


First, if you haven't read this blog, do so.
Second, if you haven't immediately updated your HLD template to support subtree queries, do so.
The problem trivially reduces to finding the number of nodes with value $$$1$$$ that have no other node with value $$$1$$$ in their subtree. Further, an update on node $$$u$$$ clearly corresponds to xoring the values for all nodes in the subtree of $$$u$$$ with $$$1$$$.
Now, let's think of a slow solution for this problem. We define the following terms:
- A node $$$u$$$ is "good" if no other node in its subtree has the value $$$a_u$$$.
- $$$f_u(x)$$$ is the number of good nodes in the subtree of $$$u$$$, with value $$$x$$$.
- $$$c_{u}(x)$$$ is the number of nodes in the subtree of $$$u$$$, with value $$$x$$$.
Then the answer is clearly $$$f_{1}(1)$$$, and all values of $$$f$$$ and $$$c$$$ can be computed in $$$O(n)$$$ in the following manner:
dfs(u):
c[u][a[u]] = 1
for v in adj[u]:
dfs(v)
for x in [0, 1]:
f[u][x] += f[v][x]
c[u][x] += c[v][x]
#if u is a good node
if c[u][a[u]] == 1:
++ f[u][a[u]]
dfs(1)
How are $$$f$$$ and $$$c$$$ affected by a single update on node $$$u$$$? Let $$$g$$$ and $$$d$$$ be their new versions after the update.
- For every node $$$v$$$ in the subtree of $$$u$$$, we notice that $$$g_{v}(x) = f_{v}(x \oplus 1)$$$ and $$$d_{v}(x) = c_{v}(x \oplus 1)$$$ (in simple terms, we swap $$$f_{v}(0)$$$ and $$$f_{v}(1)$$$, and also swap $$$c_{v}(0)$$$ and $$$c_{v}(1)$$$).
- For every node $$$v$$$ that is an ancestor of $$$u$$$:
- The contribution of $$$u$$$ to $$$f_{v}(x)$$$ would have been $$$f_{u}(x)$$$ before the update, and will become $$$f_u(x \oplus 1)$$$ after the update, so we must add a delta of $$$f_u(x \oplus 1) - f_{u}(x)$$$ to $$$f_{v}(x)$$$ to account for this update.
- Similarly, we must add $$$c_u(x \oplus 1) - c_{u}(x)$$$ to $$$c_{v}(x)$$$ to account for this update.
Now, a less attentive reader might have overlooked a pesky little detail: It could be the case that xoring the subtree of $$$u$$$ with $$$1$$$ results in the status of some good nodes outside our subtree being toggled, and this isn't being captured by the updates described above.
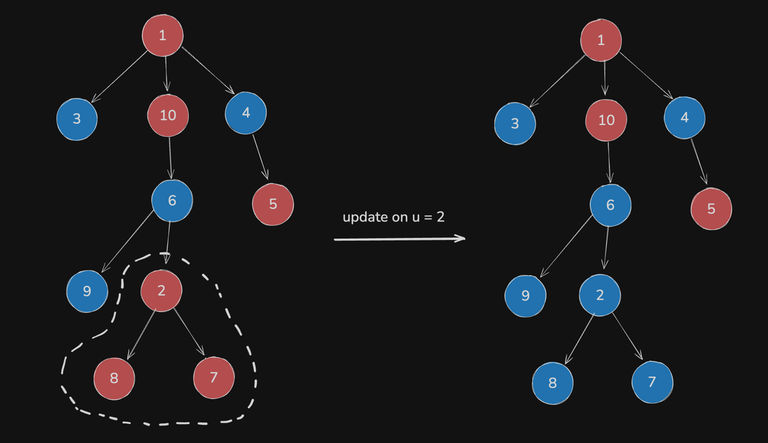
For instance, in the above image (where colors indicate values), node $$$10$$$ isn't "good" before the update, but does become so afterwards.
We make the following observations:
- Only the "goodness" of ancestors of $$$u$$$ can be affected by an update at $$$u$$$.
- Define $$$p_x$$$ to be the lowest (strict) ancestor of $$$u$$$ with value $$$x$$$ (it might not exist, and we just ignore this in that case). Then only the goodness status of $$$p_0$$$ and $$$p_1$$$ can be affected by this update.
- For any $$$p_x$$$:
- If $$$p_x$$$ was good before the update, then we can easily prove that it is not good after the update (since $$$u$$$ will have the same value as $$$p_x$$$). So we subtract $$$1$$$ from $$$f_v(x)$$$ for every ancestor $$$v$$$ of $$$p_x$$$ (including $$$p_x$$$).
- If it wasn't good before the update, then we simply check if $$$c_{p_x}(x) = 1$$$ after performing the earlier described update for $$$c$$$ (which doesn't depend on anything else), and if so, we add $$$1$$$ to $$$f_v(x)$$$ for every ancestor $$$v$$$ of $$$p_x$$$.
Now, reducing the updates/queries that this solution requires us to perform to a more general form, we want some data structure that can do the following on a static rooted tree:
- Update the subtree of a node (the swap updates).
- Update the path from the root to an arbitrary node (adding arbitrary deltas for $$$f$$$ and $$$c$$$).
- Finding the value(s) at a certain node.
- Finding the lowest node on the path from the root to an arbitrary node that satisfies some criterion (finding $$$p_x$$$).
Luckily, HLD can do all of these things in $$$O(\log{n})$$$ / $$$O(\log^2{n})$$$ when augmented with lazy segment trees.
Lazy propagation here might be slightly non-trivial for some readers, so I'll try to explain the operations in appropriate detail below.
In hindsight, it's a simple application of a simple technique, but cool DS problems like these definitely induce more happiness in me than most ad-hoc problems, so I hope we'll see more of them in the future, and orz to the author.






A much easier solution:
Let $$$v_1, v_2, \ldots, v_k$$$ be the positions of monsters, sorted by tin order. A vertex should be counted in the answer if and only if there exists no other monsters in it's subtree, i.e. $$$v_i$$$ counted if there does not exist $$$v_j, j \gt i$$$ such that $$$v_j$$$ lies in subtree of $$$v_i$$$ (due to tin order sorted). But we can actually go further, and say $$$v_i$$$ should be counted if and only if $$$v_{i + 1}$$$ is not in $$$v_i$$$'s subtree (proof left to the reader)
Thus, the answer is $$$k - \sum([$$$ is $$$v_i$$$ ancestor of $$$v_{i + 1}])$$$
Then, the updates are trivial with some segment tree storing first and last positions of $$$0$$$ and $$$1$$$, and the answer, (answer when flipped) in each node.
Finally, comments on your solution : As far as I have discussed, this is the worst solution to this problem, due to being particularly implementation heavy, and annoying to do in contest. Several people struggled because they tried to force this solution, I do not consider this a good solution.
I facepalmed so hard when I read the easier solution.
But I still like the one described in the blog because:
I don’t agree that it’s the worst one to implement — that honor being reserved for a cancerous square root decomposition (on the query sequence) I tried and failed to implement before this.