigger elements after it must also all be ascending (as this will make our LIS). Similarly, all the bigger elements before it and all the smaller elements after it should be descending. This gives us a good pattern, and we can easily see that any subarray included within a cute subarray is cute itself (call this monotonic property).
For counting the total number of cute subarrays, we calculate the values of $$$R_i$$$ and $$$L_i$$$ for each index. Let $$$L_i$$$ be the biggest index before $$$i$$$, such that the condition above is met. Similarly define $$$R_i$$$ as the $$$smallest$$$ index after $$$i$$$. If we can somehow calculate this values for all indices, then we'll end up with $$$n$$$ segments (for each $$$1\le i\le n$$$), and a subarray is cute iff it's included in at least one segment. This is a very classic problem, so the solution won't be discussed here.
The only detail left is how to calculate the values of $$$L_i$$$ and $$$R_i$$$? We'll discuss the process of calculating the $$$R_i$$$ here, but the $$$L_i$$$ follows a very similar pattern. We claim that $$$R_i = min(R_{i+1}, f(i))$$$. In here $$$f(i)$$$ is defined as follow:
- if $$$a_i \gt a_{i+1}$$$: then $$$f(i)$$$ is minimum index $$$j$$$, such that $$$a_{i+1}\le a_j\le a_i$$$.
- if $$$a_i \lt a_{i+1}$$$: in this case $$$f(i)$$$ is minimum $$$j$$$ such that $$$a_i\le a_j\le a_{i+1}$$$.
Proof: The fact that $$$R_i\le R_{i+1}$$$ can easily be concluded from the fact thay cuteness is a monotonic property. Also going back to the conditions described above, we can see that $$$f(i)$$$ is basically the first index that will ruin our condition, so based on the definition of $$$R_i$$$, we can say that $$$R_i = min(R_{i+1}, f(i))$$$.
The calculation of $$$L_i$$$ and $$$R_i$$$ can both be implemented using a Segment Tree or a Monotonic Stack; both implementations are included below. After we have those values, we count the number of subarrays included in at least one segment, and that would be our final answer.
#include <bits/stdc++.h>
#define int long long
// #pragma GCC target("avx2,bmi,bmi2,lzcnt,popcnt")
// #pragma GCC optimize("O3")
// #pragma GCC optimize("unroll-loops")
#define F first
#define S second
#define mp make_pair
#define pb push_back
#define all(x) x.begin(), x.end()
#define kill(x) cout << x << "\n", exit(0);
#define pii pair<int, int>
#define pll pair<long long, long long>
#define endl "\n"
using namespace std;
typedef long long ll;
typedef long double ld;
const int MAXN = (int)1e6 + 7;
const int MOD = 998244353;
const int INF = (int)1e9 + 7;
int n, m, k, tmp, t, tmp2, tmp3, tmp4, u, v, w, q, ans, flag;
int arr[MAXN], L[MAXN], R[MAXN];
/* Segment Tree */
#define mid ((l+r)>>1)
#define lid (mid<<1)
#define rid (lid|1)
int seg[MAXN<<2];
void build(int l=0, int r=n, int id=1) {
if (l+1 == r) {
if (!flag) seg[id] = INF;
else seg[id] = -INF;
return;
}
build(l, mid, lid);
build(mid, r, rid);
if (!flag) seg[id] = min(seg[lid], seg[rid]);
else seg[id] = max(seg[lid], seg[rid]);
}
void upd(int ind, int k, int l=0, int r=n, int id=1) {
if (l+1 == r) {
seg[id] = k;
return;
}
if (ind < mid) upd(ind, k, l, mid, lid);
else upd(ind, k, mid, r, rid);
if (!flag) seg[id] = min(seg[lid], seg[rid]);
else seg[id] = max(seg[lid], seg[rid]);
}
int get(int s, int t, int l=0, int r=n, int id=1) {
if (l >= r || s >= t) {
if (!flag) return INF;
else return -INF;
}
if (s <= l && t >= r) return seg[id];
if (t <= mid) return get(s, t, l, mid, lid);
if (s >= mid) return get(s, t, mid, r, rid);
if (!flag) return min(get(s, t, l, mid, lid), get(s, t, mid, r, rid));
else return max(get(s, t, l, mid, lid), get(s, t, mid, r, rid));
}
/* Segment Tree */
void solve() {
cin >> n;
for (int i=1; i<=n; i++) {
cin >> arr[i];
}
fill(L, L+n+7, 1);
fill(R, R+n+7, n);
flag = 0;
build();
for (int i=n-2; i>=1; i--) {
upd(arr[i+2]-1, i+2);
R[i] = min(R[i], get(min(arr[i], arr[i+1]), max(arr[i], arr[i+1]))-1);
}
flag = 1;
build();
for (int i=3; i<=n; i++) {
upd(arr[i-2]-1, i-2);
L[i] = max(L[i], get(min(arr[i], arr[i-1]), max(arr[i], arr[i-1]))+1);
}
for (int i=n-1; i>=1; i--) R[i] = min(R[i], R[i+1]);
for (int i=2; i<=n; i++) L[i] = max(L[i], L[i-1]);
ans = R[1];
for (int i=2; i<=n; i++) {
ans += R[i-1]-i+1;
ans += (i-L[i]+1)*(R[i]-R[i-1]);
}
cout << ans << endl;
}
int32_t main() {
#ifdef LOCAL
freopen("inp.in", "r", stdin);
freopen("res.out", "w", stdout);
#else
ios::sync_with_stdio(0); cin.tie(0); cout.tie(0);
#endif
cin >> t;
while (t--) solve();
return 0;
}
#include <bits/stdc++.h>
#define pb push_back
#define int long long
#define F first
#define S second
#define sz(a) (int)a.size()
#define pii pair<int,int>
#define rep(i , a , b) for(int i = (a) ; i <= (b) ; i++)
#define per(i , a , b) for(int i = (a) ; i >= (b) ; i--)
#define all(a) a.begin(),a.end()
using namespace std ;
const int maxn = 5e5 + 10 , mod = 1e9 + 7;
int a[maxn] , ri[maxn] , le[maxn] , bl[maxn] , br[maxn] , sl[maxn] , sr[maxn] ;
signed main(){
ios::sync_with_stdio(0) ; cin.tie(0);
int T;
cin >> T;
while(T--) {
int n; cin >> n;
rep(i ,1, n) {
cin >> a[i];
}
vector <int> s , b;
rep(i , 1 ,n){
while(sz(s) && a[s.back()] > a[i])s.pop_back() ;
while(sz(b) && a[b.back()] < a[i])b.pop_back() ;
sl[i] = (sz(s) ? s.back() : 0);
bl[i] = (sz(b) ? b.back() : 0);
s.pb(i); b.pb(i) ;
}
s.clear();
b.clear();
per(i , n , 1){
while(sz(s) && a[s.back()] > a[i])s.pop_back() ;
while(sz(b) && a[b.back()] < a[i])b.pop_back() ;
sr[i] = (sz(s) ? s.back() : n+1);
br[i] = (sz(b) ? b.back() : n+1);
s.pb(i); b.pb(i) ;
}
ri[n] = n;
per(i , n-1 ,1){
ri[i] = ri[i+1];
if(a[i] > a[i+1] && a[br[i+1]] < a[i]){
ri[i] = min(ri[i] , br[i+1]-1);
}
if(a[i] < a[i+1] && a[sr[i+1]] > a[i]){
ri[i] = min(ri[i] , sr[i+1]-1);
}
}
le[1] = 1 ;
rep(i , 2,n){
le[i] = le[i-1] ;
if(a[i] > a[i-1] && a[bl[i-1]] < a[i]){
le[i] = max(le[i] , bl[i-1]+1);
}
if(a[i] < a[i-1] && a[sl[i-1]] > a[i]){
le[i] = max(le[i] , sl[i-1]+1);
}
}
int ans = ri[1] ;
rep(i , 2 , n){
ans = (ans + (i-1 - le[i] + 1) * (ri[i] - ri[i-1]) + ri[i]-i+1) ;
}
cout << ans << "\n" ;
}
}
We ended up having two D1D difficulty problems, but in the end chose this one as it was more cute!
We believe this was one of the cleanest problems we had. However, both the statement and solution made it look too classic, so we had a hard time making sure this idea had not been used elsewhere!
Do you have a different approach than ours? Tell us in the comments.
2101E - Kia Bakes a Cake
Can we see any node twice in our walk?
What is the upper bound on the length of the path?
How do we approach this using dynamic programming?
How to optimize the DP?
The length of each two nodes in a tree is always less than the number of nodes, and therefore the maximum weight that we can see in our constructed graph has an upper bound of $$$n-1$$$. Because the weight of any nice path is doubled every time, the maximum length of any nice path won't exceed $$$log_2(n)$$$.
The next observation is that we cannot see any node twice in a nice path (in other words, there are no cycles).
Proof: Let's assume that a cycle exists. We know that the weight of each edge is always greater than the sum of all previous edges, so even without any waste, $$$\sum_{i=0}^{k} 2^i \lt 2^{k+1}$$$. This tells us no matter how far we get, because we're taking more steps in the last edge than the sum of all previous ones, we can never end up in the first node. Therefore, every nice path is a simple path, and no cycles can be made.
Now, let's define $$$dp_{i, j}$$$ as the maximum weight of any edge to start a simple path from vertex $$$j$$$ and take $$$i$$$ steps, and $$$0$$$ if not possible. The idea here is to build the nicest path reversly, from the end to the beginning. We can update this $$$dp$$$ and build the paths backwards, and this will give us an $$$O(n^2\cdot log(n))$$$ solution as $$$i\le log_2(n)$$$.
To optimize this, we use the suffix trick on centroid decomposition and keep the maximum two suffixes every time, to update $$$dp_{i, ?}$$$ in increasing order of $$$i$$$ accordingly. This would result in a $$$O(n\cdot log(n)^3)$$$ implementation, which can be further optimized to $$$O(n\cdot log(n)^2)$$$ using the fact that we can use counting sort for sorting as we have an upper bound of $$$n$$$. Both implementations are included below.
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef long double ld;
typedef pair<int,int> pii;
typedef pair<ll,ll> pll;
#define F first
#define S second
#define endl '\n'
#define Mp make_pair
#define pb push_back
#define pf push_front
#define size(x) (ll)x.size()
#define all(x) x.begin(), x.end()
#define fuck(x) cout<<"("<<#x<<" : "<<x<<")\n"
const int N = 2e5 + 100, lg = 18;
const ll Mod = 1e9 + 7;
const ll inf = 1e18 + 10;
ll MOD(ll a, ll mod=Mod) {
a%=mod; (a<0)&&(a+=mod); return a;
}
ll poww(ll a, ll b, ll mod=Mod) {
ll res = 1;
while(b > 0) {
if(b%2 == 1) res = MOD(res * a, mod);
b /= 2;
a = MOD(a * a, mod);
}
return res;
}
int t, n, a[N], dp[lg + 1][N], gl, subt[N], mark[N];
int h[N], T[N], pd[N], tag[N];
vector<int> adj[N], centAdj[N];
void init(int v, int p=0) {
subt[v] = 1, h[v] = (p == 0 ? 0 : h[p] + 1);
for(int u : adj[v]) {
if(u == p || mark[u] == 1) continue;
init(u, v);
subt[v] += subt[u];
}
}
int findCent(int v, int p=0) {
for(int u : adj[v]) {
if(u == p || mark[u] == 1) continue;
if(subt[u] > subt[gl]/2) return findCent(u, v);
}
return v;
}
int createCentTree(int v) {
gl = v;
init(v);
int cent = findCent(v);
init(cent);
mark[cent] = 1;
for(int u : adj[cent]) {
if(mark[u] == 1) continue;
centAdj[cent].pb(createCentTree(u));
}
return cent;
}
struct node {
pii mx1, mx2;
node() {
mx1 = {-1e9, -1}; mx2 = {-1e9, -2};
}
} suff[N];
node util(node y, pii x) {
if(y.mx1 < y.mx2) swap(y.mx1, y.mx2);
if(y.mx1 < x) swap(y.mx1, x);
if(y.mx2 < x) swap(y.mx2, x);
if(y.mx1.S == y.mx2.S) swap(y.mx2, x);
return y;
}
vector<int> vec;
void dfs1(int v, int p=0) {
// update v by gl
if(2*h[v] <= T[gl]) pd[v] = max(pd[v], h[v]);
// update gl by v
if(2*h[v] <= T[v]) pd[gl] = max(pd[gl], h[v]);
if(p == 0) tag[v] = 0;
else if(p == gl) {
tag[v] = v;
} else tag[v] = tag[p];
if(tag[v] != 0 && T[v] - h[v] * 2 >= 0) vec.pb(v);
for(int u : adj[v]) {
if(u == p || mark[u] == 1) continue;
dfs1(u, v);
}
}
void dfs2(int v, int p=0) {
if(p != 0) {
if(suff[2*h[v]].mx1.S != tag[v]) {
pd[v] = max(pd[v], suff[2*h[v]].mx1.F + h[v]);
} else {
pd[v] = max(pd[v], suff[2*h[v]].mx2.F + h[v]);
}
}
for(int u : adj[v]) {
if(u == p || mark[u] == 1) continue;
dfs2(u, v);
}
}
void solve(int v) {
init(v, 0);
gl = v;
dfs1(v);
for(auto it : vec) {
int wh = min(T[it] - 2*h[it], 2*subt[v]);
suff[wh] = util(suff[wh], {h[it], tag[it]});
}
for(int i=2*subt[v]-1; i>=1; i--) {
suff[i] = util(suff[i], suff[i+1].mx1);
suff[i] = util(suff[i], suff[i+1].mx2);
}
dfs2(v);
vec.clear();
for(int i=0; i<=2*subt[v]+1; i++) suff[i] = node();
mark[v] = 1;
for(int u : centAdj[v]) {
solve(u);
}
}
void work() {
cin>>n;
for(int i=1; i<=n; i++) {
char ch; cin>>ch;
a[i] = (ch == '1');
}
for(int v,u,i=1; i<n; i++) {
cin>>v>>u; adj[v].pb(u); adj[u].pb(v);
}
int rt = createCentTree(1);
fill(mark, mark+n+2, 0);
fill(h, h+n+2, 0);
for(int i=1; i<=n; i++) dp[0][i] = (a[i]==1 ? 2*n : -1);
for(int i=1; i<=lg; i++) {
for(int j=1; j<=n; j++) {
if(a[j] == 1) T[j] = dp[i-1][j];
else T[j] = -1;
}
solve(rt);
for(int j=1; j<=n; j++) {
tag[j] = mark[j] = 0;
dp[i][j] = pd[j];
pd[j] = 0;
}
}
for(int i=1; i<=n; i++) {
if(a[i] == 0) {cout<<-1<<' '; continue;}
for(int j=lg; j>=0; j--) {
if(dp[j][i] >= 1) {
cout<<j+1<<' ';
break;
}
}
}
cout<<endl;
}
void reset_work() {
for(int i=0; i<=lg; i++) for(int j=1; j<=n; j++) dp[i][j] = 0;
gl = 0;
for(int i=0; i<=n+1; i++) {
adj[i].clear();
centAdj[i].clear();
h[i] = T[i] = pd[i] = tag[i] = 0;
subt[i] = mark[i] = 0;
}
return;
}
int main() {
ios_base::sync_with_stdio(false), cin.tie(0);
cin>>t;
while(t--) {
work();
reset_work();
}
return 0;
}
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
using ld = long double;
using pii = pair<int, int>;
using pll = pair<long long, long long>;
using ull = unsigned long long;
#define X first
#define Y second
#define SZ(x) int(x.size())
#define all(x) x.begin(), x.end()
#define mins(a,b) (a = min(a,b))
#define maxs(a,b) (a = max(a,b))
#define pb push_back
#define Mp make_pair
#define lc id<<1
#define rc lc|1
#define mid ((l+r)>>1)
mt19937_64 rng(chrono::steady_clock::now().time_since_epoch().count());
const ll INF = 1e9 + 23;
const ll MOD = 1e9 + 7;
const int MXN = 7e4+2;
const int LOG = 18;
int n;
string s;
vector<int> g[MXN];
int dp[LOG][MXN];
bool dead[MXN];
int sz[MXN];
int get_sz(int v, int p=0) {
sz[v] = 1;
for(int u : g[v])
if(!dead[u] && u!=p)
sz[v] += get_sz(u, v);
return sz[v];
}
int centroid(int v, int N, int p=0) {
for(int u : g[v])
if(!dead[u] && u!=p && sz[u]+sz[u]>N)
return centroid(u, N, v);
return v;
}
vector<pair<int, int>> U;
vector<pair<int, int>> G;
int h[MXN], par[MXN];
void dfs(int i, int v, int p=0) {
if(s[v-1]=='1') {
G.pb({h[v]<<1, v});
if(dp[i-1][v]>=2*h[v]) U.pb({dp[i-1][v]-2*h[v], v});
}
for(int u : g[v])
if(!dead[u] && u!=p)
par[u] = par[v],
h[u] = h[v]+1,
dfs(i, u, v);
}
void solve(int i, int v) {
dead[v=centroid(v,get_sz(v))] = 1;
U.clear();
G.clear();
h[v] = 0;
par[v] = v;
if(s[v-1]=='1') {
G.pb({h[v]<<1, v});
if(dp[i-1][v]>=2*h[v]) U.pb({dp[i-1][v]-2*h[v], v});
}
for(int u : g[v])
if(!dead[u]) {
par[u] = u;
h[u] = 1;
dfs(i, u);
}
sort(all(U), greater<>());
sort(all(G), greater<>());
int mx1=0, mx2=0, ptr=0;
for(auto [lim, u] : G) {
while(ptr<SZ(U) && U[ptr].X>=lim) {
if(mx1 && par[mx1]==par[U[ptr].Y]) {
if(h[U[ptr].Y]>h[mx1]) mx1 = U[ptr].Y;
}
else if(mx2 && par[mx2]==par[U[ptr].Y]) {
if(h[U[ptr].Y]>h[mx2]) mx2 = U[ptr].Y;
if(h[mx2]>h[mx1]) swap(mx1, mx2);
}
else {
if(!mx1 || h[U[ptr].Y]>h[mx1]) mx2=mx1, mx1=U[ptr].Y;
else if(!mx2 || h[U[ptr].Y]>h[mx2]) mx2=U[ptr].Y;
}
ptr++;
}
if(mx1) {
if(mx1 && par[mx1]!=par[u]) maxs(dp[i][u], h[mx1]+h[u]);
else if(mx2) maxs(dp[i][u], h[mx2]+h[u]);
}
}
for(int u : g[v])
if(!dead[u])
solve(i, u);
}
void Main() {
cin >> n >> s;
for(int i=1; i<=n; i++) g[i].clear();
for(int i=1,u,v; i<n; i++) {
cin >> u >> v;
g[u].pb(v);
g[v].pb(u);
}
for(int i=1; i<=n; i++)
if(s[i-1]=='1')
dp[0][i] = 2*n-2;
else
dp[0][i] = -1;
for(int i=1; i<LOG; i++) {
fill(dead+1, dead+n+1, 0);
fill(dp[i]+1, dp[i]+n+1, -1);
solve(i, 1);
}
for(int i=1; i<=n; i++)
if(s[i-1]=='1') {
for(int j=LOG-1; j>=0; j--)
if(dp[j][i]!=-1) {
cout << j+1 << ' ';
break;
}
}
else cout << "-1 ";
cout << '\n';
}
int32_t main() {
cin.tie(0); cout.tie(0); ios_base::sync_with_stdio(0);
int T = 1;
cin >> T;
while(T--) Main();
return 0;
}
We aimed to kill $$$log(n)^3$$$ implementations but then ended up making some correct $$$log(n)^2$$$ ones TLE, and gave up!
What was your favorite part about this problem? Comment it below.
2101F - Shoo Shatters the Sunshine
What are some properties of such colored trees?
Is the farthest blue and red node unique?
Should we look for an $$$O(n^2)$$$ solution or optimizes a slower one?
Note: For the purpose of this editorial, the diameter of a colored tree is defined as a simple path with maximum coolness which has a blue and red node on each side.
Let's say a node is special iff the distance of the farthest blue node from it plus the distance of the farthesrt red node is equal to the length of the diameter of the tree. We also define a special edge as an edge such that the distances of the farthes red nodes on both sides are equal, and the distances of the blue nodes on each side are also equal to each other. Something like this:
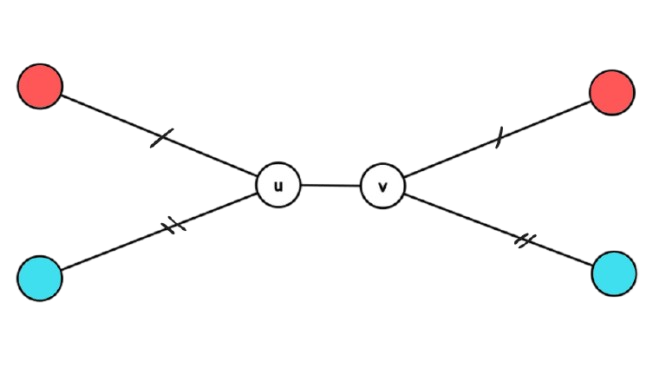
We can see that the sum of distances of the farthest blue and green plus one is the length of the diameter. We claim that if there is no special node in a colored tree, then there must be a special edge.
Proof: If there is no special node in a tree, then that means the farthest red and blue node for each vertex are on one side of it. We know that if there is at least one blue and one red colored node, then we have a valid diameter, so considering each node on that diameter, becuase it is not a special node the farthest blue and red of it must be on one side, and this leasds us towards a speical edge, the formal proof is described later when discussing $$$T'$$$.
Let's make some more observations. It's easy to see that the diameter of a tree is not necessarily unique, but an interesting fact is that every two valid diameters must intersect with each other.
Proof: if not, consider the tree is rooted from the blue/red node of one diameter, this would trivially show us a new blue and red node that has a distance longer than our current diameter and therefore a contradiction.
This gives us the idea that the intersection of all valid diameters is a non-empty simple path on the tree.
Proof: Consider two diameters and take their intersection, then add the rest one by one and take the intersection of the intersections. If there are any two pairs with intersections that do not intersect, this means there exists a pair of valid diameters which do not intersect with each other, and this is against our hypothesis.
Before continuing, you must have an idea so far that we are aiming to count the trees with special node based on their node, and others based on their special edge, but there is still a lot to discuss.
Going back to the special nodes, it's easy to see that they must must be on our diameter, and what makes this more interesting is that they must be on all diameters! So, taking the simple path that was the intersection of all valid diameters, we know that all of our special nodes lie on this path.
Getting deeper on special nodes, we can see that for a non-special node such as $$$v$$$, the farthest blue and red are both on the same subtree if we root the tree from $$$v$$$. This makes the sum of distances to farthest red plus the farthest blue result in a number always bigger than the actual length of our diameter (as there is a shared part). Call the child in which both the farthest red and blue lie on a cool child.
Let's create another graph based on our tree (call it $$$T'$$$) that has identical nodes to the tree, and directed edges. For each non-special node, give a directed edge from the identical vertex in $$$T'$$$ to its cool child. It's easy to see that special nodes would not have any incoming edges to them in this new graph, but every non-special node has at least one.
We can use this graph to formally prove almost everything. Let's start with the fact that why any tree without a special node has a special edge?
Proof: No special edge means that there are $$$n$$$ nodes in our tree that each have an outgoing edge, therefore $$$n$$$ directed edges as well. Our initial tree had only $$$n-1$$$ edge, so therefore based on the pigeonhole principle, there must be an edge in the initial tree, that two directed edges pass above it. It's trivial that those edges cannot have the same direction, and therefore this will lead us to a directed cycle of length two. Well, think about it, this is exactly what a special edge is!
So if no special node is there, now we know that there is at least one special edge there somewhere. Well, it appears that we also cannot have more than one special edge in a colored tree.
Proof: If so, we know that both of them must appear on the diameter, and considering their placement, this will contradict the fact that the distance of red and blue from both sides must be equal.
Combining both above observations, now we know that if there is no special node in the colored tree, then there is exactly one special edge there somewhere.
Now let's solve the first sub-problem, which is how to solve the problem if there is no special node. Define $$$f(v, a, b)$$$ for a node $$$v$$$ as the number of colourings which the farthest blue has a distance of $$$a$$$, and the farthest red has a distance of $$$b$$$. How to calculate $$$f$$$? Define $$$g(v, a, b)$$$ as the same thing, but this time for the distance of at most $$$a$$$ for blue and at most $$$b$$$ for red. It's easy to see that if we somehow calculate $$$g(v, a, b)$$$, then the following equation holds: \begin{equation} f(v, a, b) = g(v, a, b) — g(v, a-1, b) — g(v, a, b-1) + g(v, a-1, b-1) \end{equation} And here's how we find $$$g(v, a, b)$$$:
\begin{equation} g(v, a, b) = 3^{p\cdot q}\cdot 1^r \end{equation} Where $$$p$$$ is the number of nodes such as $$$u$$$ that have a distance less than or equal to $$$a$$$, $$$q$$$ is the number of nodes that have a distance bigger than $$$a$$$ but less than or equal to $$$b$$$, and $$$r$$$ is the number of nodes that have a distance more than $$$b$$$. Formally:
This will so far give us an $$$O(n^3)$$$ solution, dw we'll optimize it further later. Now we count the result for each edge of the tree, considering it will be a special edge in some colourings. Call both sides of the edge $$$u$$$ and $$$v$$$ just like the diagram shown above. Assuming we have $$$f$$$ calculated for all nodes, the answer is: \begin{equation} \sum_{a=0}^{n} \sum_{b=0}^{n} f(u, a, b) \cdot f(v, a, b) \cdot (a + b + 1) \end{equation} We're halfway there! Before the optimizing part, the only question left is what if there is a special node?
Let's define a super-special node a node that is special, and not only does it have the farthest blue and red on different sides, but also either a blue node with distance one less than the farthest blue, or a red node with distance one less than the farthest red.
Using the same observations that we made earlier and a deeper understanding of $$$T'$$$, you can prove that there is at least one super-special node, also at most one super-special node, and therefore always exactly one super-special node if there exists at least one special node. For such trees, we aim to calculate the answer for them based on their super-special node.
Make the tree rooted from an arbitrary node. Define $$$dp_{v, i, a, b, j}$$$ as if you're in vertext $$$v$$$, you iterated $$$i$$$ children, so far the farthest blue node has a distance of $$$a$$$, the farthest red node has a distance of $$$b$$$, and $$$j=0$$$ if these two don't belong to one subtree (if possible, preferably $$$0$$$), and $$$1$$$ otherwise. Iterate over new subtrees and use the $$$f$$$ function defined before to end up with a computable $$$O(n^4)$$$ implementation!
Now add another dimension $$$k$$$ to the above DP to keep track of if there is any blue node with distance one less than the farthest blue, or a red node with distance one less than the farthest red. Note that this really doesn't change anything.
The above DP, though correct, won't give us a good solution and is only explained for gaining deeper insight. After truly understanding what is going on and what we are looking for, we can break down the same idea and calculate it manually, which will result in a $$$O(n^2)$$$ solution in the end. The primary fact to notice is that if the number of edges between two farthest red vertices is even, then it can be proven that the middle vertex of this path is a special node, and if odd, the middle edge is a special edge. As explaining everything in detail takes forever, try to prove the things we missed yourself and ask if you encountered any issues.
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
using ld = long double;
using pii = pair<int, int>;
using pll = pair<long long, long long>;
using ull = unsigned long long;
#define X first
#define Y second
#define SZ(x) int(x.size())
#define all(x) x.begin(), x.end()
#define mins(a,b) (a = min(a,b))
#define maxs(a,b) (a = max(a,b))
#define pb push_back
#define Mp make_pair
#define lc id<<1
#define rc lc|1
#define mid ((l+r)>>1)
mt19937_64 rng(chrono::steady_clock::now().time_since_epoch().count());
const ll INF = 1e9 + 23;
const ll MOD = 998244353;
const int MXN = 3006;
const int LOG = 23;
template<typename T>
inline T md(T x) { return x — (x>=MOD ? MOD : 0); }
template<typename T>
inline void fix(T &x) { x = md(x); }
int n;
vector<int> g[MXN];
vector<int> H[MXN];
int cnt[MXN], pscnt[MXN];
ll red[MXN], redb[MXN];
ll two[MXN], thr[MXN], itwo[MXN];
ll ans;
ll ps[MXN];
void dfs(int v, int h=0, int p=-1) {
cnt[h]++;
H[h].back()++;
for(int u : g[v])
if(u!=p)
dfs(u, h+1, v);
}
void Main() {
cin >> n;
for(int i=1; i<=n; i++) g[i].clear();
ans = 0;
for(int i=0, u,v; i<n-1; i++) {
cin >> u >> v;
g[u].pb(v);
g[v].pb(u);
}
for(int v=1; v<=n; v++) {
for(int adj=-1; adj<SZ(g[v]); adj++) {
for(int i=0; i<n; i++) H[i].clear(), cnt[i]=0;
if(adj==-1) {
cnt[0]++;
for(int u : g[v]) {
for(int i=0; i<n; i++) H[i].pb(0);
dfs(u, 1, v);
}
}
else {
if(g[v][adj]<v) continue;
for(int i=0; i<n; i++) H[i].pb(0);
dfs(v, 0, g[v][adj]);
for(int i=0; i<n; i++) H[i].pb(0);
dfs(g[v][adj], 0, v);
}
pscnt[0] = cnt[0];
for(int i=1; i<n; i++) pscnt[i] = pscnt[i-1] + cnt[i];
red[0] = 1;
redb[0] = 1;
for(int i=1; i<n; i++) {
red[i] = two[cnt[i]]-1;
for(int a : H[i])
fix(red[i] += MOD-(two[a]-1));
redb[i] = md(thr[cnt[i]]-two[cnt[i]]+MOD);
for(int a : H[i])
fix(redb[i] += MOD-(thr[a]-two[a]+MOD)*two[cnt[i]-a]%MOD);
}
for(int i=0; i<n; i++) {
ps[i] = red[i]*two[i==0?0:pscnt[i-1]]%MOD*(i+(adj!=-1))%MOD;
if(i) fix(ps[i] += ps[i-1]);
}
for(int j=0; j<n; j++)
fix(ans += thr[j==0?0:pscnt[j-1]]
*(thr[cnt[j]]-two[cnt[j]]+MOD)%MOD
*itwo[pscnt[j]]%MOD
*(ps[n-1]-ps[j]+MOD)%MOD);
for(int i=0; i<n; i++) {
ps[i] = red[i]*two[i==0?0:pscnt[i-1]]%MOD;
if(i) fix(ps[i] += ps[i-1]);
}
for(int j=0; j<n; j++)
fix(ans += thr[j==0?0:pscnt[j-1]]
*(thr[cnt[j]]-two[cnt[j]]+MOD)%MOD
*itwo[pscnt[j]]%MOD
*j%MOD
*(ps[n-1]-ps[j]+MOD)%MOD);
for(int i=0; i<n; i++) {
ps[i] = redb[i]
*thr[i==0?0:pscnt[i-1]]%MOD
*itwo[pscnt[i]]%MOD
*(i+(adj!=-1))%MOD;
if(i) fix(ps[i] += ps[i-1]);
}
for(int j=1; j<n; j++)
fix(ans += two[pscnt[j-1]]%MOD
*(two[cnt[j]]-1)%MOD
*ps[j-1]%MOD);
for(int i=0; i<n; i++) {
ps[i] = redb[i]
*thr[i==0?0:pscnt[i-1]]%MOD
*itwo[pscnt[i]]%MOD;
if(i) fix(ps[i] += ps[i-1]);
}
for(int j=1; j<n; j++)
fix(ans += two[pscnt[j-1]]%MOD
*(two[cnt[j]]-1)%MOD
*j%MOD
*ps[j-1]%MOD);
for(int i=0; i<n; i++) {
fix(ans += (redb[i]-red[i]+MOD)*thr[i==0?0:pscnt[i-1]]%MOD*(i+i+(adj!=-1))%MOD);
}
}
}
cout << ans << '\n';
}
int32_t main() {
cin.tie(0); cout.tie(0); ios_base::sync_with_stdio(0);
int T = 1;
cin >> T;
two[0] = 1;
for(int i=1; i<MXN; i++) two[i] = two[i-1]*2%MOD;
thr[0] = 1;
for(int i=1; i<MXN; i++) thr[i] = thr[i-1]*3%MOD;
itwo[0] = 1;
for(int i=1; i<MXN; i++) itwo[i] = itwo[i-1]*((MOD+1)/2)%MOD;
while(T--) Main();
return 0;
}
The intended solution was the $$$O(n^3)$$$ discussed with some further optimizations, but then a new $$$O(n^2)$$$ solution showed up that changed everything! We thought of dividing the problem into two subtasks, but didn't do so, as the observation required for the $$$O(n^2)$$$ solution was quite beautiful.
Also, we would like to thank Hamed_Ghaffari for his contributions to this problem.






Add it in contest material or announcement blog. I was waiting for this
This is my submission for 2101B. Plz can someone help me where this goes wrong. I've followed a simple logic, with bruforce. I made a recursive function, which takes vector v and i as parameters, the task of the function is to sort all the elements with the same parity as i, starting from the i till the end of array, using the possible operations. I also try to make sure these operations don't mess with the part of array already we took care off. Hope you get it.
No help :(, I tried looking for reason with chatgpt and Gemini but unfortunately they couldn't figure out the right thing. I'd be grateful if someone could help.
ur solution is basically greedy,it wont always find the optimal answer,just compare the test cases where it failed with the right answer and dry run it to understand why,also the time complexity is bad
I tried doing that, I'm not able to find the test case where it fails.I don't know what greedy means, but I don't know why it might fail? At every point we are sorting and going forward, I'm not able to see the logical flaw.Ya time complexity is bad,and I understood the optimal way,I'm just not able to find what's wrong in my solution.
scroll down on ur submission,on the left side u can see
"Click to see test details"
It's not showing there, that's I'm asking here, it shows ..... after some point and the test case which fails is in that .... :(
Ah,I see sorry I didn't notice..
I just asked chatgpt(it took 2 tries) to give a case where your code would fail and here:
1
6
2 3 4 5 1 6
if im not wrong,doing ur code n times repeatedly from the start should give the right answer but yea then time complexity will get even worse..btw for the optimal solution I found 15-puzzle vid by numberphile kinda help me a bit-in a way,u can watch it
try dry running on it on paper,btw I think u should learn what greedy means,it is a pretty important and easy to learn topic,learn fractional knapsack and 0/1 knapsack(in this greedy fails and u gotta use dp,learn why greedy fails).
Aah i see, there was minor error that in each iteration I was not just sorting the elements of i parity but also trying to sort other elements also which gave wrong answer, not just changing j++ to j+=2 in the inner loop of bubble sort, gives right answer,it's not optimal solution but works.
awesome,also,learn how constraints can be used to determine time complexity,you won't waste your time on writing code which wouldn't have qualified anyways
Div2 F>>>>E? I solved F used about 40 minutes but E about 80 minutes. Maybe because Chinese are good at data structures but bad at greedy.
Div1 ABCE's observations are interesting, especially E.
Maybe time for you to learn that difficulty is relative. For you div1D is easier than div1C and for me div1F is easier than div1D.
For me div1C is the easiest problem in div1 :D
"Div1C is the easiest problem in Div1D" what does that mean?
That D is :D smile emoji
Ohhhhh, my bad
u r so cute
Well,but I'm good at greedy and not too good at data structures
I got TLE two times on The picky cat, my submission did exactly whats told in the editorial, I just checked if its less than med+1 the position. I have two questions, first that how am I getting a tle when I the time complexity is just O(n), also when I removed everything from the entire code except the solutions, this logic of index <= median +1, gave wrong answer so I solved for even and odd n separately, which then gave correct answer, why is that the case? any help would be appreciated.
I don't think, your solution has O(N) time complexity.
So you were asking for Picky Cat Problem error which was causing TLE, error part in the code is:
if (n == 1) {
}
Actually once you hit n=1 case, you didn't take further input for "temp" variable, but the checker is giving you that input, so that causes some error as you exited/returned before taking the complete input
Make sure to take complete input then only return.
In the first TLE submission you made you didn't take abs(res), I think you got that one later.
For the even/odd thing just check some examples like n=4, n=5 how many have to be smaller etc, would realise that you had to make cases. The tutorial had floor/ceil in solution, so need to take care of it.
ohhhhhhhh thank you very much, feeling so dumb now
Can you tell testcase where it is failing — Submission
This editorial for F looks overkill with calling a lot of stuff special, maybe after waking up I'll change my mind. I solved it using the following ideas:
It's well known that when looking for a max path between two sets of vertices we can reduce each set to the endpoints of some diameter of it. The first 1/3 of the editorial seems to be proving that the center is always in any diameter but that's just well known.
Fix the center of the blue diameter and solve it for that center. The center might be a vertex or an edge. Then to make that the actual center there must be at least 2 vertices that are blue in different subtrees at the lowest height that has some blue vertex (or the root in case it's a vertex center). Now the max distance between blue and red is just the distance of blue to the center + distance of red to the center (maybe +1 for the edge center case).
To compute the thing above you can choose the color for vertices in reverse bfs order going out of the center. This conveniently gives us vertices of same height as a subarray and edges of same height and same subtree also as a subarray. Then it's a matter of dp going brr, the state will be the number of stuff that has been chosen and a state that's the cartesian product of {no blue vertex yet, first blue in current subtree, first blue at same height but different subtree, two blues done} x {no red, some red} while maintaining count of such states and the sum of their distances.
The edge center vs vertex center cases differ by not a lot, it changes some choices for the center in the last few steps of the dp and how you initialize the bfs (for one vertex just do it and for an edge start with the queue having both vertices with height 0).
I don't understand editorial of F at all. your idea seems to be more understandable but I still have difficult in understanding it.
I've searched the answer for days and got none. the only charted illustration on ytb is in Japanese. I don't understand the language but I watched through and still cannot get it.
Can you please share the thoughts with video and whiteboard? thx in advance.
it looks like a pretty straightfoward answer, but I just haven't had the technique to convert the counting problem into a solution by monotonic stack etc..
Who can give the sufficiency proof for Div.2 D(Div.1 B)?
What do you mean by sufficiency proof? Could you clarify?
Why can this construction scheme be obtained through several operations?
hope my poor English can make you understand.
It is really quite straightforward. It just requires you to try it, and brute force it.
You can follow a procedure of setting up the final array from the beginning of the array. Since we are moving 2 elements at a time, none of the elements can change the parity (i.e. odd-ness/even-ness) of its index. At any partially completed stage, just look at all the elements (to the right, after the partially completed bit), that are in the correct modulo-positions, take the smallest of them, and you will just be able to simple move it into position, with zero resistance, or complications. Keep repeating the procedure. But when you reach a stage, where you have only 3 elements left, there will be nothing more you can do.
The proof that there is nothing you can do, once you reach a stage where only 3 elements are left is as follows: The (n-2) element is already the ONLY one candidate for its modulo-positions. And the maximum you might be able to do, is to swap the (n-3) and (n-1) elements. But this is also NOT possible, since the parity of the number of inversions of the original array will be changed by such a candidate swap, it is impossible because the 2-swap weird operation given in the question, preserves the parity of the number of inversions.
That's true.
I think the original question was different than what is answered, the proof would be sufficient if it can be proven every possible permutation is achievable keeping the parity of inversions same.
why would the parity of inversions be same ? I thought the exact inversions in both odd and even array are going to be same and not the parity thing here.. Can you please help me and provide me a case where after applying some operations the parity remains same but inversions in odd and even array differ ?
as the given array is a permuation,replacing abcd with cdab will either +2 ,+0,-2 the inversion count thus preserving the parity of inversion
For div1C, is $$$O(nlog^2n)$$$ not allowed? I realized after contest we can do it in $$$O(nlogn)$$$, but this $$$O(nlog^2n)$$$ submission passes in 4.5s while the time limit was set to 4s.
I got one submission to pass with some optimizations, but sometimes it takes 4.5s and sometimes it takes 3.8s, which is very strange. Maybe you could improve it with golden-section search instead of binary search, but I don't know how to do that.
You mean this? Haven't read this, so will look check it out, thanks.
I also used ternary search. Got 3.8s result with std::set and 1.1s with std::priority_queue. Tried to optimize further via golden section, but failed, probably because of rounding to integers. If you will manage implement golden section for integers, please share.
This is an $$$O\left(n\log^2n\right)$$$ solution using std::multiset. 319333985
Can someone explain why the equality of parity of number of inversions in even and odd arrays checked ? In problem D.(I don't understand why it is considered for checking)
Observe that an operation on any index can alter the number of inversions only by $$$0$$$, $$$2$$$ or $$$4$$$. You can consider all $$$24$$$ possible orders of four consecutive elements, but the relative order of the first and second elements, as well as third and fourth, does not matter, so the number of cases reduces to $$$6$$$.
The other three cases are derived from these by swapping states before and after the operation. So the parity of number of inversions is the invariant.
Nice , that is a good observation. I get it now
More generically: it is known that any swap changes the parity of the number of inversions in a permutation. Since our operation does two swaps, you know the parity must remain constant.
I am a newbie to cp , the first observation of index parity was easy to spot for me but i wasn’t able to get the second observation of inversion parity thing neither i was aware of such terms so i wanted to ask is it ok to learn these things as we solve the problems or is it bot ao hard to spot such observations without knowing about even swaps results in same parity of inversion this is an example there are numerous such things that i dont know about and they might come in next contest say
I think most people learned about inversion parity from a past problem that needed it — looks like this is that problem for you.
I agree that the parity of total inversion count of the array should remain constant but what about the parity of only odd and even index positioned elements that is there in the solution.
is this correct for C: 8 9 10 11 7 0 1 2 . 6 5 4 3 . . . . . . I mean like a number spiral but it starts from middle
Iterating spirally works. I started from n*n — 1 at (0, 0) and added elements spirally, reaching 0 at the middle.
i spent a lot of time stuck trying to make sense of counting inversions in div2D/div1B but then i realized theres a easier way to solve:
suppose we have elements wxyz .. ab:
corner case: if we have xyab we can do xyab -> abxy
so i just maintained an index lookup table and a list of odd and even parity elements and swapped them greedily for every i from 0 to n-3 (one-indexed) and got the AC :3
can you provide code
this was my submission during the contest: 319288492
the n%2==i%2 check couldve just been next==n but i was too much in a hurry to fix it :p
Can you check this code out ?
319481919
I dont understand how to improve the TL here,I also tried doing this greedily
Great editorial.
By the way, this round is much better than CodeForces Round 1000 (Div. 2)! I think your problem can deserve this historic round! Every problem is interesting, thank you!
sorry for my bad english. XD
Can someone explain the parity solution for 1B/2D? I used greedy and swaps in my solution
Imagine the swap abcd -> cdab. Exactly four pairs change their order:
All other pairs stay in their order. Now let's look at what those 4 changes can do to the number of inversions:
This means a swap can change the number of inversions by +4, +2, 0, -2 or -4. This also means that if the number of inversions is odd initially, then swaps will never change that, and if the number of inversions is even initially, then swaps will keep the number of inversions even.
OK all those inversion and parity having been making my head spin for two days; I don't know what people are referring to. Now with this comment it all makes sense.
same lol
same lol
E with maximum segment tree + binary search 319356051
I am screwed, B was damn easy idk what happened to me i was just overwhelmed tomorrow by A , i screwed damn damn damn damn
I need to trust my intuition more. Lost so much time on A.
I quite liked Div. 1 C!
I solved Div.1 C with hard way:tripartite(3 parts) search.I searched for how many pairs of numbers should I use.I gussed the answer will increase than decrease,so I used tripartite search
Link
Seems that just using greedy is OK.I should find the largest pairs of numbers that we can use
Div.1 A Bonus: I think that first for every x,I count how many subgrids have MEX that >=x,this is (left-up counts)*(right-down counts).For example,if n==5,9*9=81 subgrids have MEX that >=0
Then I use inclusion-exclusion to count how many subgrids have MEX that ==x,so I can know the sum of MEX of all subgrids
You don't need inclusion-exclusion, the sum of all $$$\mathrm{MEX}$$$ values can just be written as $$$v_1 + v_2 + \dots + v_{n^2}$$$, where $$$v_i$$$ is the number of subgrids with $$$\mathrm{MEX}$$$ more than or equal to $$$i$$$ (this is because a grid $$$\mathrm{MEX}$$$ equal to $$$k$$$ will be counted exactly $$$k$$$ times: once in each of $$$1, 2, \dots, k$$$), so you can simply take the sum of all the values you calculated.
Div2D with sorting+dfs O(nlogn)319316859
Observation:The key is element at odd/even position will remain it parity after swap,so we can just directly sorting the element at odd and even position but there is obviously a counter example [1,4,3,2],so for last four element it exist special condition need to be handle.
Assume that a[n],a[n-1],a[n-2],a[n-3] is the last four element then a[n-3]<a[n-1] always handle and there is two possibly answer which is [??,a[n-3],a[n-2],a[n-1],a[n]] or [??,a[n-3],a[n],a[n-1],a[n-2]]
a[n-3] must less than a[n-1] otherwise we can swap them and get a more lexicographically smaller permutation,so after directly sorting the element at odd and even position,there is two possibly answer which a[n-2] may occur before a[n] or a[n] occur before a[n-2].
The key is parity of permutation,
Defination of the parity of permutation:The parity of inversion in the permutation. So obviously a[n] is not equal to a[n-2] so they may have a inversion or not,this imply the parity of two possible answer will different.
Claim 1:Swap operation in this problem does not change the parity of permutation
let assume a[i],a[i+1],a[i+2],a[i+3],after swap there is three condition
1.a[i+2] and a[i+3] both greater than a[i] then inversion + 2
2.a[i+2] and a[i+3] both less than a[i] then inversion -2
3.a[i+2] and a[i+3] exactly one greater than a[i] and one less than a[i] then inversion + 0
So similarly to a[i+1] then swap operation does not change the parity of permutation
From claim 1 we know that we can count the parity of original permutaion as v1,and count the two possibly permutation as u1 and u2 and just compare v1 to u1,u2 then we can know which one is the answer,but naive solution to count the inversion cost O(n^2),so we need to optimize our algorithm
I will introduct functional graph,i believe most of you already know it if you regard p[i] as a directed edge from i to p[i] then you will get a functional graph,and one of the properties of functional graph is every disjoint connected component will exist exactly one loop(may be self loop) so the permutaion will become a set of disjoint cycle,but how it related to the problem?
Claim 2:for a permutation,for any swap between two element it will change the parity of the permutation
let i<j and we want to swap a[i] and a[j],let n=j-i-1 (number of element between a[i] and a[j]),then let x and y be the number of element greater than a[i] and smaller than a[i],from the defination we have x+y=n
There is y element less than a[i] so if we swap a[i] to j then inversion — y
and we swap a[j] to i then inversion + y
There is x element greater than a[i] so if we swap a[i] to j then inversion + x
now let x=x1+x2,x1 and x2 are the number of element greater than a[j] and less than a[j] respectively,then we swap a[j] to i then inversion +x2-x1
Last don't forget a[i] and a[j] is different and before swap if a[i]<a[j] inversion +1; else inversion-1
So after the swap,inversion will change -y+y+x+x2-x1+(1/-1)=2*x2+(1/-1),obviously then parity will change
From claim 2,I think this one is also a well known problem,given you a permutation,how many swap to make the permutation identity?Let ∂i be the number of cycle with length i then the answer for cycle length i is (i-1)*∂i,why?
For a cycle with length i,we can greedily to swap a element to the correct position this cost i-2 step and the last two element just use one swap is enough then i-2+1=i-1
So this the total swap operation to make original permutation identity is ∑(i-1)∂i
Claim 3,The parity of the permutaion is the n-number of cycle
From the previous result,let x=total swap operation to make original permutation identity,then if we use x step can make original permutation become identity,on the reverse we also can use x step to make identity permutation become original permutation,and from claim 2 every swap operation change the parity of permutation and we know a identity permutation have 0 inversion,so in otherword the parity is (0+x)%2 which is x%2
Since we know x=∑(i-1)∂i.then
x=∑(i-1)∂i
x=∑(i∂i-∂i)
x=n-c(c is the number of cycle)
So the parity of the permutation is n-c,so there is a lot of algorithm to count the number of cycle like dfs/bfs/dsu
Thank for your reading
If confused for Div 2 A shouldn't there be n — p + 1 blocks? Just like the first test case for n = 3 and p = 2
The editorial means non-overlapping blocks, because it is calculating the sum of all elements in the array.
For the Bonus for d1A, isn't it for each (i1,j1)(i2,j2), we do (i1+1)(j1+1)(n-i2)(n-j2)(k), where i1,i2,j1,j2 is smallest subgrid to contain mex k, we do that for each k > 0, is that right?
tks bro
I hate geeksforgeeks, I copied their inversion count for div2 d and forgot to change the int type to change to long long which passed the pretest....... fell from 130 to 1300+ sedlyf
Hey everyone, I need some help. In the Bonus Section of Problem 2101B — Quartet Swapping, It's given: "Do you know how to count the parity of inversions without counting the number of inversions?" Can anyone help me out with this?
I also want to know, can someone give a hint?
A different and (I think) simpler approach for 2101D: (I got this idea in the contest but failed to find the way of implementation)
We call an array acute if either the first or last element equals the maximum or the minimum of the array. An array is cute if all of its subarrays are acute.
We call an array lcute if the first element equals the maximum or the minimum of the array and rcute if the last element equals the maximum or the minimum of the array. These two can be found using 4 monotonic stacks. Then we can extend the rcute bounds to cute bounds (I don't know what name of the algorithm is but it works). Time complexity $$$O(n)$$$.
Hi,you can use Hanzi(or Chinese characters) instead of Pinyin in coding.Compilers have supported Unicode long ago.
Make sure the code is encoded in UTF-8 then you can use Hanzi.And with compilation command -finput-charset=UTF-8 -fexec-charset=UTF-8,we can input or output Unicode characters
Using Chinese characters should always be avoided in programming (even in comments), no matter whether it is in Codeforces or not. I got some fatal errors in my game in the past because of using characters that are not in ASCII.
Oh yeah,the time complexity is O(n). And I don't know whether this can be hacked.Seems it's right
In Problem div.2 C, can we count distinct matrices which maximises the sum of mex over all subgrids ?
A much simpler solution (in my opinion) exists for Div2D/Div1B.
If we want to bring an element with index i to index j where i>j && i%2==j%2, we just keep swapping back until we get it to j.
Now we see that we need to shift all the elements which will take a lot of time. So to get rid of shifting we would shift the pair of elements which was originally at j,j+1 to i,i+1 using swaps.
This means we can actually just swap elements at i,i+1 with j,j+1.
So we do a simulation for 1<=i<=n-3 each time we bring the minimum possible element to i with swaps.
My solution 319241757 for Div2D/Div1B does not rely on inversions.
Every allowed move flips the “even‑part” inversion parity and the “odd‑part” inversion parity together, So parity_even ⊕ parity_odd is preserved.
What I did?
Split the permutation into two mini‑arrays:
Work out the inversion parity of each block. (ele_count — cycle_count)
Two cases:
▸ Parities already match
→ Just sort each block independently and weave them back together.
(This is lexicographically optimal because every slot gets the smallest possible value still legal for its parity class.)
▸ Parities differ
→ We must flip exactly one block’s parity.
The cheapest way to do that is a single swap of its two largest elements (they sit at the end, so they disturb the prefix the least).
(Try flipping the last pair from EVEN and ODD block, and keep the lexicographically smaller result.)
I had got everything correct but had not checked the inversion parity (WA 2Nd), I did not understand the reason for checking the inversion parity. could you please explain that. Thanks a lot!!
Take the case of N=4 and A ={1,4,3,2}.
what would be your output and what should be the expected?
The reason is consider, we have 5 4 3 2 1 permutation what will be the best possible smallest lexicographical array obviously it is 1 2 3 4 5. Now Let's see what happens when we perform an operation mentioned in the problem and how it behaves. Elements whose positions have same parity that means elements at odd position will always stay in odd positions and same is true for elements at even positions. Now if we wanted to do an operation on (i and i+2) then (i+1 and i+3) or (i+1 and i-1) should be swapped that means one operation leads to 2 swaps 1 on odd positions and 1 on even position. That means to achieve the best possible permutation total swaps happened together(on odd and even positions) will be even and let say it as Y now consider a1 is no of swaps performed on even positions and a2 on odd positions to achieve the optimal solution then (Y = a1 + a2 ) here Y should be even right then when will sum of 2 numbers become even ? obviously when a1 and a2 both have same parity. But here the question is how can we decide the a1 and a2 parity? For this let's consider an example (3, 2, 1) let's try to sort this in increasing order but we can only swap the adjacent elements then it takes at least 3 swaps to sort it, now try to sort (3, 2, 1) with more than 3 swaps you can see whenever the array become sorted after x operations then x will always be odd. That means parity of no of swaps remains constant. So using this observation we can count the minimum no of swaps required to sort the elements at odd and even positions (a1 & a2) separately as parity remains. Hence, we can say that we will achieve the best possible answer if and only if parity of inversions or swaps is same otherwise, we can just revert one swap on the best possible answer so that it will satisfy the parity of both a1 and a2.To achieve this we reverse last n and n-2 elements why because they are the large elements. This problem is related to Invariant problems and all above observations are invariant properties we need to observe while solving. Sorry for my bad English.
Problem- B
Can someone tell testcase where it is failing — Submission
Someone pls explain the editorial of div2 E, i am unable to understand it
This is a copy-pasted comment from the announcement. I just want to share "simpler" and more straightforward solution for D1.
I have $$$O(n)$$$ solution for D1.
Observation: if $$$p[1...n]$$$ is cute, then $$$p[1...{n-1}]$$$ and $$$p[2...n]$$$ are cute as well. So, we can use two-pointers to calculate intervals $$$(i, r_i)$$$, where $$$(i, r_i)$$$ is the longest cute subarray starting at $$$i$$$.
To do so, we have to maintain LIS and LDS in deque (to simulate two pointers), but notice that $$$(i, r_i)$$$ is cute, meaning that LIS + LDS $$$ = r_i - i + 2$$$ (this fact simplifies problem).
Since, we only considering cute subarrays adding $$$p_j$$$ to the back of the deque is easy, since LIS or LDS must extend by element $$$p_j$$$, and non-extending longest subsequence can only change its last element.
Deleting $$$p_i$$$ from the front of the deque is a bit harder, since it is possible for $$$p_i$$$ to be a beginning for both LIS and LDS. In this case, we can proof that after erasing $$$p_i$$$ we always can extend LIS/LDS in the front by the first element of LDS/LIS.
And the last case occurs when LIS = 1 or LDS = 1 (but not at the same time), in this situation the one having single element must change it to the last element of the other one.
My solution: 319304301
could be solve using Binary Search
Let $$$F$$$($$$x$$$) is a function that calculate $$$Max$$$($$$Right_i$$$) $$$-$$$ $$$Min$$$($$$Left_i$$$), $$$\forall$$$ $$$i$$$ $$$\in$$$ $$$[1,x]$$$, it work as follow
Let all $$$a_i$$$ = $$$min(a_i, x)$$$
iterate on elements from $$$x$$$ to $$$1$$$
for each element take largest right, with smallest left, and the remaining positions move it to previous element
Let $$$z$$$ = $$$x$$$ that gives you $$$max(F(x))$$$,
that mean $$$F(x)$$$ in $$$[1,z-1]$$$ is increasing,
$$$F(z)$$$ is maximum that mean there is Intersections between all ranges, because if there is no Intersection between any 2 ranges for example $$$[1,3]$$$ , $$$[4,6]$$$ $$$(6-4 + 3-1)$$$ < $$$(6-1)$$$ always, that mean for sure there is no Intersections when $$$x$$$ = $$$z$$$, then if we set $$$x$$$ = $$$z-1$$$, it will be still without Intersections, but what happened that we combined two ranges that does Intersection which minimize $$$F(x)$$$
and $$$F(x)$$$ in $$$[z+1,n]$$$ is decreasing
$$$F(z)$$$ is maximum that mean there is Intersections between all ranges, if we do $$$F(z+1)$$$ what will happen that we add another range but it doesn't Intersection with some other range, which minimize $$$F(x)$$$
Now after that step we can easily make a binary search on $$$F(x)$$$ to find $$$F(z)$$$, in my code $$$F(x)$$$ complexity is $$$O(nlogn)$$$ when doing binary search on it total complexity will be $$$O(nlog^2n)$$$ which will pass in ~3s.
319504423
Really?
Based on what's i've understood from D's solution Even if the question was modified to be: "Swap any two elements from odd indices 1..3..5 but you've to swap any two even indices from 2..4..6 also" in one operation the solution would be the same. Since the parity of the number of operations does not change.. regardless if you're just swapping adjacent elements or any two elements.
eg: 4 1 3 5 2 : Odd indices would require 1 swap if we can swap any two odd indices (1&5) but if adjacent odd indices allowed, it would require 3 swaps.
Dear @Shoo @eren__ @sweetweasel @MikeMirzayanov , In the recent codeforces round 1024 Div. 2 contest, i received a mail regarding my C solution https://mirror.codeforces.com/contest/2102/submission/319277228 that it coincided with many other solution. This was purely a coincidence as I have previously solved a similar question on leetcode, here's my submission link for leetcode https://leetcode.com/problems/spiral-matrix/post-solution/?submissionId=1563392392. Traversing a spiral matrix was a standard question on leetcode and it's not difficult to see that subtracting each element will give me the required answer, the logic was completely mine. i have given enough evidences can you pls reconsider about my situation.
Dear Shoo, eren__, sweetweasel, MikeMirzayanov, This Same thing happened with me too .I also solved this similar spiral matrix problem earlier on LeetCode. You can even check the same comments written on both my Codeforces and LeetCode submissions. Leetcode: https://ibb.co/XZ0mHs6t Codeforces: https://ibb.co/Xr7Xgc17 Submission links:https://mirror.codeforces.com/contest/2102/submission/319269814 https://leetcode.com/problems/spiral-matrix/submissions/1209464644 Plzz look into this and consider my explanation.
I had a bit different solution for D1D. The observation that there is some position $$$i$$$ that is in both sequences is still important. We know, that elements to the left of $$$i$$$, that are also $$$ \gt a_i$$$, ascend if going from $$$i$$$ to the left. Similarly elements $$$ \lt a_i$$$ descend. Let's find the first position $$$L_i$$$, when such property fails. Suppose $$$a_{L_i} \gt a_i$$$. Then there is position $$$L_i \lt j \lt i$$$, such that $$$a_{L_i} \lt a_j$$$. Let's find the closest greater element to the right of an element, for all of them. Let's call it $$$rge_i$$$. Then $$$L_i = \max j: a_j \gt a_i, rge_j \lt i$$$.
We can think of this as points on a 2D plane: $$$(i, a_i)$$$. We need to find the maximal $$$j$$$ such that $$$(a_j, rge_j)$$$ is higher and to the left of point $$$(a_i, i)$$$. This can be found via scanline with segment tree or fenwick tree.
What if $$$a_{L_i} \lt a_i$$$. We can do similar thing. Only now we need to find $$$rle_i$$$ — the closest integer to the right that is less that $$$a_i$$$. Similar scanline can be done, so we can find $$$L_i$$$.
To find $$$R_i$$$ we do 2 more scanlines (try not to bug while copypasting). Now we know, that all segments $$$[l, r]$$$ such that $$$L_i \lt l \le i \le r \lt R_i$$$ are good. In order to find the total number of segments we can find the area of unity of rectangles $$$(L_i + 1, i, i, R_i - 1)$$$.
I wonder why... I did see much difference between my code and the ac solution...but I got WA
For problem C of this competition, I guessed the answer was a spiral matrix. After verifying it for a while, I directly used the code I had previously submitted on Luogu. However, it was skipped due to similarity.https://www.luogu.com.cn/problem/P2239
In my opinion D2B was easier than D2A, I got 5 "wrong answer on pretest 2" until I got A right
My code in java at https://mirror.codeforces.com/contest/2102/submission/319616903 got run time error, it exit with code 11, can anyone help me?
I am wondering if there is a solution for F that, for each coolness value, calculates the number of tree colorings with this coolness value. I only know how to solve this in $$$O(n^2 \log^2 n)$$$ time.
I don't quite understand, if there's only one red and one blue node(obviously there will exist special nodes on the path between them), will there exist a super-special node?
eren__ pls answer, thx.
Div.2 B can be written in Python simpler.This is the style of Python
Dear Shoo, eren__, sweetweasel, MikeMirzayanov, In the recent codeforces round 1024 Div. 2 contest, I received an email regarding my C solution https://mirror.codeforces.com/contest/2102/submission/319271302 that it coincided with many other solution. This was purely a coincidence as I have previously solved a similar question on leetcode, here's my submission link for leetcode https://leetcode.com/problems/spiral-matrix/submissions/1490667996/ and from where I had learnt this a few months ago https://takeuforward.org/data-structure/spiral-traversal-of-matrix/. Traversing a spiral matrix was a standard question everywhere. Can you please reconsider my skipped solutions.
Can anyone direct me to where I am wrong?
This is my submission
How can i farm positive contribution?
Thank you for Editorial
Can anyone tell how to find sum of mex of all subgrids in Div2 C question
anyone know how to solve the follow up Bonus question for Mex in the grid question
"We had the idea of dividing this problem into two subtasks, in which the second subtask requires you to count the sum of MEX of all subgrids! "
bad editorial for div1c , what is meant by it can be proven ? The editorial is incomplete .
for problem Div1C
how to prove its always possible to obtain array B with the maximum matches for each index ?
can someone please give an explanation of 2101B — Quartet swapping, of the part of ordering of last three elements.
Could you guys tell me what's wrong with my submission for 2101B? https://mirror.codeforces.com/contest/2101/submission/321669351
Why C give the incomplete and ambiguous editorial?
For the Div2E (23 Kingdom), why does their approach of adding up the number of begins (at or before index $$$i$$$) and the number of ends after $$$i$$$ not overcount the distance?
For example, take: 1 1
Here, the distance should be 2. The number of begins at or before index 1 is 1 and the same for index 2. The number of ends after index 1 is 1, and 0 for index 2. Adding these together gives 3 which is not 1.
First, sorry for necroposting.
Here is a different idea for div1D.
For an array to be cute, every element should be part of LIS or LDS, and one should be part for both.
For each index $$$i$$$ we will find longest subarray to the left $$$[L[i], i]$$$ that is good, and longest on the right $$$[i, R[i]]$$$.
To find $$$L[i]$$$, we will run two stacks, one for finding nearest smaller and one for nearest greater. Now
$$$[L[i], i]$$$ is good if sum of number of elements $$$ \gt = L[i]$$$ in both stacks is $$$i-L[i]+1$$$.
We can find $$$R[i]$$$ in the same manner.
To implement, we can bin search on $$$L[i]$$$ and to find element $$$ \gt = L[i]$$$ we can also bin search the stacks.
Problem 2101 kingdoms , really skips much desired explanation, in everything it's like it can be proved .
Can someone please explain this part in the div2 C solution :
<< Proof: The multiplication of two numbers with the same sum is maximized when they are as close to each other as possible. Therefore, for each subgrid, if we consider the empty rows above and below it and separately consider the columns on its right and left, if one is fixed, the place is optimized to be in the middle. Now, similarly, we can say that it is optimal if the length and height of the subgrid are close to each other as well, as increasing one will cause the other one to decrease. With these two observations combined, a subgrid having the above properties is optimal when it's a nearly square subgrid in the middle of the grid. >>
For anyone looking for the problem B code in C++
351530979
Dear Shoo, eren__, sweetweasel, MikeMirzayanov,
Please pay attention to this.
I am getting the bigger answer than the test case. for n = 3,
Answer given is : 8 4 5 6 0 1 7 2 3 sum = 23
My answer:
0 1 4 2 3 5 7 6 8 sum = 30
Basically the approach I used was to keep numbers as near as possible to 0.
Sorry, my bad :(
:)
:)
can any one tell me why this the first approach of mine of start with right then down then left then up passes but the approach with down left up right fails!! 369534888 369534946