


✨ Hope you enjoyed the problems! ✨
2127A - Mix Mex Max
Idea: Bahamin
Preparation: Hamed_Ghaffari
What happens if $$$\operatorname{mex}([a_i, a_{i+1}, a_{i+2}]) = 0$$$?
Now what happens if $$$\operatorname{mex}([a_i, a_{i+1}, a_{i+2}]) \neq 0$$$?
Let's see when does $$$\operatorname{mex}([a_i, a_{i+1}, a_{i+2}])$$$ equal $$$\max([a_i, a_{i+1}, a_{i+2}]) - \min([a_i, a_{i+1}, a_{i+2}])$$$.
Case 1: $$$\operatorname{mex}([a_i, a_{i+1}, a_{i+2}]) = 0$$$
This implies that all numbers are equal and non-zero, since otherwise $$$\min$$$ would be less than $$$\max$$$ and the difference wouldn't be $$$0$$$.
Case 2: $$$\operatorname{mex}([a_i, a_{i+1}, a_{i+2}]) \neq 0$$$
In this case $$$\min([a_i, a_{i+1}, a_{i+2}])$$$ should be $$$0$$$ because $$$0$$$ is in the sequence. So $$$\operatorname{mex}([a_i, a_{i+1}, a_{i+2}]) = \max([a_i, a_{i+1}, a_{i+2}])$$$ but this is not possible, since $$$\operatorname{mex}([a_i, a_{i+1}, a_{i+2}])$$$ should not be among $$$a_i$$$, $$$a_{i+1}$$$, or $$$a_{i+2}$$$.
So an array is good if all elements are equal and non-zero. Remove every $$$-1$$$ from $$$a$$$, then check whether all remaining elements are equal and non-zero.
#include <bits/stdc++.h>
using namespace std;
int main() {
int tc;
cin >> tc;
while (tc--) {
int n;
cin>>n;
vector<int> v(n);
for (int i = 0; i < n; i++) cin >> v[i];
set<int> s(v.begin(), v.end());
s.erase(-1);
if (s.size()<=1 && !s.count(0)) cout<<"YES"<<endl;
else cout<<"NO"<<endl;
}
}
2127B - Hamiiid, Haaamid... Hamid?
Idea: _R00T and Error_Yuan
Preparation: _R00T and Hamed_Ghaffari
The answer to the problem only depends on $$$x$$$, $$$n$$$, the index of the wall Hamid would hit if he moves to the left, and the index of the wall he would hit if he moves to the right.
If we denote the two indices defined in Hint 1 as $$$L$$$ and $$$R$$$, then in each of Hamid's turns, he can move in a way that ensures by the next time, either $$$L$$$ has decreased by at least one, or $$$R$$$ has increased by at least one, regardless of Mani's moves. So, if it's Hamid's turn, what is the maximum possible answer in terms of $$$L$$$, $$$R$$$, and $$$n$$$?
The answer is at most $$$\min(L + 1, n - R + 2)$$$.
Suppose it's Hamid's turn. If there is no wall to his right or to his left, he can escape the grid in one move. Otherwise, define:
- $$$L$$$ as the index of the wall Hamid would reach if he moves to the left.
- $$$R$$$ as the index of the wall he would reach if he moves to the right.
Hamid can move to the left and decrease $$$L$$$ by at least one. (Since $$$L$$$ is always to the left of Hamid's current position, when Hamid moves left, he reaches and destroys the wall at position L. As a result, on his next turn, the new L will be at least one position further to the left. meaning $$$L$$$ decreases by at least one, regardless of Mani's actions.) Similarly, Hamid can increase $$$R$$$ by at least $$$1$$$ by moving to the right and destroying the wall there.
So, since Hamid wants to escape in the minimum number of moves, he can escape the grid in at most $$$\min(L + 1, n - R + 2)$$$ moves.
On the other hand, with each of Hamid's moves, Mani can place a wall in such a way that $$$L$$$ decreases by at most one or R increases by at most one.
So the minimum number of moves Hamid needs is also $$$\min(L + 1, n - R + 2)$$$.
Therefore, assuming Hamid starts first, the answer is $$$\min(L + 1, n - R + 2)$$$.
Now consider Mani's first move. Since Mani wants to maximize the number of days Hamid needs. Moreover, with each of his moves, at least one of the $$$L$$$ or $$$R$$$ remains unchanged. So, on his first move, he can:
- maximize $$$L + 1$$$ by setting $$$L = x - 1$$$, or
- maximize $$$n - R + 2$$$ by minimizing $$$R$$$, setting it to $$$x + 1$$$.
So the answer becomes either $$$\min((x-1) + 1, n - R + 2)$$$ or $$$\min(L + 1, n - (x+1) + 1)$$$.
Because Mani wants the number of days to be as large as possible, the final answer is: $$$\max(\min(x, n - R + 2), \min(L + 1, n - x + 1))$$$
We can easily find L and R with a time complexity of $$$\mathcal{O}(n)$$$. Therefore, the problem is solved in $$$\mathcal{O}(n)$$$ time complexity.
#include<bits/stdc++.h>
using namespace std;
int32_t main() {
cin.tie(0); cout.tie(0); ios_base::sync_with_stdio(0);
int tc;
cin >> tc;
while(tc--) {
int n, x;
string s;
cin >> n >> x >> s;
if(x==1 || x==n) {
cout << "1\n";
continue;
}
x--;
int inf = 1e9;
int lf=-inf, rg=inf;
for(int i=x-1; i>=0; i--)
if(s[i]=='#') {
lf=i;
break;
}
for(int i=x+1; i<n; i++)
if(s[i]=='#') {
rg=i;
break;
}
if(lf==-inf && rg==inf) {
cout << "1\n";
continue;
}
cout << max(min(x+1, n-rg+1), min(lf+2, n-x)) << '\n';
}
return 0;
}
2127C - Trip Shopping
Idea: Bahamin
Preparation: Bahamin and _R00T
We can see that permuting arrays $$$a$$$ and $$$b$$$ in the same way or changing $$$a_i$$$ with $$$b_i$$$ for a specific index $$$i$$$ doesn't change the answer. WLOG assume $$$a_i \leq b_i$$$ is always true.
Imagine Ali selects indices $$$i$$$ and $$$j$$$ in a round of game. What are all the different new arrays Bahamin can achieve?
Can Ali ever achieve a $$$value$$$ less that the initial $$$value$$$?
He can't. Because Bahamin can always keep the chosen indices as they are, and so the $$$value$$$ won't change. No matter what Ali does.
Read the hints.
Let’s first address hint $$$2$$$. To determine all arrays that Bahamin can reach, WLOG assume $$$a_i \leq b_i \leq a_j \leq b_j$$$. The specific order doesn't matter, since Bahamin can permute them freely. Set $$$x_1 = a_i$$$, $$$x_2 = b_i$$$, $$$x_3 = a_j$$$, $$$x_4 = b_j$$$ — this makes the following cases reachable for Bahamin:
- $$$a_i := x_1, b_i := x_2, a_j := x_3, b_j := x_4 \rightarrow \space value = x_2 - x_1 + x_4 - x_3$$$
- $$$a_i := x_1, b_i := x_3, a_j := x_2, b_j := x_4 \rightarrow \space value = x_3 - x_1 + x_4 - x_2$$$
- $$$a_i := x_1, b_i := x_4, a_j := x_2, b_j := x_3 \rightarrow \space value = x_4 - x_1 + x_3 - x_2$$$
Other cases are similar (based on Hint $$$1$$$). We observe that the second and third options yield the same $$$value$$$, while the first option is exactly $$$2 \times (x_3 - x_2)$$$ less than the other two. There are now two possible cases:
Case 1: Ali can choose two indices $$$i$$$ and $$$j$$$ such that the ordering of $$$[a_i, b_i, a_j, b_j]$$$ already matches one of the second or third options. In this case, Bahamin cannot increase the value when he is initially given indices $$$i$$$ and $$$j$$$. Since Ali also cannot reduce the $$$value$$$, his optimal strategy is to always give Bahamin such indices so that the final $$$value$$$ remains equal to the initial $$$value$$$.
Case 2: Ali cannot find any two indices $$$i$$$ and $$$j$$$ that match the second or third option. This implies that for every pair of indices $$$i, j$$$, either $$$b_i \lt a_j$$$ or $$$b_j \lt a_i$$$. We claim the answer is $$$\sum\limits_{i=1}^{n} (b_i - a_i) + \min\limits_{1 \leq i, j \leq n, \space b_i \lt a_j} (2 \times (a_j - b_i))$$$.
A strategy for Ali is to always select the two indices $$$i, j$$$ such that $$$b_i \lt a_j$$$ and the difference $$$a_j - b_i$$$ is minimized. Bahamin can increase the $$$value$$$ only once — when he changes the configuration of indices $$$i, j$$$ from the first option to either the second or third option. We know this increases the initial $$$value$$$ by exactly $$$2 \times (a_j - b_i)$$$. Also, it's impossible for Ali to force any $$$value$$$ lower than this. Since regardless of Ali's selection, Bahamin can always change it to the second or third option, and by definition, any choice by Ali gives Bahamin a chance to increase $$$value$$$ by at least our claimed amount. Also Bahamin should skip his turn (i.e., make no changes) on all subsequent turns after the first.
Now to calculate the answer so that it fits the time limit, let’s first represent our array as a set of $$$n$$$ segments of the form $$$[a_i, b_i]$$$ on the number line. An interesting property of this representation is that the first option now corresponds to two completely separate intervals, while the second and third options correspond to two intersecting intervals.
Now finding the answer becomes relatively easy. Sort the intervals by their left endpoint. If there are two neighboring intervals that intersect, then the input satisfies the Case 1 condition, and so the answer is the initial $$$value$$$. Otherwise, we observe that all pairs of intervals are non-intersecting, and thus the input satisfies the Case 2 condition. The answer, based on Case 2 and our earlier definitions, is $$$2 \times (\text{distance between closest two segments}) + (\text{initial value})$$$.
The two closest intervals must also be adjacent after sorting by their left endpoint. So, by computing the minimum distance between each pair of neighboring intervals, we obtain a solution in $$$\mathcal{O}(n \log n)$$$.
#include <bits/stdc++.h>
using namespace std;
const int MXN = 2e5+5;
int n, k, a[MXN];
void Main() {
cin >> n >> k;
for(int i=1; i<=n; i++) cin >> a[i];
vector<pair<int, int>> vec;
long long ans = 0;
for(int i=1, b; i<=n; i++) {
cin >> b;
if(b<a[i]) swap(b, a[i]);
ans += b-a[i];
vec.push_back({a[i], b});
}
sort(vec.begin(), vec.end());
for(int i=1; i<n; i++)
if(vec[i].first<=vec[i-1].second) {
cout << ans << '\n';
return;
}
int mn = 2e9;
for(int i=1; i<n; i++)
mn = min(mn, vec[i].first - vec[i-1].second);
cout << ans + 2*mn << '\n';
}
int32_t main() {
cin.tie(0); cout.tie(0); ios_base::sync_with_stdio(0);
int tc;
cin >> tc;
while(tc--) Main();
}
There were completely different versions of this problem at first.
The original version was that Ali and Bahamin would take turns, and on each turn, a player would perform both operations described in the problem. Their goals and the constraints were similar to what is stated in the final version of the question.
Can you solve it?
2127D - Root was Built by Love, Broken by Destiny
Idea: _R00T and Bahamin
Preparation: _R00T and Hamed_Ghaffari
We can prove that the map of Destinyland contains no cycles.
Take a look at the map below:
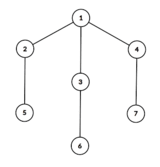
Prove that a tree can be a valid Destinyland map if and only if it does not contain a subtree that looks like the one shown in Hint 2.
If we remove all the leaves from the Destinyland tree, the remaining graph forms a simple path.
Let $$$G$$$ be the graph of the Destinyland map.
If there exists a subgraph $$$H$$$ of $$$G$$$ that cannot be a valid Destinyland map, then $$$G$$$ itself cannot be valid either.
To prove this, assume, for contradiction, that $$$G$$$ is valid but $$$H$$$ is not. Then, by removing the vertices and edges not in $$$H$$$, we get a subgraph $$$H$$$ that should also be valid. But it isn't! This contradicts our assumption, so $$$G$$$ cannot be valid either.
Lemma 1: A cycle of any length cannot be a valid Destinyland map.
Proof: Assume the opposite. Let $$$v$$$ be the leftmost house on the northern side. It has two neighbors on the southern side. Let the one on the left be $$$L$$$ and the other one $$$R$$$. Since $$$L$$$ must have another neighbor besides $$$v$$$, that neighbor cannot be on the southern side, so it must be on the northern side. However, since $$$v$$$ is the leftmost node, this neighbor must be to the right of $$$v$$$, and the edge between $$$L$$$ and this neighbor would cross the edge $$$v$$$—$$$L$$$. This contradiction shows that $$$L$$$ cannot have another neighbor besides $$$v$$$, which contradicts our assumption that the graph is a cycle.
Lemma 2: The following tree cannot be a valid Destinyland map:
Proof: Vertices $$$2$$$, $$$3$$$, and $$$4$$$ are all on the side opposite vertex $$$1$$$. If we place them in order from left to right as $$$u_1$$$, $$$u_2$$$, and $$$u_3$$$, then the neighbor of $$$u_2$$$ will necessarily create a crossing either with edge $$$1$$$—$$$u_1$$$ or $$$1$$$—$$$u_3$$$. Therefore, it is impossible to arrange the vertices of this tree in a valid Destinyland layout.
From Lemma 1 and Lemma 2, we conclude that:
- $$$G$$$ must be a tree.
- No vertex in $$$G$$$ can be connected to three or more non-leaf neighbors.
Now, remove all the leaf nodes. Since these leaves are always non-cut vertices (i.e., their removal doesn't disconnect the tree), the remaining graph, if it exists, is still connected. Since all remaining vertices have degree at most $$$2$$$. So the resulting structure must be a path.
Case 1: The graph becomes empty after removing leaves.
In this case, the original graph was just a single edge. So the answer is simply $$$2$$$.
Case 2: Only one vertex remains.
In this case, the original tree was a star. Depending on which side we place the central vertex, and how we permute the leaves, the answer is: $$$2\times(n−1)!$$$
Case 3: Two connected non-leaf vertices $$$u$$$ and $$$v$$$ remain.
In this case, there are $$$4$$$ valid placements depending on which one is on the northern side and how their adjacent leaves are arranged around the other. ( Note: It's impossible for either $$$u$$$ or $$$v$$$ to have neighbors on both sides of the other.)
So the answer is: $$$4\times(d_u−1)!\times(d_v−1)!$$$ where $$$d_u$$$ and $$$d_v$$$ are the degrees of $$$u$$$ and $$$v$$$, respectively.
Case 4: The remaining structure is a path of length at least $$$3$$$.
In this case, we have $$$4$$$ valid ways to place it. These depend on which vertices are placed on the northern side, and how the two vertices from one side with at least two vertices are positioned. (Since the path has at least $$$3$$$ vertices, there's no conflict.)
Now, we only need to arrange the leaves adjacent to each vertex relative to each other. Because their positions relative to the other vertices depend only on the four ways to arrange the main path. The proof of that is boring, so we won’t bore you with it :)
Let $$$S$$$ be the set of vertices on the path, and let $$$Saha_i$$$ be the number of leaves connected to vertex $$$i$$$. Then the total number of valid layouts is: $$$4 \times \prod\limits_{r \in S} (Saha_r!)$$$
To implement the solution:
- Check if the input graph is a tree.
- Verify that no vertex has more than two non-leaf neighbors.
- Count the number of non-leaf vertices.
- Based on that count, determine which case applies and compute the answer accordingly.
The entire algorithm runs in $$$\mathcal{O}(n)$$$ time.
#include <bits/stdc++.h>
using namespace std;
#define SZ(x) int(x.size())
const int MOD = 1e9 + 7;
const int MXN = 2e5 + 5;
int n, m, fact[MXN];
vector<int> adj[MXN];
int32_t main() {
cin.tie(0); cout.tie(0); ios_base::sync_with_stdio(0);
fact[0] = 1;
for (int i = 1; i < MXN; i++)
fact[i] = (1ll * fact[i-1] * i) % MOD;
int T;
cin >> T;
while (T--) {
cin >> n >> m;
for (int i = 1; i <= n; i++) adj[i].clear();
for (int i = 1; i <= m; i++) {
int u, v;
cin >> u >> v;
adj[u].push_back(v);
adj[v].push_back(u);
}
long long ans = 2;
int tl = 0;
if (m >= n) ans = 0;
for (int u = 1; u <= n; u++) {
if (adj[u].size() > 1) {
int x = 0;
for (int v : adj[u]) {
x += (SZ(adj[v]) == 1);
}
if (x >= SZ(adj[u]) - 2) (ans *= fact[x]) %= MOD;
else ans = 0;
} else tl ++;
}
if (tl < n-1) tl = 2; else tl = 1;
cout << (ans * tl % MOD) << '\n';
}
return 0;
}
2127E - Ancient Tree
Idea: Bahamin
Preparation: Bahamin and Hamed_Ghaffari
There are some vertices that will always be cutie, no matter how the other vertices are colored. What are these vertices?
We can show that there exists a coloring where only the vertices mentioned in Hint 1 become cutie. So, the final answer is the sum of the weights of the vertices mentioned in Hint 1.
Read the hints.
We will use a very useful and interesting technique called the Virtual Tree (or Auxiliary Tree). You can learn more here: Virtual Tree. There are other solutions to this problem, but they use a similar core idea.
The virtual tree of a set of vertices like $$$S$$$ is defined as this set:
$$$A = S \cup \{\operatorname{lca}(u, v) \mid u, v \in S \}$$$
Now let's build this virtual tree for the vertices of each color separately. After this, all vertices fall into three categories:
- Vertices that are in no virtual tree.
- Vertices that are in exactly one virtual tree.
- Vertices that appear in more than one virtual tree.
Every vertex like $$$u$$$ of the third type will definitely be cutie, because no matter what color it is assigned, at least one of the colors of the virtual trees it belongs to will be different from $$$u$$$'s color.
So the answer is at least the sum of the weights of all type-3 vertices.
To construct an example with exactly this answer, run a $$$DFS$$$ algorithm. Every time you enter a vertex $$$u$$$, consider the following cases:
- It's type 2. In that case, color it with the color of the virtual tree it belongs to.
- It's type 3. In that case, color it with any color from its subtree (such a color exists by definition). This vertex is cutie anyway.
- It's type 1 and there is some colored vertex in its subtree. Then color this vertex with that color.
- It's type 1 and its entire subtree is uncolored. In that case, color this vertex with its parent's color.
To prove this coloring is valid, observe that coloring a vertex $$$u$$$ with a color from its subtree does not make any new vertices cutie (because any such vertex would already have become cutie due to the same color in $$$u$$$'s subtree). Also, no vertex strictly inside $$$u$$$'s subtree changes status. And $$$u$$$ itself doesn't increase the cost based on how we chose its color.
Now, for the case where we color $$$u$$$ with its parent’s color: if any new cutie vertex appears, it must be the parent. But since both have the same color, there’s no additional cost.
Also, in this constructed example, we never introduce any new colors. So all colors stay within the range $$$[1, k]$$$.
Therefore, the final answer is always the sum of the weights of type-3 vertices—those that appear in more than one virtual tree. These virtual trees can be constructed in $$$\mathcal{O}(n \log n)$$$.
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
const int MXN = 2e5+1, LOG = 18;
int n, k, w[MXN], c[MXN], par[LOG][MXN], stt[MXN], timer, h[MXN], cnt[MXN], col[MXN];
vector<int> g[MXN], cols[MXN];
bool mark[MXN], cutie[MXN];
void dfs(int v) {
stt[v] = timer++;
for(int i=1; i<LOG; i++) par[i][v] = par[i-1][par[i-1][v]];
for(int u : g[v])
if(u!=par[0][v]) {
h[u] = h[v]+1;
par[0][u] = v;
dfs(u);
}
}
inline int jump(int v, int d) {
for(int i=0; i<LOG; i++)
if(d>>i&1)
v = par[i][v];
return v;
}
inline int LCA(int u, int v) {
if(h[u]<h[v]) swap(u, v);
u = jump(u, h[u]-h[v]);
if(u==v) return u;
for(int i=LOG-1; i>=0; i--)
if(par[i][u]!=par[i][v])
u = par[i][u], v = par[i][v];
return par[0][u];
}
void DFS(int v, int cc) {
if(c[v]) cc=c[v];
else c[v]=cc;
for(int u : g[v])
if(u!=par[0][v])
DFS(u, cc);
}
void Main() {
cin >> n >> k;
timer = 0;
for(int i=1; i<=n; i++) {
cnt[i] = 0;
col[i] = 0;
g[i].clear();
cutie[i] = 0;
cols[i].clear();
}
for(int i=1; i<=n; i++) cin >> w[i];
for(int i=1; i<=n; i++) cin >> c[i], cols[c[i]].push_back(i);
for(int i=1, u,v; i<n; i++) {
cin >> u >> v;
g[u].push_back(v);
g[v].push_back(u);
}
bool fnd=0;
for(int i=1; i<=n; i++)
fnd |= c[i];
if(!fnd) {
cout << "0\n";
for(int i=1; i<=n; i++) cout << "1 ";
cout << '\n';
return;
}
dfs(1);
for(int i=1; i<=k; i++) {
sort(cols[i].begin(), cols[i].end(), [&](int u, int v) {
return stt[u]<stt[v];
});
vector<int> V;
for(int j=0, u, v, lca; j+1<int(cols[i].size()); j++) {
u = cols[i][j], v = cols[i][j+1], lca = LCA(u, v);
if(!mark[lca]) {
if(c[lca]) {
if(c[lca] != i) cutie[lca] = 1;
continue;
}
mark[lca] = 1;
cnt[lca]++;
col[lca] = i;
V.push_back(lca);
}
}
for(int v : V) mark[v] = 0;
cols[i].clear();
}
ll val=0;
for(int i=1; i<=n; i++) {
if(cutie[i] || cnt[i]>1) val += w[i];
if(!c[i] && cnt[i]==1) c[i] = col[i];
}
cout << val << '\n';
for(int i=1; i<=n; i++)
if(c[i]) {
DFS(1, c[i]);
break;
}
for(int i=1; i<=n; i++) cout << c[i] << ' ';
cout << '\n';
}
int32_t main() {
cin.tie(0); cout.tie(0); ios_base::sync_with_stdio(0);
int tc;
cin >> tc;
while(tc--) Main();
return 0;
}
2127F - Hamed and AghaBalaSar
Idea: Hamed_Ghaffari and _R00T
Preparation: Hamed_Ghaffari
What exactly is $$$f(a)$$$?
$$$f(a)$$$ is the sum of maximums minus the sum of element right after a maximum minus $$$a_1$$$.
Fix the maximum. How to count the sum of maximums?
You need to solve the following sub-problem:
You are given three integers $$$n$$$, $$$m$$$, and $$$x$$$. How many arrays $$$a_1,a_2,\ldots,a_n$$$ exists such that:
- $$$0 \leq a_i \leq x$$$ for all $$$1 \leq i \leq n$$$
- $$$a_1 + a_2 + \ldots + a_n = m$$$
The sub-problem can be solved in $$$\mathcal{O}(m/x)$$$ using inclusion exclusion.
How to count the sum of an specific element in the sub-problem of Hint 3?
Observation: $$$f(a)$$$ is the sum of maximums minus the sum of element right after a maximum minus $$$a_1$$$.
Suppose that $$$1 = i_1 \lt i_2 \lt \ldots \lt i_k = n$$$ is the indices that we visit in the algorithm, and $$$1 \leq j_1 \lt j_2 \lt \dots \lt j_t = k$$$ is the indices such that $$$a_{i_{j_p}}$$$ is maximum for all $$$1 \leq p \leq t$$$.
If we group the indices like below:
$$$i_1, \ldots, i_{j_1}$$$
$$$i_{j_1+1}, \ldots, i_{j_2}$$$
...
$$$i_{j_{t-1}+1}, \ldots, i_k$$$
each group will be increasing and $$$f(a)$$$ will be:
$$$(a_{i_{j_1}}-a_{i_1}) + \ldots + (a_n - a_{i_{j_{t-1}+1}}) = \sum\limits_{p=1}^{t}a_{i_{j_p}} - \sum\limits_{p=1}^{t-1}a_{i_{j_p+1}} - a_1$$$
Let $$$g(n, m, x)$$$ be the answer of the sub-problem in Hint 3. We can calculate $$$g(n, m, x)$$$ is $$$\mathcal{O}(m/x)$$$ using inclusion exclusion and "Stars and bars".
From now we fix $$$a_n = x$$$ and calculate the sum of $$$f(a)$$$ over all snake arrays with maximum equal to $$$x$$$.
Counting the sum of maximums:
The sum of $$$a_n$$$ over all arrays is $$$x \cdot g(n-1,m-x,x)$$$. The sum of $$$a_i$$$ for all $$$1 \leq i \leq n-1$$$ such that $$$a_i=x$$$ is $$$x \cdot (n-1) \cdot g(n-2, m-2x, x)$$$.
Counting the sum of $$$a_1$$$:
Let $$$s_i$$$ be the sum of $$$a_i$$$ over all snake arrays with $$$a_n=x$$$ for all $$$1 \leq i \lt n$$$.
It turns out that $$$s_i = s_j$$$ for all $$$1 \leq i, j \lt n$$$, because we can swap $$$a_i$$$ and $$$a_j$$$ in every array and there is no difference between $$$i$$$ and $$$j$$$.
The sum of $$$a_1,a_2,\ldots,a_{n-1}$$$ in every snake array is $$$m-x$$$, so $$$s_1+s_2+\ldots+s_{n-1} = (m-x)g(n-1,m-x,x) \rightarrow \space s_1 = \frac{m-x}{n-1}g(n-1,m-x,x).$$$
Counting the sum of elements right after a maximum:
This part is similar to $$$a_1$$$ part. Suppose that $$$a_{i-1}=x$$$, the sum is $$$(m-2x)g(n-2,m-2x,x)$$$ for all $$$1 \lt i \lt n$$$, and $$$x \cdot g(n-2, m-2x,x)$$$ for $$$i=n$$$.
Since for each $$$x$$$ we just need $$$g(n-1, m-x, x)$$$ and $$$g(n-2, m-2x, x)$$$, the solution runs in $$$\sum\limits_{x=0}^{m}{\frac{m}{x+1}} = \mathcal{O}(m\log m)$$$.
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
const int MXN = 4e5+5;
const int MOD = 1e9+7;
ll power(ll a, ll b) {
ll res = 1;
while(b) {
if(b&1) (res *= a) %= MOD;
(a *= a) %= MOD;
b >>= 1;
}
return res;
}
ll F[MXN], I[MXN];
void prep() {
F[0] = 1;
for(int i=1; i<MXN; i++) F[i] = F[i-1]*i%MOD;
I[0] = I[1] = 1;
for(int i=2; i<MXN; i++) I[i] = (MOD-MOD/i)*I[MOD%i]%MOD;
for(int i=2; i<MXN; i++) (I[i] *= I[i-1]) %= MOD;
}
ll C(int n, int r) {
return r<0 || r>n ? 0 : F[n]*I[r]%MOD*I[n-r]%MOD;
}
ll g(int n, int m, int l) {
if(n==0) return m==0;
ll ans = 0;
for(int t=0; t<=n && t*(l+1)<=m; t++)
(ans += C(n,t)*C(m+n-1-t*(l+1), n-1)%MOD*(t%2 ? MOD-1 : 1)%MOD) %= MOD;
return ans;
}
void solve() {
ll n, m, ans=0;
cin >> n >> m;
ll inv = power(n-1, MOD-2);
for(ll x=0; x<=m; x++) {
ll g1 = g(n-1, m-x, x), g2 = g(n-2, m-2*x, x);
(ans += x*(g1+g2*(n-1)%MOD)) %= MOD;
ll bad=0;
(bad += (m-x)*g1%MOD*inv) %= MOD;
(bad += x*g2) %= MOD;
(bad += (m-2*x)*g2) %= MOD;
(ans += MOD-bad) %= MOD;
}
cout << ans << '\n';
}
int32_t main() {
cin.tie(0); cout.tie(0); ios_base::sync_with_stdio(0);
prep();
int tc;
cin >> tc;
while(tc--) solve();
return 0;
}
2127G1 - Inter Active (Easy Version)
Idea: Ali_BBN
Preparation: Hamed_Ghaffari and Ali_BBN
Consider the following graph: $$$i\to p_i$$$. We will see the permutation as the graph.
When asking a permutation $$$q$$$, the result is sum of whether $$$q^{-1}(i) \lt q^{-1}(p_i)$$$.
Why is there a condition about $$$k$$$? If we do not have $$$k$$$, can the permutation $$$[2, 1, 4, 3]$$$ be guessed out?
When we ask a permutation, what does asking the reverse of the permutation help us with?
If we ask the reverse of the permutation except the index $$$k$$$, how many times is each edge of the permutation graph counted in total?
How to choose $$$k$$$?
Let $$$x$$$ be a number that we have not yet fixed, and let $$$k = x + 1$$$.
This partitions the array into three segments:
This tripartition helps in controlling the query behavior.
Queries:
Say we want to find out who maps to vertex $$$i$$$, i.e., find $$$j$$$ such that $$$p_j = i$$$.
Here's how:
- Construct a permutation $$$q$$$ such that $$$q_k = i$$$
- Query this permutation $$$→$$$ receive answer $$$a$$$
- Reverse all elements of $$$q$$$ except the position $$$k$$$
- Query the reversed permutation $$$→$$$ receive answer $$$b$$$
If we consider the permutation graph of p:
- Any edge not involving $$$i$$$ contributes once to the total count. Why?
- The edge where $$$p_j = i$$$:
- Will not be counted if $$$j = q_k$$$. This is not possible because it is guaranteed in the question that $$$p_i\neq i$$$.
- Will be counted in only one of the two queries if $$$j \in q[A \cup C]$$$.
- Will be counted neither if $$$j \in q[B]$$$.
- The edge where $$$p_i = j$$$ will not be counted at all, because $$$i$$$ is at index $$$k$$$.
Thus, $$$a + b$$$ is one of $$$[n - 2, n - 1]$$$ and by comparing $$$a + b$$$, we can find which segment $$$j$$$ (the predecessor of $$$i$$$) lies in.
Repeating the Process:
Once you know the predecessor is in a certain half, you repeat:
- Repartition the candidate set into two
- Choose one half to be placed in $$$A \cup C$$$, and the other in $$$B$$$ (If we had enough capacity).
- Place $$$i$$$ at index $$$k$$$ again.
- Do the same query + reverse trick
Choosing k:
If we set $$$x = \lfloor \frac{n+1}{4} \rfloor,\quad k = x + 1$$$, with each iteration (both in the first query and in the rest of the queries) the size of the candidate set shrinks by a factor of 2.
So to find the predecessor of one number $$$i$$$, we need $$$2 \log (n - 1)$$$ queries.
To find the entire permutation of $$$n$$$ elements $$$2 n\log (n - 1)$$$ queries.
We stay well within the $$$15 \cdot n$$$ limit.
#include <bits/stdc++.h>
using namespace std;
#define SZ(x) int(x.size())
const int MXN = 1003;
int n, k, p[MXN], q[MXN], cnt=0;
int ask() {
cout << "? ";
for(int i=1; i<=n; i++) cout << q[i] << ' ';
cout << endl;
int r;
cin >> r;
return r;
}
void ans() {
cout << "! ";
for(int i=1; i<=n; i++) cout << p[i] << ' ';
cout << endl;
}
bool mark[MXN];
void build(int i, vector<int> opt, vector<int> optbad) {
fill(mark+1, mark+n+1, 0);
fill(q+1, q+n+1, 0);
q[k] = i;
mark[i] = 1;
for(int j=1; j<k && !opt.empty(); j++) {
mark[q[j] = opt.back()] = 1;
opt.pop_back();
}
for(int j=n; !opt.empty(); j--) {
mark[q[j] = opt.back()] = 1;
opt.pop_back();
}
for(int j=k+1; !optbad.empty(); j++) {
mark[q[j] = optbad.back()] = 1;
optbad.pop_back();
}
for(int j=1; j<=n; j++)
if(!mark[j])
opt.push_back(j);
for(int j=1; j<=n; j++)
if(!q[j]) {
q[j] = opt.back();
opt.pop_back();
}
}
void rev() {
vector<int> vec;
for(int i=1; i<=n; i++)
if(i!=k)
vec.push_back(q[i]);
for(int i=1; i<=n; i++)
if(i!=k) {
q[i] = vec.back();
vec.pop_back();
}
}
void Main() {
cin >> n;
k = (n+1)/4+1;
cout << k << endl;
for(int i=1; i<=n; i++) {
vector<int> opt;
for(int j=1; j<=n; j++)
if(j!=i)
opt.push_back(j);
while(opt.size()>1) {
int sz = SZ(opt) - min((SZ(opt)+1)/2, n-(2*k-1));
build(i,
vector<int>(opt.begin(), opt.begin()+sz),
vector<int>(opt.begin()+sz, opt.end()));
int val = ask();
rev();
val += ask();
if(val==n-1) opt = vector<int>(opt.begin(), opt.begin()+sz);
else opt = vector<int>(opt.begin()+sz, opt.end());
}
p[opt.back()] = i;
}
ans();
}
int32_t main() {
int tc;
cin >> tc;
while(tc--) Main();
}
This way can also be implemented with $$$2 \log (n - 1) + \sum\limits_{x=1}^{n - 1}{2 \log x}\sim 12 \cdot n$$$ queries.
2127G2 - Inter Active (Hard Version)
Solution & Analysis: LMydd0225 and Error_Yuan
Preparation: _R00T and Hamed_Ghaffari
This version used an almost completely different approach from G1. Here's the step-by-step analysis:
Consider the following graph: $$$i\to p_i$$$. We will see the permutation as the graph.
When asking a permutation $$$q$$$, the result is sum of whether $$$q^{-1}(i) \lt q^{-1}(p_i)$$$.
Why is there a condition about $$$k$$$? If we do not have $$$k$$$, can the permutation $$$[2, 1, 4, 3]$$$ be guessed out?
If there is a cycle of length $$$2$$$ in the permutation graph (that is, $$$p_i=j$$$ and $$$p_j=i$$$), exactly one of the two corresponding pairs to $$$(p_i, p_j)$$$ and $$$(p_j,p_i)$$$ will be counted in any query when we do not have $$$k$$$. So we have to use $$$k$$$ for cycles of length $$$2$$$. This inspires us to do casework on cycle length $$$=2$$$ or $$$\ge 3$$$.
If the whole permutation graph is composed only of cycles of length $$$2$$$, can you guess out the permutation in about $$$\frac{1}{2}n\log n$$$ queries?
You need to use the property that the permutation graph is composed only of cycles of length $$$2$$$.
Let's say you want to determine what is $$$p_i$$$. Query any permutation $$$q$$$ with $$$q_k=i$$$. If $$$p_i$$$ is among $$$q_1, q_2, \ldots, q_{k-1}$$$, the response to the query will be $$$\frac{n}{2}$$$, otherwise, $$$p_i$$$ is among $$$q_{k+1}, q_{k+2}, \ldots, q_n$$$, and the response will be $$$\frac{n}{2}-1$$$. You can verify this by yourself. Note that permutation graph is composed only of cycles of length $$$2$$$.
Thus, we can put $$$k$$$ around $$$\frac{n}{2}$$$ and apply binary search for a single $$$i\to p_i$$$ with $$$\log n$$$ queries. Note that when we get $$$p_i=j$$$, we also get $$$p_j=i$$$. So we only need $$$\frac{1}{2}n\log n$$$ queries in total.
How can we distinguish $$$i\to p_i$$$ is in which kind of cycle, length of $$$2$$$ or length $$$\ge 3$$$? Try to solve this for a single $$$i$$$ in $$$2\log n$$$ queries. Note that you do not need to determine $$$p_i$$$, you just need to tell whether $$$i\to p_i$$$ is in a cycle of length $$$2$$$.
If $$$i\to p_i$$$ is in a cycle of length $$$\ge 3$$$, we have $$$l$$$ and $$$j$$$ such that $$$l\to i\to j$$$ and $$$l\ne j$$$. Otherwise, $$$l=j$$$.
Consider bitmasks.
Consider cyclic shifts. Do not use $$$k$$$.
Consider the following two queries ($$$m \lt k$$$):
- $$$[q_1, q_2, q_3, \ldots, q_m, \ldots, q_k, \ldots]$$$;
- $$$[q_m, q_1, q_2, \ldots, q_{m-1}, \ldots, q_k, \ldots]$$$.
Only the contribution of $$$x\to q_m\to y$$$ may change: Let's say $$$A=\{q_1,q_2,\ldots,q_{m-1}\}$$$, $$$B=\{q_{m+1}, q_{m+2}, \ldots q_n\}$$$. If $$$x$$$ and $$$y$$$ are both inside $$$A$$$ or both inside $$$B$$$, responses to query 1. and 2. will be the same. Otherwise, answer changes by exactly $$$1$$$. If the responses are different, we can next tell whether $$$x_i$$$ is in $$$A$$$ by looking at whether the difference is $$$1$$$ or $$$-1$$$. However, if the responses are the same, we can't tell whether they are both in $$$A$$$ or both in $$$B$$$.
An idea to tell whether $$$x=y$$$ is to group numbers by their bitmasks. We can use $$$\log n$$$ times such two queries to ask for each bit (let numbers with 0 on this bit in $$$A$$$, those with 1 in $$$B$$$). In the end, we will get $$$x\oplus y$$$. Then we surely get whether $$$x=y$$$.
Step 3.5 needs $$$2\log n$$$ queries for a single element. Can you use $$$n\log n$$$ queries to solve the problem in Step 3.5 for all elements? Note that we are doing cyclic shifts.
Note that we are doing cyclic shifts. In fact, for each $$$i$$$, we just need it to appear at $$$q_1$$$ and $$$q_m$$$ respectively, without changing the set $$$A$$$. Then, for a certain set $$$A$$$, we can do cyclic shifts $$$|A|$$$ times to get all information we need. Similar for $$$B$$$. Thus, we finished the task in Hint 3.6 in $$$n\log n$$$ queries.
Since we will fix $$$k$$$ around $$$\frac{n}{2}$$$ for cycles with length $$$2$$$, we must ensure that $$$|A|$$$ and $$$|B|$$$ are around $$$\frac{n}{2}$$$. But this is not always true. Fortunately, we can resolve this issue by assigning each integer an unqiue number $$$c_i$$$, where $$$0\le c_i\le 2^{\lceil\log n\rceil}-1$$$, so that there will be exactly $$$\frac{n}{2}$$$ (or floor and ceil) 0s and 1s on each bit. We will group the indices by $$$c_i$$$ instead. Now we can put $$$k=\lceil\frac{n}{2}\rceil+1$$$.
Here are the final steps of this problem. First, we run the algorithm in Step 3. Now we get all $$$x_i \oplus p_i$$$, where $$$x_i\to i\to p_i$$$ holds.
First, we will determine all $$$p_i$$$-s on cycles of length $$$\ge 3$$$. Note that we have determined all $$$x_i\oplus p_i$$$, so we only need to determine one edge for each cycle.
Note that in Step 3, when responses to two queries are different, we can know whether $$$p_i$$$ is in $$$A$$$ or $$$x_i$$$ is in $$$A$$$. Note that we can change $$$m$$$ arbitrarily, so we can apply binary search on $$$m$$$ to get one of $$$p_i$$$ and $$$x_i$$$. That finishes the task in $$$\log n$$$ queries for each cycle. On average for each element, it is at most $$$\frac{1}{3}\log n$$$ queries.
After that, we know all $$$p_i$$$-s on cycles of length $$$\ge 3$$$, and we can calculate the response to any query $$$[q_1, q_2,\ldots,q_n]$$$ easily if we don't have $$$k$$$. Similar to Step 2, we can determine all $$$p_i$$$-s on cycles of length $$$2$$$ in $$$\frac{1}{2}n\log n$$$ queries. On average for each element, it is $$$\frac{1}{2}\log n$$$ queries. Thus, in the worst case where the whole permutation graph consists only of cycles of length $$$2$$$, the total number of queries is $$$1.5\lceil\log n\rceil\cdot n$$$. When $$$n=100$$$, it is $$$10.5\cdot n$$$, a little larger than the limit. We can apply a trivial optimization when doing Step 2: do binary serach on possible indices instead of all indices. This will use a total of at most $$$n\log n+\sum\limits_{i=0}^{\lfloor(n-1)/2\rfloor} \log(n-1-2\cdot i)$$$ queries. When $$$n=100$$$, it is $$$986$$$, which fits the constraints well.
#include <bits/stdc++.h>
#define all(s) s.begin(), s.end()
using namespace std;
using ll = long long;
using ull = unsigned long long;
int T;
void solve() {
int n; cin >> n;
const int k = (n + 1) / 2;
const int M = __lg(n - 1) + 1;
cout << k + 1 << endl;
vector<int> p(n + 1);
auto query = [&](vector<int> &q) -> int {
cout << "? ";
for (int i = 1; i <= n; i++) cout << q[i] << " \n"[i == n];
cout.flush();
int res; cin >> res;
return res;
};
vector<int> c(n + 1), d(1 << M);
auto binary_coding = [&]() {
for (int i = 0, cnt = 1; cnt <= n; i++, cnt++) {
c[cnt++] = i;
if (cnt <= n) c[cnt] = (1 << M) - 1 - i;
}
for (int i = 1; i <= n; i++) d[c[i]] = i;
return;
};
vector<int> xors(n + 1);
vector<vector<int>> res1(M, vector<int>(n + 1)), res2(M, vector<int>(n + 1));
vector<int> good, bad;
auto getXORs = [&]() {
for (int bit = 0; bit < M; bit++) {
vector<int> A, B;
for (int i = 1; i <= n; i++) {
if (c[i] & (1 << bit)) B.emplace_back(i);
else A.emplace_back(i);
}
int m = A.size(), l = B.size();
for (int i = 0; i < m; i++) {
vector<int> q(n + 1);
for (int j = 0; j < m; j++) q[j + 1] = A[(j + i) % m];
for (int j = 0; j < l; j++) q[j + m + 1] = B[j];
int res = query(q);
res1[bit][q[1]] = res;
res2[bit][q[m]] = res;
}
for (int i = 0; i < l; i++) {
vector<int> q(n + 1);
for (int j = 0; j < l; j++) q[j + 1] = B[(j + i) % l];
for (int j = 0; j < m; j++) q[j + l + 1] = A[j];
int res = query(q);
res1[bit][q[1]] = res;
res2[bit][q[l]] = res;
}
for (int i = 1; i <= n; i++) {
if (res1[bit][i] != res2[bit][i]) xors[i] ^= (1 << bit);
}
}
for (int i = 1; i <= n; i++) {
if (xors[i] != 0) good.emplace_back(i);
else bad.emplace_back(i);
}
return;
};
auto solve3 = [&]() {
for (auto pos : good) {
if (p[pos]) continue;
int x = xors[pos], bit = __lg(x & (-x));
vector<int> A, B;
for (int i = 1; i <= n; i++) {
if (c[i] & (1 << bit)) B.emplace_back(i);
else A.emplace_back(i);
}
if (c[pos] & (1 << bit)) swap(A, B);
int m = A.size(), l = B.size();
int id = 0;
for (int i = 0; i < m; i++) if (A[i] == pos) id = i;
int L = 2, R = m;
vector<int> base(n + 1);
for (int j = 0; j < m; j++) base[j + 1] = A[(j + id) % m];
for (int j = 0; j < l; j++) base[j + m + 1] = B[j];
while (L < R) {
int mid = (L + R) >> 1;
vector<int> q(n + 1);
for (int i = 1; i < mid; i++) q[i] = base[i + 1];
q[mid] = base[1];
for (int i = mid + 1; i <= n; i++) q[i] = base[i];
int res = query(q);
if (res != res1[bit][pos]) R = mid;
else L = mid + 1;
}
int s = 0;
if (res2[bit][pos] > res1[bit][pos]) p[base[L]] = pos, s = base[L];
else p[pos] = base[L], s = pos;
while (!p[p[s]]) {
int X = xors[p[s]];
p[p[s]] = d[X ^ c[s]];
s = p[s];
}
}
};
auto solve2 = [&]() {
for (auto pos : bad) {
if (p[pos]) continue;
auto calc = [&](vector<int> &q) {
int val = count(all(p), 0) / 2;
vector<int> inv(n + 1);
for (int i = 1; i <= n; i++) inv[q[i]] = i;
for (int i = 1; i <= n; i++) val += (inv[i] < inv[p[i]]);
return val;
};
vector<int> cand, ok;
for (int i = 1; i <= n; i++) {
if (i != pos && !p[i]) cand.emplace_back(i);
if (p[i]) ok.emplace_back(i);
}
while ((int)cand.size() != 1) {
vector<int> q = { 0 }, L, R;
int len = ((int)cand.size() + 1) / 2;
for (int i = 0; i < len; i++) q.emplace_back(cand[i]), L.emplace_back(cand[i]);
for (int i = len; i < k; i++) q.emplace_back(ok[i - len]);
q.emplace_back(pos);
for (int i = len; i < (int)cand.size(); i++) q.emplace_back(cand[i]), R.emplace_back(cand[i]);
for (int i = k - len; i < (int)ok.size(); i++) q.emplace_back(ok[i]);
int res = query(q);
res -= calc(q);
if (res != 0) swap(L, R);
cand = L;
for (auto x : R) ok.emplace_back(x);
}
p[pos] = cand[0];
p[cand[0]] = pos;
}
};
binary_coding();
getXORs();
solve3();
solve2();
cout << "! ";
for (int i = 1; i <= n; i++) cout << p[i] << " \n"[i == n];
cout.flush();
return;
}
int main() {
ios::sync_with_stdio(false), cin.tie(0), cout.tie(0);
cin >> T;
while (T--) {
solve();
}
}
2127H - 23 Rises Again
Idea: sweetweasel and eren__
Preparation: Hamed_Ghaffari and _R00T
Each connected component of a candy graph is either a simple path or a simple cycle.
Try to break the problem down into smaller parts.
Take a DFS tree, at most $$$5$$$ back-edges pass through each vertex.
Choose a vertex $$$v$$$, brute force on the back-edges that pass through $$$v$$$ and appears in the subgraph with maximum number of edges, then remove $$$v$$$ and all back-edges that pass through $$$v$$$.
Now we have to solve the following sub-problem for each connected component:
You are given a simple connected graph that each vertex belongs to at most $$$5$$$ simple cycles, and an array $$$d_1,d_2,\ldots,d_n (0 \leq d_i \leq 2)$$$. What is the subgraph with maximum number of edges that degree of vertex $$$i$$$ is at most $$$d_i$$$.
The sub-problem can be solved in $$$\mathcal{O}(2^nnm)$$$ with dp bitmask.
Let $$$N$$$ be the size of the component with the maximum size after removing $$$v$$$ and back-edges that pass through $$$v$$$.
We can solve the problem in $$$\mathcal{O}(2^5 2^NNm)$$$.
Choose $$$v$$$ as the centroid of the DFS tree.
Since $$$N \leq n/2$$$ the complexity will be $$$\mathcal{O}(2^5 2^{n/2}nm)$$$.
Is the complexity really $$$\mathcal{O}(2^5 2^{n/2}nm)$$$?
Each connected component of a candy graph is either a simple path or a simple cycle.
Take a DFS tree, at most $$$5$$$ back-edges pass through each vertex, then choose a vertex $$$v$$$, brute force on the back-edges that pass through $$$v$$$ and appears in the subgraph with maximum number of edges, then remove $$$v$$$ and all back-edges that pass through $$$v$$$.
Let $$$d_i$$$ be the maximum degree that vertex $$$i$$$ can have. Initially $$$d_i=2$$$ for each vertex. Each back-edge $$$(x,y)$$$ that you select, reduces $$$d_x$$$ and $$$d_y$$$ by $$$1$$$. If after selecting back-edges that pass through $$$v$$$, there exists a vertex with negative $$$d$$$, skip this case. Otherwise you have to solve the sub-problem in Hint 4 for every connected component.
We can solve the sub-problem with the following dp bitmask:
Let $$$ans_{mask}$$$ be the answer for $$$mask$$$, and let $$$dp_{mask,u,v,l1}$$$ be the answer for $$$mask$$$ where the last path we selected is from $$$u$$$ to $$$v$$$ and $$$l1 \in \text{{0, 1}}$$$ means that the length of the path is $$$1$$$ or not.
Transitions:
- Start a new path: $$$ans_{mask}+1 \to dp_{mask,u,v,1}$$$, if $$$(u,v)$$$ is an edge outside $$$mask$$$ with $$$d_u, d_v \geq 1$$$.
- Add a vertex to the last path: $$$dp_{mask,u,v,l1}+1 \to dp_{mask+2^w,u,w,0}$$$, if $$$w$$$ is a vertex outside $$$mask$$$ and adjacent to $$$v$$$, and $$$d_v = 2, d_w \geq 1$$$.
- Make the last path cycle: $$$dp_{mask,u,v,0}+1 \to ans_{mask}$$$, if there exists a $$$(u, v)$$$ edge, and $$$d_u = d_v = 2$$$.
- Skip a vertex: $$$ans_{mask} \to ans_{mask+2^w}$$$, if $$$w$$$ is a vertex outside $$$mask$$$.
Also, you have to solve the sub-problem for each component twice, because you can choose a DFS tree edge connected to the vertex that you've deleted and it reduces $$$d$$$ of one vertex in that component.
It can be seen that if $$$N$$$ be the size of the component with the maximum size, the complexity will be $$$\mathcal{O}(2^NNm)$$$ for a fixed set of back-edges, and $$$\mathcal{O}(2^52^NNm)$$$ in total.
If we select $$$v$$$ as the centroid of the DFS tree $$$N$$$ will be less than or equal to $$$n/2$$$ so the complexity will be $$$\mathcal{O}(2^5 2^{n/2}nm)$$$.
It can be proven that $$$m \leq 3n$$$ in graphs that each vertex belongs to at most $$$5$$$ simple cycles. So the complexity will be $$$\mathcal{O}(2^52^{n/2}n^2)$$$.
We prove this by induction. suppose that $$$m \leq 3n$$$ for all graphs with $$$n \lt N$$$.
Take a DFS tree, we can prove that the degree of a leaf is at most $$$3$$$, because otherwise at least $$$3$$$ back-edges would exit that leaf and there would be at least $$$6$$$ cycles containing that leaf.
So there always exists a vertex with degree $$$\leq 3$$$, we can remove it, $$$m \leq 3(N-1) + 3 = 3N$$$.
#include <bits/stdc++.h>
using namespace std;
#define SZ(x) int(x.size())
#define maxs(a, b) (a = max(a, b))
const int MXN = 30, MXM = MXN*(MXN-1)/2;
int n, m, U[MXM], V[MXM];
vector<int> g[MXN];
bool tedge[MXM], have_edge[MXN][MXN];
int sz[MXN];
void dfs1(int v) {
sz[v] = 1;
for(int i : g[v]) {
int u = v^U[i]^V[i];
if(!sz[u]) {
tedge[i] = 1;
dfs1(u);
sz[v] += sz[u];
}
}
}
int centroid(int v, int p=-1) {
for(int i : g[v]) if(tedge[i]) {
int u = v^U[i]^V[i];
if(u!=p && sz[u]+sz[u]>n)
return centroid(u, v);
}
return v;
}
int ID[MXN], id_counter;
vector<int> vertices[MXN];
int dp[1<<(MXN>>1)][MXN>>1][MXN>>1][2], ans_tmp[1<<(MXN>>1)], ans[2];
void dfs_id(int v, int p=-1) {
vertices[ID[v] = id_counter].push_back(v);
for(int i : g[v]) if(tedge[i]) {
int u = v^U[i]^V[i];
if(u!=p) dfs_id(u, v);
}
}
int deg[MXN], pos[MXN];
int solve_(int id) {
int n = SZ(vertices[id]);
for(int msk=0; msk<(1<<n); msk++) {
ans_tmp[msk] = -1e9;
for(int i=0; i<n; i++)
for(int j=0; j<n; j++)
for(int x : {0,1})
dp[msk][i][j][x] = -1e9;
}
ans_tmp[0] = 0;
for(int msk=0; msk<(1<<n); msk++) {
for(int i=0; i<n; i++) if(msk>>i&1)
for(int j=0; j<n; j++) if(i!=j && (msk>>j&1)) {
if(deg[vertices[id][j]]==2) {
for(int eid : g[vertices[id][j]]) if(ID[U[eid]]==ID[V[eid]]) {
int u = vertices[id][j]^U[eid]^V[eid];
if(!(msk>>pos[u]&1) && deg[u]>=1)
maxs(dp[msk^(1<<pos[u])][i][pos[u]][0],
max(dp[msk][i][j][0], dp[msk][i][j][1])+1);
}
if(deg[vertices[id][i]]==2 && have_edge[vertices[id][i]][vertices[id][j]])
maxs(ans_tmp[msk], dp[msk][i][j][0]+1);
}
maxs(ans_tmp[msk], max(dp[msk][i][j][0], dp[msk][i][j][1]));
}
for(int i=0; i<n; i++) if(!(msk>>i&1)) {
maxs(ans_tmp[msk^(1<<i)], ans_tmp[msk]);
if(deg[vertices[id][i]]>=1)
for(int eid : g[vertices[id][i]]) if(ID[U[eid]]==ID[V[eid]]) {
int u = vertices[id][i]^U[eid]^V[eid];
if(deg[u]>=1 && !(msk>>pos[u]&1))
maxs(dp[msk^(1<<i)^(1<<pos[u])][i][pos[u]][1], ans_tmp[msk]+1);
}
}
}
return ans_tmp[(1<<n)-1];
}
void solve(int id, int cent_neighbour) {
ans[0] = solve_(id);
if(deg[cent_neighbour]!=0) {
deg[cent_neighbour]--;
ans[1] = solve_(id);
}
else ans[1] = -1e9;
}
void Main() {
cin >> n >> m;
for(int i=0; i<n; i++) {
g[i].clear();
vertices[i].clear();
sz[i] = 0;
for(int j=0; j<n; j++)
have_edge[i][j] = 0;
}
for(int i=0; i<m; i++) {
tedge[i] = 0;
}
for(int i=0,u,v; i<m; i++) {
cin >> u >> v;
u--, v--;
have_edge[u][v] = have_edge[v][u] = 1;
U[i] = u;
V[i] = v;
g[u].push_back(i);
g[v].push_back(i);
}
dfs1(0);
int cent = centroid(0);
ID[cent] = 0;
id_counter = 0;
for(int i : g[cent]) if(tedge[i]) {
int u = cent^U[i]^V[i];
id_counter++;
dfs_id(u, cent);
for(int j=0; j<SZ(vertices[id_counter]); j++)
pos[vertices[id_counter][j]] = j;
}
vector<int> be;
for(int i=0; i<m; i++)
if(!tedge[i] && (ID[U[i]]^ID[V[i]])) be.push_back(i);
int besz = SZ(be), answer = -1e9;
for(int msk=0; msk<(1<<besz); msk++) {
fill(deg, deg+n, 2);
for(int i=0; i<besz; i++) if(msk>>i&1)
deg[U[be[i]]]--, deg[V[be[i]]]--;
bool deg3 = 0;
for(int i=0; i<n; i++)
if(deg[i]<0) {
deg3 = 1;
break;
}
if(deg3) continue;
int cur[3];
cur[0] = cur[1] = cur[2] = -1e9;
cur[deg[cent]] = __builtin_popcount(msk);
for(int i : g[cent]) if(tedge[i]) {
int u = cent^U[i]^V[i];
solve(ID[u], u);
cur[0] = max(cur[0]+ans[0], cur[1]+ans[1]+1);
cur[1] = max(cur[1]+ans[0], cur[2]+ans[1]+1);
cur[2] = cur[2]+ans[0];
}
answer = max({answer, cur[0], cur[1], cur[2]});
}
cout << answer << '\n';
}
int32_t main() {
cin.tie(0); cout.tie(0); ios_base::sync_with_stdio(0);
int tc;
cin >> tc;
while(tc--) Main();
return 0;
}
It turns out there are some very simple randomized solutions we hadn’t anticipated, as well as approaches using matching and even unexpected ones like backtracking. Unfortunately, these are quite hard to detect and reject without knowing beforehand.
We sincerely apologize for this mistake. We hope you enjoyed the rest of the problems.







Auto comment: topic has been updated by Bahamin (previous revision, new revision, compare).
Fast editorial!
This is really good—very comforting.
Fast response!
why my standing/leaderboard still broken, any ideas?
Edit: I no longer have this problem
same problem first thought my browser issue but checked on all browsers and alt accounts
Thank you for preparing such a clear and detailed editorial. It was truly insightful
although I attempted only 4 problems I enjoyed the contest.. thanks for fast editorial
nice problems and nice explaination thank you
GPT able to solve H....highly unexpected....
proofs?
check this https://mirror.codeforces.com/submissions/Firetruck_iretr
Check my submission for H, there was a post which has been deleted and mentioned he solved H through GPT. I then feeded the problem to GPT and submitted after contest and it got accepted.
This guy blatantly cheated and got top 40 lol: https://mirror.codeforces.com/submissions/ckuhn222/contest/2127
At least they admit to cheating
can anyone clarify where i have done wrong for 2127B - Hamiiid, Haaamid... Hamid?_
code:
import java.util.*;
public class Main { public static int solve(Scanner sc) { int length = sc.nextInt(); int position = sc.nextInt() — 1; String path = sc.next();
int leftWalls = 0, leftEmpty = 0; int rightWalls = 0, rightEmpty = 0; for (int i = 0; i < position; i++) { if (path.charAt(i) == '#') leftWalls++; else leftEmpty++; } for (int i = position + 1; i < length; i++) { if (path.charAt(i) == '#') rightWalls++; else rightEmpty++; } if (leftWalls == 0 || rightWalls == 0) { return 1; } int fromLeft = leftWalls + Math.min(rightWalls, leftEmpty); int fromRight = rightWalls + Math.min(leftWalls, rightEmpty); return Math.min(fromLeft, fromRight) + 1; } public static void main(String[] args) { Scanner sc = new Scanner(System.in); int t = sc.nextInt(); while (t-- > 0) { System.out.println(solve(sc)); } }}
Maybe the best option to escape is choose a direction and don't change it.
Try this test case:
The answer should be 2 because Mani can choose the 3rd grid and block it at first, and Hamid need to use 2 days anyhow.
Easy backtrack solution for H (not as easy as the random shuffle solution, but it did not require any parameter tweaking so I will take it as a win)
We will go in increasing order of vertice id, adding new edges from the current vertice to ones with larger id. Notice that if we can add an edge, it is never beneficial to not do so. That's it.
A, B, C and D are all high-quality! To my surprise the E need virtual tree (or DSU on tree according to the discuss of other participants). Unfortunately I mastered none of them.
Perhaps they are commonly used in advanced problems. Anyway, thanks for sharing these amazing problem and I think I need to learn them now. :D
Isn't E just small to large? I don't know how you need anything more than that.
Yeah, participants around me explain that E only need small-to-large. Virtual tree is mentioned in the tutorial. So I think I need to master both of them.
For problem E, I wasn't aware of virtual tree, and I think the "other solutions" include my small-to-large solution.
We can run DFS on the tree and retrieve the set of colors from each subtree, but only the reference to the sets instead of copying it every time. Determining the color of this node is identical to the editorial's strategy. By merging all the sets into the largest set among them, the total number of insertions during merging is $$$\mathcal{O}(n\log{n})$$$ and each insertion takes $$$\mathcal{O}(\log{n})$$$. Therefore, this solution runs in $$$\mathcal{O}(n\log^2{n})$$$ time in total.
My submission: 332889063
I was actually able to do the part you have mentioned. Can you please help me with the part on how to apply color to non-colored(unknown colored nodes) such a way final answer doesn't increase ? I wasn't able to do this part. :( .
int n , m, k, H, a[maxn], clr[maxn]; int fact[1], ifact[1];
string s; vi g[maxn];
set ms;
int ans;
si * childrenClrs[maxn];
si storage[maxn];
void dfs(int node, int par) {
}
void solve() { dfs(1,-1); cout << ans << endl;
}
You just need to keep these nodes uncolored, and after this phase, you can run another traversal on the tree which propagates the parent's color to its children, and color the uncolored nodes with this color.
Same Thought bro
damn :| . I thought about this approach as well.
If the parent node isn't colored, then what to do ? ( I tried started propagating one of the child's color to its parent. ).
Above approach worked until, test case that has zero colored nodes.
If you followed these "small-to-large" steps, then the only uncolored nodes can only be the root of an uncolored subtree, in which case you can just start the traversal from the root and all nodes will be naturally colored with the parent's color. If the whole tree is uncolored, you can just color the whole tree with color $$$1$$$ and then the cost is $$$0$$$.
In the first case, you can set the root's color as $$$2$$$ during the "small-to-large" phase (children to parent propagation). In the second case, you leave the uncolored nodes in this phase, and during the second traversal you propagate the root's color ($$$2$$$) to its children (parent to children propagation).
got it. thanks for the help. solved it finally.
https://mirror.codeforces.com/contest/2127/submission/332924829
If you find any improvements to my submission, I am all ears. Again, thank you.
Hi, I just solved this problem with the same approach, but I'm concerned about one thing. I store the set of colors for every node in the tree, and don't delete them after I use them. Still, my code only takes around 80MB of memory even though I think its memory complexity is O(n^2). Could you explain why this is the case?
My code: 339460078
god DAMN.
Light speed editorial
solution outline for E without mentioning virtual tree:
iterate nodes in dfs order (i.e. pre-order traversal). i claim that we can assign colors to nodes where $$$c_u=0$$$, such that we don't increase the number of "doomed" vertices (as mentioned in the editorial's hints).
let the "color set" of $$$u$$$ be the set of pre-assigned colors in subtree $$$u$$$. Note that we can obtain this information via small-to-large merging.
For each node $$$u$$$, consider the number of colors that appear in multiple colors sets. If there is exactly 1 such color, let it be $$$s_u$$$, otherwise let $$$s_u=-1$$$.
for nodes where $$$s_u\neq -1$$$ and $$$c_u=0$$$, we want to set $$$c_u:=s_u$$$.
for nodes where $$$s_u=-1$$$ and $$$c_u=0$$$, we set $$$c_u:=c_{fa_u}$$$ where $$$fa_u$$$ is parent of $$$u$$$ or $$$c_u:=1$$$ if $$$u=1$$$.
Notice that in the first case, we don't add doomed vertices since $$$u$$$ doesn't become doomed and none of $$$u$$$'s ancestors can become doomed (they must have been doomed already due to occurences of $$$s_u$$$ in $$$u$$$'s subtree).
In the second case:
a) If all of u's children's color sets are disjoint, then $$$u$$$ doesn't become doomed, and none of $$$u$$$ ancestors can become doomed: $$$fa_u$$$ can't become doomed since $$$c_u=c_{fa_u}$$$, and higher ancestors can't become doomed (otherwise $$$fa_u$$$ would've already made them doomed).
b) If there are >=2 colors that appear in u's children's color sets, then u was doomed already. Then by the same argument in a), we can show that none of u's ancestors become doomed.
Cant understand why i'm getting WA on test 5 in problem D. Probably missing some case where i have to multiply 0. Can someone help? 332893206 Update: NVM got it.
A better solution for H:
Take out a single biconnected component and it's easy to see that any node in this component can have a maximum degree of $$$3$$$. Otherwise any $$$2$$$ neighboring edges from this node can form a cycle (since the graph is biconnected), leading to at least $$$6$$$.
It's also easy to see that there are at most $$$4$$$ nodes with degree $$$=3$$$ in this component, otherwise there will be at least $$$2^3=8$$$ cycles. Since at the end we keep at most $$$2$$$ edges from any node, we can choose an unused edge and delete it from a node with degree $$$=3$$$ without changing the answer. Since we don't know yet which edge is used, we can only brute force to try all possibilities in $$$O(3^4)$$$ time.
Now we have a graph where every node has degree $$$\le 2$$$, which means every component is either a cycle or a chain, and we can do standard dp on this graph to obtain the answer. The dp can be done in $$$O(n)$$$ time if implemented carefully.
Back in the original problem, we build the block-forest of the original graph and do a tree dp on it. For every biconnected component, we do the brute force and dp above with the answers obtained in the subtrees.
The total complexity is $$$O(3^4 n)$$$ (or maybe $$$O(3^4 n^2)$$$), which is way much smaller than the author's solution. The downside is that this solution is very very hard to implement and hard to debug. I wrote ~7K and took >2h to debug it, so this solution won't pay off in the contest, unfortunately :(
I think for H, you should probably assume that a backtracking/heuristic solution exists, since the limits are really small to allow these sorts of solutions. At least testers should have found a better solution and buff $$$n$$$.
Some alternative solutions:
It is the problem 7 of this article. I wrote a Korean translation of it in my blog.
(BEGIN RANT) Actually I opened this page in my Korean blog almost immediately after reading the problem. Unfortunately this was problem 9, and I was lazy to scroll all the way down, so I assumed that it was not in that blog, started thinking and came up with the DP solution. In two of the recent five contests, I was fucked pretty hard by problems that can be googled. This time I solved it by myself, so the damage was somewhat mitigated, but my endless ability to get fucked by known problems kinda frightens me, especially given the history that I was usually the one exploiting that. I suppose Karma police is real. (END RANT)
What I came up instead was the following: Say a back edge (u, v) "corresponds" to a vertex $$$w$$$ if $$$w$$$ is in a path between $$$u$$$ and $$$v$$$ in the DFS tree (incl. endpoints). For all vertex there are $$$\leq 5$$$ corresponding edges.
Now I run a tree DP — $$$DP[v][S][p]$$$ is the maximum edge (or sum of deg) to be taken for a subtree of $$$v$$$, choose the edges in $$$S$$$ where $$$S$$$ is the subset of edges that corresponds to $$$v$$$, and $$$p$$$ is a boolean flag denoting if I choose the edge between $$$(v, par(v))$$$.
Transitions can be done in $$$O(4^5)$$$ time and can be optimized to $$$O(2^5)$$$ time (but why?). So the solution works in $$$O(n 4^5)$$$ time. My extremely lazy implementation works in 62ms.
ksun48 shared his solution. I would rather implement mine, but that solution made me happy, so I'll write it here.
If a graph contains a $$$K_4$$$ minor, each vertex of that $$$K_4$$$ minor will have at least $$$6$$$ cycles that passes through it. Hence an input graph can not contain any $$$K_4$$$ minor. Hence it's treewidth is at most $$$2$$$. You can recognize it in linear time. Now you can write a DP solution for bounded treewidth, or exploit the series-parallel condition.
Probably you can even argue that the # of optimal solutions can be maintained in edge insertion/deletion updates, so now the optimal solution can be found in $$$O(\log n)$$$ time per output, which seems much better than $$$O(n^2 2^{n/2})$$$ time per output in the Editorial.
I present to you the dumbest solution for A. I noticed the pattern... but didn't realize I could just code it like that
✅ AC on 332878042
is there a DFS based approach for D ?something where we count child with deg one and use factorial based logic after that ??
https://mirror.codeforces.com/contest/2127/submission/332864988
https://mirror.codeforces.com/contest/2127/submission/332955943
thanks i was able to debug the code, didnt write the whole thing on my own tho but idea is similar , instead of making cases and starting with 1 , i started with max deg then made one case for the root
https://mirror.codeforces.com/contest/2127/submission/332872778
getCount() in my code is essentially the DFS function you are looking for. This is DFS as well as BFS, because, the graph is almost chain-graph.
I like the problems, especially E. Thanks for the contest!
In problem C i ordered (arrA[i],arrB[i]) array by arrA[i] and look for adjacent pairs to find shorter distance. Should it work or are cases weak?
It should work. I did the same. Basically, lets say a,b,c,d are the numbers that bob is gonna rearrange. He will benefit when (lets say min of these 4 is a and max is d) a and d are far away from each other but are already not paired up. So our idea works because we try to keep this a and d as close as possible and then calculate the ans.
https://mirror.codeforces.com/contest/2127/submission/332968054
Thank you by your reply, but i couldnt understand what is gonna happen in a case like:
(1,2) (2,50) (3,4)
comparing by x will keep this order, but best choice would be (1,2) (3,4) instead of (1,2) (2,50)
I don't exactly understand what you mean by "(1,2)(3,4) instead of (1,2)(2,50)"
Supose a = [1,2,3] and b = [2,50,4]
Index 0 -> pair (1,2) Index 1 -> pair (2,50) Index 2 -> pair (3,4)
If we sort by x and compare adjacent pairs, we will compare (1,2) with (2,50) and (2,50) with (3,4), while the best option is (1,2) with (3,4)
Do you mean to say, Alice will choose [1,2] and [3,4]?
Yes, thats the optimal choice, but i cant see how it works when we choice pairs ordering by x
If Alice chooses [1,2][3,4], Bob would rearrange them to make [1,4][2,3] which will increase the original answer by 2. Alice would actually choose [2,50][3,4] as no matter how Bob rearranges it, he can't increase the answer.
I think you are confused between Alice and Bob's goals. Alice is trying to choose i and j such that the answer as a minimum increase, or possibly no increase.
Now I understand. It was my mistake. Thx!
i got ac after reading this , i thinked for 2 hours how to find those pairs which will choose by ali and bahamin can not take more benefit from those pair , can you give me proof or something which help me to know sorting is enough like but i am not getting feel , please help me
It's simple, I'm not sure if I can give you some kind of mathematical proof but the idea is if I'm Alice, I just don't want to give Bob an advantage.
When does Bob get an advantage? When the min and max of the 4 numbers are far away from each other.
So you can be like in this case [5,1] [10, 100], 1 and 100 are far from each other (and Bob can rearrange this to get an advantage) but when I sort based on first array, they lie adjacently.
Okay lets extend the array now. So now rest of the values, assuming 100 is the largest in both the arrays; for first array new values we fill in should be greater than 10 (as it is sorted) but the corresponding value in the second array should be less than 100 based on our assumption.
So no matter how you fill in, one possible way is [5,1] [10, 100] [20, 40] [30, 80]. May be [5,1][10, 100] being adjacent is an advantage for Bob. But now Alice can choose [10,100][20,40] as 20 is lying between 10 and 100.
I just went with my intuition during the contest, maybe I was lucky. But if you take more cases and analyze, you might understand it better.
yes like for each test case result is same , but the thing is you can realise this during contest that sorting and then just checking adjacent will work like for div 2 c you will not be able to realise your self this works
If you think each pairing as a line segment, you will realize no matter if you considering starting points of line segment or ending points of line segment for sorting, the closest ones will appear next to each other in sorted order. This can be another way to look at it.
can you help me understand why is K completely ignored in all solutions i saw for C, i mean we are doing n-1 operations and if k<n-1 and all the operationa actually take place , isn't it a violation of the constraints
It is no where mentioned alice has to choose different i and j every time. So Alice will greedily keep choosing the same i and j.
ohkk , got this perfectly, now i have one more doubt,
suppose we have stored vtr as {Ai , Bi} sorted on Ai where Ai<Bi ,
Now for the index i and i+1 , we have four values Ai , Bi , Ai+1 , Bi+1, the current minimum contribution being cur = abs(Bi-Ai) + abs(Bi+1-Ai+1), Bahamin can simply sort the four values suppose as temp[0], temp[1], temp[2], temp[3], then the max he can get is newn = (temp[3]-temp[0]) + (temp[2]-temp[1]), the extra difference being newn — cur(if newn>cur), but the editorial says newn should be abs(Bi+1-Ai) + abs(Ai+1-Bi), my doubt is we know Ai<Ai+1 but its not necessary that Bi<Ai+1 and Bi+1<Ai ,
ideally sorting the 4 values and then taking the difference should make sense, but its WA on test2 , like getting 2 instead of 0.
having a similar doubt.
After first operation, alice can choose same elements for every remaining k, so bahamin will not be able to increase v
Thank you for the great problem and lightning fast editorial! But imo, B is a little hard for Div.2B
Excellent contest, problems are intreresting indeed
Thanks the authors for the quality of the contest! Great solutions for B and C!
Although I faced lots of difficulties, it really taught me something I didn't know. Thank you for the contest.
Problem C is very good and interesting but for me problem D much more easier than C.
what is "Stars and bars" in editorial of F?
https://en.wikipedia.org/wiki/Stars_and_bars_(combinatorics)
thanks!
Didn’t participate in the contest, but really enjoyed solving this problem later. The idea was elegant and the implementation was fun. Thanks to the author and testers
I learned a lot from problem F. I like the solution!
The solution of C provided is amazing. I have already made out case 1 and case 2 myself. How can we finally know using the intersection of intervals to figure out case 1 or case 2?
D is a very good problem
All of the problems were good. All of the solutions are verrry beautiful but unfortunately, H was accepted with an easy way. but in the end, it was a very, very good contest and thank you all.
in the first question unordered_set is better right since we don't need the order
In problem, the statement says,
In each day, the following events happen in order:
1. Mani selects an empty cell and builds a wall in that cell. Note that he can not build a wall in the cell which Hamid currently is at;
2. Hamid selects a direction (left or right)
Dosn't it mean Mani always starts first ?
The symmetry in F for determining the contributions of the subtracted elements is very nice! Unfortunately during the contest, I found the following on upper-bound integer sums, and the formula looked $$$O(n)$$$ so I thought there must've been a different thinking path. It also looked intimidating lol, but it turns out that figuring it out yourself isn't too difficult.
Can anyone help in Bonus of C?
Can someone explain the implementation part of E without the use of virtual trees? I have got the logic that
if node has value; --> cutie then skip --> else make all -1 in its subtree = this value;
if ith node has 0; --> cutie then skip --> else do nothing;
end -> make all 0 = root;
got a randomized solution for G2 with $$$n (\log n + 1)$$$ queries for large $$$n$$$($$$n \gt 14$$$), 333152719. Though for small $$$n$$$ I have no idea how to solve it quickly, some randomised approach gave me the same 8n, so this solution makes no more than 8n queries
in problem C I do not understand where the solution takes k(the number of rounds) into consideration. I understood the solution as assuming we have infinite number of rounds to reorder the arrays and add gains as we wish. can someone please explain?
No relation — actually it can be done in at most one operation.
For problem H, we found an algorithm with $$$O(2^5n)$$$ time complexity.
https://mirror.codeforces.com/contest/2127/submission/333483386
$$$O(n)$$$ solution in Chinese:https://www.luogu.com.cn/article/0fo23cva
Wow,amazing solution!
333522158,problem D,I don't know why it wa on text2 52nd
Regarding submission 332832455 — Problem C: Trip Shopping I recently received a plagiarism warning for my submission 332832455 in Problem 2127C.I did not intentionally share my code or copy from others. I would like to clarify the situation. I did not share my code with anyone, nor did I copy from any other participant. The similarity with another solution appears because: Standard Approach – This problem naturally leads to a “sort intervals + check overlap + find min gap” strategy. Common Variable Naming – My variable names (s, e, ivs) are short and generic, which is common in competitive programming due to time pressure. Many participants independently write similar-looking code in such situations. Independent Implementation – I implemented the solution entirely on my own during the contest without consulting any external sources or public IDEs. Limited Variation in Logic – The problem has a relatively straightforward optimal approach, which often results in structurally similar code even when written independently. I request that you please review my case, as the resemblance is coincidental and due to the nature of the problem and typical competitive programming practices.
In the editorial's solution for B, there seems to be a typo; it says:
when it should say:
which is correctly stated in the final solution:
can someone pls help with checking why this is tle,
problem E,
https://mirror.codeforces.com/contest/2127/submission/336913209
Problem D: Why does this solution get WA at test 2 ?? I used small to large merging on trees to store the distinct colors in subtrees of all nodes. My submission: 338256378