


I hope you all enjoyed the contest! Special thanks to
- djm03178 for suggesting the inclusion of C1, and for helping with test writing on all problems, especially F
- satyam343 for helping me solve H
- Dominater069 for providing the idea for one of the solutions to E
- Intellegent for providing one of the proofs for the solution to D, and for providing the idea for one of the solutions to F
A — Shizuku Hoshikawa and Farm Legs
If $$$n$$$ is odd, there are clearly zero possible configurations.
Suppose $$$n$$$ is even. Then consider the number of legs that belong to cows. This can be any multiple of $$$4$$$ that is less than or equal to $$$n$$$. The remaining legs will belong to chickens. Thus, the answer is equal to the number of nonnegative multiples of $$$4$$$ which are less than or equal to $$$n$$$, which is given by $$$\lfloor \frac{n}{4} \rfloor + 1$$$.
#include <bits/stdc++.h>
using namespace std;
void solve(){
int n;
cin >> n;
cout << (n & 1 ? 0 : n/4+1) << '\n';
}
int main(){
ios::sync_with_stdio(false);
cin.tie(NULL);
int t;
cin >> t;
while(t--) solve();
}
B — Yuu Koito and Minimum Absolute Sum
The given expression is equal to $$$|(a_2 - a_1) + (a_3 - a_2) + \dots + (a_n - a_{n-1})|$$$.
This simplifies to $$$|a_n - a_1|$$$.
We want to minimize the absolute difference between the first and last elements. To do so, if one of them is set and the other one isn't, we will set them to be equal. Now, the remaining blank elements do not affect the given expression, so we can set them all to be zero.
#include <bits/stdc++.h>
using namespace std;
void solve(){
int n;
cin >> n;
vector<int> a(n);
for(int i=0; i<n; i++)
cin >> a[i];
if(a[0] == -1)
a[0] = a[n-1];
if(a[n-1] == -1)
a[n-1] = a[0];
for(int i=0; i<n; i++)
if(a[i] == -1)
a[i] = 0;
cout << abs(a[n-1] - a[0]) << '\n';
for(int i=0; i<n; i++)
cout << a[i] << " \n"[i == n-1];
}
int main(){
ios::sync_with_stdio(false);
cin.tie(NULL);
int t;
cin >> t;
while(t--) solve();
}
C1/C2 — Renako Amaori and XOR Game
The $$$\mathrm{XOR}$$$ of all $$$2n$$$ elements is invariant. Note that this is also equal to the $$$\mathrm{XOR}$$$ between Ajisai and Mai's final scores. Therefore, if this value is zero, the game ends in a tie. Otherwise, Ajisai and Mai's final scores will differ, so the game does not end in a tie.
Suppose the $$$\mathrm{XOR}$$$ of all $$$2n$$$ elements is nonzero. If $$$a_i = b_i$$$, then the $$$i$$$-th turn is useless. Now, consider the largest $$$i$$$ such that $$$a_i \neq b_i$$$. This person can control whose score is $$$0$$$ and whose score is $$$1$$$. Since all future turns are useless, they win. Therefore, if the largest $$$i$$$ satisfying $$$a_i \neq b_i$$$ is odd, Ajisai wins. Otherwise, Mai wins.
#include <bits/stdc++.h>
using namespace std;
void solve(){
int n, x = 0, idx;
cin >> n;
vector<int> a(n), b(n);
for(int i=0; i<n; i++){
cin >> a[i];
x ^= a[i];
}
for(int i=0; i<n; i++){
cin >> b[i];
x ^= b[i];
}
if(!x){
cout << "Tie" << '\n';
return;
}
for(int i=0; i<n; i++)
if(a[i] ^ b[i])
idx = i;
cout << (idx & 1 ? "Mai" : "Ajisai") << '\n';
}
int main(){
ios::sync_with_stdio(false);
cin.tie(NULL);
int t;
cin >> t;
while(t--) solve();
}
The $$$\mathrm{XOR}$$$ of all $$$2n$$$ elements is equal to the $$$\mathrm{XOR}$$$ between Ajisai and Mai's final scores. Therefore, we know exactly what bits their scores will differ in.
The most significant of these bits dictates who wins the game. Therefore, we can apply the solution from the easy version to the most significant bit of the $$$\mathrm{XOR}$$$ of all $$$2n$$$ elements.
#include <bits/stdc++.h>
using namespace std;
void solve(){
int n, x = 0, bit, idx;
cin >> n;
vector<int> a(n), b(n);
for(int i=0; i<n; i++){
cin >> a[i];
x ^= a[i];
}
for(int i=0; i<n; i++){
cin >> b[i];
x ^= b[i];
}
if(!x){
cout << "Tie" << '\n';
return;
}
for(int i=0; i<20; i++)
if(x&1<<i)
bit = i;
for(int i=0; i<n; i++)
if((a[i]^b[i])&1<<bit)
idx = i;
cout << (idx & 1 ? "Mai" : "Ajisai") << '\n';
}
int main(){
ios::sync_with_stdio(false);
cin.tie(NULL);
int t;
cin >> t;
while(t--) solve();
}
Can you find the difference between the players' scores, where the winner tries to maximize this value and the loser tries to minimize this value? I don't have a solution, but I suspect this may be impossible in polynomial time. Leave a comment if you have either a solution or a proof that it's impossible.
D/F — Rae Taylor and Trees
Let $$$\mathrm{pre}_i$$$ denote the minimum of $$$p_1, \dots, p_i$$$, and let $$$\mathrm{suf}_i$$$ denote the maximum of $$$p_i, \dots, p_n$$$. Then if there exists some $$$i$$$ such that $$$\mathrm{pre}_{i-1} \gt \mathrm{suf}_i$$$, then the answer is $$$\texttt{No}$$$. This is because there is no edge from any value in $$$p_1, \dots, p_{i-1}$$$ to any value in $$$p_i, \dots, p_n$$$.
Otherwise, suppose that for every $$$i$$$, we have that $$$\mathrm{pre}_{i-1} \lt \mathrm{suf}_i$$$. Then for every $$$i$$$, we have that there exists a path from $$$p_{i-1}$$$ to $$$p_i$$$, by going from $$$p_{i-1}$$$ to $$$\mathrm{pre}_{i-1}$$$ to $$$\mathrm{suf}_i$$$ to $$$p_i$$$. Since the graph consisting of these paths is connected, it must have some spanning tree, so the answer is $$$\texttt{Yes}$$$.
#include <bits/stdc++.h>
using namespace std;
void solve(){
int n;
cin >> n;
vector<int> p(n+1), pre(n+1, n), suf(n+2);
for(int i=1; i<=n; i++){
cin >> p[i];
pre[i] = min(pre[i-1], p[i]);
}
for(int i=n; i>=1; i--)
suf[i] = max(suf[i+1], p[i]);
for(int i=2; i<=n; i++)
if(pre[i-1] > suf[i]){
cout << "No" << '\n';
return;
}
cout << "Yes" << '\n';
}
int main(){
ios::sync_with_stdio(false);
cin.tie(NULL);
int t;
cin >> t;
while(t--) solve();
}
Suppose that $$$\mathrm{pre}_{i-1} \lt \mathrm{suf}_i$$$ for all $$$i$$$. Let $$$s_1 \lt \dots \lt s_k = n$$$ denote the indices satisfying $$$p_i = \mathrm{suf}_i$$$, that is, the suffix maxes of $$$p$$$. Then let's partition $$$p$$$ into blocks ending at each $$$s_i$$$. Now, consider a block consisting of $$$p[l, r]$$$ for $$$l=s_{i-1}+1$$$ and $$$r=s_i$$$. We have that $$$\mathrm{suf}_l = \mathrm{suf}_r = p_r$$$ by construction, which means that all values in $$$p[l, r-1]$$$ are less than $$$p_r$$$. So we can connect all of these values to $$$p_r$$$.
Now, each block is connected, so it suffices to connect the blocks to each other. We have that $$$\mathrm{pre}_{l-1} \lt \mathrm{suf}_l = p_r$$$, so we can connect $$$p_r$$$ to $$$\mathrm{pre}_{l-1}$$$. By induction, we see that all blocks are now connected, since each block is connected to some previous block.
#include <bits/stdc++.h>
using namespace std;
void solve(){
int n;
cin >> n;
vector<int> p(n+1), pre(n+1, n);
vector<pair<int, int>> suf(n+2);
for(int i=1; i<=n; i++){
cin >> p[i];
pre[i] = min(pre[i-1], p[i]);
}
for(int i=n; i>=1; i--)
suf[i] = max(suf[i+1], {p[i], i});
for(int i=2; i<=n; i++)
if(pre[i-1] > suf[i].first){
cout << "No" << '\n';
return;
}
cout << "Yes" << '\n';
for(int l=1; l<=n;){
int r = suf[l].second;
for(int i=l; i<r; i++)
cout << p[i] << ' ' << p[r] << '\n';
if(l > 1)
cout << pre[l-1] << ' ' << p[r] << '\n';
l = r+1;
}
}
int main(){
ios::sync_with_stdio(false);
cin.tie(NULL);
int t;
cin >> t;
while(t--) solve();
}
Can you count the number of satisfactory trees? I don't have a solution to this version; leave a comment if you find one.
E — Anisphia Wynn Palettia and Good Permutations
Let $$$x$$$'s denote elements which all share a common divisor, and let $$$-$$$'s denote any elements. Then an array of the form $$$[-, x, x, -, x, x, \dots]$$$ will have no bad indices. Let's call an array of this form "perfect".
Suppose the $$$x$$$'s are even elements. We have roughly $$$\frac{n}{2}$$$ even elements, which means we can form a perfect array of length roughly $$$\frac{3n}{4}$$$. Now, we have roughly $$$\frac{n}{6}$$$ elements which are odd multiples of $$$3$$$, which means we can form a disjoint perfect array of length roughly $$$\frac{n}{4}$$$. By concatenating these two arrays, we achieve a roughly full permutation with $$$O(1)$$$ bad indices. See the next section for a proof of the bound on bad indices.
Instead of counting bad indices, we will count good indices. We form a perfect array of length $$$3\lfloor \frac{n}{4} \rfloor$$$, where all indices are good except for potentially the last one. We also form a perfect array of length $$$3\lfloor \frac{n+3}{12} \rfloor$$$ because we gain a new triple for every pair of $$$\{3, 9\} \pmod{12}$$$. Again, all indices are good except for potentially the last one. Therefore, we achieve $$$3\lfloor \frac{n}{4}\rfloor + 3\lfloor \frac{n+3}{12} \rfloor - 2$$$ good indices. It can be verified for every residue class $$$\bmod 12$$$ that this is lower bounded by $$$n-6$$$. Since there are $$$n-2$$$ indices in total, we have at most $$$4$$$ bad indices.
#include <bits/stdc++.h>
using namespace std;
void solve(){
int n;
cin >> n;
vector<vector<int>> a(3);
for(int i=1; i<=n; i++)
if(!(i % 2))
a[0].push_back(i);
else if(!(i % 3))
a[1].push_back(i);
else
a[2].push_back(i);
while(a[2].size() >= 1 && a[0].size() >= 2){
cout << a[2].back() << ' ';
a[2].pop_back();
cout << a[0].back() << ' ';
a[0].pop_back();
cout << a[0].back() << ' ';
a[0].pop_back();
}
while(a[2].size() >= 1 && a[1].size() >= 2){
cout << a[2].back() << ' ';
a[2].pop_back();
cout << a[1].back() << ' ';
a[1].pop_back();
cout << a[1].back() << ' ';
a[1].pop_back();
}
for(int i : a[0])
cout << i << ' ';
for(int i : a[1])
cout << i << ' ';
for(int i : a[2])
cout << i << ' ';
cout << '\n';
}
int main(){
ios::sync_with_stdio(false);
cin.tie(NULL);
int t;
cin >> t;
while(t--) solve();
}
Let $$$f(n)$$$ denote the minimum number of bad indices across all permutations of length $$$n$$$. Can you find the value of $$$\max f(n)$$$? I suspect the answer is $$$2$$$, but I don't have a formal proof. Furthermore, can you find $$$f(n)$$$ for all $$$n$$$?
Update: I've heard from several people that $$$\max f(n) = 1$$$. Feel free to post a comment with a proof, if you'd like.
Update:
A construction commented by d1amondzz seems to prove an upper bound of $$$f(3), f(5) \leq 1$$$ and $$$f(n) = 0$$$ for $$$n\neq 3, 5$$$. I think several other comments may have alluded to a similar solution as well. The general idea is that for the largest prefix of primes $$$p_1, ..., p_k$$$ satisfying $$$p_{k-1}\cdot p_k \leq n$$$, we can construct an array $$$q$$$ as follows: for each $$$p_i$$$, first append $$$p_i$$$ to $$$q$$$, then append all elements with smallest prime factor $$$p_i$$$, ending with $$$p_i\cdot p_{i+1}$$$. Then all adjacent elements are not coprime, so as long as this array is of size at least roughly $$$\frac{2}{3}n$$$, we can intersperse it with the remaining elements to achieve no bad indices. All composites are included in $$$q$$$, because if a composite number has smallest prime factor at least $$$p_{k+1}$$$, then its value is at least $$$(p_{k+1})^2 \gt p_k\cdot p_{k+1} \gt n$$$ by construction of $$$k$$$. So we have that $$$q$$$ is of length asympototically at least $$$n-\frac{n}{\log n}$$$, which is asymptotically at least $$$cn$$$ for any $$$c \lt 1$$$. We can furthermore verify that this construction works for all small $$$n$$$ except for $$$3$$$ and $$$5$$$.
As for the lower bound, it's easy to see that $$$f(3) \geq 1$$$ since all pairs are coprime, and that $$$f(5) \geq 1$$$ since the only pair that is not coprime is $$$\{2, 4\}$$$, but we cannot have that these elements appear in all triples. Therefore, we have that $$$f(3) = f(5) = 1$$$ and $$$f(n) = 0$$$ for $$$n\neq 3, 5$$$.
G — Sakura Adachi and Optimal Sequences
Let's fix the number of double operations we use; call this integer $$$k$$$. Now, we can treat each value independently.
Consider a specific pair $$$a_i, b_i$$$. If we don't apply any addition operations, we have that $$$a_i$$$ becomes $$$a_i \cdot 2^k$$$. Clearly we need that $$$a_i \cdot 2^k \leq b_i$$$. Now, observe that applying an addition operation before applying $$$j$$$ of the $$$k$$$ double operations is equivalent to adding $$$2^j$$$ to our final sum. We need to add $$$b_i - a_i \cdot 2^k$$$, so in total, we apply $$$\lfloor \frac{b_i - a_i \cdot 2^k}{2^k} \rfloor = \lfloor \frac{b_i}{2^k} \rfloor - a_i$$$ addition operations at the beginning, each adding $$$2^k$$$ to our sum. Then, we apply $$$\texttt{popcount}((b_i - a_i \cdot 2^k)\pmod{2^k}) = \texttt{popcount}(b_i\pmod{2^k})$$$ addition operations later, where $$$\texttt{popcount}(x)$$$ denotes the number of set bits in $$$x$$$. This is because, if the $$$j$$$-th bit of $$$b_i - a_i \cdot 2^k$$$ is set for some $$$j \lt k$$$, we would like to apply an operation before applying $$$j$$$ of the double operations so we can add $$$2^j$$$ to our sum.
We would like to choose the largest number of double operations possible, since a double operation increases all values by at least one. Furthermore, since $$$n\geq 2$$$, a double operation is strictly more effective than an addition operation. However, we still need to satisfy $$$a_i \cdot 2^k \leq b_i$$$ for all $$$i$$$. Therefore, we will choose $$$k=\min \log_2{\frac{b_i}{a_i}}$$$.
Between each double operation, the addition operations can be rearranged. Let's consider all of the addition operations applied before applying exactly $$$j$$$ double operations; denote these values $$$c_1, \dots, c_n$$$, where $$$c_i$$$ is the number of addition operations performed on element $$$a_i$$$. Then we can multiply our number of sequences by $$${\sum c_i \choose c_1, \dots, c_n}$$$, the multinomial coefficient of $$$c_i$$$. This is equal to $$$\frac{(\sum c_i)!}{\prod (c_i!)}$$$. To simplify implementation, note that for $$$j \lt k$$$, all $$$c_i$$$ are either $$$0$$$ or $$$1$$$, so the denominator is only nontrivial for $$$j=k$$$. The final answer is the product of these values across all $$$0\leq j\leq k$$$. See the next section for intuition on multinomial coefficients and some of the details on its implementation.
The intuition behind the formula for multinomial coefficients is as follows: let's say $$$n=3$$$, and we want to find the number of ways to color $$$\sum c_i$$$ balls such that $$$c_1$$$ are red, $$$c_2$$$ are green, and $$$c_3$$$ are blue. Let's call our positions "red $$$1$$$" $$$\dots$$$ "red $$$c_1$$$" $$$\dots$$$ "blue $$$c_3$$$". Now, it's clear that there are $$$(\sum c_i)!$$$ ways to assign each ball to a position, because we have $$$\sum c_i$$$ choices of balls to assign to "red $$$1$$$", then $$$\sum c_i - 1$$$ remaining choices of balls to assign to "red $$$2$$$", and so forth, until we only have one choice of balls to assign to "blue $$$c_3$$$". However, this overcounts, because there is no difference between assigning ball $$$1$$$ to "red $$$1$$$" and ball $$$2$$$ to "red $$$2$$$", and vice versa. We are overcounting the red assignments by a factor of $$$c_1!$$$, because every valid selection of red balls achieves $$$c_1!$$$ assignments of red balls to positions. Similar reasoning holds for the green and blue balls, so in total, we have $$$\frac{(\sum c_i)!}{\prod (c_i!)}$$$ different sequences.
Multinomial coefficients can be computed by precomputing factorials. For the numerator, note that if $$$\sum c_i \geq 10^6+3$$$ then $$$(\sum c_i)! \equiv 0\pmod{10^6+3}$$$ because we have a factor of $$$10^6+3$$$, so we only need to precompute factorials up to $$$10^6+2$$$. For the denominator, we can divide by $$$c_i!$$$ by multiplying by the modular inverse of $$$c_i!$$$ modulo $$$10^6+3$$$. Crucially, note that $$$c_i \lt 10^6+3$$$ because the number of addition operations you can apply is at most $$$b_i - a_i \lt 10^6$$$, so modular inverses are well-defined.
#include <bits/stdc++.h>
#define int long long
using namespace std;
int mod = 1e6+3;
vector<int> fact(mod);
int inv(int a){
return a <= 1 ? a : mod - mod / a * inv(mod % a) % mod;
}
void solve(){
int n, x, ans = 1;
cin >> n;
vector<int> a(n), b(n);
for(int i=0; i<n; i++)
cin >> a[i];
for(int i=0; i<n; i++)
cin >> b[i];
int k = __lg(b[0] / a[0]);
for(int i=1; i<n; i++)
k = min(k, __lg(b[i] / a[i]));
x = k;
vector<int> cnt(k), c(n);
for(int i=0; i<n; i++){
for(int j=0; j<k; j++){
cnt[j] += b[i] & 1;
b[i] >>= 1;
}
c[i] = b[i] - a[i];
}
for(int j=0; j<k; j++){
x += cnt[j];
ans = ans * fact[cnt[j]] % mod;
}
int last = accumulate(c.begin(), c.end(), 0LL);
ans = (last < mod ? ans * fact[last] % mod : 0);
for(int i : c){
x += i;
ans = ans * inv(fact[i]) % mod;
}
cout << x << ' ' << ans << '\n';
}
signed main(){
ios::sync_with_stdio(false);
cin.tie(NULL);
fact[0] = 1;
for(int i=1; i<mod; i++) fact[i] = fact[i-1] * i % mod;
int t;
cin >> t;
while(t--) solve();
}
H — Shiori Miyagi and Maximum Array Score
Let's first try to solve this problem with inefficient time and memory, then we will later optimize it. For $$$1\leq i\leq n$$$ and $$$0\leq j\leq m-n$$$, let $$$\mathrm{dp}[i][j]$$$ denote the largest score achievable from the first $$$i$$$ indices, while also satisfying $$$a_i = i+j$$$. Now, since $$$a$$$ must be strictly increasing, we equivalently have that $$$a_i - i$$$ is monotonically increasing. Therefore, we can transition as follows: $$$\mathrm{dp}[i][j] = \max_{k\leq j} \mathrm{dp}[i-1][k] + v(i, i+j)$$$, because we may choose $$$a_{i-1}$$$ to be any value satisfying $$$a_{i-1} - (i-1) \leq j$$$, then we choose $$$a_i = i+j$$$, adding a score of $$$v(i, i+j)$$$.
Now, we will try to remove the first dimension; that is, $$$\mathrm{dp}[j]$$$ denotes the largest score achievable while also satisfying $$$a_i = i+j$$$, where we will update this array as we iterate through all $$$i$$$. We will store this in a data structure that supports quickly querying prefix maximums and increasing point values; in particular, either a Fenwick tree or a segment tree will work.
Suppose we are at some stage $$$i$$$ and would like to update $$$\mathrm{dp}[j]$$$. As before, we want to update it to $$$\max_{k\leq j} \mathrm{dp}[k] + v(i, i+j)$$$. We should process $$$j$$$ in reverse order, as we want to ensure that we are accessing $$$\mathrm{dp}[i-1][k]$$$ instead of $$$\mathrm{dp}[i][k]$$$.
However, we only have to update $$$\mathrm{dp}[j]$$$ if $$$v(i, i+j)$$$ is nonzero. This is because, if $$$v(i, i+j)$$$ is zero, then we are updating $$$\mathrm{dp}[j]$$$ to $$$\max_{k\leq j} \mathrm{dp}[k]$$$. However, since we are only querying prefix maximums, any query involving $$$j$$$ will implicitly query all $$$k\leq j$$$ anyways, so it is not necessary to explicitly update $$$\mathrm{dp}[j]$$$. Our final answer is $$$\max \mathrm{dp}[j]$$$. See the next section for runtime analysis.
For simplicity of analysis, assume $$$m - n \geq c$$$ for some reasonable $$$c$$$, to avoid pathological cases where $$$\log (m-n)$$$ is undefined or zero.
For each $$$i$$$, we are updating $$$O(\frac{m-n}{i})$$$ values. Therefore, in total, we have $$$O(\sum \frac{m-n}{i}) = O((m-n)H(n))$$$ updates. Since harmonic numbers are known to grow logarithmically, this is $$$O((m-n)\log n)$$$. Each update takes $$$O(\log (m-n))$$$ time, as it involves a query and an update on a Fenwick tree or segment tree of size $$$m-n+1$$$. So the updates in total take $$$O((m-n)\log n\log{(m-n)})$$$ time.
However, we also need to compute $$$v(i, i+j)$$$ for each update. This will take $$$O(\sum v(i, i+j))$$$ time. For a fixed $$$i$$$, we have that $$$O(\frac{m-n}{i})$$$ values satisfy $$$v(i, i+j) \geq 1$$$, $$$O(\frac{m-n}{i^2})$$$ values satisfy $$$v(i, i+j) \geq 2$$$, and so forth. Therefore, for a fixed $$$i$$$, we have that $$$\sum v(i, i+j) = O(\sum \frac{m-n}{i^k}) = O(\frac{m-n}{i}\sum \frac{1}{i^{k-1}}) = O(\frac{m-n}{i} \cdot \frac{1}{1-\frac{1}{i}}) = O(\frac{m-n}{i} \cdot \frac{i}{i-1}) = O((m-n) \cdot \frac{1}{i-1})$$$. Across all $$$i\geq 2$$$, we have $$$O((m-n)H(n-1)) = O((m-n)\log n)$$$. This is dominated by the $$$O((m-n)\log n\log{(m-n)})$$$ term from the updates.
Finally, we have an additional $$$n$$$ term, as we have to iterate through all $$$i\leq n$$$. Our total runtime is $$$O((m-n)\log n\log{(m-n)} + n)$$$.
#include <bits/stdc++.h>
using namespace std;
void solve(){
int n, m;
cin >> n >> m;
vector<int> mx(m-n+1);
function<int(int)> query = [&](int i)->int{
int ret = 0;
for(; i>=0; i=(i&i+1)-1)
ret = max(ret, mx[i]);
return ret;
};
function<void(int, int)> update = [&](int i, int val){
for(; i<=m-n; i|=i+1)
mx[i] = max(mx[i], val);
};
function<int(int, int)> v = [](int b, int x)->int{
int ans = 0;
while(!(x % b)){
ans++;
x /= b;
}
return ans;
};
for(int i=2; i<=n; i++)
for(int j=(m-n+i)/i*i; j>=i; j-=i)
update(j-i, query(j-i) + v(i, j));
cout << query(m-n) << '\n';
}
int main(){
ios::sync_with_stdio(false);
cin.tie(NULL);
int t;
cin >> t;
while(t--) solve();
}






Very fast editorial :)
editorial at the speed of light!
At the speed of light~ Here, we can stand on our feet~ You go after my lead~ (Why do you keep waiting?)~
Fast editorial.Thanks!)
Super fast tutorial!
No hacking phase?
Nice, that was so fast :v
A very beautiful use of prefix and suffix list in D and F
Can't wait for ratings to roll out!!
Thanks a lot to reirugan and the testers for the amazing contest
For bonus E, i think f(n)=1,code — 349964120,although i didn't prove this.
mine has 0 :) for N>11
can you explain your approach ?
Make segments sharing their spf , like for N=11 2 4 6 8 10 , 3 9 , 5 , 7 , 11 , 1
we want to insert these (single primes , here 5 ,7 , 11) in the array at distance 2 , as we know that the number of these single primes is always less than N/2 (or N/log(N)) ,
it becomes 5 2 4 7 6 8 11 10 3 9 1(push 1 at last ) , hope I was able to explain it :)
It's 1 even for n=21,please check base cases atleast.
I am sorry , the upper bound is always 1
In your code, you shouldn't push primes between always at distance 2,if count of some spf1 is odd, you get {prime,spf1,spf2} which can be bad if last two values have gcd 1.Also,no need to say sorry,make mistakes and learn :)
but it occurs only once ?
For n=23,your code has 2 bad indices,you can make further tetcases to check upper bound on your solution.
I think mine is f(n)=0 except for n=3 and n=5. And it's very simple 350681384
E is an interesting problem.
can anyone explain step 2 of Prblem C1 is there any proof for that..?
The last i that ai differs bi is gonna be the last step that matters, so whoever gets this step can decide their own number of 1 to be odd or even therefore wins the game.
thanx
Are you referring to this line?
Basically, the idea is that, since the XOR of all elements is $$$1$$$, we must have that one of their scores is $$$0$$$, and the other's is $$$1$$$. Now, since $$$a_i \neq b_i$$$, if you swap $$$a_i$$$ and $$$b_i$$$, you also swap their scores. So the player to move can choose whether or not to swap their scores.
understood Thanks reirugan i was trying to solve using the fact that if ajisai has to win then he should have odd no. of 1s and same for Mai and considering no. of ones till prefix i for each turn.. but was getting wa on some samples..
It's a game theory concept. Could you specify in what statement you are facing the confusion?
Suppose that the game is not a tied game. Then, at the largest i s.t. a_i and b_i are different, there is only 2 cases from the POV of the player making the choice at this point in time. Let's call this player Alice.
Case 1: Alice is winning, then Alice will pass and stay winning.
Case 2: Alice is losing. Alice will swap, and this results in a winning position.
Regardless of the prior actions taken at any point before i, it will always result in either of the two cases.
what about tie case, he could swap and win, does this case considered here?
See step 1
yes actually if you see carefully the person having last place where there is difference always can control forming 0 and 1 , so either that will result in tie or his win
Easy contest expected it to be a little harder.
You only solved 5, how is it easy?
for pupil, solving 5 in div 3 is kinda good.
Yes, but that doesn't mean the contest is easy
See, the thing is that I don't feel I should be able to solve this many problems, and one more thing, I was able to solve F too, but I needed to have dinner, so I have to leave it, so I felt the contest was pretty easy compared to other div3 contests
And one more thing, you can compare the no. of wrong submissions and the timing of submission, and get to know how your performance was and how mine was.
It's not how many problems you've solved, it's more about the ratio.
There were still 3 problems that you didn't solve(if we count F) so you can't really say it's easy. Most of the time there are 2-3 problems left in Div. 3's(dependent).
So, as I said, it wasn't necessarily easy and I'm not calling you bad.
My wrong submissions were merely dumb mistakes born from the stress of this contest as this could be the contest that makes me Expert.
You are going to be an expert bro, my extension (Carrot) says that (congrats in advance), and I was also talking about the competitive difficulty
Thanks a lot!
But I do think the competitive difficulty is the same for everyone, so unless you can solve all the problems, the rating won't change much(depends on the topics, as some are less popular)
See, you are an expert now :)
:D
Carrot said I was also going to be expert but I didn't :(
I think only +-5 deviation happens from its prediction. I prefer that
lol my deviation was more than that it predicted +267 actual was +234
bro, I think you are new here. Codeforces does not increase your rating drastically; you should have gotten this much increment, but Codeforces didn't give you that. In the next contest, you will get it.
At least harder than Round 1071
I'm late for this contest QQ
Kinda surprised the number of solve in E (including cheaters) is under 1000. Thought chatGPT would be able to solve it easily
Yuri is good :) I support Ajisai so I think the solution of C1/C2 is printing "Ajisai" for all tests.()
Out of people I've asked:
Team Ajisai: me, fast-fourier-transfem
Team Mai: Friedrich, kevlu8
Team Renako (???): djm03178
reirugan Really good contest bro, enjoyed the problems. Waiting for your next contest.
E another solution:
set p_i+1's mod 12 to {1, 6, 2, 5, 4, 8, 7, 10, 12, 11, 3, 9}'s i (mod 12) element.
https://mirror.codeforces.com/contest/2171/submission/349954650
Why couldn't D1 be solved with DSU? Or I'm just bad in implementation...
349949664
There are some working solutions for both D and F that use DSU.
Yeah, I solved it using DSU. 349897669
Dude...chill
There was REALLY no need for DSU, and it's just overkill
overkill = OK
i used dsu+segtree XD in live. IDK i was bricking every contest.link
Respect
using dsu + divide and conquer also is a solution 352768735
In problem G, can someone explain why are we multiplying cnt[i]! to ans ?
Maybe it would have been more clear if I had used the variable
jinstead ofi. I've updated the code to use this variable naming, to match the editorial.Basically
cnt[j]denotes the number of indices such that you need an addition operation before $$$j$$$ double operations. These can be permuted in any way, so you want to multiply byfact[cnt[j]].For bonus C, I think we need to find the players who has the ability to set the final value on each bit. Then, once we get the msb (winner) we can set the diff for each bit (winner->1, loser->0). But, I am not sure. If anyone has a good answer, please comment it.
One of the worst div3 contests ever.
For bonus E, max f(n) is actually 1. The proof is a bit long though.
do you have proof, if yes can you post it here
I can generate (non-constructive, something similar to simulated annealing) sequence for $$$n=10^7$$$ with $$$f(n) = 0$$$. Provide me your proof please.
PS: If you want to generate this sequence so that you can verify it, use
solve_range(1, n, 0);from 353828654.UPD: nevermind, I forgot small cases $$$n=3,n=5$$$.
Construction of a Permutation with At Most 1 Bad Index
Small Cases (n < 6):
n=3: [1, 2, 3] (1 bad index)
n=4: [1, 2, 4, 3] (0 bad indices)
n=5: [1, 2, 4, 3, 5] (1 bad index)
General Case (n ≥ 6):
Let n = 6q + r with q ≥ 1 and 0 ≤ r ≤ 5.
Core Blocks (covering 1 to 6q):
Divide into q blocks of 6: k-th block (k=0 to q-1) is 6k+1 to 6k+6.
Order each as: 6k+2, 6k+1, 6k+4, 6k+6, 6k+5, 6k+3.
Reverse every odd-indexed block (k odd, 0-based).
Concatenate blocks.
Why 0 bad indices in core:
Within blocks: Every triplet has a pair with gcd > 1.
Even k blocks start with multiple of 2, end with multiple of 3.
Odd k (reversed) start with multiple of 3, end with multiple of 2.
Junctions are thus 3-to-3 (gcd ≥ 3) or 2-to-2 (gcd ≥ 2).
Core starts with 2.
Remainder r (numbers 6q+1 to n):
r=0: Use core (0 bad)
r=1: Append 6q+1 → at most 1 bad at junction (1 bad)
r=2: Prepend 6q+1, 6q+2 → pattern 6q+1 (odd), 6q+2 (even), 2 (even). Even-even junction (0 bad)
r=3: Prepend as r=2 (0 bad). Place 6q+3 (multiple of 3):
If q odd: core ends with multiple of 3 → append (gcd ≥ 3)
If q even (q ≥ 2): first two blocks end with ...3 then 9... → insert 6q+3 between them (gcd ≥ 3 pairs)
r=4: Prepend 6q+1, 6q+4, 6q+2 → pattern 6q+1 (odd), 6q+4 (even), 6q+2 (even), 2 (even) and place 6q+3 as above (0 bad)
r=5: As r=4 for first four (0 bad), and append 6q+5 → at most 1 bad at junction (1 bad)
This yields a permutation with at most 1 bad index for any n.
I guess it is possible to modify your construction to make $$$f(n) = 0$$$ for $$$n \ge 100$$$ (and cases for $$$6 \le n \lt 100$$$ by bruteforce). Replacing cases for $$$r = 1, 5$$$ we can replace the initial $$$5$$$ in the first block with $$$6q + r$$$, and now we have a multiple of five, so we can place it near $$$25 = 6 \cdot 4 + 1$$$, and in this block we were covering $$$25$$$ by its neighbors, so it should not break anything.
Can someone explain me why my Dsu solution gives WA in problem D? Submission:349981598
My $$$O(M\sqrt{M}log(M))$$$ solution passed for H.
For indices in range $$$[1, 2, ..., \sqrt(M)]$$$, I computed $$$dp[i][j]$$$ as the max score possible on assigning values to $$$A[1], A[2], \dots A[i]$$$ from the values $$$1, 2, \dots j$$$. Basic dp with no data structure optimization
For indices $$$i$$$ s.t. $$$i$$$ > $$$\sqrt(M)$$$, $$$val(i, A[i])$$$ will be atmost 1. Compute $$$dp2[i][j]$$$ as the the maximum possible score possible on assigning values to $$$A[i], A[i+1], \dots, A[n]$$$ from the values $$$j, j+1, \dots, M$$$. For this, the maximum possible score can be $$$N - \sqrt(M)$$$ (since each index contributes atmost 1), then I maintained the minimum $$$j$$$ needed to obtain a given score as I iterated through $$$i$$$ from $$$N$$$ downto $$$\sqrt(M) + 1$$$. (kind of what we do for longest increasing subsequence)
It is trivial to merge these to obtain the final answer.
Define DP[i][j] as in the editorial makes everything much easier. I struggled with the definition that DP[i][j] is the answer at position i with value j.
Is there problems solvable with similar tricks?
Problem D/F can be easily solved using stack 349987767
I solved D/F using scanline + dfs on segments + binary search: 349972666. I saw someone call the DSU overkill. I wonder what he thinks about my solution...
An alternative $$$O(m \sqrt{m})$$$ solution on Problem H, which might be more beginner-friendly and easier to understand and implement (hopefully):
Similar to the official solution, let $$$\text{dp}[i][j]$$$ be the maximum score achievable from the first $$$i$$$ indices with $$$a_i = j$$$. Meanwhile, let $$$\text{dp2}[i][j]$$$ be the maximum score achievable from the first $$$i$$$ indices with $$$a_i \leq j$$$.
The transition can then be derived as:
This yields to an $$$O(nm)$$$ solution. As a remark, the first dimension can be optimized with rolling DP to reduce space complexity.
The following explains how we can enhance this to the $$$O(m \sqrt{m})$$$ solution we want.
Consider $$$K = 450 \approx \sqrt{2 \cdot 10^5}$$$ and $$$K^2 \gt 2 \cdot 10^5$$$.
Case 1. $$$n \leq K$$$
We can directly solve it with the aforementioned idea, which takes $$$O(Km) = O(m \sqrt{m})$$$ time.
Case 2. $$$n \gt K$$$
Note that $$$v(i, a_i)$$$ can only contribute at most $$$1$$$ for $$$i \gt K$$$ to the answer. Also, if an index $$$i \gt K$$$ does contribute to the answer, then $$$a_i = c \cdot i$$$ for some constant $$$c \lt K$$$. In this case, any index $$$j \gt i$$$ can contribute to the answer as well by taking $$$a_j = c \cdot j$$$.
With this observation, we can iterate over that $$$c$$$. On a fixed $$$c$$$, we are taking the sequences satisfying all the following conditions into account:
To calculate the contribution resulted from indices $$$i \leq K$$$, we can pre-compute $$$\text{dp2}[K][j]$$$ for $$$j = 1, 2, \ldots, K^2$$$ which takes $$$O(K^3)$$$ time. The required value is $$$\text{dp2}[K][c \cdot K]$$$. This is done globally before running any test case.
As for the contribution resulted from indices $$$i \gt K$$$, the largest $$$(a_i \leftarrow c \cdot i)$$$-assignable index is $$$f(c) = \left\lfloor\dfrac{m - n}{c - 1}\right\rfloor$$$ for $$$c \gt 1$$$ by solving $$$c \cdot i + (n - i) \leq m$$$ we just mentioned. You may set $$$f(1) = \infty$$$ in your implementation.
Therefore, the answer is $$$\displaystyle \max_{c} \left( \text{dp2}[K][c \cdot K] + \min(f(c), n) - K \right)$$$ for all valid $$$c$$$'s such that $$$c \cdot K + (n - K) \leq m$$$. Since $$$c \lt K$$$, this only takes $$$O(K)$$$ time.
349990689
i think you can just precompute $$$dp[i][j]$$$ for all the desired $$$i$$$ and $$$j$$$ in $$$O(m \sqrt m)$$$ and just use short int as data type to pass memory limit, and answer $$$n \lt K$$$ case in $$$O(1)$$$.
... or do it offline in $$$O(1)$$$ per query
This solution relies on the claim that an optimal tail ($$$i \gt K$$$) structure is a single contiguous block: $$$a_{K+1}=c(K+1), \cdots, a_{K+f(c)}= c(K+f(c))$$$, but I'm failing to see why this is true.
Thanks in advance.
When I first tried to see why, I thought about extending the useful interval (the interval from $$$a_{K+1}$$$ to $$$a_n$$$) in useless ways (e.g. the above). Those kinds of extensions don't contribute to the answer, hence it's optimal to make it in a contigous block.
Could you explain WHY they don't contribute to the answer?
any index j>i can contribute to the answer as well by taking aj=c⋅j .can you explain why this is always optimal? Like, what if we take $$$a_j = c' \cdot j$$$ and that gives a better answer?
Did not get C2, what if the number having highest set bit is present on both odd and even indices ? then how will you proceed
Once you consider the most significant bit, you can follow the solution to C1. In particular, you only need to consider the largest $$$i$$$ such that the highest set bit of the XOR differs in value between $$$a_i$$$ and $$$b_i$$$.
For problem D, I took advantage of the fact that if, for any given $$$1\le k\le n - 1$$$, the last $$$k$$$ elements of our permutation $$$p$$$ contains all integers from $$$1$$$ to $$$k$$$, then the answer is $$$\text{No}$$$.
Fairly easy to see why this is a necessary condition, but I couldn’t prove why it’s also sufficient. Can anyone help?
Code: 349979576
Your condition is actually the same as the one in the editorial, just put in a different way.
Indeed, if the last $$$k$$$ elements are the integers from $$$1$$$ to $$$k$$$, then
pre[n-k] = k+1andsuf[n-k+1] = k. Conversely, ifpre[n-k] > suf[n-k+1], then we must have that the last $$$k$$$ elements are the integers from $$$1$$$ to $$$k$$$.Now, you can simply use the proof in the editorial.
Thanks!
wasted so much time in question D. I couldn't able to find the intuition for that. BTW the solution is really beautiful.
Some experiences as a tester:
Thanks a lot for all of your hard work! Especially with tests — as a relatively inexperienced setter, your help was very appreciated.
349997416 Can this solution Time limit exceed. I have done this in O(n^2). It got accepted. Can you have a look into it?
Codeforces Round 1065 (Div. 3) in problem 2171H - Shiori Miyagi and Maximum Array Score
in 4th test case
3 500maximal array would be
[_,128,243]and k will be
[_,7,5]so 7+5 = 12 but why it is 13 and similarly in
3rd test case
6 216maximal array would be
[_,16,27,64,125,216]and k will be
[_,4,3,3,3,3]so 4+3+3+3+3 = 16
but it is given 19 how?
[, 256, 486] -> [, 8, 5]. they don't have to be necessarily exact powers. They have to be only divisible.
thanks. was my first contest
[_, 256, 486]gives[_, 8, 5][_, 128, 162, 192, 200, 216]gives[_, 7, 4, 3, 2, 3]Why was the contest not rated?
It will be rated after hacking phase is over.
I was playing with an alternative constructive idea for problem E from this round:
https://mirror.codeforces.com/contest/2171/problem/E
The idea is to first build a single block of length $$$30$$$ on the interval $$$[1, 30]$$$ such that:
I managed to find such a permutation of $$${1, 2, \dots, 30}$$$:
Because this block only uses gcds $$$2$$$, $$$3$$$, and $$$5$$$ between neighbors, you can shift it by $$$+30$$$, $$$+60$$$, $$$+90$$$, etc., and reuse the same structure on the intervals $$$[31, 60]$$$, $$$[61, 90]$$$, and so on.
In other words, you can tile the solution with blocks of size $$$30$$$.
This is good enough for the solution because with list that don't include larger numbers you get an error of at most 1 the reason being you are missing a connector between the gcds like 6 or 15. So that is the code I submitted. You could also build shorter array to have no error on the shorter final block here are the ones I built.
1: {1}
2: {1, 2}
3: {1, 30, 2, 3} 30 from the previous list
4: {1, 2, 4, 3}
5: {1, 25, 30, 3, 2, 4, 5}
6: {1, 2, 4, 5, 6, 3}
7: {1, 2, 4, 5, 6, 3, 7}
8: {1, 2, 4, 5, 8, 6, 7, 3}
9: {1, 2, 4, 5, 8, 6, 7, 3, 9}
10: {1, 2, 4, 5, 8, 6, 7, 3, 9, 10}
11: {1, 2, 4, 5, 8, 10, 7, 6, 3, 11, 9}
12: {1, 2, 4, 5, 8, 10, 7, 12, 6, 11, 3, 9}
13: {1, 2, 4, 5, 8, 10, 7, 12, 6, 11, 3, 9, 13}
14: {1, 2, 4, 5, 8, 10, 7, 12, 14, 11, 6, 3, 13, 9}
With this now the only solution that have a bad index are 3, and 5 that I are impossible to fix.
I did similar but with 2 blocks of length 6. 349964351
Just concatenate these two blocks alternatively (adding 6 * i) and you are all set.
I tried that same solution but couldn't find the blocks thanks for the comment
I solved E with $$$max\ f(n) = 1$$$. The idea was to print a "base" number immediately followed by its multiples which have this number as their lowest divisor (except 1) sorted in reversed order. All numbers up to $$$\frac{n}{2}$$$ are printed this way, but there are primes in $$$[\frac{n}{2}, n]$$$. So, if at any point we've got a "base" number to print (i.e. we haven't printed it before) and some multiples of it which we also haven't printed before, we print a prime after the first multiple and then after each two non-final multiples: "base" — multiple — prime — multiple — multiple — prime — multiple. Similarly, if the "base" number has already been printed before but there are some multiples to go, we print a prime after each two non-final multiples: multiple — multiple — prime — multiple. It happens to be that for every $$$n$$$, except a few small ones, all primes in $$$[\frac{n}{2}, n]$$$ get printed in between the multiples this way. Submission: https://mirror.codeforces.com/contest/2171/submission/349988810
I thought of an easier solution to D/F.
The idea came from looking at the brute-force approach. Naively, you would try to add an edge from each position (i) to every position (j > i) such that the value at (j) is greater than the value at (i). That clearly creates way too many edges.
However, for a tree you don’t need to connect every valid pair — you only need enough edges to connect the components. So instead, you can process the array from right to left and use a monotonic stack.
The point is: when you connect elements, you only need to remember the greatest value in each connected component. That “maximum” acts as the representative of the component and will handle all future connections. This is because the maximum will give you the most options to connect with future numbers. The monotonic stack naturally keeps track of these representatives and tells you which components to merge as you move to the right.
It is an amortized version of the brute force because you can connect with all the greater elements in the monotonic stack and leave the greatest element in the component.<spoiler
Pretty Inspiring! I have implemented the same, have a look. Submission
It was weird its basically my code Submission
Yes it is, well I have read your solution and submission, and then try to implement it myself. It's a way of saying it's a really good solution. Thanks!
E is too hardddddddddd
My idea to solve E is to construct a array in that format:
$$$x,2,4,x,6,8,x,\dots,x,3,9,x,15,21,\dots$$$
This is fill two numbers into three blanks.
And we can know the bad index will only in the change of the different qualitative factor.
We will need $$$\frac{2}{3} \times n$$$ numbers for fill.
And the numbers of multiple of 2 or 3 also have $$$\frac{2}{3} \times n$$$,but the number can be odd,which leads to we can't chooose the last one.So we will put some multiple of 5 at the end.
Finally we can construct the array with $$$f(max)=2$$$.
Sorry for my poor English level,if you don't understand you can send post or notifications to me.
Actually i was also thinking the same but wasn't able to code that..!
I solved F by greedily choosing any parent that works, if not, put it inside a queue then try to repeatedly empty the queue in every iteration: 350007901. Typically, finding the parent is $$$O(n)$$$, but I optimized it to $$$O(\log(n))$$$ using segment trees. I think this might not work if there is no such tree that $$$p_1$$$ is the root.
very fast edtioral , which make my code spin, love from regenbogen
how come may brain just shut donw during this division. i can`t even figure out hwo to solve D untill i woke up this morining.
F. Rae Taylor and Trees (hard version)
Can someone proof that $$$p_r$$$ to $$$p_{l-1}$$$ are connected using $$$\text{pre}_{l-1} \lt \text{suf}_l = p_r$$$ on Hint-step 2?
In the beginning of step 1, we say "Suppose that $$$\mathrm{pre}_{i-1} \lt \mathrm{suf}_i$$$ for all $$$i$$$." Indeed, by the result of the easy version, this is a necessary and sufficient condition for an answer to exist.
Now, using this identity at $$$l$$$, we get that $$$\mathrm{pre}_{l-1} \lt \mathrm{suf}_l$$$. We have that $$$\mathrm{suf}_l = p_r$$$ by definition of $$$l$$$ and $$$r$$$, because $$$l-1$$$ and $$$r$$$ are the indices of consecutive suffix maxes.
Now, we have that $$$\mathrm{pre}_{l-1} \lt p_r$$$, and $$$\mathrm{pre}_{l-1}$$$ is in the first $$$l-1$$$ elements, so it appears first. So they can be connected, as desired.
In problem E, Another Solution (Maybe?).
I want to find a longest WONDERFUL array using number $$$1,\cdots,n$$$, that $$$gcd(a_i, a_{i+1}) \gt 1 || gcd(a_{i+1}, a_{i+2}) $$$ for every $$$i$$$ from $$$1$$$ to $$$n - 2$$$。 So the array can be : $$$2,4,6,(3,9,12,\cdots),8,10,(5,20,25,35,40,50,\cdots), 14, (7, 28, 49, 56, 77, \cdots),16,\cdots。$$$
When we meet a number $$$2 \times P$$$ and P is a prime, we put $$$2P, 3P, \cdots $$$ in this array. After that, the number we didn't use is the prime which bigger than $$$n / 2$$$.
Then we can put this number into our WONDERFUL array. If $$$\gcd(a_i, a_{i+1}) \gt 1, \gcd(a_{i+1}, a_{i+2}) \gt 1$$$, Then we can put one number after $$$a_i$$$。 Maybe this is a solution for $$$max f(n) = 1$$$?
Code: 350012298
I thought of a similar idea to the tutorial by noticing that we have n/2 multiples of 2 and n/6 odd multiples of 3. So you use all of them to make a sequence such that for every i from 1 to n — 2 we have exactly one non coprime pair. For example :-
2, X, 4, 6, X, 8, 10, X, ...
Here X denotes "not filled". (Starting with 2 is not optimal but i guess i didn't think of that at the time plus implementation was not easy for me).
It is not enough because n/2 multiples will only give n/4 X's so we are able to add 3n/4 numbers which still leaves n/4 numbers. So, how can we transition to using 3's multiples from this. We can use a multiple of 6 to achieve this in the following manner : Let x be multiple of 2 , y be odd multiple of 3 and z be multiple of 6, then sequence would look like this:
..., x, y, X, z, ...
So, now we have 3n/4 multiples and should have 3n/8 X's which is more than enough ( n/4 < 3n/8) to use up all the numbers.
Code: 350172224
Those problems were so good
cooked by D
is there no DP solution for C1/C2 ?
I use a memoization solution for C1/C2.
First, create a $$$n * 2 * 2$$$ array $$$dp$$$.
for every bit, $$$dp_{i,u,v}$$$ means if in i-th turn, $$$xor a_j(1\leq j\leq i - 1) = u, xor b_j(1\leq j\leq i - 1) = v$$$, whether the player in i-th turn can win。
then check the two swap option(swap or not swap). if I can make next people lose, then I can win this game; IF I can make next person tie, Then the game is tie.
The solution is 349887096
I think there can be a similar problem with bonus of C: 2115D - Gellyfish and Forget-Me-Not
Let's our score be $$$s = \bigoplus a_i$$$ in the begining. For each position define $$$c_i = a_i \oplus b_i$$$. If a move is made on index $$$i$$$, the score simply becomes $$$s = s \bigoplus c_i$$$, otherwise it stays same.
The opponent's score can also be written as $$$(\bigoplus a_i) \bigoplus (\bigoplus b_i) \bigoplus s$$$. So can we say our aim is maximizing or minimizing the $$$s$$$ for maximizing the difference?
reirugan
The program given in question C cannot pass the example. Is it an error in the example or in the code/ll
I just checked and the editorial codes for both C1 and C2 pass samples.
This is the true Div3!
Does someone know any DSU solution for D? Thanks!
https://mirror.codeforces.com/contest/2171/submission/349903368
didn't realise it was that easy for pB :(
I have come up with an idea for question E, but I need to sleep in East Asia.
What are the expected ratings of all the problems..?
If you are struggling to understand problem C (Easy + Hard) then
here is the detailed video editorial (in Hindi) for you : C Video tutorial
How someone can think for problem D ? i wasn't even close to this.
Anyone used divide and conquer for problem D/F ? (would love to see some similar solutions to improve my implementation of the same.)
It's funny that brute-force solution works for E 350059773
Thanks for the amazing contest!!!
P.S. Very Fast Editorial ^-^! Thanks for all the effort you put into it
can someone please check my tree construction part and tell me where the logic is wrong, preferably with a testcase 349963130
UPD : nvm went with the tutorial way, good enough
Another solution for E : 350006163
Basically, we construct a vector v = {2,5,4,6,1,3} and also its reverse , rv = {3,1,6,4,5,2}.
To build the answer, we process the numbers in blocks of 6. For each block, we push back i*6 + v[0] to i*6 + v[5]. After each block, we swap v with rv.
The reason we use this specific pattern {2,5,4,6,1,3} is that, within each block of 6, any three consecutive numbers always contain at least one pair that shares a common factor (either 2 or 3). This ensures that no three consecutive numbers are pairwise coprime.
Last ,we reverse every other block to make sure that sequences across block boundaries also satisfy the rules. If we didn’t, some sequences would violate the constraints.
Very creative!
For problem G, it dose not cover edge case Input 1 1 1 5 Output: 3 2 but code with output 3 1 will also pass
it is not considering the case when n is 1 and a[0] = 1, so a[0] can be made 2 using 2 operation either by adding 1 or by doubling it.
In the constraints of the problem, $$$n\geq 2$$$. I specifically made it like this to avoid the edge case you mentioned.
Finally I write it by myself Actually I didn't understand it a bit Maybe my English is very bad
I have a solution for H and used a magic number MA=24 for avoiding TLE, but I can't prove that would never miss correct answer(or it may be hacked?). Does anynoe can help me? https://mirror.codeforces.com/contest/2171/submission/350094661
Why in Problem C2 do we only care about the last position where the XOR of a_i with b_i differs and the bit x is active there? And what happens if there are several positions like this? I don’t really understand that part.
Another solution for c2/c1 is to greedyly checking the swap for each players.
this is my solution for it
Ohhh, thanks
Another solution for c2/c1 is to greedyly checking the swap for each players.
this is my solution for it
Can anyone tell me why this solution is correct for E? solution I am not able to prove this
Hello, I understood the logic behind problem G and I tried to submit the following code. But it is giving Out of bounds memory error in Test Case: 3.
Now I see the issue is because the
countvariables value is becoming bigger than the permutation array length I have set. Is there an efficient way to calculatepermutation(count)% modwithin the limits of permutation array length (in my code, the length is set as 10^7) ?Nevermind. Please ignore.
The following change worked.
for D/F — I maintained a monotonic decreasing stack as I iterated. when I got a smaller number, I popped all bigger numbers and then added to same dsu, followed pushing the min element of dsu back to stack. worked good
350067977
This is my code for the D , can anybody explain why this is wrong answer on test case 2 , saying it answers "yes" when it must answer "no"
Good problems and nice editorial! love!! QwQ
for problem d my first idea was to divide the array into three subarrays a,b,c if n appears before one, then a contains the first elements until n, and b contains all before 1, and c contains all from where is 1 until the last element. all elements in a can be connected with themselves and the same for c. then the last step was to find if I can connect the array a and c, and if b can be connected with one or both of them. the idea was correct, sadly, the implementation had many errors.
my ac sol:
https://mirror.codeforces.com/contest/2171/submission/350258232
This seems to always give 0 bad indices except for $$$n=3$$$ and $$$n=5$$$.
Let's define a sequence $$$q$$$ like this: start with $$$i=2$$$, add all $$$i^k \leq n$$$; for all $$$j$$$ from $$$\lfloor n/i \rfloor$$$ to $$$3$$$ add all $$$i^k*j \leq n$$$ which haven't yet been added, change $$$i$$$ to the last (the smallest) $$$j$$$ for which we added something.
Any 2 neighbours in $$$q$$$ are not coprime. If the number of integers $$$1 \leq x \leq n$$$ that are not in $$$q$$$ is small enough we can "fit" them between values of $$$q$$$ ($$$[x_1, q_1, q_2, x_2, q_3, q_4, x_3, ...]$$$).
I believe all $$$i$$$ are primes and we stop when $$$i * nextprime(i) \gt n$$$. And when we reach $$$i$$$ we have already added all the multiples of $$$i$$$ that are less than $$$i^2$$$, except $$$i$$$ itself. So the numbers that are not in $$$q$$$ should all be primes (their multiples that are not in $$$q$$$ are too large).
The number of primes $$$\leq n$$$ approaches $$$n/log(n)$$$, which is $$$ \lt n/3$$$ for big enough n, so we should be able to "fit" those values. And for small n it also seems to be working.
Am I missing something?
Very interesting — looks correct! Nice job.
Thank you for the great problems! I learned a lot from the editorial. I'm also a fan of Mikoto ♥️
In problem H, how to come up with the the dp definition in the editorial instead of the the definition that dp[i][j] is the answer at position i with value j, or does it have any problems or tutorials to practice?
Is there an even simple way?
For E problem, I did a greedy approach, making chains by connecting numbers with same Smallest prime factor(SPF) and then keeping 2 elements from a SPF chain with >=2 elts left and then placing an element with an SPF chain left of length=1.I performed a indepth analysis of number of bad indices given by code and by the author's code over a range of values ranging from very small to very large using a generator,validator and a compare python script to generate a plot of no. of bad indices v/s n for both the programs. From it I am concluding that the maxm no. of bad indices possible is atmost 1 which is achieved by my program, which is in coherence with claim in the editorial.
Link:https://mirror.codeforces.com/contest/2171/submission/350520470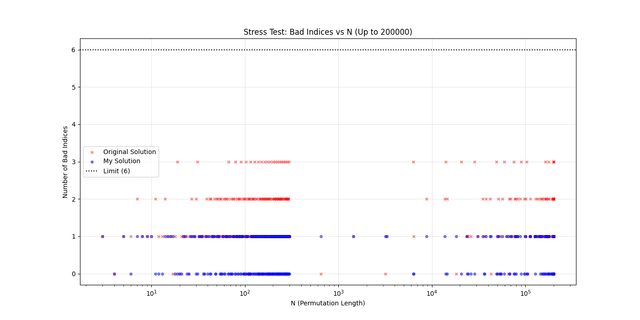
349945988 does this satisfies for the bonus solution of C2?
very fast editorial
352260257 for C1 easy version can anyone explain why my code is failing
Hello everyone, I'm not sure why I'm getting a different result on my computer compared to the result in my submission 352466539.
Could someone help me check my code and see what I might be doing wrong? Here is my output: Your result
The official explanation for E was not very palpable for me. I wrote my detailed intuition with proof in the solution https://mirror.codeforces.com/contest/2171/submission/353349699 if anyone faced the same as I did. Copying the comment from the code below.
I have a question for C2, why shouldn't we consider the second most significant bits if they got a tie for the most significant bits, and do until they consider the last bits? Thank you!
Because if MSB is bigger, then all bits after it can be 1, still the element with MSB 1 will be greater than element with MSB 0. See by 2^k + 2^(k-1) + .. 1 < 2^(k+1). And tie for MSB is not possible, as we took XOR of both arrays and got 1, so only one of the scores has MSB of XOR as 1.
Can F be solved by DSU.
Like I think, if we keep a track of the edges from 0 upto when it reaches N — 1 and then we keep two sets to check for elements to left of a index lesser than it and similarly greater elements to write. Then slide through indices and update the sets.
While making union we obviously check if they are already a part of the MST or tree and proceed. Is it feasible or will it give TLE. I think it wont give TLE but I don't have a formal proof or TC.
for the bonus problem F we notice that any set of n-1 edges and those edges should cover each number from 1 to n at least once gives a valid tree so we just find total number of such sets but i see that in n^2 time
Did anybody try to do E by constructing a graph? Like we can take edge exists if two numbers have non-1 GCD, find a path in each connected component, and then somehow join those path and put single elements between them to find the full permutation. But I think the graph will be large, and will TLE with the constraints. Thanks!